20240604
This commit is contained in:
parent
6061f636f8
commit
64b78bed3b
192
README.md
192
README.md
@ -14,28 +14,35 @@
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md) | [**Türkçe**](./docs/tr/README.tr.md) | [**Português**](./docs/pt/README.pt.md)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
|
||||
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md)| [**Türkçe**](./docs/tr/README.tr.md)
|
||||
|
||||
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
训练推理界面:go-web.bat
|
||||
|
||||
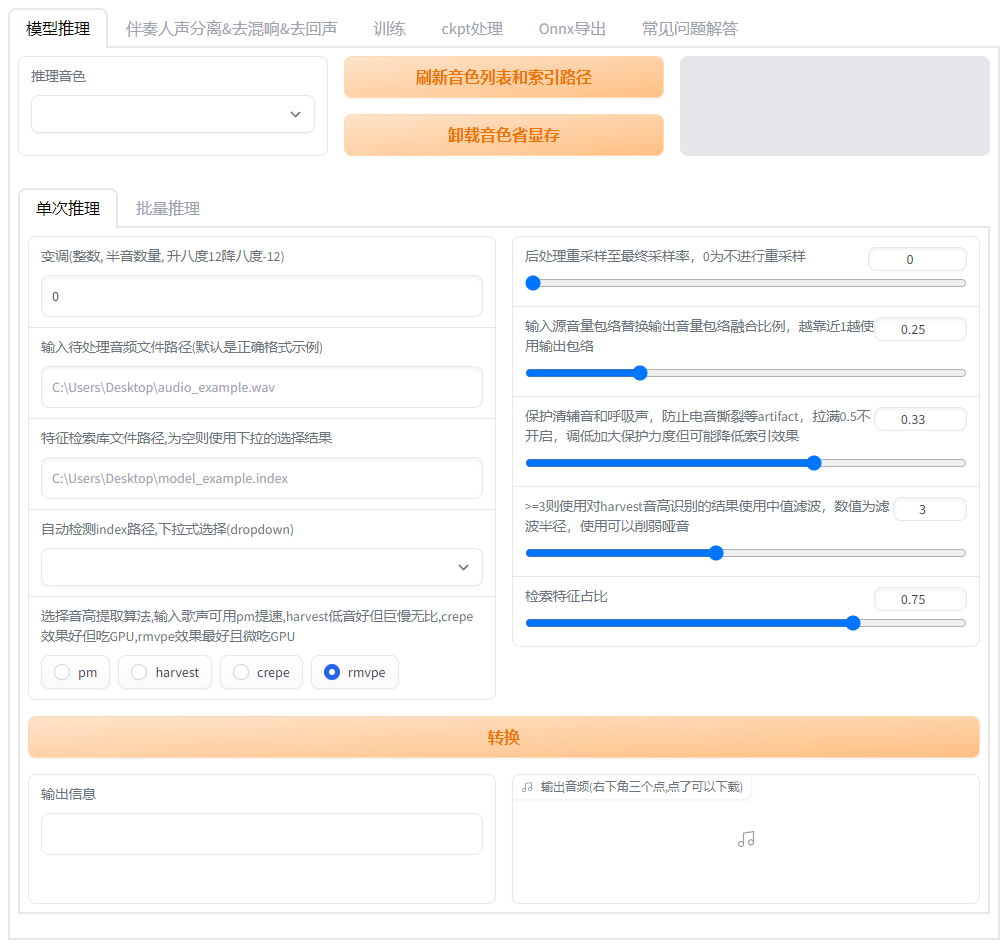
|
||||
|
||||
实时变声界面:go-realtime-gui.bat
|
||||
|
||||
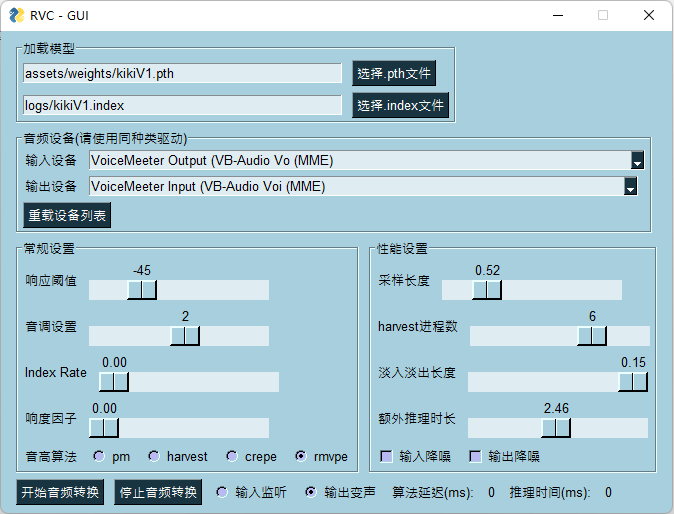
|
||||
|
||||
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
||||
|
||||
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">训练推理界面</td>
|
||||
<td align="center">实时变声界面</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">可以自由选择想要执行的操作。</td>
|
||||
<td align="center">我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## 简介
|
||||
本仓库具有以下特点
|
||||
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
||||
@ -47,47 +54,55 @@
|
||||
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
|
||||
+ A卡I卡加速支持
|
||||
|
||||
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
## 环境配置
|
||||
以下指令需在 Python 版本大于3.8的环境中执行。
|
||||
|
||||
(Windows/Linux)
|
||||
首先通过 pip 安装主要依赖:
|
||||
### Windows/Linux/MacOS等平台通用方法
|
||||
下列方法任选其一。
|
||||
#### 1. 通过 pip 安装依赖
|
||||
1. 安装Pytorch及其核心依赖,若已安装则跳过。参考自: https://pytorch.org/get-started/locally/
|
||||
```bash
|
||||
# 安装Pytorch及其核心依赖,若已安装则跳过
|
||||
# 参考自: https://pytorch.org/get-started/locally/
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
#如果是win系统+Nvidia Ampere架构(RTX30xx),根据 #21 的经验,需要指定pytorch对应的cuda版本
|
||||
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
2. 如果是 win 系统 + Nvidia Ampere 架构(RTX30xx),根据 #21 的经验,需要指定 pytorch 对应的 cuda 版本
|
||||
```bash
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
3. 根据自己的显卡安装对应依赖
|
||||
- N卡
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
- A卡/I卡
|
||||
```bash
|
||||
pip install -r requirements-dml.txt
|
||||
```
|
||||
- A卡ROCM(Linux)
|
||||
```bash
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
- I卡IPEX(Linux)
|
||||
```bash
|
||||
pip install -r requirements-ipex.txt
|
||||
```
|
||||
|
||||
可以使用 poetry 来安装依赖:
|
||||
#### 2. 通过 poetry 来安装依赖
|
||||
安装 Poetry 依赖管理工具,若已安装则跳过。参考自: https://python-poetry.org/docs/#installation
|
||||
```bash
|
||||
# 安装 Poetry 依赖管理工具, 若已安装则跳过
|
||||
# 参考自: https://python-poetry.org/docs/#installation
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
|
||||
# 通过poetry安装依赖
|
||||
poetry install
|
||||
```
|
||||
|
||||
你也可以通过 pip 来安装依赖:
|
||||
通过 Poetry 安装依赖时,python 建议使用 3.7-3.10 版本,其余版本在安装 llvmlite==0.39.0 时会出现冲突
|
||||
```bash
|
||||
N卡:
|
||||
pip install -r requirements.txt
|
||||
|
||||
A卡/I卡:
|
||||
pip install -r requirements-dml.txt
|
||||
|
||||
A卡Rocm(Linux):
|
||||
pip install -r requirements-amd.txt
|
||||
|
||||
I卡IPEX(Linux):
|
||||
pip install -r requirements-ipex.txt
|
||||
poetry init -n
|
||||
poetry env use "path to your python.exe"
|
||||
poetry run pip install -r requirments.txt
|
||||
```
|
||||
|
||||
------
|
||||
Mac 用户可以通过 `run.sh` 来安装依赖:
|
||||
### MacOS
|
||||
可以通过 `run.sh` 来安装依赖
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
@ -97,48 +112,48 @@ RVC需要其他一些预模型来推理和训练。
|
||||
|
||||
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
|
||||
|
||||
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称:
|
||||
### 1. 下载 assets
|
||||
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。你可以在`tools`文件夹找到下载它们的脚本。
|
||||
|
||||
- ./assets/hubert/hubert_base.pt
|
||||
|
||||
- ./assets/pretrained
|
||||
|
||||
- ./assets/uvr5_weights
|
||||
|
||||
想使用v2版本模型的话,需要额外下载
|
||||
|
||||
- ./assets/pretrained_v2
|
||||
|
||||
### 2. 安装 ffmpeg
|
||||
若ffmpeg和ffprobe已安装则跳过。
|
||||
|
||||
#### Ubuntu/Debian 用户
|
||||
```bash
|
||||
./assets/hubert/hubert_base.pt
|
||||
|
||||
./assets/pretrained
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
想测试v2版本模型的话,需要额外下载
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
如果你正在使用Windows,则你可能需要这个文件,若ffmpeg和ffprobe已安装则跳过; ubuntu/debian 用户可以通过apt install ffmpeg来安装这2个库, Mac 用户则可以通过brew install ffmpeg来安装 (需要预先安装brew)
|
||||
|
||||
./ffmpeg
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
./ffprobe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
A卡I卡用户需要的dml环境要请下载
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
之后使用以下指令来启动WebUI:
|
||||
#### MacOS 用户
|
||||
```bash
|
||||
python infer-web.py
|
||||
brew install ffmpeg
|
||||
```
|
||||
如果你正在使用Windows 或 macOS,你可以直接下载并解压`RVC-beta.7z`,前者可以运行`go-web.bat`以启动WebUI,后者则运行命令`sh ./run.sh`以启动WebUI。
|
||||
#### Windows 用户
|
||||
下载后放置在根目录。
|
||||
- 下载[ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
对于需要使用IPEX技术的I卡用户,请先在终端执行`source /opt/intel/oneapi/setvars.sh`(仅Linux)。
|
||||
- 下载[ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
仓库内还有一份`小白简易教程.doc`以供参考。
|
||||
### 3. 下载 rmvpe 人声音高提取算法所需文件
|
||||
|
||||
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录。
|
||||
|
||||
- 下载[rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
||||
|
||||
#### 下载 rmvpe 的 dml 环境(可选, A卡/I卡用户)
|
||||
|
||||
- 下载[rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
||||
|
||||
### 4. AMD显卡Rocm(可选, 仅Linux)
|
||||
|
||||
## AMD显卡Rocm相关(仅Linux)
|
||||
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
||||
|
||||
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
||||
@ -155,11 +170,32 @@ export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
之后运行WebUI:
|
||||
|
||||
## 开始使用
|
||||
### 直接启动
|
||||
使用以下指令来启动 WebUI
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
若先前使用 Poetry 安装依赖,则可以通过以下方式启动WebUI
|
||||
```bash
|
||||
poetry run python infer-web.py
|
||||
```
|
||||
|
||||
### 使用整合包
|
||||
下载并解压`RVC-beta.7z`
|
||||
#### Windows 用户
|
||||
双击`go-web.bat`
|
||||
#### MacOS 用户
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
### 对于需要使用IPEX技术的I卡用户(仅Linux)
|
||||
```bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
```
|
||||
|
||||
## 参考项目
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
|
||||
@ -1 +1 @@
|
||||
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_hostapi": "MME", "sg_wasapi_exclusive": false, "sg_input_device": "VoiceMeeter Output (VB-Audio Vo", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi", "sr_type": "sr_device", "threhold": -60.0, "pitch": 12.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.15, "crossfade_length": 0.08, "extra_time": 2.0, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
||||
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_hostapi": "MME", "sg_wasapi_exclusive": false, "sg_input_device": "VoiceMeeter Output (VB-Audio Vo", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi", "sr_type": "sr_device", "threhold": -60.0, "pitch": 12.0, "formant": 0.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.15, "crossfade_length": 0.08, "extra_time": 2.0, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
||||
@ -14,44 +14,52 @@ An easy-to-use Voice Conversion framework based on VITS.<br><br>
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/en/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
> Check out our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">Training and inference Webui</td>
|
||||
<td align="center">Real-time voice changing GUI</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">You can freely choose the action you want to perform.</td>
|
||||
<td align="center">We have achieved an end-to-end latency of 170ms. With the use of ASIO input and output devices, we have managed to achieve an end-to-end latency of 90ms, but it is highly dependent on hardware driver support.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
> The dataset for the pre-training model uses nearly 50 hours of high quality audio from the VCTK open source dataset.
|
||||
|
||||
Check our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
||||
|
||||
Training/Inference WebUI:go-web.bat
|
||||
|
||||
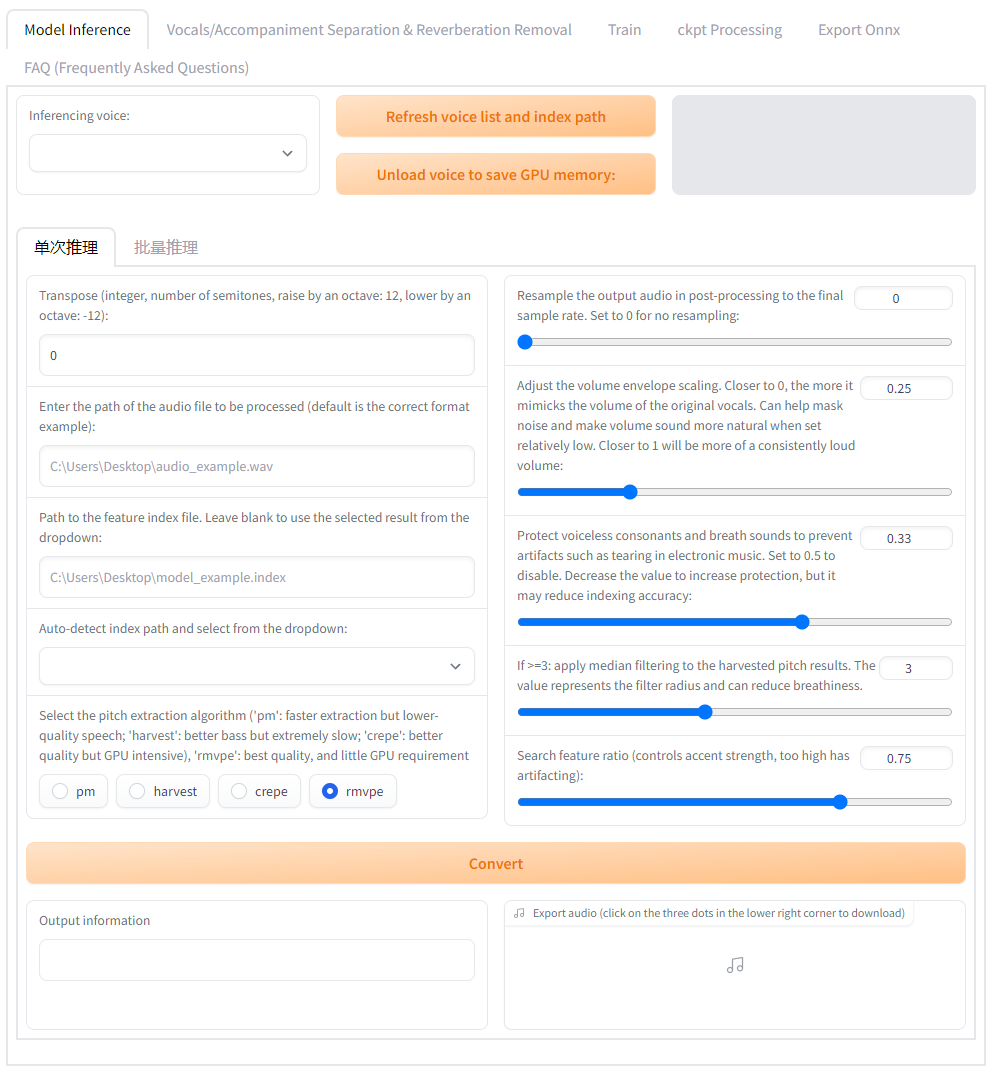
|
||||
|
||||
Realtime Voice Conversion GUI:go-realtime-gui.bat
|
||||
|
||||

|
||||
|
||||
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
|
||||
|
||||
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
|
||||
> High quality licensed song datasets will be added to the training-set often for your use, without having to worry about copyright infringement.
|
||||
|
||||
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
|
||||
|
||||
## Summary
|
||||
This repository has the following features:
|
||||
## Features:
|
||||
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
||||
+ Easy and fast training, even on relatively poor graphics cards;
|
||||
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
|
||||
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
||||
+ Easy-to-use Webui interface;
|
||||
+ Use the UVR5 model to quickly separate vocals and instruments.
|
||||
+ Use the most powerful High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent the muted sound problem. Provides the best results (significantly) and is faster, with even lower resource consumption than Crepe_full.
|
||||
+ AMD/Intel graphics cards acceleration supported.
|
||||
+ Easy + fast training, even on poor graphics cards;
|
||||
+ Training with a small amounts of data (>=10min low noise speech recommended);
|
||||
+ Model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
||||
+ Easy-to-use WebUI;
|
||||
+ UVR5 model to quickly separate vocals and instruments;
|
||||
+ High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent a muted sound problem. Provides the best results (significantly) and is faster with lower resource consumption than Crepe_full;
|
||||
+ AMD/Intel graphics cards acceleration supported;
|
||||
+ Intel ARC graphics cards acceleration with IPEX supported.
|
||||
|
||||
## Preparing the environment
|
||||
The following commands need to be executed in the environment of Python version 3.8 or higher.
|
||||
The following commands need to be executed with Python 3.8 or higher.
|
||||
|
||||
(Windows/Linux)
|
||||
First install the main dependencies through pip:
|
||||
@ -125,15 +133,6 @@ If you want to test the v2 version model (the v2 version model has changed the i
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
#If you are using Windows, you may also need these two files, skip if FFmpeg and FFprobe are installed
|
||||
ffmpeg.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
ffprobe.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
If you want to use the latest SOTA RMVPE vocal pitch extraction algorithm, you need to download the RMVPE weights and place them in the RVC root directory
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
@ -144,14 +143,22 @@ https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
```
|
||||
|
||||
Intel ARC graphics cards users needs to run `source /opt/intel/oneapi/setvars.sh` command before starting Webui.
|
||||
### 2. Install FFmpeg
|
||||
If you have FFmpeg and FFprobe installed on your computer, you can skip this step.
|
||||
|
||||
Then use this command to start Webui:
|
||||
#### For Ubuntu/Debian users
|
||||
```bash
|
||||
python infer-web.py
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
#### For MacOS users
|
||||
```bash
|
||||
brew install ffmpeg
|
||||
```
|
||||
#### For Windwos users
|
||||
Download these files and place them in the root folder:
|
||||
- [ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
If you are using Windows or macOS, you can download and extract `RVC-beta.7z` to use RVC directly by using `go-web.bat` on windows or `sh ./run.sh` on macOS to start Webui.
|
||||
- [ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
## ROCm Support for AMD graphic cards (Linux only)
|
||||
To use ROCm on Linux install all required drivers as described [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||
@ -166,16 +173,30 @@ You might also need to set these environment variables (e.g. on a RX6700XT):
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
````
|
||||
Also make sure your user is part of the `render` and `video` group:
|
||||
Make sure your user is part of the `render` and `video` group:
|
||||
````
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
After that you can run the WebUI:
|
||||
|
||||
## Get started
|
||||
### start up directly
|
||||
Use the following command to start WebUI:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
### Use the integration package
|
||||
Download and extract file `RVC-beta.7z`, then follow the steps below according to your system:
|
||||
#### For Windows users
|
||||
双击`go-web.bat`
|
||||
#### For MacOS users
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
### For Intel IPEX users (Linux Only)
|
||||
```bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
```
|
||||
## Credits
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
|
||||
@ -14,13 +14,13 @@ Un framework simple et facile à utiliser pour la conversion vocale (modificateu
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
|
||||
[**English**](./docs/en/README.en.md) |[ **中文简体**](./docs/cn/README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Turc**](./docs/tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [ **中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Turc**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
Cliquez ici pour voir notre [vidéo de démonstration](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
@ -39,10 +39,10 @@ Ce dépôt a les caractéristiques suivantes :
|
||||
+ Interface web simple et facile à utiliser.
|
||||
+ Peut appeler le modèle UVR5 pour séparer rapidement la voix et l'accompagnement.
|
||||
+ Utilise l'algorithme de pitch vocal le plus avancé [InterSpeech2023-RMVPE](#projets-référencés) pour éliminer les problèmes de voix muette. Meilleurs résultats, plus rapide que crepe_full, et moins gourmand en ressources.
|
||||
+ Support d'accélération pour les cartes A et I.
|
||||
+ Support d'accélération pour les cartes AMD et Intel.
|
||||
|
||||
## Configuration de l'environnement
|
||||
Exécutez les commandes suivantes dans un environnement Python de version supérieure à 3.8.
|
||||
Exécutez les commandes suivantes dans un environnement Python de version 3.8 ou supérieure.
|
||||
|
||||
(Windows/Linux)
|
||||
Installez d'abord les dépendances principales via pip :
|
||||
@ -52,7 +52,10 @@ Installez d'abord les dépendances principales via pip :
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
# Pour les utilisateurs de Windows avec une architecture Nvidia Ampere (RTX30xx), en se basant sur l'expérience #21, spécifiez la version CUDA correspondante pour Pytorch.
|
||||
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
# Pour Linux + carte AMD, utilisez cette version de Pytorch:
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||
```
|
||||
|
||||
Vous pouvez utiliser poetry pour installer les dépendances :
|
||||
@ -67,15 +70,17 @@ poetry install
|
||||
|
||||
Ou vous pouvez utiliser pip pour installer les dépendances :
|
||||
```bash
|
||||
Cartes Nvidia :
|
||||
|
||||
# Cartes Nvidia :
|
||||
pip install -r requirements.txt
|
||||
|
||||
Cartes AMD/Intel :
|
||||
pip install -
|
||||
# Cartes AMD/Intel :
|
||||
pip install -r requirements-dml.txt
|
||||
|
||||
r requirements-dml.txt
|
||||
# Cartes Intel avec IPEX
|
||||
pip install -r requirements-ipex.txt
|
||||
|
||||
# Cartes AMD sur Linux (ROCm)
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
|
||||
------
|
||||
@ -87,7 +92,12 @@ sh ./run.sh
|
||||
## Préparation d'autres modèles pré-entraînés
|
||||
RVC nécessite d'autres modèles pré-entraînés pour l'inférence et la formation.
|
||||
|
||||
Vous pouvez télécharger ces modèles depuis notre [espace Hugging Face](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||
```bash
|
||||
#Télécharger tous les modèles depuis https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
||||
python tools/download_models.py
|
||||
```
|
||||
|
||||
Ou vous pouvez télécharger ces modèles depuis notre [espace Hugging Face](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||
|
||||
Voici une liste des modèles et autres fichiers requis par RVC :
|
||||
```bash
|
||||
@ -97,29 +107,30 @@ Voici une liste des modèles et autres fichiers requis par RVC :
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
Pour tester la version v2 du modèle, téléchargez également :
|
||||
# Pour tester la version v2 du modèle, téléchargez également :
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
Si vous utilisez Windows, vous pourriez avoir besoin de ces fichiers pour ffmpeg et ffprobe, sautez cette étape si vous avez déjà installé ffmpeg et ffprobe. Les utilisateurs d'ubuntu/debian peuvent installer ces deux bibliothèques avec apt install ffmpeg. Les utilisateurs de Mac peuvent les installer avec brew install ffmpeg (prérequis : avoir installé brew).
|
||||
# Si vous utilisez Windows, vous pourriez avoir besoin de ces fichiers pour ffmpeg et ffprobe, sautez cette étape si vous avez déjà installé ffmpeg et ffprobe. Les utilisateurs d'ubuntu/debian peuvent installer ces deux bibliothèques avec apt install ffmpeg. Les utilisateurs de Mac peuvent les installer avec brew install ffmpeg (prérequis : avoir installé brew).
|
||||
|
||||
./ffmpeg
|
||||
# ./ffmpeg
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
./ffprobe
|
||||
# ./ffprobe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
Si vous souhaitez utiliser le dernier algorithme RMVPE de pitch vocal, téléchargez les paramètres du modèle de pitch et placez-les dans le répertoire racine de RVC.
|
||||
# Si vous souhaitez utiliser le dernier algorithme RMVPE de pitch vocal, téléchargez les paramètres du modèle de pitch et placez-les dans le répertoire racine de RVC.
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
Les utilisateurs de cartes AMD/Intel nécessitant l'environnement DML doivent télécharger :
|
||||
# Les utilisateurs de cartes AMD/Intel nécessitant l'environnement DML doivent télécharger :
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||
|
||||
```
|
||||
Pour les utilisateurs d'Intel ARC avec IPEX, exécutez d'abord `source /opt/intel/oneapi/setvars.sh`.
|
||||
Ensuite, exécutez la commande suivante pour démarrer WebUI :
|
||||
```bash
|
||||
python infer-web.py
|
||||
@ -127,7 +138,28 @@ python infer-web.py
|
||||
|
||||
Si vous utilisez Windows ou macOS, vous pouvez télécharger et extraire `RVC-beta.7z`. Les utilisateurs de Windows peuvent exécuter `go-web.bat` pour démarrer WebUI, tandis que les utilisateurs de macOS peuvent exécuter `sh ./run.sh`.
|
||||
|
||||
Il y a également un `Guide facile pour les débutants.doc` inclus pour référence.
|
||||
## Compatibilité ROCm pour les cartes AMD (seulement Linux)
|
||||
Installez tous les pilotes décrits [ici](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||
|
||||
Sur Arch utilisez pacman pour installer le pilote:
|
||||
````
|
||||
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||
````
|
||||
|
||||
Vous devrez peut-être créer ces variables d'environnement (par exemple avec RX6700XT):
|
||||
````
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
````
|
||||
Assurez-vous que votre utilisateur est dans les groupes `render` et `video`:
|
||||
````
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
Enfin vous pouvez exécuter WebUI:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
## Crédits
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
|
||||
@ -3,107 +3,255 @@
|
||||
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
||||
VITSに基づく使いやすい音声変換(voice changer)framework<br><br>
|
||||
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||
|
||||
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
||||
|
||||
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**更新日誌**](./Changelog_JA.md) | [**よくある質問**](./faq_ja.md) | [**AutoDL·5 円で AI 歌手をトレーニング**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**対照実験記録**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**オンラインデモ**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
|
||||
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
> デモ動画は[こちら](https://www.bilibili.com/video/BV1pm4y1z7Gm/)でご覧ください。
|
||||
|
||||
> RVCによるリアルタイム音声変換: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
||||
> RVC によるリアルタイム音声変換: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
||||
|
||||
> 著作権侵害を心配することなく使用できるように、基底モデルは約50時間の高品質なオープンソースデータセットで訓練されています。
|
||||
> 著作権侵害を心配することなく使用できるように、基底モデルは約 50 時間の高品質なオープンソースデータセットで訓練されています。
|
||||
|
||||
> 今後も、次々と使用許可のある高品質な歌声の資料集を追加し、基底モデルを訓練する予定です。
|
||||
> RVCv3 の基底モデルルをご期待ください。より大きなパラメータ、より大きなデータ、より良い効果を提供し、基本的に同様の推論速度を維持しながら、トレーニングに必要なデータ量はより少なくなります。
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">トレーニングと推論インターフェース</td>
|
||||
<td align="center">リアルタイム音声変換インターフェース</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">実行したい操作を自由に選択できます。</td>
|
||||
<td align="center">既に端から端までの170msの遅延を実現しました。ASIO入出力デバイスを使用すれば、端から端までの90msの遅延を達成できますが、ハードウェアドライバーのサポートに非常に依存しています。</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## はじめに
|
||||
|
||||
本リポジトリには下記の特徴があります。
|
||||
|
||||
+ Top1検索を用いることで、生の特徴量を訓練用データセット特徴量に変換し、トーンリーケージを削減します。
|
||||
+ 比較的貧弱なGPUでも、高速かつ簡単に訓練できます。
|
||||
+ 少量のデータセットからでも、比較的良い結果を得ることができます。(10分以上のノイズの少ない音声を推奨します。)
|
||||
+ モデルを融合することで、音声を混ぜることができます。(ckpt processingタブの、ckpt mergeを使用します。)
|
||||
+ 使いやすいWebUI。
|
||||
+ UVR5 Modelも含んでいるため、人の声とBGMを素早く分離できます。
|
||||
- Top1 検索を用いることで、生の特徴量を訓練用データセット特徴量に変換し、トーンリーケージを削減します。
|
||||
- 比較的貧弱な GPU でも、高速かつ簡単に訓練できます。
|
||||
- 少量のデータセットからでも、比較的良い結果を得ることができます。(10 分以上のノイズの少ない音声を推奨します。)
|
||||
- モデルを融合することで、音声を混ぜることができます。(ckpt processing タブの、ckpt merge を使用します。)
|
||||
- 使いやすい WebUI。
|
||||
- UVR5 Model も含んでいるため、人の声と BGM を素早く分離できます。
|
||||
- 最先端の[人間の声のピッチ抽出アルゴリズム InterSpeech2023-RMVPE](#参照プロジェクト)を使用して無声音問題を解決します。効果は最高(著しく)で、crepe_full よりも速く、リソース使用が少ないです。
|
||||
- A カードと I カードの加速サポート
|
||||
|
||||
私たちの[デモビデオ](https://www.bilibili.com/video/BV1pm4y1z7Gm/)をチェックしてください!
|
||||
|
||||
## 環境構築
|
||||
Poetryで依存関係をインストールすることをお勧めします。
|
||||
|
||||
下記のコマンドは、Python3.8以上の環境で実行する必要があります:
|
||||
下記のコマンドは、Python3.8 以上の環境で実行する必要があります:
|
||||
|
||||
### Windows/Linux/MacOS などのプラットフォーム共通方法
|
||||
|
||||
以下の方法のいずれかを選択してください。
|
||||
|
||||
#### 1. pip を通じた依存関係のインストール
|
||||
|
||||
1. Pytorch 及びその主要な依存関係のインストール、すでにインストールされている場合はスキップ。参照:https://pytorch.org/get-started/locally/
|
||||
|
||||
```bash
|
||||
# PyTorch関連の依存関係をインストール。インストール済の場合は省略。
|
||||
# 参照先: https://pytorch.org/get-started/locally/
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
#Windows+ Nvidia Ampere Architecture(RTX30xx)の場合、 #21 に従い、pytorchに対応するcuda versionを指定する必要があります。
|
||||
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
# PyTorch関連の依存関係をインストール。インストール済の場合は省略。
|
||||
# 参照先: https://python-poetry.org/docs/#installation
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
|
||||
# Poetry経由で依存関係をインストール
|
||||
poetry install
|
||||
```
|
||||
|
||||
pipでも依存関係のインストールが可能です:
|
||||
2. win システム + Nvidia Ampere アーキテクチャ(RTX30xx)の場合、#21 の経験に基づいて pytorch に対応する cuda バージョンを指定
|
||||
|
||||
```bash
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
|
||||
3. 自分のグラフィックカードに合わせた依存関係のインストール
|
||||
|
||||
- N カード
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## 基底modelsを準備
|
||||
RVCは推論/訓練のために、様々な事前訓練を行った基底モデルを必要とします。
|
||||
- A カード/I カード
|
||||
|
||||
modelsは[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)からダウンロードできます。
|
||||
|
||||
以下は、RVCに必要な基底モデルやその他のファイルの一覧です。
|
||||
```bash
|
||||
./assets/hubert/hubert_base.pt
|
||||
|
||||
./assets/pretrained
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
V2のモデルを使用するには、追加でファイルをダウンロードする必要があります
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
# ffmpegがすでにinstallされている場合は省略
|
||||
./ffmpeg
|
||||
pip install -r requirements-dml.txt
|
||||
```
|
||||
その後、下記のコマンドでWebUIを起動します。
|
||||
|
||||
- A カード ROCM(Linux)
|
||||
|
||||
```bash
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
|
||||
- I カード IPEX(Linux)
|
||||
|
||||
```bash
|
||||
pip install -r requirements-ipex.txt
|
||||
```
|
||||
|
||||
#### 2. poetry を通じた依存関係のインストール
|
||||
|
||||
Poetry 依存関係管理ツールのインストール、すでにインストールされている場合はスキップ。参照:https://python-poetry.org/docs/#installation
|
||||
|
||||
```bash
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
```
|
||||
|
||||
poetry を使って依存関係をインストール
|
||||
|
||||
```bash
|
||||
poetry install
|
||||
```
|
||||
|
||||
### MacOS
|
||||
|
||||
`run.sh`を使って依存関係をインストールできます
|
||||
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
|
||||
## その他の事前訓練されたモデルの準備
|
||||
|
||||
RVC は推論とトレーニングのために他のいくつかの事前訓練されたモデルが必要です。
|
||||
|
||||
これらのモデルは私たちの[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)でダウンロードできます。
|
||||
|
||||
### 1. assets のダウンロード
|
||||
|
||||
以下は、RVC に必要なすべての事前学習モデルとその他のファイルのリストです。`tools`フォルダーにこれらをダウンロードするスクリプトがあります。
|
||||
|
||||
- ./assets/hubert/hubert_base.pt
|
||||
|
||||
- ./assets/pretrained
|
||||
|
||||
- ./assets/uvr5_weights
|
||||
|
||||
v2 バージョンのモデルを使用する場合、追加で以下をダウンロードする必要があります。
|
||||
|
||||
- ./assets/pretrained_v2
|
||||
|
||||
### 2. ffmpeg のインストール
|
||||
|
||||
ffmpeg と ffprobe が既にインストールされている場合はスキップします。
|
||||
|
||||
#### Ubuntu/Debian ユーザー
|
||||
|
||||
```bash
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
|
||||
#### MacOS ユーザー
|
||||
|
||||
```bash
|
||||
brew install ffmpeg
|
||||
```
|
||||
|
||||
#### Windows ユーザー
|
||||
|
||||
ダウンロード後、ルートディレクトリに配置してください。
|
||||
|
||||
- [ffmpeg.exe をダウンロード](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
- [ffprobe.exe をダウンロード](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
### 3. RMVPE 人間の声のピッチ抽出アルゴリズムに必要なファイルのダウンロード
|
||||
|
||||
最新の RMVPE 人間の声のピッチ抽出アルゴリズムを使用する場合、ピッチ抽出モデルのパラメータをダウンロードして RVC のルートディレクトリに配置する必要があります。
|
||||
|
||||
- [rmvpe.pt をダウンロード](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
||||
|
||||
#### dml 環境の RMVPE をダウンロード(オプション、A カード/I カードユーザー)
|
||||
|
||||
- [rmvpe.onnx をダウンロード](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
||||
|
||||
### 4. AMD グラフィックカード Rocm(オプション、Linux のみ)
|
||||
|
||||
Linux システムで AMD の Rocm 技術をベースに RVC を実行したい場合、[こちら](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)で必要なドライバーを先にインストールしてください。
|
||||
|
||||
Arch Linux を使用している場合、pacman を使用して必要なドライバーをインストールできます。
|
||||
|
||||
```
|
||||
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||
```
|
||||
|
||||
一部のモデルのグラフィックカード(例:RX6700XT)の場合、以下のような環境変数を追加で設定する必要があるかもしれません。
|
||||
|
||||
```
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
```
|
||||
|
||||
同時に、現在のユーザーが`render`および`video`ユーザーグループに属していることを確認してください。
|
||||
|
||||
```
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
```
|
||||
|
||||
## 使用開始
|
||||
|
||||
### 直接起動
|
||||
|
||||
以下のコマンドで WebUI を起動します
|
||||
'''bash
|
||||
python infer-web.py
|
||||
```
|
||||
Windowsをお使いの方は、直接`RVC-beta.7z`をダウンロード後に展開し、`go-web.bat`をクリックすることで、WebUIを起動することができます。(7zipが必要です。)
|
||||
'''
|
||||
|
||||
また、リポジトリに[小白简易教程.doc](./小白简易教程.doc)がありますので、参考にしてください(中国語版のみ)。
|
||||
### 統合パッケージの使用
|
||||
|
||||
`RVC-beta.7z`をダウンロードして解凍
|
||||
|
||||
#### Windows ユーザー
|
||||
|
||||
`go-web.bat`をダブルクリック
|
||||
|
||||
#### MacOS ユーザー
|
||||
|
||||
'''bash
|
||||
sh ./run.sh
|
||||
'''
|
||||
|
||||
### IPEX 技術が必要な I カードユーザー向け(Linux のみ)
|
||||
|
||||
'''bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
'''
|
||||
|
||||
## 参考プロジェクト
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
||||
+ [Gradio](https://github.com/gradio-app/gradio)
|
||||
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
||||
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
||||
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
||||
|
||||
## 貢献者(contributor)の皆様の尽力に感謝します
|
||||
- [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
- [VITS](https://github.com/jaywalnut310/vits)
|
||||
- [HIFIGAN](https://github.com/jik876/hifi-gan)
|
||||
- [Gradio](https://github.com/gradio-app/gradio)
|
||||
- [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
||||
- [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
||||
- [audio-slicer](https://github.com/openvpi/audio-slicer)
|
||||
- [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
||||
- 事前訓練されたモデルは[yxlllc](https://github.com/yxlllc/RMVPE)と[RVC-Boss](https://github.com/RVC-Boss)によって訓練され、テストされました。
|
||||
|
||||
## すべての貢献者の努力に感謝します
|
||||
|
||||
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
||||
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
||||
</a>
|
||||
|
||||
@ -1,5 +1,22 @@
|
||||
### 2023-08-13
|
||||
### 2023년 10월 6일 업데이트
|
||||
|
||||
실시간 음성 변환을 위한 인터페이스인 go-realtime-gui.bat/gui_v1.py를 제작했습니다(사실 이는 이미 존재했었습니다). 이번 업데이트는 주로 실시간 음성 변환 성능을 최적화하는 데 중점을 두었습니다. 0813 버전과 비교하여:
|
||||
|
||||
- 1. 인터페이스 조작 최적화: 매개변수 핫 업데이트(매개변수 조정 시 중단 후 재시작 필요 없음), 모델 지연 로딩(이미 로드된 모델은 재로드 필요 없음), 음량 인자 매개변수 추가(음량을 입력 오디오에 가깝게 조정)
|
||||
- 2. 내장된 노이즈 감소 효과 및 속도 최적화
|
||||
- 3. 추론 속도 크게 향상
|
||||
|
||||
입력 및 출력 장치는 동일한 유형을 선택해야 합니다. 예를 들어, 모두 MME 유형을 선택해야 합니다.
|
||||
|
||||
1006 버전의 전체 업데이트는 다음과 같습니다:
|
||||
|
||||
- 1. rmvpe 음성 피치 추출 알고리즘의 효과를 계속해서 향상, 특히 남성 저음역에 대한 개선이 큼
|
||||
- 2. 추론 인터페이스 레이아웃 최적화
|
||||
|
||||
### 2023년 08월 13일 업데이트
|
||||
|
||||
1-정기적인 버그 수정
|
||||
|
||||
- 최소 총 에포크 수를 1로 변경하고, 최소 총 에포크 수를 2로 변경합니다.
|
||||
- 사전 훈련(pre-train) 모델을 사용하지 않는 훈련 오류 수정
|
||||
- 반주 보컬 분리 후 그래픽 메모리 지우기
|
||||
@ -9,9 +26,10 @@
|
||||
- 실시간 음성 변경 중 faiss 검색으로 인한 CPU 소모 문제 해결
|
||||
|
||||
2-키 업데이트
|
||||
|
||||
- 현재 가장 강력한 오픈 소스 보컬 피치 추출 모델 RMVPE를 훈련하고, 이를 RVC 훈련, 오프라인/실시간 추론에 사용하며, PyTorch/Onx/DirectML을 지원합니다.
|
||||
- 파이토치_DML을 통한 AMD 및 인텔 그래픽 카드 지원
|
||||
(1) 실시간 음성 변화 (2) 추론 (3) 보컬 반주 분리 (4) 현재 지원되지 않는 훈련은 CPU 훈련으로 전환, Onnx_Dml을 통한 gpu의 RMVPE 추론 지원
|
||||
- 파이토치\_DML을 통한 AMD 및 인텔 그래픽 카드 지원
|
||||
(1) 실시간 음성 변화 (2) 추론 (3) 보컬 반주 분리 (4) 현재 지원되지 않는 훈련은 CPU 훈련으로 전환, Onnx_Dml을 통한 gpu의 RMVPE 추론 지원
|
||||
|
||||
### 2023년 6월 18일 업데이트
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ VITS基盤의 簡單하고使用하기 쉬운音聲變換틀<br><br>
|
||||
------
|
||||
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_KO.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
> [示範映像](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 確認해 보세요!
|
||||
|
||||
|
||||
@ -3,104 +3,243 @@
|
||||
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
||||
VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.<br><br>
|
||||
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||
|
||||
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
||||
|
||||
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**업데이트 로그**](./Changelog_KO.md) | [**자주 묻는 질문**](./faq_ko.md) | [**AutoDL·5원으로 AI 가수 훈련**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**대조 실험 기록**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**온라인 데모**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
</div>
|
||||
|
||||
---
|
||||
|
||||
[**업데이트 로그**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/kr/Changelog_KO.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
> [데모 영상](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 확인해 보세요!
|
||||
|
||||
> RVC를 활용한 실시간 음성변환: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
||||
|
||||
> 기본 모델은 50시간 가량의 고퀄리티 오픈 소스 VCTK 데이터셋을 사용하였으므로, 저작권상의 염려가 없으니 안심하고 사용하시기 바랍니다.
|
||||
|
||||
> 저작권 문제가 없는 고퀄리티의 노래를 이후에도 계속해서 훈련할 예정입니다.
|
||||
> 더 큰 매개변수, 더 큰 데이터, 더 나은 효과, 기본적으로 동일한 추론 속도, 더 적은 양의 훈련 데이터가 필요한 RVCv3의 기본 모델을 기대해 주십시오.
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">훈련 및 추론 인터페이스</td>
|
||||
<td align="center">실시간 음성 변환 인터페이스</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">원하는 작업을 자유롭게 선택할 수 있습니다.</td>
|
||||
<td align="center">우리는 이미 끝에서 끝까지 170ms의 지연을 실현했습니다. ASIO 입력 및 출력 장치를 사용하면 끝에서 끝까지 90ms의 지연을 달성할 수 있지만, 이는 하드웨어 드라이버 지원에 매우 의존적입니다.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## 소개
|
||||
|
||||
본 Repo는 다음과 같은 특징을 가지고 있습니다:
|
||||
|
||||
- top1 검색을 이용하여 입력 음색 특징을 훈련 세트 음색 특징으로 대체하여 음색의 누출을 방지;
|
||||
- 상대적으로 낮은 성능의 GPU에서도 빠른 훈련 가능;
|
||||
- 적은 양의 데이터로 훈련해도 좋은 결과를 얻을 수 있음 (최소 10분 이상의 저잡음 음성 데이터를 사용하는 것을 권장);
|
||||
- 모델 융합을 통한 음색의 변조 가능 (ckpt 처리 탭->ckpt 병합 선택);
|
||||
- 사용하기 쉬운 WebUI (웹 인터페이스);
|
||||
- top1 검색을 이용하여 입력 음색 특징을 훈련 세트 음색 특징으로 대체하여 음색의 누출을 방지
|
||||
- 상대적으로 낮은 성능의 GPU에서도 빠른 훈련 가능
|
||||
- 적은 양의 데이터로 훈련해도 좋은 결과를 얻을 수 있음 (최소 10분 이상의 저잡음 음성 데이터를 사용하는 것을 권장)
|
||||
- 모델 융합을 통한 음색의 변조 가능 (ckpt 처리 탭->ckpt 병합 선택)
|
||||
- 사용하기 쉬운 WebUI (웹 인터페이스)
|
||||
- UVR5 모델을 이용하여 목소리와 배경음악의 빠른 분리;
|
||||
- 최첨단 [음성 피치 추출 알고리즘 InterSpeech2023-RMVPE](#参考项目)을 사용하여 무성음 문제를 해결합니다. 효과는 최고(압도적)이며 crepe_full보다 더 빠르고 리소스 사용이 적음
|
||||
- A카드와 I카드 가속을 지원
|
||||
|
||||
## 환경의 준비
|
||||
해당 프로젝트의 [데모 비디오](https://www.bilibili.com/video/BV1pm4y1z7Gm/)를 확인해보세요!
|
||||
|
||||
poetry를 통해 dependecies를 설치하는 것을 권장합니다.
|
||||
## 환경 설정
|
||||
|
||||
다음 명령은 Python 버전 3.8 이상의 환경에서 실행되어야 합니다:
|
||||
다음 명령은 Python 버전이 3.8 이상인 환경에서 실행해야 합니다.
|
||||
|
||||
### Windows/Linux/MacOS 등 플랫폼 공통 방법
|
||||
|
||||
아래 방법 중 하나를 선택하세요.
|
||||
|
||||
#### 1. pip를 통한 의존성 설치
|
||||
|
||||
1. Pytorch 및 의존성 모듈 설치, 이미 설치되어 있으면 생략. 참조: https://pytorch.org/get-started/locally/
|
||||
|
||||
```bash
|
||||
# PyTorch 관련 주요 dependencies 설치, 이미 설치되어 있는 경우 건너뛰기 가능
|
||||
# 참조: https://pytorch.org/get-started/locally/
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
# Windows + Nvidia Ampere Architecture(RTX30xx)를 사용하고 있다면, https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/21 에서 명시된 것과 같이 PyTorch에 맞는 CUDA 버전을 지정해야 합니다.
|
||||
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
# Poetry 설치, 이미 설치되어 있는 경우 건너뛰기 가능
|
||||
# Reference: https://python-poetry.org/docs/#installation
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
|
||||
# Dependecies 설치
|
||||
poetry install
|
||||
```
|
||||
|
||||
pip를 활용하여 dependencies를 설치하여도 무방합니다.
|
||||
2. win 시스템 + Nvidia Ampere 아키텍처(RTX30xx) 사용 시, #21의 사례에 따라 pytorch에 해당하는 cuda 버전을 지정
|
||||
|
||||
```bash
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
|
||||
3. 자신의 그래픽 카드에 맞는 의존성 설치
|
||||
|
||||
- N카드
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## 기타 사전 모델 준비
|
||||
|
||||
RVC 모델은 추론과 훈련을 위하여 다른 사전 모델이 필요합니다.
|
||||
|
||||
[Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)를 통해서 다운로드 할 수 있습니다.
|
||||
|
||||
다음은 RVC에 필요한 사전 모델 및 기타 파일 목록입니다:
|
||||
- A카드/I카드
|
||||
|
||||
```bash
|
||||
./assets/hubert/hubert_base.pt
|
||||
|
||||
./assets/pretrained
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
V2 버전 모델을 테스트하려면 추가 다운로드가 필요합니다.
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
# Windows를 사용하는 경우 이 사전도 필요할 수 있습니다. FFmpeg가 설치되어 있으면 건너뛰어도 됩니다.
|
||||
ffmpeg.exe
|
||||
pip install -r requirements-dml.txt
|
||||
```
|
||||
|
||||
그 후 이하의 명령을 사용하여 WebUI를 시작할 수 있습니다:
|
||||
- A카드ROCM(Linux)
|
||||
|
||||
```bash
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
|
||||
- I카드IPEX(Linux)
|
||||
|
||||
```bash
|
||||
pip install -r requirements-ipex.txt
|
||||
```
|
||||
|
||||
#### 2. poetry를 통한 의존성 설치
|
||||
|
||||
Poetry 의존성 관리 도구 설치, 이미 설치된 경우 생략. 참조: https://python-poetry.org/docs/#installation
|
||||
|
||||
```bash
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
```
|
||||
|
||||
poetry를 통한 의존성 설치
|
||||
|
||||
```bash
|
||||
poetry install
|
||||
```
|
||||
|
||||
### MacOS
|
||||
|
||||
`run.sh`를 통해 의존성 설치 가능
|
||||
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
|
||||
## 기타 사전 훈련된 모델 준비
|
||||
|
||||
RVC는 추론과 훈련을 위해 다른 일부 사전 훈련된 모델이 필요합니다.
|
||||
|
||||
이러한 모델은 저희의 [Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)에서 다운로드할 수 있습니다.
|
||||
|
||||
### 1. assets 다운로드
|
||||
|
||||
다음은 RVC에 필요한 모든 사전 훈련된 모델과 기타 파일의 목록입니다. `tools` 폴더에서 이들을 다운로드하는 스크립트를 찾을 수 있습니다.
|
||||
|
||||
- ./assets/hubert/hubert_base.pt
|
||||
|
||||
- ./assets/pretrained
|
||||
|
||||
- ./assets/uvr5_weights
|
||||
|
||||
v2 버전 모델을 사용하려면 추가로 다음을 다운로드해야 합니다.
|
||||
|
||||
- ./assets/pretrained_v2
|
||||
|
||||
### 2. ffmpeg 설치
|
||||
|
||||
ffmpeg와 ffprobe가 이미 설치되어 있다면 건너뜁니다.
|
||||
|
||||
#### Ubuntu/Debian 사용자
|
||||
|
||||
```bash
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
|
||||
#### MacOS 사용자
|
||||
|
||||
```bash
|
||||
brew install ffmpeg
|
||||
```
|
||||
|
||||
#### Windows 사용자
|
||||
|
||||
다운로드 후 루트 디렉토리에 배치.
|
||||
|
||||
- [ffmpeg.exe 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
- [ffprobe.exe 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
### 3. RMVPE 인간 음성 피치 추출 알고리즘에 필요한 파일 다운로드
|
||||
|
||||
최신 RMVPE 인간 음성 피치 추출 알고리즘을 사용하려면 음피치 추출 모델 매개변수를 다운로드하고 RVC 루트 디렉토리에 배치해야 합니다.
|
||||
|
||||
- [rmvpe.pt 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
||||
|
||||
#### dml 환경의 RMVPE 다운로드(선택사항, A카드/I카드 사용자)
|
||||
|
||||
- [rmvpe.onnx 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
||||
|
||||
### 4. AMD 그래픽 카드 Rocm(선택사항, Linux만 해당)
|
||||
|
||||
Linux 시스템에서 AMD의 Rocm 기술을 기반으로 RVC를 실행하려면 [여기](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)에서 필요한 드라이버를 먼저 설치하세요.
|
||||
|
||||
Arch Linux를 사용하는 경우 pacman을 사용하여 필요한 드라이버를 설치할 수 있습니다.
|
||||
|
||||
```
|
||||
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||
```
|
||||
|
||||
일부 모델의 그래픽 카드(예: RX6700XT)의 경우, 다음과 같은 환경 변수를 추가로 설정해야 할 수 있습니다.
|
||||
|
||||
```
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
```
|
||||
|
||||
동시에 현재 사용자가 `render` 및 `video` 사용자 그룹에 속해 있는지 확인하세요.
|
||||
|
||||
```
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
```
|
||||
|
||||
## 시작하기
|
||||
|
||||
### 직접 시작
|
||||
|
||||
다음 명령어로 WebUI를 시작하세요
|
||||
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
Windows를 사용하는 경우 `RVC-beta.7z`를 다운로드 및 압축 해제하여 RVC를 직접 사용하거나 `go-web.bat`을 사용하여 WebUi를 시작할 수 있습니다.
|
||||
### 통합 패키지 사용
|
||||
|
||||
## 참고
|
||||
`RVC-beta.7z`를 다운로드하고 압축 해제
|
||||
|
||||
#### Windows 사용자
|
||||
|
||||
`go-web.bat` 더블 클릭
|
||||
|
||||
#### MacOS 사용자
|
||||
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
|
||||
### IPEX 기술이 필요한 I카드 사용자를 위한 지침(Linux만 해당)
|
||||
|
||||
```bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
```
|
||||
|
||||
## 참조 프로젝트
|
||||
|
||||
- [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
- [VITS](https://github.com/jaywalnut310/vits)
|
||||
@ -109,8 +248,10 @@ Windows를 사용하는 경우 `RVC-beta.7z`를 다운로드 및 압축 해제
|
||||
- [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
||||
- [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
||||
- [audio-slicer](https://github.com/openvpi/audio-slicer)
|
||||
- [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
||||
- 사전 훈련된 모델은 [yxlllc](https://github.com/yxlllc/RMVPE)와 [RVC-Boss](https://github.com/RVC-Boss)에 의해 훈련되고 테스트되었습니다.
|
||||
|
||||
## 모든 기여자 분들의 노력에 감사드립니다.
|
||||
## 모든 기여자들의 노력에 감사드립니다
|
||||
|
||||
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
||||
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
||||
|
||||
@ -17,7 +17,7 @@ Uma estrutura de conversão de voz fácil de usar baseada em VITS.<br><br>
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/en/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
|
||||
@ -18,9 +18,9 @@ VITS'e dayalı kullanımı kolay bir Ses Dönüşümü çerçevesi.<br><br>
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Değişiklik Geçmişi**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/tr/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||
[**Değişiklik Geçmişi**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||
|
||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
Burada [Demo Video'muzu](https://www.bilibili.com/video/BV1pm4y1z7Gm/) izleyebilirsiniz!
|
||||
|
||||
|
||||
BIN
docs/小白简易教程.doc
Normal file
BIN
docs/小白简易教程.doc
Normal file
Binary file not shown.
29
gui_v1.py
29
gui_v1.py
@ -84,13 +84,13 @@ if __name__ == "__main__":
|
||||
import librosa
|
||||
from tools.torchgate import TorchGate
|
||||
import numpy as np
|
||||
import PySimpleGUI as sg
|
||||
import FreeSimpleGUI as sg
|
||||
import sounddevice as sd
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torchaudio.transforms as tat
|
||||
|
||||
import tools.rvc_for_realtime as rvc_for_realtime
|
||||
from infer.lib import rtrvc as rvc_for_realtime
|
||||
from i18n.i18n import I18nAuto
|
||||
from configs.config import Config
|
||||
|
||||
@ -107,13 +107,16 @@ if __name__ == "__main__":
|
||||
opt_q = Queue()
|
||||
n_cpu = min(cpu_count(), 8)
|
||||
for _ in range(n_cpu):
|
||||
Harvest(inp_q, opt_q).start()
|
||||
p = Harvest(inp_q, opt_q)
|
||||
p.daemon = True
|
||||
p.start()
|
||||
|
||||
class GUIConfig:
|
||||
def __init__(self) -> None:
|
||||
self.pth_path: str = ""
|
||||
self.index_path: str = ""
|
||||
self.pitch: int = 0
|
||||
self.formant=0.0
|
||||
self.sr_type: str = "sr_model"
|
||||
self.block_time: float = 0.25 # s
|
||||
self.threhold: int = -60
|
||||
@ -197,6 +200,7 @@ if __name__ == "__main__":
|
||||
"sr_type": "sr_model",
|
||||
"threhold": -60,
|
||||
"pitch": 0,
|
||||
"formant": 0.0,
|
||||
"index_rate": 0,
|
||||
"rms_mix_rate": 0,
|
||||
"block_time": 0.25,
|
||||
@ -331,7 +335,7 @@ if __name__ == "__main__":
|
||||
[
|
||||
sg.Text(i18n("音调设置")),
|
||||
sg.Slider(
|
||||
range=(-24, 24),
|
||||
range=(-16, 16),
|
||||
key="pitch",
|
||||
resolution=1,
|
||||
orientation="h",
|
||||
@ -339,6 +343,17 @@ if __name__ == "__main__":
|
||||
enable_events=True,
|
||||
),
|
||||
],
|
||||
[
|
||||
sg.Text(i18n("性别因子/声线粗细")),
|
||||
sg.Slider(
|
||||
range=(-2, 2),
|
||||
key="formant",
|
||||
resolution=0.05,
|
||||
orientation="h",
|
||||
default_value=data.get("formant", 0.0),
|
||||
enable_events=True,
|
||||
),
|
||||
],
|
||||
[
|
||||
sg.Text(i18n("Index Rate")),
|
||||
sg.Slider(
|
||||
@ -606,6 +621,10 @@ if __name__ == "__main__":
|
||||
self.gui_config.pitch = values["pitch"]
|
||||
if hasattr(self, "rvc"):
|
||||
self.rvc.change_key(values["pitch"])
|
||||
elif event == "formant":
|
||||
self.gui_config.formant = values["formant"]
|
||||
if hasattr(self, "rvc"):
|
||||
self.rvc.change_formant(values["formant"])
|
||||
elif event == "index_rate":
|
||||
self.gui_config.index_rate = values["index_rate"]
|
||||
if hasattr(self, "rvc"):
|
||||
@ -664,6 +683,7 @@ if __name__ == "__main__":
|
||||
]
|
||||
self.gui_config.threhold = values["threhold"]
|
||||
self.gui_config.pitch = values["pitch"]
|
||||
self.gui_config.formant = values["formant"]
|
||||
self.gui_config.block_time = values["block_time"]
|
||||
self.gui_config.crossfade_time = values["crossfade_length"]
|
||||
self.gui_config.extra_time = values["extra_time"]
|
||||
@ -688,6 +708,7 @@ if __name__ == "__main__":
|
||||
torch.cuda.empty_cache()
|
||||
self.rvc = rvc_for_realtime.RVC(
|
||||
self.gui_config.pitch,
|
||||
self.gui_config.formant,
|
||||
self.gui_config.pth_path,
|
||||
self.gui_config.index_path,
|
||||
self.gui_config.index_rate,
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
"B模型路径": "B模型路径",
|
||||
"E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
|
||||
"F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调",
|
||||
"Index Rate": "Index Rate",
|
||||
"Index Rate": "检索特征占比",
|
||||
"Onnx导出": "Onnx导出",
|
||||
"Onnx输出路径": "Onnx输出路径",
|
||||
"RVC模型路径": "RVC模型路径",
|
||||
|
||||
@ -10,16 +10,16 @@ from torch import nn
|
||||
from torch.nn import AvgPool1d, Conv1d, Conv2d, ConvTranspose1d
|
||||
from torch.nn import functional as F
|
||||
from torch.nn.utils import remove_weight_norm, spectral_norm, weight_norm
|
||||
|
||||
from infer.lib.infer_pack import attentions, commons, modules
|
||||
from infer.lib.infer_pack.commons import get_padding, init_weights
|
||||
|
||||
has_xpu = bool(hasattr(torch, "xpu") and torch.xpu.is_available())
|
||||
|
||||
|
||||
class TextEncoder256(nn.Module):
|
||||
class TextEncoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels,
|
||||
out_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
@ -29,7 +29,7 @@ class TextEncoder256(nn.Module):
|
||||
p_dropout,
|
||||
f0=True,
|
||||
):
|
||||
super(TextEncoder256, self).__init__()
|
||||
super(TextEncoder, self).__init__()
|
||||
self.out_channels = out_channels
|
||||
self.hidden_channels = hidden_channels
|
||||
self.filter_channels = filter_channels
|
||||
@ -37,7 +37,7 @@ class TextEncoder256(nn.Module):
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = float(p_dropout)
|
||||
self.emb_phone = nn.Linear(256, hidden_channels)
|
||||
self.emb_phone = nn.Linear(in_channels, hidden_channels)
|
||||
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
||||
if f0 == True:
|
||||
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
||||
@ -52,60 +52,12 @@ class TextEncoder256(nn.Module):
|
||||
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
||||
|
||||
def forward(
|
||||
self, phone: torch.Tensor, pitch: Optional[torch.Tensor], lengths: torch.Tensor
|
||||
):
|
||||
if pitch is None:
|
||||
x = self.emb_phone(phone)
|
||||
else:
|
||||
x = self.emb_phone(phone) + self.emb_pitch(pitch)
|
||||
x = x * math.sqrt(self.hidden_channels) # [b, t, h]
|
||||
x = self.lrelu(x)
|
||||
x = torch.transpose(x, 1, -1) # [b, h, t]
|
||||
x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
|
||||
x.dtype
|
||||
)
|
||||
x = self.encoder(x * x_mask, x_mask)
|
||||
stats = self.proj(x) * x_mask
|
||||
|
||||
m, logs = torch.split(stats, self.out_channels, dim=1)
|
||||
return m, logs, x_mask
|
||||
|
||||
|
||||
class TextEncoder768(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
out_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
p_dropout,
|
||||
f0=True,
|
||||
phone: torch.Tensor,
|
||||
pitch: torch.Tensor,
|
||||
lengths: torch.Tensor,
|
||||
skip_head: Optional[torch.Tensor] = None,
|
||||
):
|
||||
super(TextEncoder768, self).__init__()
|
||||
self.out_channels = out_channels
|
||||
self.hidden_channels = hidden_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.n_heads = n_heads
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = float(p_dropout)
|
||||
self.emb_phone = nn.Linear(768, hidden_channels)
|
||||
self.lrelu = nn.LeakyReLU(0.1, inplace=True)
|
||||
if f0 == True:
|
||||
self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
|
||||
self.encoder = attentions.Encoder(
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
float(p_dropout),
|
||||
)
|
||||
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
||||
|
||||
def forward(self, phone: torch.Tensor, pitch: torch.Tensor, lengths: torch.Tensor):
|
||||
if pitch is None:
|
||||
x = self.emb_phone(phone)
|
||||
else:
|
||||
@ -117,8 +69,12 @@ class TextEncoder768(nn.Module):
|
||||
x.dtype
|
||||
)
|
||||
x = self.encoder(x * x_mask, x_mask)
|
||||
if skip_head is not None:
|
||||
assert isinstance(skip_head, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
x = x[:, :, head:]
|
||||
x_mask = x_mask[:, :, head:]
|
||||
stats = self.proj(x) * x_mask
|
||||
|
||||
m, logs = torch.split(stats, self.out_channels, dim=1)
|
||||
return m, logs, x_mask
|
||||
|
||||
@ -293,7 +249,17 @@ class Generator(torch.nn.Module):
|
||||
if gin_channels != 0:
|
||||
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
||||
|
||||
def forward(self, x: torch.Tensor, g: Optional[torch.Tensor] = None):
|
||||
def forward(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
g: Optional[torch.Tensor] = None,
|
||||
n_res: Optional[torch.Tensor] = None,
|
||||
):
|
||||
if n_res is not None:
|
||||
assert isinstance(n_res, torch.Tensor)
|
||||
n = int(n_res.item())
|
||||
if n != x.shape[-1]:
|
||||
x = F.interpolate(x, size=n, mode="linear")
|
||||
x = self.conv_pre(x)
|
||||
if g is not None:
|
||||
x = x + self.cond(g)
|
||||
@ -572,9 +538,22 @@ class GeneratorNSF(torch.nn.Module):
|
||||
|
||||
self.lrelu_slope = modules.LRELU_SLOPE
|
||||
|
||||
def forward(self, x, f0, g: Optional[torch.Tensor] = None):
|
||||
def forward(
|
||||
self,
|
||||
x,
|
||||
f0,
|
||||
g: Optional[torch.Tensor] = None,
|
||||
n_res: Optional[torch.Tensor] = None,
|
||||
):
|
||||
har_source, noi_source, uv = self.m_source(f0, self.upp)
|
||||
har_source = har_source.transpose(1, 2)
|
||||
if n_res is not None:
|
||||
assert isinstance(n_res, torch.Tensor)
|
||||
n = int(n_res.item())
|
||||
if n * self.upp != har_source.shape[-1]:
|
||||
har_source = F.interpolate(har_source, size=n * self.upp, mode="linear")
|
||||
if n != x.shape[-1]:
|
||||
x = F.interpolate(x, size=n, mode="linear")
|
||||
x = self.conv_pre(x)
|
||||
if g is not None:
|
||||
x = x + self.cond(g)
|
||||
@ -601,6 +580,7 @@ class GeneratorNSF(torch.nn.Module):
|
||||
x = F.leaky_relu(x)
|
||||
x = self.conv_post(x)
|
||||
x = torch.tanh(x)
|
||||
|
||||
return x
|
||||
|
||||
def remove_weight_norm(self):
|
||||
@ -682,7 +662,8 @@ class SynthesizerTrnMs256NSFsid(nn.Module):
|
||||
self.gin_channels = gin_channels
|
||||
# self.hop_length = hop_length#
|
||||
self.spk_embed_dim = spk_embed_dim
|
||||
self.enc_p = TextEncoder256(
|
||||
self.enc_p = TextEncoder(
|
||||
256,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
@ -790,24 +771,31 @@ class SynthesizerTrnMs256NSFsid(nn.Module):
|
||||
sid: torch.Tensor,
|
||||
skip_head: Optional[torch.Tensor] = None,
|
||||
return_length: Optional[torch.Tensor] = None,
|
||||
return_length2: Optional[torch.Tensor] = None,
|
||||
):
|
||||
g = self.emb_g(sid).unsqueeze(-1)
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
if skip_head is not None and return_length is not None:
|
||||
assert isinstance(skip_head, torch.Tensor)
|
||||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
flow_head = torch.clamp(skip_head - 24, min=0)
|
||||
dec_head = head - int(flow_head.item())
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths, flow_head)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
z = z[:, :, dec_head : dec_head + length]
|
||||
x_mask = x_mask[:, :, dec_head : dec_head + length]
|
||||
nsff0 = nsff0[:, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, nsff0, g=g)
|
||||
else:
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, nsff0, g=g, n_res=return_length2)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
||||
|
||||
class SynthesizerTrnMs768NSFsid(nn.Module):
|
||||
class SynthesizerTrnMs768NSFsid(SynthesizerTrnMs256NSFsid):
|
||||
def __init__(
|
||||
self,
|
||||
spec_channels,
|
||||
@ -830,28 +818,30 @@ class SynthesizerTrnMs768NSFsid(nn.Module):
|
||||
sr,
|
||||
**kwargs
|
||||
):
|
||||
super(SynthesizerTrnMs768NSFsid, self).__init__()
|
||||
if isinstance(sr, str):
|
||||
sr = sr2sr[sr]
|
||||
self.spec_channels = spec_channels
|
||||
self.inter_channels = inter_channels
|
||||
self.hidden_channels = hidden_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.n_heads = n_heads
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = float(p_dropout)
|
||||
self.resblock = resblock
|
||||
self.resblock_kernel_sizes = resblock_kernel_sizes
|
||||
self.resblock_dilation_sizes = resblock_dilation_sizes
|
||||
self.upsample_rates = upsample_rates
|
||||
self.upsample_initial_channel = upsample_initial_channel
|
||||
self.upsample_kernel_sizes = upsample_kernel_sizes
|
||||
self.segment_size = segment_size
|
||||
self.gin_channels = gin_channels
|
||||
# self.hop_length = hop_length#
|
||||
self.spk_embed_dim = spk_embed_dim
|
||||
self.enc_p = TextEncoder768(
|
||||
super(SynthesizerTrnMs768NSFsid, self).__init__(
|
||||
spec_channels,
|
||||
segment_size,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
p_dropout,
|
||||
resblock,
|
||||
resblock_kernel_sizes,
|
||||
resblock_dilation_sizes,
|
||||
upsample_rates,
|
||||
upsample_initial_channel,
|
||||
upsample_kernel_sizes,
|
||||
spk_embed_dim,
|
||||
gin_channels,
|
||||
sr,
|
||||
**kwargs
|
||||
)
|
||||
del self.enc_p
|
||||
self.enc_p = TextEncoder(
|
||||
768,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
@ -860,113 +850,6 @@ class SynthesizerTrnMs768NSFsid(nn.Module):
|
||||
kernel_size,
|
||||
float(p_dropout),
|
||||
)
|
||||
self.dec = GeneratorNSF(
|
||||
inter_channels,
|
||||
resblock,
|
||||
resblock_kernel_sizes,
|
||||
resblock_dilation_sizes,
|
||||
upsample_rates,
|
||||
upsample_initial_channel,
|
||||
upsample_kernel_sizes,
|
||||
gin_channels=gin_channels,
|
||||
sr=sr,
|
||||
is_half=kwargs["is_half"],
|
||||
)
|
||||
self.enc_q = PosteriorEncoder(
|
||||
spec_channels,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
5,
|
||||
1,
|
||||
16,
|
||||
gin_channels=gin_channels,
|
||||
)
|
||||
self.flow = ResidualCouplingBlock(
|
||||
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
||||
)
|
||||
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
||||
logger.debug(
|
||||
"gin_channels: "
|
||||
+ str(gin_channels)
|
||||
+ ", self.spk_embed_dim: "
|
||||
+ str(self.spk_embed_dim)
|
||||
)
|
||||
|
||||
def remove_weight_norm(self):
|
||||
self.dec.remove_weight_norm()
|
||||
self.flow.remove_weight_norm()
|
||||
if hasattr(self, "enc_q"):
|
||||
self.enc_q.remove_weight_norm()
|
||||
|
||||
def __prepare_scriptable__(self):
|
||||
for hook in self.dec._forward_pre_hooks.values():
|
||||
# The hook we want to remove is an instance of WeightNorm class, so
|
||||
# normally we would do `if isinstance(...)` but this class is not accessible
|
||||
# because of shadowing, so we check the module name directly.
|
||||
# https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.dec)
|
||||
for hook in self.flow._forward_pre_hooks.values():
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.flow)
|
||||
if hasattr(self, "enc_q"):
|
||||
for hook in self.enc_q._forward_pre_hooks.values():
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.enc_q)
|
||||
return self
|
||||
|
||||
@torch.jit.ignore
|
||||
def forward(
|
||||
self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
|
||||
): # 这里ds是id,[bs,1]
|
||||
# print(1,pitch.shape)#[bs,t]
|
||||
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
||||
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
||||
z_p = self.flow(z, y_mask, g=g)
|
||||
z_slice, ids_slice = commons.rand_slice_segments(
|
||||
z, y_lengths, self.segment_size
|
||||
)
|
||||
# print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
|
||||
pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
|
||||
# print(-2,pitchf.shape,z_slice.shape)
|
||||
o = self.dec(z_slice, pitchf, g=g)
|
||||
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
||||
|
||||
@torch.jit.export
|
||||
def infer(
|
||||
self,
|
||||
phone: torch.Tensor,
|
||||
phone_lengths: torch.Tensor,
|
||||
pitch: torch.Tensor,
|
||||
nsff0: torch.Tensor,
|
||||
sid: torch.Tensor,
|
||||
skip_head: Optional[torch.Tensor] = None,
|
||||
return_length: Optional[torch.Tensor] = None,
|
||||
):
|
||||
g = self.emb_g(sid).unsqueeze(-1)
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
if skip_head is not None and return_length is not None:
|
||||
assert isinstance(skip_head, torch.Tensor)
|
||||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
nsff0 = nsff0[:, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, nsff0, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
||||
|
||||
class SynthesizerTrnMs256NSFsid_nono(nn.Module):
|
||||
@ -1011,7 +894,8 @@ class SynthesizerTrnMs256NSFsid_nono(nn.Module):
|
||||
self.gin_channels = gin_channels
|
||||
# self.hop_length = hop_length#
|
||||
self.spk_embed_dim = spk_embed_dim
|
||||
self.enc_p = TextEncoder256(
|
||||
self.enc_p = TextEncoder(
|
||||
256,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
@ -1103,23 +987,30 @@ class SynthesizerTrnMs256NSFsid_nono(nn.Module):
|
||||
sid: torch.Tensor,
|
||||
skip_head: Optional[torch.Tensor] = None,
|
||||
return_length: Optional[torch.Tensor] = None,
|
||||
return_length2: Optional[torch.Tensor] = None,
|
||||
):
|
||||
g = self.emb_g(sid).unsqueeze(-1)
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
if skip_head is not None and return_length is not None:
|
||||
assert isinstance(skip_head, torch.Tensor)
|
||||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, g=g)
|
||||
flow_head = torch.clamp(skip_head - 24, min=0)
|
||||
dec_head = head - int(flow_head.item())
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths, flow_head)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
z = z[:, :, dec_head : dec_head + length]
|
||||
x_mask = x_mask[:, :, dec_head : dec_head + length]
|
||||
else:
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, g=g, n_res=return_length2)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
||||
|
||||
class SynthesizerTrnMs768NSFsid_nono(nn.Module):
|
||||
class SynthesizerTrnMs768NSFsid_nono(SynthesizerTrnMs256NSFsid_nono):
|
||||
def __init__(
|
||||
self,
|
||||
spec_channels,
|
||||
@ -1142,26 +1033,30 @@ class SynthesizerTrnMs768NSFsid_nono(nn.Module):
|
||||
sr=None,
|
||||
**kwargs
|
||||
):
|
||||
super(SynthesizerTrnMs768NSFsid_nono, self).__init__()
|
||||
self.spec_channels = spec_channels
|
||||
self.inter_channels = inter_channels
|
||||
self.hidden_channels = hidden_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.n_heads = n_heads
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = float(p_dropout)
|
||||
self.resblock = resblock
|
||||
self.resblock_kernel_sizes = resblock_kernel_sizes
|
||||
self.resblock_dilation_sizes = resblock_dilation_sizes
|
||||
self.upsample_rates = upsample_rates
|
||||
self.upsample_initial_channel = upsample_initial_channel
|
||||
self.upsample_kernel_sizes = upsample_kernel_sizes
|
||||
self.segment_size = segment_size
|
||||
self.gin_channels = gin_channels
|
||||
# self.hop_length = hop_length#
|
||||
self.spk_embed_dim = spk_embed_dim
|
||||
self.enc_p = TextEncoder768(
|
||||
super(SynthesizerTrnMs768NSFsid_nono, self).__init__(
|
||||
spec_channels,
|
||||
segment_size,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
p_dropout,
|
||||
resblock,
|
||||
resblock_kernel_sizes,
|
||||
resblock_dilation_sizes,
|
||||
upsample_rates,
|
||||
upsample_initial_channel,
|
||||
upsample_kernel_sizes,
|
||||
spk_embed_dim,
|
||||
gin_channels,
|
||||
sr,
|
||||
**kwargs
|
||||
)
|
||||
del self.enc_p
|
||||
self.enc_p = TextEncoder(
|
||||
768,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
@ -1171,102 +1066,6 @@ class SynthesizerTrnMs768NSFsid_nono(nn.Module):
|
||||
float(p_dropout),
|
||||
f0=False,
|
||||
)
|
||||
self.dec = Generator(
|
||||
inter_channels,
|
||||
resblock,
|
||||
resblock_kernel_sizes,
|
||||
resblock_dilation_sizes,
|
||||
upsample_rates,
|
||||
upsample_initial_channel,
|
||||
upsample_kernel_sizes,
|
||||
gin_channels=gin_channels,
|
||||
)
|
||||
self.enc_q = PosteriorEncoder(
|
||||
spec_channels,
|
||||
inter_channels,
|
||||
hidden_channels,
|
||||
5,
|
||||
1,
|
||||
16,
|
||||
gin_channels=gin_channels,
|
||||
)
|
||||
self.flow = ResidualCouplingBlock(
|
||||
inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
|
||||
)
|
||||
self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
|
||||
logger.debug(
|
||||
"gin_channels: "
|
||||
+ str(gin_channels)
|
||||
+ ", self.spk_embed_dim: "
|
||||
+ str(self.spk_embed_dim)
|
||||
)
|
||||
|
||||
def remove_weight_norm(self):
|
||||
self.dec.remove_weight_norm()
|
||||
self.flow.remove_weight_norm()
|
||||
if hasattr(self, "enc_q"):
|
||||
self.enc_q.remove_weight_norm()
|
||||
|
||||
def __prepare_scriptable__(self):
|
||||
for hook in self.dec._forward_pre_hooks.values():
|
||||
# The hook we want to remove is an instance of WeightNorm class, so
|
||||
# normally we would do `if isinstance(...)` but this class is not accessible
|
||||
# because of shadowing, so we check the module name directly.
|
||||
# https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.dec)
|
||||
for hook in self.flow._forward_pre_hooks.values():
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.flow)
|
||||
if hasattr(self, "enc_q"):
|
||||
for hook in self.enc_q._forward_pre_hooks.values():
|
||||
if (
|
||||
hook.__module__ == "torch.nn.utils.weight_norm"
|
||||
and hook.__class__.__name__ == "WeightNorm"
|
||||
):
|
||||
torch.nn.utils.remove_weight_norm(self.enc_q)
|
||||
return self
|
||||
|
||||
@torch.jit.ignore
|
||||
def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
|
||||
g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
||||
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
||||
z_p = self.flow(z, y_mask, g=g)
|
||||
z_slice, ids_slice = commons.rand_slice_segments(
|
||||
z, y_lengths, self.segment_size
|
||||
)
|
||||
o = self.dec(z_slice, g=g)
|
||||
return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
||||
|
||||
@torch.jit.export
|
||||
def infer(
|
||||
self,
|
||||
phone: torch.Tensor,
|
||||
phone_lengths: torch.Tensor,
|
||||
sid: torch.Tensor,
|
||||
skip_head: Optional[torch.Tensor] = None,
|
||||
return_length: Optional[torch.Tensor] = None,
|
||||
):
|
||||
g = self.emb_g(sid).unsqueeze(-1)
|
||||
m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
|
||||
z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
|
||||
if skip_head is not None and return_length is not None:
|
||||
assert isinstance(skip_head, torch.Tensor)
|
||||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
||||
|
||||
class MultiPeriodDiscriminator(torch.nn.Module):
|
||||
|
||||
461
infer/lib/rtrvc.py
Normal file
461
infer/lib/rtrvc.py
Normal file
@ -0,0 +1,461 @@
|
||||
from io import BytesIO
|
||||
import os
|
||||
import sys
|
||||
import traceback
|
||||
from infer.lib import jit
|
||||
from infer.lib.jit.get_synthesizer import get_synthesizer
|
||||
from time import time as ttime
|
||||
import fairseq
|
||||
import faiss
|
||||
import numpy as np
|
||||
import parselmouth
|
||||
import pyworld
|
||||
import scipy.signal as signal
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchcrepe
|
||||
from torchaudio.transforms import Resample
|
||||
|
||||
now_dir = os.getcwd()
|
||||
sys.path.append(now_dir)
|
||||
from multiprocessing import Manager as M
|
||||
|
||||
from configs.config import Config
|
||||
|
||||
# config = Config()
|
||||
|
||||
mm = M()
|
||||
|
||||
|
||||
def printt(strr, *args):
|
||||
if len(args) == 0:
|
||||
print(strr)
|
||||
else:
|
||||
print(strr % args)
|
||||
|
||||
|
||||
# config.device=torch.device("cpu")########强制cpu测试
|
||||
# config.is_half=False########强制cpu测试
|
||||
class RVC:
|
||||
def __init__(
|
||||
self,
|
||||
key,
|
||||
formant,
|
||||
pth_path,
|
||||
index_path,
|
||||
index_rate,
|
||||
n_cpu,
|
||||
inp_q,
|
||||
opt_q,
|
||||
config: Config,
|
||||
last_rvc=None,
|
||||
) -> None:
|
||||
"""
|
||||
初始化
|
||||
"""
|
||||
try:
|
||||
if config.dml == True:
|
||||
|
||||
def forward_dml(ctx, x, scale):
|
||||
ctx.scale = scale
|
||||
res = x.clone().detach()
|
||||
return res
|
||||
|
||||
fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
|
||||
# global config
|
||||
self.config = config
|
||||
self.inp_q = inp_q
|
||||
self.opt_q = opt_q
|
||||
# device="cpu"########强制cpu测试
|
||||
self.device = config.device
|
||||
self.f0_up_key = key
|
||||
self.formant_shift = formant
|
||||
self.f0_min = 50
|
||||
self.f0_max = 1100
|
||||
self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
|
||||
self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
|
||||
self.n_cpu = n_cpu
|
||||
self.use_jit = self.config.use_jit
|
||||
self.is_half = config.is_half
|
||||
|
||||
if index_rate != 0:
|
||||
self.index = faiss.read_index(index_path)
|
||||
self.big_npy = self.index.reconstruct_n(0, self.index.ntotal)
|
||||
printt("Index search enabled")
|
||||
self.pth_path: str = pth_path
|
||||
self.index_path = index_path
|
||||
self.index_rate = index_rate
|
||||
self.cache_pitch: torch.Tensor = torch.zeros(
|
||||
1024, device=self.device, dtype=torch.long
|
||||
)
|
||||
self.cache_pitchf = torch.zeros(
|
||||
1024, device=self.device, dtype=torch.float32
|
||||
)
|
||||
|
||||
self.resample_kernel = {}
|
||||
|
||||
if last_rvc is None:
|
||||
models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
||||
["assets/hubert/hubert_base.pt"],
|
||||
suffix="",
|
||||
)
|
||||
hubert_model = models[0]
|
||||
hubert_model = hubert_model.to(self.device)
|
||||
if self.is_half:
|
||||
hubert_model = hubert_model.half()
|
||||
else:
|
||||
hubert_model = hubert_model.float()
|
||||
hubert_model.eval()
|
||||
self.model = hubert_model
|
||||
else:
|
||||
self.model = last_rvc.model
|
||||
|
||||
self.net_g: nn.Module = None
|
||||
|
||||
def set_default_model():
|
||||
self.net_g, cpt = get_synthesizer(self.pth_path, self.device)
|
||||
self.tgt_sr = cpt["config"][-1]
|
||||
cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0]
|
||||
self.if_f0 = cpt.get("f0", 1)
|
||||
self.version = cpt.get("version", "v1")
|
||||
if self.is_half:
|
||||
self.net_g = self.net_g.half()
|
||||
else:
|
||||
self.net_g = self.net_g.float()
|
||||
|
||||
def set_jit_model():
|
||||
jit_pth_path = self.pth_path.rstrip(".pth")
|
||||
jit_pth_path += ".half.jit" if self.is_half else ".jit"
|
||||
reload = False
|
||||
if str(self.device) == "cuda":
|
||||
self.device = torch.device("cuda:0")
|
||||
if os.path.exists(jit_pth_path):
|
||||
cpt = jit.load(jit_pth_path)
|
||||
model_device = cpt["device"]
|
||||
if model_device != str(self.device):
|
||||
reload = True
|
||||
else:
|
||||
reload = True
|
||||
|
||||
if reload:
|
||||
cpt = jit.synthesizer_jit_export(
|
||||
self.pth_path,
|
||||
"script",
|
||||
None,
|
||||
device=self.device,
|
||||
is_half=self.is_half,
|
||||
)
|
||||
|
||||
self.tgt_sr = cpt["config"][-1]
|
||||
self.if_f0 = cpt.get("f0", 1)
|
||||
self.version = cpt.get("version", "v1")
|
||||
self.net_g = torch.jit.load(
|
||||
BytesIO(cpt["model"]), map_location=self.device
|
||||
)
|
||||
self.net_g.infer = self.net_g.forward
|
||||
self.net_g.eval().to(self.device)
|
||||
|
||||
def set_synthesizer():
|
||||
if self.use_jit and not config.dml:
|
||||
if self.is_half and "cpu" in str(self.device):
|
||||
printt(
|
||||
"Use default Synthesizer model. \
|
||||
Jit is not supported on the CPU for half floating point"
|
||||
)
|
||||
set_default_model()
|
||||
else:
|
||||
set_jit_model()
|
||||
else:
|
||||
set_default_model()
|
||||
|
||||
if last_rvc is None or last_rvc.pth_path != self.pth_path:
|
||||
set_synthesizer()
|
||||
else:
|
||||
self.tgt_sr = last_rvc.tgt_sr
|
||||
self.if_f0 = last_rvc.if_f0
|
||||
self.version = last_rvc.version
|
||||
self.is_half = last_rvc.is_half
|
||||
if last_rvc.use_jit != self.use_jit:
|
||||
set_synthesizer()
|
||||
else:
|
||||
self.net_g = last_rvc.net_g
|
||||
|
||||
if last_rvc is not None and hasattr(last_rvc, "model_rmvpe"):
|
||||
self.model_rmvpe = last_rvc.model_rmvpe
|
||||
if last_rvc is not None and hasattr(last_rvc, "model_fcpe"):
|
||||
self.device_fcpe = last_rvc.device_fcpe
|
||||
self.model_fcpe = last_rvc.model_fcpe
|
||||
except:
|
||||
printt(traceback.format_exc())
|
||||
|
||||
def change_key(self, new_key):
|
||||
self.f0_up_key = new_key
|
||||
|
||||
def change_formant(self, new_formant):
|
||||
self.formant_shift = new_formant
|
||||
|
||||
def change_index_rate(self, new_index_rate):
|
||||
if new_index_rate != 0 and self.index_rate == 0:
|
||||
self.index = faiss.read_index(self.index_path)
|
||||
self.big_npy = self.index.reconstruct_n(0, self.index.ntotal)
|
||||
printt("Index search enabled")
|
||||
self.index_rate = new_index_rate
|
||||
|
||||
def get_f0_post(self, f0):
|
||||
if not torch.is_tensor(f0):
|
||||
f0 = torch.from_numpy(f0)
|
||||
f0 = f0.float().to(self.device).squeeze()
|
||||
f0_mel = 1127 * torch.log(1 + f0 / 700)
|
||||
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * 254 / (
|
||||
self.f0_mel_max - self.f0_mel_min
|
||||
) + 1
|
||||
f0_mel[f0_mel <= 1] = 1
|
||||
f0_mel[f0_mel > 255] = 255
|
||||
f0_coarse = torch.round(f0_mel).long()
|
||||
return f0_coarse, f0
|
||||
|
||||
def get_f0(self, x, f0_up_key, n_cpu, method="harvest"):
|
||||
n_cpu = int(n_cpu)
|
||||
if method == "crepe":
|
||||
return self.get_f0_crepe(x, f0_up_key)
|
||||
if method == "rmvpe":
|
||||
return self.get_f0_rmvpe(x, f0_up_key)
|
||||
if method == "fcpe":
|
||||
return self.get_f0_fcpe(x, f0_up_key)
|
||||
x = x.cpu().numpy()
|
||||
if method == "pm":
|
||||
p_len = x.shape[0] // 160 + 1
|
||||
f0_min = 65
|
||||
l_pad = int(np.ceil(1.5 / f0_min * 16000))
|
||||
r_pad = l_pad + 1
|
||||
s = parselmouth.Sound(np.pad(x, (l_pad, r_pad)), 16000).to_pitch_ac(
|
||||
time_step=0.01,
|
||||
voicing_threshold=0.6,
|
||||
pitch_floor=f0_min,
|
||||
pitch_ceiling=1100,
|
||||
)
|
||||
assert np.abs(s.t1 - 1.5 / f0_min) < 0.001
|
||||
f0 = s.selected_array["frequency"]
|
||||
if len(f0) < p_len:
|
||||
f0 = np.pad(f0, (0, p_len - len(f0)))
|
||||
f0 = f0[:p_len]
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
if n_cpu == 1:
|
||||
f0, t = pyworld.harvest(
|
||||
x.astype(np.double),
|
||||
fs=16000,
|
||||
f0_ceil=1100,
|
||||
f0_floor=50,
|
||||
frame_period=10,
|
||||
)
|
||||
f0 = signal.medfilt(f0, 3)
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
f0bak = np.zeros(x.shape[0] // 160 + 1, dtype=np.float64)
|
||||
length = len(x)
|
||||
part_length = 160 * ((length // 160 - 1) // n_cpu + 1)
|
||||
n_cpu = (length // 160 - 1) // (part_length // 160) + 1
|
||||
ts = ttime()
|
||||
res_f0 = mm.dict()
|
||||
for idx in range(n_cpu):
|
||||
tail = part_length * (idx + 1) + 320
|
||||
if idx == 0:
|
||||
self.inp_q.put((idx, x[:tail], res_f0, n_cpu, ts))
|
||||
else:
|
||||
self.inp_q.put(
|
||||
(idx, x[part_length * idx - 320 : tail], res_f0, n_cpu, ts)
|
||||
)
|
||||
while 1:
|
||||
res_ts = self.opt_q.get()
|
||||
if res_ts == ts:
|
||||
break
|
||||
f0s = [i[1] for i in sorted(res_f0.items(), key=lambda x: x[0])]
|
||||
for idx, f0 in enumerate(f0s):
|
||||
if idx == 0:
|
||||
f0 = f0[:-3]
|
||||
elif idx != n_cpu - 1:
|
||||
f0 = f0[2:-3]
|
||||
else:
|
||||
f0 = f0[2:]
|
||||
f0bak[part_length * idx // 160 : part_length * idx // 160 + f0.shape[0]] = (
|
||||
f0
|
||||
)
|
||||
f0bak = signal.medfilt(f0bak, 3)
|
||||
f0bak *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0bak)
|
||||
|
||||
def get_f0_crepe(self, x, f0_up_key):
|
||||
if "privateuseone" in str(
|
||||
self.device
|
||||
): ###不支持dml,cpu又太慢用不成,拿fcpe顶替
|
||||
return self.get_f0(x, f0_up_key, 1, "fcpe")
|
||||
# printt("using crepe,device:%s"%self.device)
|
||||
f0, pd = torchcrepe.predict(
|
||||
x.unsqueeze(0).float(),
|
||||
16000,
|
||||
160,
|
||||
self.f0_min,
|
||||
self.f0_max,
|
||||
"full",
|
||||
batch_size=512,
|
||||
# device=self.device if self.device.type!="privateuseone" else "cpu",###crepe不用半精度全部是全精度所以不愁###cpu延迟高到没法用
|
||||
device=self.device,
|
||||
return_periodicity=True,
|
||||
)
|
||||
pd = torchcrepe.filter.median(pd, 3)
|
||||
f0 = torchcrepe.filter.mean(f0, 3)
|
||||
f0[pd < 0.1] = 0
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
|
||||
def get_f0_rmvpe(self, x, f0_up_key):
|
||||
if hasattr(self, "model_rmvpe") == False:
|
||||
from infer.lib.rmvpe import RMVPE
|
||||
|
||||
printt("Loading rmvpe model")
|
||||
self.model_rmvpe = RMVPE(
|
||||
"assets/rmvpe/rmvpe.pt",
|
||||
is_half=self.is_half,
|
||||
device=self.device,
|
||||
use_jit=self.config.use_jit,
|
||||
)
|
||||
f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
|
||||
def get_f0_fcpe(self, x, f0_up_key):
|
||||
if hasattr(self, "model_fcpe") == False:
|
||||
from torchfcpe import spawn_bundled_infer_model
|
||||
|
||||
printt("Loading fcpe model")
|
||||
if "privateuseone" in str(self.device):
|
||||
self.device_fcpe = "cpu"
|
||||
else:
|
||||
self.device_fcpe = self.device
|
||||
self.model_fcpe = spawn_bundled_infer_model(self.device_fcpe)
|
||||
f0 = self.model_fcpe.infer(
|
||||
x.to(self.device_fcpe).unsqueeze(0).float(),
|
||||
sr=16000,
|
||||
decoder_mode="local_argmax",
|
||||
threshold=0.006,
|
||||
)
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
|
||||
def infer(
|
||||
self,
|
||||
input_wav: torch.Tensor,
|
||||
block_frame_16k,
|
||||
skip_head,
|
||||
return_length,
|
||||
f0method,
|
||||
) -> np.ndarray:
|
||||
t1 = ttime()
|
||||
with torch.no_grad():
|
||||
if self.config.is_half:
|
||||
feats = input_wav.half().view(1, -1)
|
||||
else:
|
||||
feats = input_wav.float().view(1, -1)
|
||||
padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False)
|
||||
inputs = {
|
||||
"source": feats,
|
||||
"padding_mask": padding_mask,
|
||||
"output_layer": 9 if self.version == "v1" else 12,
|
||||
}
|
||||
logits = self.model.extract_features(**inputs)
|
||||
feats = (
|
||||
self.model.final_proj(logits[0]) if self.version == "v1" else logits[0]
|
||||
)
|
||||
feats = torch.cat((feats, feats[:, -1:, :]), 1)
|
||||
t2 = ttime()
|
||||
try:
|
||||
if hasattr(self, "index") and self.index_rate != 0:
|
||||
npy = feats[0][skip_head // 2 :].cpu().numpy().astype("float32")
|
||||
score, ix = self.index.search(npy, k=8)
|
||||
if (ix >= 0).all():
|
||||
weight = np.square(1 / score)
|
||||
weight /= weight.sum(axis=1, keepdims=True)
|
||||
npy = np.sum(
|
||||
self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1
|
||||
)
|
||||
if self.config.is_half:
|
||||
npy = npy.astype("float16")
|
||||
feats[0][skip_head // 2 :] = (
|
||||
torch.from_numpy(npy).unsqueeze(0).to(self.device)
|
||||
* self.index_rate
|
||||
+ (1 - self.index_rate) * feats[0][skip_head // 2 :]
|
||||
)
|
||||
else:
|
||||
printt(
|
||||
"Invalid index. You MUST use added_xxxx.index but not trained_xxxx.index!"
|
||||
)
|
||||
else:
|
||||
printt("Index search FAILED or disabled")
|
||||
except:
|
||||
traceback.print_exc()
|
||||
printt("Index search FAILED")
|
||||
t3 = ttime()
|
||||
p_len = input_wav.shape[0] // 160
|
||||
factor = pow(2, self.formant_shift / 12)
|
||||
return_length2 = int(np.ceil(return_length * factor))
|
||||
if self.if_f0 == 1:
|
||||
f0_extractor_frame = block_frame_16k + 800
|
||||
if f0method == "rmvpe":
|
||||
f0_extractor_frame = 5120 * ((f0_extractor_frame - 1) // 5120 + 1) - 160
|
||||
pitch, pitchf = self.get_f0(
|
||||
input_wav[-f0_extractor_frame:], self.f0_up_key - self.formant_shift, self.n_cpu, f0method
|
||||
)
|
||||
shift = block_frame_16k // 160
|
||||
self.cache_pitch[:-shift] = self.cache_pitch[shift:].clone()
|
||||
self.cache_pitchf[:-shift] = self.cache_pitchf[shift:].clone()
|
||||
self.cache_pitch[4 - pitch.shape[0] :] = pitch[3:-1]
|
||||
self.cache_pitchf[4 - pitch.shape[0] :] = pitchf[3:-1]
|
||||
cache_pitch = self.cache_pitch[None, -p_len:]
|
||||
cache_pitchf = self.cache_pitchf[None, -p_len:] * return_length2 / return_length
|
||||
t4 = ttime()
|
||||
feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
|
||||
feats = feats[:, :p_len, :]
|
||||
p_len = torch.LongTensor([p_len]).to(self.device)
|
||||
sid = torch.LongTensor([0]).to(self.device)
|
||||
skip_head = torch.LongTensor([skip_head])
|
||||
return_length2 = torch.LongTensor([return_length2])
|
||||
return_length = torch.LongTensor([return_length])
|
||||
with torch.no_grad():
|
||||
if self.if_f0 == 1:
|
||||
infered_audio, _, _ = self.net_g.infer(
|
||||
feats,
|
||||
p_len,
|
||||
cache_pitch,
|
||||
cache_pitchf,
|
||||
sid,
|
||||
skip_head,
|
||||
return_length,
|
||||
return_length2,
|
||||
)
|
||||
else:
|
||||
infered_audio, _, _ = self.net_g.infer(
|
||||
feats, p_len, sid, skip_head, return_length, return_length2
|
||||
)
|
||||
infered_audio = infered_audio.squeeze(1).float()
|
||||
upp_res = int(np.floor(factor * self.tgt_sr // 100))
|
||||
if upp_res != self.tgt_sr // 100:
|
||||
if upp_res not in self.resample_kernel:
|
||||
self.resample_kernel[upp_res] = Resample(
|
||||
orig_freq=upp_res,
|
||||
new_freq=self.tgt_sr // 100,
|
||||
dtype=torch.float32,
|
||||
).to(self.device)
|
||||
infered_audio = self.resample_kernel[upp_res](
|
||||
infered_audio[:, : return_length * upp_res]
|
||||
)
|
||||
t5 = ttime()
|
||||
printt(
|
||||
"Spent time: fea = %.3fs, index = %.3fs, f0 = %.3fs, model = %.3fs",
|
||||
t2 - t1,
|
||||
t3 - t2,
|
||||
t4 - t3,
|
||||
t5 - t4,
|
||||
)
|
||||
return infered_audio.squeeze()
|
||||
3642
poetry.lock
generated
Normal file
3642
poetry.lock
generated
Normal file
File diff suppressed because it is too large
Load Diff
64
pyproject.toml
Normal file
64
pyproject.toml
Normal file
@ -0,0 +1,64 @@
|
||||
[tool.poetry]
|
||||
name = "rvc-beta"
|
||||
version = "0.1.0"
|
||||
description = ""
|
||||
authors = ["lj1995"]
|
||||
license = "MIT"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.8"
|
||||
torch = "^2.0.0"
|
||||
torchaudio = "^2.0.1"
|
||||
Cython = "^0.29.34"
|
||||
gradio = "^4.11.0"
|
||||
future = "^0.18.3"
|
||||
pydub = "^0.25.1"
|
||||
soundfile = "^0.12.1"
|
||||
ffmpeg-python = "^0.2.0"
|
||||
tensorboardX = "^2.6"
|
||||
functorch = "^2.0.0"
|
||||
fairseq = "^0.12.2"
|
||||
faiss-cpu = "^1.7.2"
|
||||
Jinja2 = "^3.1.2"
|
||||
json5 = "^0.9.11"
|
||||
librosa = "0.9.1"
|
||||
llvmlite = "0.39.0"
|
||||
Markdown = "^3.4.3"
|
||||
matplotlib = "^3.7.1"
|
||||
matplotlib-inline = "^0.1.6"
|
||||
numba = "0.56.4"
|
||||
numpy = "1.23.5"
|
||||
scipy = "1.9.3"
|
||||
praat-parselmouth = "^0.4.3"
|
||||
Pillow = "9.3.0"
|
||||
pyworld = "^0.3.2"
|
||||
resampy = "^0.4.2"
|
||||
scikit-learn = "^1.2.2"
|
||||
starlette = "^0.27.0"
|
||||
tensorboard = "^2.12.1"
|
||||
tensorboard-data-server = "^0.7.0"
|
||||
tensorboard-plugin-wit = "^1.8.1"
|
||||
torchgen = "^0.0.1"
|
||||
tqdm = "^4.65.0"
|
||||
tornado = "^6.3"
|
||||
Werkzeug = "^2.2.3"
|
||||
uc-micro-py = "^1.0.1"
|
||||
sympy = "^1.11.1"
|
||||
tabulate = "^0.9.0"
|
||||
PyYAML = "^6.0"
|
||||
pyasn1 = "^0.4.8"
|
||||
pyasn1-modules = "^0.2.8"
|
||||
fsspec = "^2023.3.0"
|
||||
absl-py = "^1.4.0"
|
||||
audioread = "^3.0.0"
|
||||
uvicorn = "^0.21.1"
|
||||
colorama = "^0.4.6"
|
||||
torchcrepe = "0.0.20"
|
||||
python-dotenv = "^1.0.0"
|
||||
av = "^10.0.0"
|
||||
|
||||
[tool.poetry.dev-dependencies]
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core>=1.0.0"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
Loading…
x
Reference in New Issue
Block a user