Merge pull request #1850 from RVC-Project/dev
chore(sync): merge dev into main
This commit is contained in:
commit
c22b912576
1
.env
1
.env
@ -5,4 +5,5 @@ no_proxy = localhost, 127.0.0.1, ::1
|
|||||||
weight_root = assets/weights
|
weight_root = assets/weights
|
||||||
weight_uvr5_root = assets/uvr5_weights
|
weight_uvr5_root = assets/uvr5_weights
|
||||||
index_root = logs
|
index_root = logs
|
||||||
|
outside_index_root = assets/indices
|
||||||
rmvpe_root = assets/rmvpe
|
rmvpe_root = assets/rmvpe
|
||||||
|
|||||||
2
.github/workflows/unitest.yml
vendored
2
.github/workflows/unitest.yml
vendored
@ -33,4 +33,4 @@ jobs:
|
|||||||
python infer/modules/train/preprocess.py logs/mute/0_gt_wavs 48000 8 logs/mi-test True 3.7
|
python infer/modules/train/preprocess.py logs/mute/0_gt_wavs 48000 8 logs/mi-test True 3.7
|
||||||
touch logs/mi-test/extract_f0_feature.log
|
touch logs/mi-test/extract_f0_feature.log
|
||||||
python infer/modules/train/extract/extract_f0_print.py logs/mi-test $(nproc) pm
|
python infer/modules/train/extract/extract_f0_print.py logs/mi-test $(nproc) pm
|
||||||
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1
|
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1 True
|
||||||
|
|||||||
5
.gitignore
vendored
5
.gitignore
vendored
@ -21,3 +21,8 @@ rmvpe.pt
|
|||||||
|
|
||||||
# To set a Python version for the project
|
# To set a Python version for the project
|
||||||
.tool-versions
|
.tool-versions
|
||||||
|
|
||||||
|
/runtime
|
||||||
|
/assets/weights/*
|
||||||
|
ffmpeg.*
|
||||||
|
ffprobe.*
|
||||||
185
README.md
185
README.md
@ -14,35 +14,28 @@
|
|||||||
|
|
||||||
[](https://discord.gg/HcsmBBGyVk)
|
[](https://discord.gg/HcsmBBGyVk)
|
||||||
|
|
||||||
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md)| [**Türkçe**](./docs/tr/README.tr.md)
|
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md)| [**Türkçe**](./docs/tr/README.tr.md)
|
||||||
|
|
||||||
</div>
|
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||||
|
|
||||||
|
训练推理界面:go-web.bat
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
实时变声界面:go-realtime-gui.bat
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
||||||
|
|
||||||
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
||||||
|
|
||||||
<table>
|
|
||||||
<tr>
|
|
||||||
<td align="center">训练推理界面</td>
|
|
||||||
<td align="center">实时变声界面</td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
|
||||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
<td align="center">go-web.bat</td>
|
|
||||||
<td align="center">go-realtime-gui.bat</td>
|
|
||||||
</tr>
|
|
||||||
<tr>
|
|
||||||
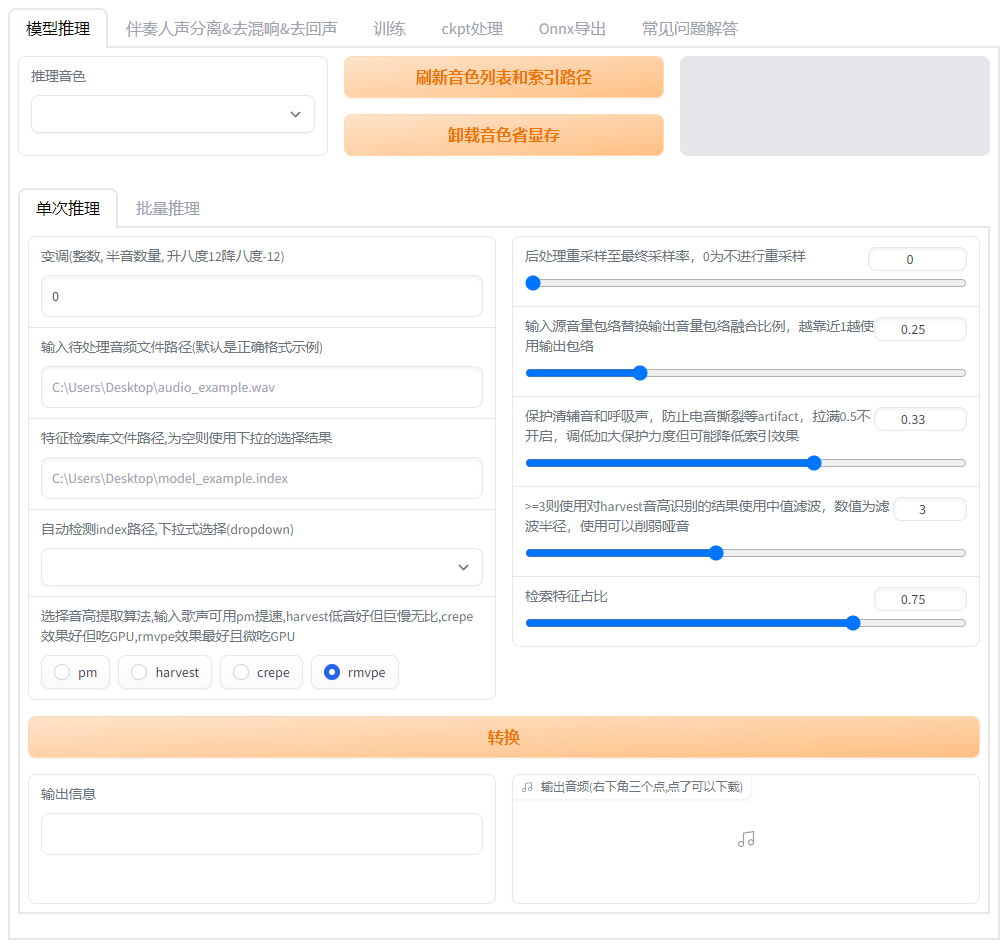
<td align="center">可以自由选择想要执行的操作。</td>
|
|
||||||
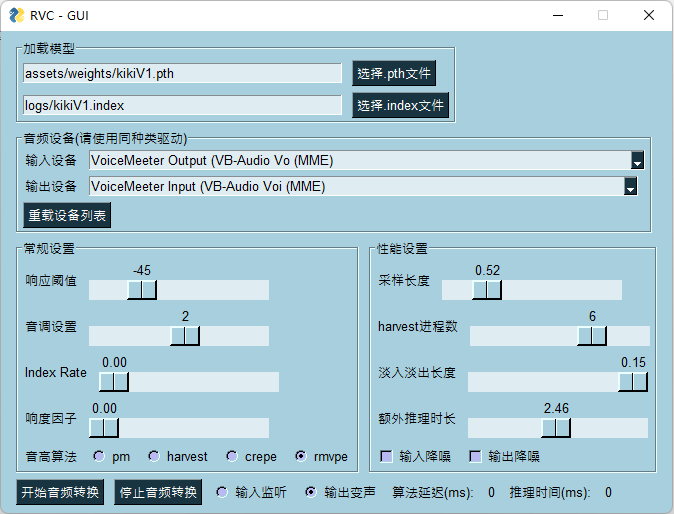
<td align="center">我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。</td>
|
|
||||||
</tr>
|
|
||||||
</table>
|
|
||||||
|
|
||||||
## 简介
|
## 简介
|
||||||
本仓库具有以下特点
|
本仓库具有以下特点
|
||||||
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
||||||
@ -54,52 +47,47 @@
|
|||||||
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
|
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
|
||||||
+ A卡I卡加速支持
|
+ A卡I卡加速支持
|
||||||
|
|
||||||
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
|
||||||
|
|
||||||
## 环境配置
|
## 环境配置
|
||||||
以下指令需在 Python 版本大于3.8的环境中执行。
|
以下指令需在 Python 版本大于3.8的环境中执行。
|
||||||
|
|
||||||
### Windows/Linux/MacOS等平台通用方法
|
(Windows/Linux)
|
||||||
下列方法任选其一。
|
首先通过 pip 安装主要依赖:
|
||||||
#### 1. 通过 pip 安装依赖
|
|
||||||
1. 安装Pytorch及其核心依赖,若已安装则跳过。参考自: https://pytorch.org/get-started/locally/
|
|
||||||
```bash
|
```bash
|
||||||
|
# 安装Pytorch及其核心依赖,若已安装则跳过
|
||||||
|
# 参考自: https://pytorch.org/get-started/locally/
|
||||||
pip install torch torchvision torchaudio
|
pip install torch torchvision torchaudio
|
||||||
```
|
|
||||||
2. 如果是 win 系统 + Nvidia Ampere 架构(RTX30xx),根据 #21 的经验,需要指定 pytorch 对应的 cuda 版本
|
#如果是win系统+Nvidia Ampere架构(RTX30xx),根据 #21 的经验,需要指定pytorch对应的cuda版本
|
||||||
```bash
|
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
|
||||||
```
|
|
||||||
3. 根据自己的显卡安装对应依赖
|
|
||||||
- N卡
|
|
||||||
```bash
|
|
||||||
pip install -r requirements.txt
|
|
||||||
```
|
|
||||||
- A卡/I卡
|
|
||||||
```bash
|
|
||||||
pip install -r requirements-dml.txt
|
|
||||||
```
|
|
||||||
- A卡ROCM(Linux)
|
|
||||||
```bash
|
|
||||||
pip install -r requirements-amd.txt
|
|
||||||
```
|
|
||||||
- I卡IPEX(Linux)
|
|
||||||
```bash
|
|
||||||
pip install -r requirements-ipex.txt
|
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 2. 通过 poetry 来安装依赖
|
可以使用 poetry 来安装依赖:
|
||||||
安装 Poetry 依赖管理工具,若已安装则跳过。参考自: https://python-poetry.org/docs/#installation
|
|
||||||
```bash
|
```bash
|
||||||
|
# 安装 Poetry 依赖管理工具, 若已安装则跳过
|
||||||
|
# 参考自: https://python-poetry.org/docs/#installation
|
||||||
curl -sSL https://install.python-poetry.org | python3 -
|
curl -sSL https://install.python-poetry.org | python3 -
|
||||||
```
|
|
||||||
通过poetry安装依赖
|
# 通过poetry安装依赖
|
||||||
```bash
|
|
||||||
poetry install
|
poetry install
|
||||||
```
|
```
|
||||||
|
|
||||||
### MacOS
|
你也可以通过 pip 来安装依赖:
|
||||||
可以通过 `run.sh` 来安装依赖
|
```bash
|
||||||
|
N卡:
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
A卡/I卡:
|
||||||
|
pip install -r requirements-dml.txt
|
||||||
|
|
||||||
|
A卡Rocm(Linux):
|
||||||
|
pip install -r requirements-amd.txt
|
||||||
|
|
||||||
|
I卡IPEX(Linux):
|
||||||
|
pip install -r requirements-ipex.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
------
|
||||||
|
Mac 用户可以通过 `run.sh` 来安装依赖:
|
||||||
```bash
|
```bash
|
||||||
sh ./run.sh
|
sh ./run.sh
|
||||||
```
|
```
|
||||||
@ -109,48 +97,48 @@ RVC需要其他一些预模型来推理和训练。
|
|||||||
|
|
||||||
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
|
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
|
||||||
|
|
||||||
### 1. 下载 assets
|
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称:
|
||||||
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。你可以在`tools`文件夹找到下载它们的脚本。
|
|
||||||
|
|
||||||
- ./assets/hubert/hubert_base.pt
|
|
||||||
|
|
||||||
- ./assets/pretrained
|
|
||||||
|
|
||||||
- ./assets/uvr5_weights
|
|
||||||
|
|
||||||
想使用v2版本模型的话,需要额外下载
|
|
||||||
|
|
||||||
- ./assets/pretrained_v2
|
|
||||||
|
|
||||||
### 2. 安装 ffmpeg
|
|
||||||
若ffmpeg和ffprobe已安装则跳过。
|
|
||||||
|
|
||||||
#### Ubuntu/Debian 用户
|
|
||||||
```bash
|
```bash
|
||||||
sudo apt install ffmpeg
|
./assets/hubert/hubert_base.pt
|
||||||
|
|
||||||
|
./assets/pretrained
|
||||||
|
|
||||||
|
./assets/uvr5_weights
|
||||||
|
|
||||||
|
想测试v2版本模型的话,需要额外下载
|
||||||
|
|
||||||
|
./assets/pretrained_v2
|
||||||
|
|
||||||
|
如果你正在使用Windows,则你可能需要这个文件,若ffmpeg和ffprobe已安装则跳过; ubuntu/debian 用户可以通过apt install ffmpeg来安装这2个库, Mac 用户则可以通过brew install ffmpeg来安装 (需要预先安装brew)
|
||||||
|
|
||||||
|
./ffmpeg
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||||
|
|
||||||
|
./ffprobe
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||||
|
|
||||||
|
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||||
|
|
||||||
|
A卡I卡用户需要的dml环境要请下载
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||||
|
|
||||||
```
|
```
|
||||||
#### MacOS 用户
|
之后使用以下指令来启动WebUI:
|
||||||
```bash
|
```bash
|
||||||
brew install ffmpeg
|
python infer-web.py
|
||||||
```
|
```
|
||||||
#### Windwos 用户
|
如果你正在使用Windows 或 macOS,你可以直接下载并解压`RVC-beta.7z`,前者可以运行`go-web.bat`以启动WebUI,后者则运行命令`sh ./run.sh`以启动WebUI。
|
||||||
下载后放置在根目录。
|
|
||||||
- 下载[ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
|
||||||
|
|
||||||
- 下载[ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
对于需要使用IPEX技术的I卡用户,请先在终端执行`source /opt/intel/oneapi/setvars.sh`(仅Linux)。
|
||||||
|
|
||||||
### 3. 下载 rmvpe 人声音高提取算法所需文件
|
仓库内还有一份`小白简易教程.doc`以供参考。
|
||||||
|
|
||||||
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录。
|
|
||||||
|
|
||||||
- 下载[rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
|
||||||
|
|
||||||
#### 下载 rmvpe 的 dml 环境(可选, A卡/I卡用户)
|
|
||||||
|
|
||||||
- 下载[rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
|
||||||
|
|
||||||
### 4. AMD显卡Rocm(可选, 仅Linux)
|
|
||||||
|
|
||||||
|
## AMD显卡Rocm相关(仅Linux)
|
||||||
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
||||||
|
|
||||||
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
||||||
@ -167,25 +155,10 @@ export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
|||||||
sudo usermod -aG render $USERNAME
|
sudo usermod -aG render $USERNAME
|
||||||
sudo usermod -aG video $USERNAME
|
sudo usermod -aG video $USERNAME
|
||||||
````
|
````
|
||||||
|
之后运行WebUI:
|
||||||
## 开始使用
|
|
||||||
### 直接启动
|
|
||||||
使用以下指令来启动 WebUI
|
|
||||||
```bash
|
```bash
|
||||||
python infer-web.py
|
python infer-web.py
|
||||||
```
|
```
|
||||||
### 使用整合包
|
|
||||||
下载并解压`RVC-beta.7z`
|
|
||||||
#### Windows 用户
|
|
||||||
双击`go-web.bat`
|
|
||||||
#### MacOS 用户
|
|
||||||
```bash
|
|
||||||
sh ./run.sh
|
|
||||||
```
|
|
||||||
### 对于需要使用IPEX技术的I卡用户(仅Linux)
|
|
||||||
```bash
|
|
||||||
source /opt/intel/oneapi/setvars.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
## 参考项目
|
## 参考项目
|
||||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||||
|
|||||||
@ -290,7 +290,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
||||||
"\n",
|
"\n",
|
||||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@ -309,7 +309,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
||||||
"\n",
|
"\n",
|
||||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
2
assets/indices/.gitignore
vendored
Normal file
2
assets/indices/.gitignore
vendored
Normal file
@ -0,0 +1,2 @@
|
|||||||
|
*
|
||||||
|
!.gitignore
|
||||||
@ -1 +1 @@
|
|||||||
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_input_device": "VoiceMeeter Output (VB-Audio Vo (MME)", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi (MME)", "sr_type": "sr_model", "threhold": -60.0, "pitch": 12.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.2, "crossfade_length": 0.08, "extra_time": 2.00, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_hostapi": "MME", "sg_wasapi_exclusive": false, "sg_input_device": "VoiceMeeter Output (VB-Audio Vo", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi", "sr_type": "sr_device", "threhold": -60.0, "pitch": 12.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.15, "crossfade_length": 0.08, "extra_time": 2.0, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
||||||
@ -2,6 +2,7 @@ import argparse
|
|||||||
import os
|
import os
|
||||||
import sys
|
import sys
|
||||||
import json
|
import json
|
||||||
|
import shutil
|
||||||
from multiprocessing import cpu_count
|
from multiprocessing import cpu_count
|
||||||
|
|
||||||
import torch
|
import torch
|
||||||
@ -58,13 +59,17 @@ class Config:
|
|||||||
self.dml,
|
self.dml,
|
||||||
) = self.arg_parse()
|
) = self.arg_parse()
|
||||||
self.instead = ""
|
self.instead = ""
|
||||||
|
self.preprocess_per = 3.7
|
||||||
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def load_config_json() -> dict:
|
def load_config_json() -> dict:
|
||||||
d = {}
|
d = {}
|
||||||
for config_file in version_config_list:
|
for config_file in version_config_list:
|
||||||
with open(f"configs/{config_file}", "r") as f:
|
p = f"configs/inuse/{config_file}"
|
||||||
|
if not os.path.exists(p):
|
||||||
|
shutil.copy(f"configs/{config_file}", p)
|
||||||
|
with open(f"configs/inuse/{config_file}", "r") as f:
|
||||||
d[config_file] = json.load(f)
|
d[config_file] = json.load(f)
|
||||||
return d
|
return d
|
||||||
|
|
||||||
@ -123,15 +128,13 @@ class Config:
|
|||||||
def use_fp32_config(self):
|
def use_fp32_config(self):
|
||||||
for config_file in version_config_list:
|
for config_file in version_config_list:
|
||||||
self.json_config[config_file]["train"]["fp16_run"] = False
|
self.json_config[config_file]["train"]["fp16_run"] = False
|
||||||
with open(f"configs/{config_file}", "r") as f:
|
with open(f"configs/inuse/{config_file}", "r") as f:
|
||||||
strr = f.read().replace("true", "false")
|
strr = f.read().replace("true", "false")
|
||||||
with open(f"configs/{config_file}", "w") as f:
|
with open(f"configs/inuse/{config_file}", "w") as f:
|
||||||
f.write(strr)
|
f.write(strr)
|
||||||
with open("infer/modules/train/preprocess.py", "r") as f:
|
logger.info("overwrite " + config_file)
|
||||||
strr = f.read().replace("3.7", "3.0")
|
self.preprocess_per = 3.0
|
||||||
with open("infer/modules/train/preprocess.py", "w") as f:
|
logger.info("overwrite preprocess_per to %d" % (self.preprocess_per))
|
||||||
f.write(strr)
|
|
||||||
print("overwrite preprocess and configs.json")
|
|
||||||
|
|
||||||
def device_config(self) -> tuple:
|
def device_config(self) -> tuple:
|
||||||
if torch.cuda.is_available():
|
if torch.cuda.is_available():
|
||||||
@ -161,10 +164,7 @@ class Config:
|
|||||||
+ 0.4
|
+ 0.4
|
||||||
)
|
)
|
||||||
if self.gpu_mem <= 4:
|
if self.gpu_mem <= 4:
|
||||||
with open("infer/modules/train/preprocess.py", "r") as f:
|
self.preprocess_per = 3.0
|
||||||
strr = f.read().replace("3.7", "3.0")
|
|
||||||
with open("infer/modules/train/preprocess.py", "w") as f:
|
|
||||||
f.write(strr)
|
|
||||||
elif self.has_mps():
|
elif self.has_mps():
|
||||||
logger.info("No supported Nvidia GPU found")
|
logger.info("No supported Nvidia GPU found")
|
||||||
self.device = self.instead = "mps"
|
self.device = self.instead = "mps"
|
||||||
@ -247,5 +247,8 @@ class Config:
|
|||||||
)
|
)
|
||||||
except:
|
except:
|
||||||
pass
|
pass
|
||||||
print("is_half:%s, device:%s" % (self.is_half, self.device))
|
logger.info(
|
||||||
|
"Half-precision floating-point: %s, device: %s"
|
||||||
|
% (self.is_half, self.device)
|
||||||
|
)
|
||||||
return x_pad, x_query, x_center, x_max
|
return x_pad, x_query, x_center, x_max
|
||||||
|
|||||||
4
configs/inuse/.gitignore
vendored
Normal file
4
configs/inuse/.gitignore
vendored
Normal file
@ -0,0 +1,4 @@
|
|||||||
|
*
|
||||||
|
!.gitignore
|
||||||
|
!v1
|
||||||
|
!v2
|
||||||
2
configs/inuse/v1/.gitignore
vendored
Normal file
2
configs/inuse/v1/.gitignore
vendored
Normal file
@ -0,0 +1,2 @@
|
|||||||
|
*
|
||||||
|
!.gitignore
|
||||||
2
configs/inuse/v2/.gitignore
vendored
Normal file
2
configs/inuse/v2/.gitignore
vendored
Normal file
@ -0,0 +1,2 @@
|
|||||||
|
*
|
||||||
|
!.gitignore
|
||||||
@ -17,7 +17,7 @@ An easy-to-use Voice Conversion framework based on VITS.<br><br>
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
------
|
------
|
||||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/en/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||||
|
|
||||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||||
|
|
||||||
@ -32,25 +32,26 @@ Realtime Voice Conversion GUI:go-realtime-gui.bat
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
> The dataset for the pre-training model uses nearly 50 hours of high quality audio from the VCTK open source dataset.
|
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
|
||||||
|
|
||||||
> High quality licensed song datasets will be added to the training-set often for your use, without having to worry about copyright infringement.
|
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
|
||||||
|
|
||||||
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
|
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
|
||||||
|
|
||||||
## Features:
|
## Summary
|
||||||
|
This repository has the following features:
|
||||||
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
||||||
+ Easy + fast training, even on poor graphics cards;
|
+ Easy and fast training, even on relatively poor graphics cards;
|
||||||
+ Training with a small amounts of data (>=10min low noise speech recommended);
|
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
|
||||||
+ Model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
||||||
+ Easy-to-use WebUI;
|
+ Easy-to-use Webui interface;
|
||||||
+ UVR5 model to quickly separate vocals and instruments;
|
+ Use the UVR5 model to quickly separate vocals and instruments.
|
||||||
+ High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent a muted sound problem. Provides the best results (significantly) and is faster with lower resource consumption than Crepe_full;
|
+ Use the most powerful High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent the muted sound problem. Provides the best results (significantly) and is faster, with even lower resource consumption than Crepe_full.
|
||||||
+ AMD/Intel graphics cards acceleration supported;
|
+ AMD/Intel graphics cards acceleration supported.
|
||||||
+ Intel ARC graphics cards acceleration with IPEX supported.
|
+ Intel ARC graphics cards acceleration with IPEX supported.
|
||||||
|
|
||||||
## Preparing the environment
|
## Preparing the environment
|
||||||
The following commands need to be executed with Python 3.8 or higher.
|
The following commands need to be executed in the environment of Python version 3.8 or higher.
|
||||||
|
|
||||||
(Windows/Linux)
|
(Windows/Linux)
|
||||||
First install the main dependencies through pip:
|
First install the main dependencies through pip:
|
||||||
@ -165,7 +166,7 @@ You might also need to set these environment variables (e.g. on a RX6700XT):
|
|||||||
export ROCM_PATH=/opt/rocm
|
export ROCM_PATH=/opt/rocm
|
||||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||||
````
|
````
|
||||||
Make sure your user is part of the `render` and `video` group:
|
Also make sure your user is part of the `render` and `video` group:
|
||||||
````
|
````
|
||||||
sudo usermod -aG render $USERNAME
|
sudo usermod -aG render $USERNAME
|
||||||
sudo usermod -aG video $USERNAME
|
sudo usermod -aG video $USERNAME
|
||||||
|
|||||||
@ -14,7 +14,7 @@ Un framework simple et facile à utiliser pour la conversion vocale (modificateu
|
|||||||
|
|
||||||
[](https://discord.gg/HcsmBBGyVk)
|
[](https://discord.gg/HcsmBBGyVk)
|
||||||
|
|
||||||
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||||
|
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|||||||
123
docs/jp/Changelog_JA.md
Normal file
123
docs/jp/Changelog_JA.md
Normal file
@ -0,0 +1,123 @@
|
|||||||
|
### 2023 年 10 月 6 日更新
|
||||||
|
|
||||||
|
リアルタイム声変換のためのインターフェース go-realtime-gui.bat/gui_v1.py を作成しました(実際には既に存在していました)。今回のアップデートでは、リアルタイム声変換のパフォーマンスを重点的に最適化しました。0813 版との比較:
|
||||||
|
|
||||||
|
- 1. インターフェース操作の最適化:パラメータのホット更新(パラメータ調整時に中断して再起動する必要がない)、レイジーロードモデル(既にロードされたモデルは再ロードする必要がない)、音量因子パラメータ追加(音量を入力オーディオに近づける)
|
||||||
|
- 2. 内蔵ノイズリダクション効果と速度の最適化
|
||||||
|
- 3. 推論速度の大幅な最適化
|
||||||
|
|
||||||
|
入出力デバイスは同じタイプを選択する必要があります。例えば、両方とも MME タイプを選択します。
|
||||||
|
|
||||||
|
1006 バージョンの全体的な更新は:
|
||||||
|
|
||||||
|
- 1. rmvpe 音声ピッチ抽出アルゴリズムの効果をさらに向上、特に男性の低音部分で大きな改善
|
||||||
|
- 2. 推論インターフェースレイアウトの最適化
|
||||||
|
|
||||||
|
### 2023 年 8 月 13 日更新
|
||||||
|
|
||||||
|
1-通常のバグ修正
|
||||||
|
|
||||||
|
- 保存頻度と総ラウンド数の最小値を 1 に変更。総ラウンド数の最小値を 2 に変更
|
||||||
|
- pretrain モデルなしでのトレーニングエラーを修正
|
||||||
|
- 伴奏とボーカルの分離完了後の VRAM クリア
|
||||||
|
- faiss 保存パスを絶対パスから相対パスに変更
|
||||||
|
- パスに空白が含まれる場合のサポート(トレーニングセットのパス+実験名がサポートされ、エラーにならない)
|
||||||
|
- filelist の強制的な utf8 エンコーディングをキャンセル
|
||||||
|
- リアルタイム声変換中にインデックスを有効にすることによる CPU の大幅な使用問題を解決
|
||||||
|
|
||||||
|
2-重要なアップデート
|
||||||
|
|
||||||
|
- 現在最も強力なオープンソースの人間の声のピッチ抽出モデル RMVPE をトレーニングし、RVC のトレーニング、オフライン/リアルタイム推論に使用。pytorch/onnx/DirectML をサポート
|
||||||
|
- pytorch-dml を通じて A カードと I カードのサポート
|
||||||
|
(1)リアルタイム声変換(2)推論(3)ボーカルと伴奏の分離(4)トレーニングはまだサポートされておらず、CPU でのトレーニングに切り替わります。onnx_dml を通じて rmvpe_gpu の推論をサポート
|
||||||
|
|
||||||
|
### 2023 年 6 月 18 日更新
|
||||||
|
|
||||||
|
- v2 に 32k と 48k の 2 つの新しい事前トレーニングモデルを追加
|
||||||
|
- 非 f0 モデルの推論エラーを修正
|
||||||
|
- 1 時間を超えるトレーニングセットのインデックス構築フェーズでは、自動的に kmeans で特徴を縮小し、インデックスのトレーニングを加速し、検索に追加
|
||||||
|
- 人間の声をギターに変換するおもちゃのリポジトリを添付
|
||||||
|
- データ処理で異常値スライスを除外
|
||||||
|
- onnx エクスポートオプションタブ
|
||||||
|
|
||||||
|
失敗した実験:
|
||||||
|
|
||||||
|
- ~~特徴検索に時間次元を追加:ダメ、効果がない~~
|
||||||
|
- ~~特徴検索に PCAR 次元削減オプションを追加:ダメ、大きなデータは kmeans でデータ量を減らし、小さいデータは次元削減の時間が節約するマッチングの時間よりも長い~~
|
||||||
|
- ~~onnx 推論のサポート(推論のみの小さな圧縮パッケージ付き):ダメ、nsf の生成には pytorch が必要~~
|
||||||
|
- ~~トレーニング中に音声、ジェンダー、eq、ノイズなどで入力をランダムに増強:ダメ、効果がない~~
|
||||||
|
- ~~小型声码器の接続調査:ダメ、効果が悪化~~
|
||||||
|
|
||||||
|
todolist:
|
||||||
|
|
||||||
|
- ~~トレーニングセットの音声ピッチ認識に crepe をサポート:既に RMVPE に置き換えられているため不要~~
|
||||||
|
- ~~多プロセス harvest 推論:既に RMVPE に置き換えられているため不要~~
|
||||||
|
- ~~crepe の精度サポートと RVC-config の同期:既に RMVPE に置き換えられているため不要。これをサポートするには torchcrepe ライブラリも同期する必要があり、面倒~~
|
||||||
|
- F0 エディタとの連携
|
||||||
|
|
||||||
|
### 2023 年 5 月 28 日更新
|
||||||
|
|
||||||
|
- v2 の jupyter notebook を追加、韓国語の changelog を追加、いくつかの環境依存関係を追加
|
||||||
|
- 呼吸、清辅音、歯音の保護モードを追加
|
||||||
|
- crepe-full 推論をサポート
|
||||||
|
- UVR5 人間の声と伴奏の分離に 3 つの遅延除去モデルと MDX-Net の混响除去モデルを追加、HP3 人声抽出モデルを追加
|
||||||
|
- インデックス名にバージョンと実験名を追加
|
||||||
|
- 人間の声と伴奏の分離、推論のバッチエクスポートにオーディオエクスポートフォーマットオプションを追加
|
||||||
|
- 32k モデルのトレーニングを廃止
|
||||||
|
|
||||||
|
### 2023 年 5 月 13 日更新
|
||||||
|
|
||||||
|
- ワンクリックパッケージ内の古いバージョンの runtime 内の lib.infer_pack と uvr5_pack の残骸をクリア
|
||||||
|
- トレーニングセットの事前処理の擬似マルチプロセスバグを修正
|
||||||
|
- harvest による音声ピッチ認識で無声音現象を弱めるために中間値フィルターを追加、中間値フィルターの半径を調整可能
|
||||||
|
- 音声エクスポートにポストプロセスリサンプリングを追加
|
||||||
|
- トレーニング時の n_cpu プロセス数を「F0 抽出のみ調整」から「データ事前処理と F0 抽出の調整」に変更
|
||||||
|
- logs フォルダ下の index パスを自動検出し、ドロップダウンリスト機能を提供
|
||||||
|
- タブページに「よくある質問」を追加(または github-rvc-wiki を参照)
|
||||||
|
- 同じパスの入力音声推論に音声ピッチキャッシュを追加(用途:harvest 音声ピッチ抽出を使用すると、全体のパイプラインが長く繰り返される音声ピッチ抽出プロセスを経験し、キャッシュを使用しない場合、異なる音色、インデックス、音声ピッチ中間値フィルター半径パラメーターをテストするユーザーは、最初のテスト後の待機結果が非常に苦痛になります)
|
||||||
|
|
||||||
|
### 2023 年 5 月 14 日更新
|
||||||
|
|
||||||
|
- 音量エンベロープのアライメント入力ミックス(「入力が無音で出力がわずかなノイズ」の問題を緩和することができます。入力音声の背景ノイズが大きい場合は、オンにしないことをお勧めします。デフォルトではオフ(1 として扱われる))
|
||||||
|
- 指定された頻度で抽出された小型モデルを保存する機能をサポート(異なるエポックでの推論効果を試したいが、すべての大きなチェックポイントを保存して手動で小型モデルを抽出するのが面倒な場合、この機能は非常に便利です)
|
||||||
|
- システム全体のプロキシが開かれている場合にブラウザの接続エラーが発生する問題を環境変数の設定で解決
|
||||||
|
- v2 事前訓練モデルをサポート(現在、テストのために 40k バージョンのみが公開されており、他の 2 つのサンプリングレートはまだ完全に訓練されていません)
|
||||||
|
- 推論前に 1 を超える過大な音量を制限
|
||||||
|
- データ事前処理パラメーターを微調整
|
||||||
|
|
||||||
|
### 2023 年 4 月 9 日更新
|
||||||
|
|
||||||
|
- トレーニングパラメーターを修正し、GPU の平均利用率を向上させる。A100 は最高 25%から約 90%に、V100 は 50%から約 90%に、2060S は 60%から約 85%に、P40 は 25%から約 95%に向上し、トレーニング速度が大幅に向上
|
||||||
|
- パラメーターを修正:全体の batch_size を各カードの batch_size に変更
|
||||||
|
- total_epoch を修正:最大制限 100 から 1000 に解除; デフォルト 10 からデフォルト 20 に引き上げ
|
||||||
|
- ckpt 抽出時に音声ピッチの有無を誤って認識し、推論が異常になる問題を修正
|
||||||
|
- 分散トレーニングで各ランクが ckpt を 1 回ずつ保存する問題を修正
|
||||||
|
- 特徴抽出で nan 特徴をフィルタリング
|
||||||
|
- 入力が無音で出力がランダムな子音またはノイズになる問題を修正(旧バージョンのモデルはトレーニングセットを作り直して再トレーニングする必要があります)
|
||||||
|
|
||||||
|
### 2023 年 4 月 16 日更新
|
||||||
|
|
||||||
|
- ローカルリアルタイム音声変換ミニ GUI を新設、go-realtime-gui.bat をダブルクリックで起動
|
||||||
|
- トレーニングと推論で 50Hz 以下の周波数帯をフィルタリング
|
||||||
|
- トレーニングと推論の音声ピッチ抽出 pyworld の最低音声ピッチをデフォルトの 80 から 50 に下げ、50-80hz の男性低音声が無声にならないように
|
||||||
|
- WebUI がシステムの地域に基づいて言語を変更する機能をサポート(現在サポートされているのは en_US、ja_JP、zh_CN、zh_HK、zh_SG、zh_TW、サポートされていない場合はデフォルトで en_US になります)
|
||||||
|
- 一部のグラフィックカードの認識を修正(例えば V100-16G の認識失敗、P4 の認識失敗)
|
||||||
|
|
||||||
|
### 2023 年 4 月 28 日更新
|
||||||
|
|
||||||
|
- faiss インデックス設定をアップグレードし、速度が速く、品質が高くなりました
|
||||||
|
- total_npy 依存をキャンセルし、今後のモデル共有では total_npy の記入は不要
|
||||||
|
- 16 シリーズの制限を解除。4G メモリ GPU に 4G の推論設定を提供
|
||||||
|
- 一部のオーディオ形式で UVR5 の人声伴奏分離のバグを修正
|
||||||
|
- リアルタイム音声変換ミニ gui に 40k 以外のモデルと妥協のない音声ピッチモデルのサポートを追加
|
||||||
|
|
||||||
|
### 今後の計画:
|
||||||
|
|
||||||
|
機能:
|
||||||
|
|
||||||
|
- 複数人のトレーニングタブのサポート(最大 4 人)
|
||||||
|
|
||||||
|
底層モデル:
|
||||||
|
|
||||||
|
- 呼吸 wav をトレーニングセットに追加し、呼吸が音声変換の電子音の問題を修正
|
||||||
|
- 歌声トレーニングセットを追加した底層モデルをトレーニングしており、将来的には公開する予定です
|
||||||
@ -18,7 +18,7 @@ VITSに基づく使いやすい音声変換(voice changer)framework<br><br>
|
|||||||
|
|
||||||
------
|
------
|
||||||
|
|
||||||
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md)
|
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/cn/Changelog_CN.md)
|
||||||
|
|
||||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||||
|
|
||||||
|
|||||||
122
docs/jp/faq_ja.md
Normal file
122
docs/jp/faq_ja.md
Normal file
@ -0,0 +1,122 @@
|
|||||||
|
## Q1: ffmpeg error/utf8 error
|
||||||
|
|
||||||
|
大体の場合、ffmpeg の問題ではなく、音声パスの問題です。<br>
|
||||||
|
ffmpeg は空白や()などの特殊文字を含むパスを読み込む際に ffmpeg error が発生する可能性があります。トレーニングセットの音声が中国語のパスを含む場合、filelist.txt に書き込む際に utf8 error が発生する可能性があります。<br>
|
||||||
|
|
||||||
|
## Q2: ワンクリックトレーニングが終わってもインデックスがない
|
||||||
|
|
||||||
|
"Training is done. The program is closed."と表示された場合、モデルトレーニングは成功しています。その直後のエラーは誤りです。<br>
|
||||||
|
|
||||||
|
ワンクリックトレーニングが終了しても added で始まるインデックスファイルがない場合、トレーニングセットが大きすぎてインデックス追加のステップが停止している可能性があります。バッチ処理 add インデックスでメモリの要求が高すぎる問題を解決しました。一時的に「トレーニングインデックス」ボタンをもう一度クリックしてみてください。<br>
|
||||||
|
|
||||||
|
## Q3: トレーニングが終了してもトレーニングセットの音色が見えない
|
||||||
|
|
||||||
|
音色をリフレッシュしてもう一度確認してください。それでも見えない場合は、トレーニングにエラーがなかったか、コンソールと WebUI のスクリーンショット、logs/実験名の下のログを開発者に送って確認してみてください。<br>
|
||||||
|
|
||||||
|
## Q4: モデルをどのように共有するか
|
||||||
|
|
||||||
|
rvc_root/logs/実験名の下に保存されている pth は、推論に使用するために共有するためのものではなく、実験の状態を保存して再現およびトレーニングを続けるためのものです。共有するためのモデルは、weights フォルダの下にある 60MB 以上の pth ファイルです。<br>
|
||||||
|
今後、weights/exp_name.pth と logs/exp_name/added_xxx.index を組み合わせて weights/exp_name.zip にパッケージ化し、インデックスの記入ステップを省略します。その場合、zip ファイルを共有し、pth ファイルは共有しないでください。別のマシンでトレーニングを続ける場合を除きます。<br>
|
||||||
|
logs フォルダの数百 MB の pth ファイルを weights フォルダにコピー/共有して推論に強制的に使用すると、f0、tgt_sr などのさまざまなキーが存在しないというエラーが発生する可能性があります。ckpt タブの一番下で、音高、目標オーディオサンプリングレートを手動または自動(ローカルの logs に関連情報が見つかる場合は自動的に)で選択してから、ckpt の小型モデルを抽出する必要があります(入力パスに G で始まるものを記入)。抽出が完了すると、weights フォルダに 60MB 以上の pth ファイルが表示され、音色をリフレッシュした後に使用できます。<br>
|
||||||
|
|
||||||
|
## Q5: Connection Error
|
||||||
|
|
||||||
|
コンソール(黒いウィンドウ)を閉じた可能性があります。<br>
|
||||||
|
|
||||||
|
## Q6: WebUI が Expecting value: line 1 column 1 (char 0)と表示する
|
||||||
|
|
||||||
|
システムのローカルネットワークプロキシ/グローバルプロキシを閉じてください。<br>
|
||||||
|
|
||||||
|
これはクライアントのプロキシだけでなく、サーバー側のプロキシも含まれます(例えば autodl で http_proxy と https_proxy を設定して学術的な加速を行っている場合、使用する際には unset でオフにする必要があります)。<br>
|
||||||
|
|
||||||
|
## Q7: WebUI を使わずにコマンドでトレーニングや推論を行うには
|
||||||
|
|
||||||
|
トレーニングスクリプト:<br>
|
||||||
|
まず WebUI を実行し、メッセージウィンドウにデータセット処理とトレーニング用のコマンドラインが表示されます。<br>
|
||||||
|
|
||||||
|
推論スクリプト:<br>
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
||||||
|
|
||||||
|
例:<br>
|
||||||
|
|
||||||
|
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
||||||
|
|
||||||
|
f0up_key=sys.argv[1]<br>
|
||||||
|
input_path=sys.argv[2]<br>
|
||||||
|
index_path=sys.argv[3]<br>
|
||||||
|
f0method=sys.argv[4]#harvest or pm<br>
|
||||||
|
opt_path=sys.argv[5]<br>
|
||||||
|
model_path=sys.argv[6]<br>
|
||||||
|
index_rate=float(sys.argv[7])<br>
|
||||||
|
device=sys.argv[8]<br>
|
||||||
|
is_half=bool(sys.argv[9])<br>
|
||||||
|
|
||||||
|
## Q8: Cuda error/Cuda out of memory
|
||||||
|
|
||||||
|
まれに cuda の設定問題やデバイスがサポートされていない可能性がありますが、大半はメモリ不足(out of memory)が原因です。<br>
|
||||||
|
|
||||||
|
トレーニングの場合は batch size を小さくします(1 にしても足りない場合はグラフィックカードを変更するしかありません)。推論の場合は、config.py の末尾にある x_pad、x_query、x_center、x_max を適宜小さくします。4GB 以下のメモリ(例えば 1060(3G)や各種 2GB のグラフィックカード)は諦めることをお勧めしますが、4GB のメモリのグラフィックカードはまだ救いがあります。<br>
|
||||||
|
|
||||||
|
## Q9: total_epoch はどのくらいに設定するのが良いですか
|
||||||
|
|
||||||
|
トレーニングセットの音質が悪く、ノイズが多い場合は、20〜30 で十分です。高すぎると、ベースモデルの音質が低音質のトレーニングセットを高めることができません。<br>
|
||||||
|
トレーニングセットの音質が高く、ノイズが少なく、長い場合は、高く設定できます。200 は問題ありません(トレーニング速度が速いので、高音質のトレーニングセットを準備できる条件がある場合、グラフィックカードも条件が良いはずなので、少しトレーニング時間が長くなることを気にすることはありません)。<br>
|
||||||
|
|
||||||
|
## Q10: トレーニングセットはどれくらいの長さが必要ですか
|
||||||
|
|
||||||
|
10 分から 50 分を推奨します。
|
||||||
|
音質が良く、バックグラウンドノイズが低い場合、個人的な特徴のある音色であれば、多ければ多いほど良いです。
|
||||||
|
高品質のトレーニングセット(精巧に準備された + 特徴的な音色)であれば、5 分から 10 分でも大丈夫です。リポジトリの作者もよくこの方法で遊びます。
|
||||||
|
1 分から 2 分のデータでトレーニングに成功した人もいますが、その成功体験は他人には再現できないため、あまり参考になりません。トレーニングセットの音色が非常に特徴的である必要があります(例:高い周波数の透明な声や少女の声など)、そして音質が良い必要があります。
|
||||||
|
1 分未満のデータでトレーニングを試みた(成功した)ケースはまだ見たことがありません。このような試みはお勧めしません。
|
||||||
|
|
||||||
|
## Q11: index rate は何に使うもので、どのように調整するのか(啓蒙)
|
||||||
|
|
||||||
|
もしベースモデルや推論ソースの音質がトレーニングセットよりも高い場合、推論結果の音質を向上させることができますが、音色がベースモデル/推論ソースの音色に近づくことがあります。これを「音色漏れ」と言います。
|
||||||
|
index rate は音色漏れの問題を減少させたり解決するために使用されます。1 に設定すると、理論的には推論ソースの音色漏れの問題は存在しませんが、音質はトレーニングセットに近づきます。トレーニングセットの音質が推論ソースよりも低い場合、index rate を高くすると音質が低下する可能性があります。0 に設定すると、検索ミックスを利用してトレーニングセットの音色を保護する効果はありません。
|
||||||
|
トレーニングセットが高品質で長い場合、total_epoch を高く設定することができ、この場合、モデル自体は推論ソースやベースモデルの音色をあまり参照しないため、「音色漏れ」の問題はほとんど発生しません。この時、index rate は重要ではなく、インデックスファイルを作成したり共有したりする必要もありません。
|
||||||
|
|
||||||
|
## Q11: 推論時に GPU をどのように選択するか
|
||||||
|
|
||||||
|
config.py ファイルの device cuda:の後にカード番号を選択します。
|
||||||
|
カード番号とグラフィックカードのマッピング関係は、トレーニングタブのグラフィックカード情報欄で確認できます。
|
||||||
|
|
||||||
|
## Q12: トレーニング中に保存された pth ファイルをどのように推論するか
|
||||||
|
|
||||||
|
ckpt タブの一番下で小型モデルを抽出します。
|
||||||
|
|
||||||
|
## Q13: トレーニングをどのように中断し、続行するか
|
||||||
|
|
||||||
|
現在の段階では、WebUI コンソールを閉じて go-web.bat をダブルクリックしてプログラムを再起動するしかありません。ウェブページのパラメータもリフレッシュして再度入力する必要があります。
|
||||||
|
トレーニングを続けるには:同じウェブページのパラメータでトレーニングモデルをクリックすると、前回のチェックポイントからトレーニングを続けます。
|
||||||
|
|
||||||
|
## Q14: トレーニング中にファイルページ/メモリエラーが発生した場合の対処法
|
||||||
|
|
||||||
|
プロセスが多すぎてメモリがオーバーフローしました。以下の方法で解決できるかもしれません。
|
||||||
|
|
||||||
|
1. 「音高抽出とデータ処理に使用する CPU プロセス数」を適宜下げます。
|
||||||
|
2. トレーニングセットのオーディオを手動でカットして、あまり長くならないようにします。
|
||||||
|
|
||||||
|
## Q15: 途中でデータを追加してトレーニングする方法
|
||||||
|
|
||||||
|
1. 全データに新しい実験名を作成します。
|
||||||
|
2. 前回の最新の G と D ファイル(あるいはどの中間 ckpt を基にトレーニングしたい場合は、その中間のものをコピーすることもできます)を新しい実験名にコピーします。
|
||||||
|
3. 新しい実験名でワンクリックトレーニングを開始すると、前回の最新の進捗からトレーニングを続けます。
|
||||||
|
|
||||||
|
## Q16: llvmlite.dll に関するエラー
|
||||||
|
|
||||||
|
```bash
|
||||||
|
OSError: Could not load shared object file: llvmlite.dll
|
||||||
|
|
||||||
|
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
||||||
|
```
|
||||||
|
|
||||||
|
Windows プラットフォームではこのエラーが発生しますが、https://aka.ms/vs/17/release/vc_redist.x64.exeをインストールしてWebUIを再起動すれば解決します。
|
||||||
|
|
||||||
|
## Q17: RuntimeError: テンソルの拡張サイズ(17280)は、非シングルトン次元 1 での既存サイズ(0)と一致する必要があります。 ターゲットサイズ:[1, 17280]。 テンソルサイズ:[0]
|
||||||
|
|
||||||
|
wavs16k フォルダーの下で、他のファイルよりも明らかに小さいいくつかのオーディオファイルを見つけて削除し、トレーニングモデルをクリックすればエラーは発生しませんが、ワンクリックプロセスが中断されたため、モデルのトレーニングが完了したらインデックスのトレーニングをクリックする必要があります。
|
||||||
|
|
||||||
|
## Q18: RuntimeError: テンソル a のサイズ(24)は、非シングルトン次元 2 でテンソル b(16)のサイズと一致する必要があります
|
||||||
|
|
||||||
|
トレーニング中にサンプリングレートを変更してはいけません。変更する必要がある場合は、実験名を変更して最初からトレーニングする必要があります。もちろん、前回抽出した音高と特徴(0/1/2/2b フォルダ)をコピーしてトレーニングプロセスを加速することもできます。
|
||||||
@ -18,7 +18,7 @@ VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.<b
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
[**업데이트 로그**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_KO.md)
|
[**업데이트 로그**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/kr/Changelog_KO.md)
|
||||||
|
|
||||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||||
|
|
||||||
|
|||||||
130
docs/kr/faq_ko.md
Normal file
130
docs/kr/faq_ko.md
Normal file
@ -0,0 +1,130 @@
|
|||||||
|
## Q1:ffmpeg 오류/utf8 오류
|
||||||
|
|
||||||
|
대부분의 경우 ffmpeg 문제가 아니라 오디오 경로 문제입니다. <br>
|
||||||
|
ffmpeg가 공백, () 등의 특수 문자가 포함된 경로를 읽을 때 ffmpeg 오류가 발생할 수 있습니다. 트레이닝 세트 오디오가 중문 경로일 때 filelist.txt에 쓸 때 utf8 오류가 발생할 수 있습니다. <br>
|
||||||
|
|
||||||
|
## Q2:일괄 트레이닝이 끝나고 인덱스가 없음
|
||||||
|
|
||||||
|
"Training is done. The program is closed."라고 표시되면 모델 트레이닝이 성공한 것이며, 이어지는 오류는 가짜입니다. <br>
|
||||||
|
|
||||||
|
일괄 트레이닝이 끝나고 'added'로 시작하는 인덱스 파일이 없으면 트레이닝 세트가 너무 커서 인덱스 추가 단계에서 멈췄을 수 있습니다. 메모리에 대한 인덱스 추가 요구 사항이 너무 큰 문제를 배치 처리 add 인덱스로 해결했습니다. 임시로 "트레이닝 인덱스" 버튼을 다시 클릭해 보세요. <br>
|
||||||
|
|
||||||
|
## Q3:트레이닝이 끝나고 트레이닝 세트의 음색을 추론에서 보지 못함
|
||||||
|
|
||||||
|
'음색 새로고침'을 클릭해 보세요. 여전히 없다면 트레이닝에 오류가 있는지, 콘솔 및 webui의 스크린샷, logs/실험명 아래의 로그를 개발자에게 보내 확인해 보세요. <br>
|
||||||
|
|
||||||
|
## Q4:모델 공유 방법
|
||||||
|
|
||||||
|
rvc_root/logs/실험명 아래에 저장된 pth는 추론에 사용하기 위한 것이 아니라 실험 상태를 저장하고 복원하며, 트레이닝을 계속하기 위한 것입니다. 공유에 사용되는 모델은 weights 폴더 아래 60MB 이상인 pth 파일입니다. <br>
|
||||||
|
<br/>
|
||||||
|
향후에는 weights/exp_name.pth와 logs/exp_name/added_xxx.index를 결합하여 weights/exp_name.zip으로 만들어 index 입력 단계를 생략할 예정입니다. 그러면 zip 파일을 공유하고 pth 파일은 공유하지 마세요. 단지 다른 기계에서 트레이닝을 계속하려는 경우에만 공유하세요. <br>
|
||||||
|
<br/>
|
||||||
|
logs 폴더 아래 수백 MB의 pth 파일을 weights 폴더에 복사/공유하여 강제로 추론에 사용하면 f0, tgt_sr 등의 키가 없다는 오류가 발생할 수 있습니다. ckpt 탭 아래에서 수동 또는 자동(로컬 logs에서 관련 정보를 찾을 수 있는 경우 자동)으로 음성, 대상 오디오 샘플링률 옵션을 선택한 후 ckpt 소형 모델을 추출해야 합니다(입력 경로에 G로 시작하는 경로를 입력). 추출 후 weights 폴더에 60MB 이상의 pth 파일이 생성되며, 음색 새로고침 후 사용할 수 있습니다. <br>
|
||||||
|
|
||||||
|
## Q5:연결 오류
|
||||||
|
|
||||||
|
아마도 컨트롤 콘솔(검은 창)을 닫았을 것입니다. <br>
|
||||||
|
|
||||||
|
## Q6:WebUI에서 "Expecting value: line 1 column 1 (char 0)" 오류가 발생함
|
||||||
|
|
||||||
|
시스템 로컬 네트워크 프록시/글로벌 프록시를 닫으세요. <br>
|
||||||
|
|
||||||
|
이는 클라이언트의 프록시뿐만 아니라 서버 측의 프록시도 포함합니다(예: autodl로 http_proxy 및 https_proxy를 설정한 경우 사용 시 unset으로 끄세요). <br>
|
||||||
|
|
||||||
|
## Q7:WebUI 없이 명령으로 트레이닝 및 추론하는 방법
|
||||||
|
|
||||||
|
트레이닝 스크립트: <br>
|
||||||
|
먼저 WebUI를 실행하여 데이터 세트 처리 및 트레이닝에 사용되는 명령줄을 메시지 창에서 확인할 수 있습니다. <br>
|
||||||
|
|
||||||
|
추론 스크립트: <br>
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py <br>
|
||||||
|
|
||||||
|
예제: <br>
|
||||||
|
|
||||||
|
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True <br>
|
||||||
|
|
||||||
|
f0up_key=sys.argv[1] <br>
|
||||||
|
input_path=sys.argv[2] <br>
|
||||||
|
index_path=sys.argv[3] <br>
|
||||||
|
f0method=sys.argv[4]#harvest 또는 pm <br>
|
||||||
|
opt_path=sys.argv[5] <br>
|
||||||
|
model_path=sys.argv[6] <br>
|
||||||
|
index_rate=float(sys.argv[7]) <br>
|
||||||
|
device=sys.argv[8] <br>
|
||||||
|
is_half=bool(sys.argv[9]) <br>
|
||||||
|
|
||||||
|
## Q8:Cuda 오류/Cuda 메모리 부족
|
||||||
|
|
||||||
|
아마도 cuda 설정 문제이거나 장치가 지원되지 않을 수 있습니다. 대부분의 경우 메모리가 부족합니다(out of memory). <br>
|
||||||
|
|
||||||
|
트레이닝의 경우 batch size를 줄이세요(1로 줄여도 부족하다면 다른 그래픽 카드로 트레이닝을 해야 합니다). 추론의 경우 config.py 파일 끝에 있는 x_pad, x_query, x_center, x_max를 적절히 줄이세요. 4GB 미만의 메모리(예: 1060(3GB) 및 여러 2GB 그래픽 카드)를 가진 경우는 포기하세요. 4GB 메모리 그래픽 카드는 아직 구할 수 있습니다. <br>
|
||||||
|
|
||||||
|
## Q9:total_epoch를 몇으로 설정하는 것이 좋을까요
|
||||||
|
|
||||||
|
트레이닝 세트의 오디오 품질이 낮고 배경 소음이 많으면 20~30이면 충분합니다. 너무 높게 설정하면 바닥 모델의 오디오 품질이 낮은 트레이닝 세트를 높일 수 없습니다. <br>
|
||||||
|
트레이닝 세트의 오디오 품질이 높고 배경 소음이 적고 길이가 길 경우 높게 설정할 수 있습니다. 200도 괜찮습니다(트레이닝 속도가 빠르므로, 고품질 트레이닝 세트를 준비할 수 있는 조건이 있다면, 그래픽 카드도 좋을 것이므로, 조금 더 긴 트레이닝 시간에 대해 걱정하지 않을 것입니다). <br>
|
||||||
|
|
||||||
|
## Q10: 트레이닝 세트는 얼마나 길어야 하나요
|
||||||
|
|
||||||
|
10분에서 50분을 추천합니다.
|
||||||
|
<br/>
|
||||||
|
음질이 좋고 백그라운드 노이즈가 낮은 상태에서, 개인적인 특색 있는 음색이라면 더 많으면 더 좋습니다.
|
||||||
|
<br/>
|
||||||
|
고품질의 트레이닝 세트(정교하게 준비된 + 특색 있는 음색)라면, 5분에서 10분도 괜찮습니다. 저장소의 저자도 종종 이렇게 합니다.
|
||||||
|
<br/>
|
||||||
|
1분에서 2분의 데이터로 트레이닝에 성공한 사람도 있지만, 그러한 성공 사례는 다른 사람이 재현하기 어려우며 참고 가치가 크지 않습니다. 이는 트레이닝 세트의 음색이 매우 뚜렷해야 하며(예: 높은 주파수의 명확한 목소리나 소녀음) 음질이 좋아야 합니다.
|
||||||
|
<br/>
|
||||||
|
1분 미만의 데이터로 트레이닝을 시도(성공)한 사례는 아직 보지 못했습니다. 이런 시도는 권장하지 않습니다.
|
||||||
|
|
||||||
|
## Q11: index rate는 무엇이며, 어떻게 조정하나요? (과학적 설명)
|
||||||
|
|
||||||
|
만약 베이스 모델과 추론 소스의 음질이 트레이닝 세트보다 높다면, 그들은 추론 결과의 음질을 높일 수 있지만, 음색이 베이스 모델/추론 소스의 음색으로 기울어질 수 있습니다. 이 현상을 "음색 유출"이라고 합니다.
|
||||||
|
<br/>
|
||||||
|
index rate는 음색 유출 문제를 줄이거나 해결하는 데 사용됩니다. 1로 조정하면 이론적으로 추론 소스의 음색 유출 문제가 없지만, 음질은 트레이닝 세트에 더 가깝게 됩니다. 만약 트레이닝 세트의 음질이 추론 소스보다 낮다면, index rate를 높이면 음질이 낮아질 수 있습니다. 0으로 조정하면 검색 혼합을 이용하여 트레이닝 세트의 음색을 보호하는 효과가 없습니다.
|
||||||
|
<br/>
|
||||||
|
트레이닝 세트가 고품질이고 길이가 길 경우, total_epoch를 높일 수 있으며, 이 경우 모델 자체가 추론 소스와 베이스 모델의 음색을 거의 참조하지 않아 "음색 유출" 문제가 거의 발생하지 않습니다. 이때 index rate는 중요하지 않으며, 심지어 index 색인 파일을 생성하거나 공유하지 않아도 됩니다.
|
||||||
|
|
||||||
|
## Q11: 추론시 GPU를 어떻게 선택하나요?
|
||||||
|
|
||||||
|
config.py 파일에서 device cuda: 다음에 카드 번호를 선택합니다.
|
||||||
|
카드 번호와 그래픽 카드의 매핑 관계는 트레이닝 탭의 그래픽 카드 정보란에서 볼 수 있습니다.
|
||||||
|
|
||||||
|
## Q12: 트레이닝 중간에 저장된 pth를 어떻게 추론하나요?
|
||||||
|
|
||||||
|
ckpt 탭 하단에서 소형 모델을 추출합니다.
|
||||||
|
|
||||||
|
## Q13: 트레이닝을 어떻게 중단하고 계속할 수 있나요?
|
||||||
|
|
||||||
|
현재 단계에서는 WebUI 콘솔을 닫고 go-web.bat을 더블 클릭하여 프로그램을 다시 시작해야 합니다. 웹 페이지 매개변수도 새로 고쳐서 다시 입력해야 합니다.
|
||||||
|
트레이닝을 계속하려면: 같은 웹 페이지 매개변수로 트레이닝 모델을 클릭하면 이전 체크포인트에서 트레이닝을 계속합니다.
|
||||||
|
|
||||||
|
## Q14: 트레이닝 중 파일 페이지/메모리 오류가 발생하면 어떻게 해야 하나요?
|
||||||
|
|
||||||
|
프로세스가 너무 많이 열려 메모리가 폭발했습니다. 다음과 같은 방법으로 해결할 수 있습니다.
|
||||||
|
|
||||||
|
1. "음높이 추출 및 데이터 처리에 사용되는 CPU 프로세스 수"를 적당히 낮춥니다.
|
||||||
|
2. 트레이닝 세트 오디오를 수동으로 잘라 너무 길지 않게 합니다.
|
||||||
|
|
||||||
|
## Q15: 트레이닝 도중 데이터를 어떻게 추가하나요?
|
||||||
|
|
||||||
|
1. 모든 데이터에 새로운 실험 이름을 만듭니다.
|
||||||
|
2. 이전에 가장 최신의 G와 D 파일(또는 어떤 중간 ckpt를 기반으로 트레이닝하고 싶다면 중간 것을 복사할 수도 있음)을 새 실험 이름으로 복사합니다.
|
||||||
|
3. 새 실험 이름으로 원클릭 트레이닝을 시작하면 이전의 최신 진행 상황에서 계속 트레이닝합니다.
|
||||||
|
|
||||||
|
## Q16: llvmlite.dll에 관한 오류
|
||||||
|
|
||||||
|
```bash
|
||||||
|
OSError: Could not load shared object file: llvmlite.dll
|
||||||
|
|
||||||
|
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
||||||
|
```
|
||||||
|
|
||||||
|
Windows 플랫폼에서 이 오류가 발생하면 https://aka.ms/vs/17/release/vc_redist.x64.exe를 설치하고 WebUI를 다시 시작하면 해결됩니다.
|
||||||
|
|
||||||
|
## Q17: RuntimeError: 텐서의 확장된 크기(17280)는 비 단일 항목 차원 1에서 기존 크기(0)와 일치해야 합니다. 대상 크기: [1, 17280]. 텐서 크기: [0]
|
||||||
|
|
||||||
|
wavs16k 폴더 아래에서 다른 파일들보다 크기가 현저히 작은 일부 오디오 파일을 찾아 삭제하고, 트레이닝 모델을 클릭하면 오류가 발생하지 않습니다. 하지만 원클릭 프로세스가 중단되었기 때문에 모델 트레이닝이 완료된 후에는 인덱스 트레이닝을 클릭해야 합니다.
|
||||||
|
|
||||||
|
## Q18: RuntimeError: 텐서 a의 크기(24)가 비 단일 항목 차원 2에서 텐서 b(16)의 크기와 일치해야 합니다.
|
||||||
|
|
||||||
|
트레이닝 도중에 샘플링 레이트를 변경해서는 안 됩니다. 변경해야 한다면 실험 이름을 변경하고 처음부터 트레이닝해야 합니다. 물론, 이전에 추출한 음높이와 특징(0/1/2/2b 폴더)을 복사하여 트레이닝 프로세스를 가속화할 수도 있습니다.
|
||||||
105
docs/pt/Changelog_pt.md
Normal file
105
docs/pt/Changelog_pt.md
Normal file
@ -0,0 +1,105 @@
|
|||||||
|
### 2023-10-06
|
||||||
|
- Criamos uma GUI para alteração de voz em tempo real: go-realtime-gui.bat/gui_v1.py (observe que você deve escolher o mesmo tipo de dispositivo de entrada e saída, por exemplo, MME e MME).
|
||||||
|
- Treinamos um modelo RMVPE de extração de pitch melhor.
|
||||||
|
- Otimizar o layout da GUI de inferência.
|
||||||
|
|
||||||
|
### 2023-08-13
|
||||||
|
1-Correção de bug regular
|
||||||
|
- Alterar o número total mínimo de épocas para 1 e alterar o número total mínimo de epoch para 2
|
||||||
|
- Correção de erros de treinamento por não usar modelos de pré-treinamento
|
||||||
|
- Após a separação dos vocais de acompanhamento, limpe a memória dos gráficos
|
||||||
|
- Alterar o caminho absoluto do faiss save para o caminho relativo
|
||||||
|
- Suporte a caminhos com espaços (tanto o caminho do conjunto de treinamento quanto o nome do experimento são suportados, e os erros não serão mais relatados)
|
||||||
|
- A lista de arquivos cancela a codificação utf8 obrigatória
|
||||||
|
- Resolver o problema de consumo de CPU causado pela busca do faiss durante alterações de voz em tempo real
|
||||||
|
|
||||||
|
Atualizações do 2-Key
|
||||||
|
- Treine o modelo de extração de pitch vocal de código aberto mais forte do momento, o RMVPE, e use-o para treinamento de RVC, inferência off-line/em tempo real, com suporte a PyTorch/Onnx/DirectML
|
||||||
|
- Suporte para placas gráficas AMD e Intel por meio do Pytorch_DML
|
||||||
|
|
||||||
|
(1) Mudança de voz em tempo real (2) Inferência (3) Separação do acompanhamento vocal (4) Não há suporte para treinamento no momento, mudaremos para treinamento de CPU; há suporte para inferência RMVPE de gpu por Onnx_Dml
|
||||||
|
|
||||||
|
|
||||||
|
### 2023-06-18
|
||||||
|
- Novos modelos v2 pré-treinados: 32k e 48k
|
||||||
|
- Correção de erros de inferência de modelo não-f0
|
||||||
|
- Para conjuntos de treinamento que excedam 1 hora, faça minibatch-kmeans automáticos para reduzir a forma dos recursos, de modo que o treinamento, a adição e a pesquisa do Index sejam muito mais rápidos.
|
||||||
|
- Fornecer um espaço de brinquedo vocal2guitar huggingface
|
||||||
|
- Exclusão automática de áudios de conjunto de treinamento de atalhos discrepantes
|
||||||
|
- Guia de exportação Onnx
|
||||||
|
|
||||||
|
Experimentos com falha:
|
||||||
|
- ~~Recuperação de recurso: adicionar recuperação de recurso temporal: não eficaz~~
|
||||||
|
- ~~Recuperação de recursos: adicionar redução de dimensionalidade PCAR: a busca é ainda mais lenta~~
|
||||||
|
- ~~Aumento de dados aleatórios durante o treinamento: não é eficaz~~
|
||||||
|
|
||||||
|
Lista de tarefas:
|
||||||
|
- ~~Vocos-RVC (vocoder minúsculo): não é eficaz~~
|
||||||
|
- ~~Suporte de crepe para treinamento: substituído pelo RMVPE~~
|
||||||
|
- ~~Inferência de crepe de meia precisão:substituída pelo RMVPE. E difícil de conseguir.~~
|
||||||
|
- Suporte ao editor de F0
|
||||||
|
|
||||||
|
### 2023-05-28
|
||||||
|
- Adicionar notebook jupyter v2, changelog em coreano, corrigir alguns requisitos de ambiente
|
||||||
|
- Adicionar consoante sem voz e modo de proteção de respiração
|
||||||
|
- Suporte à detecção de pitch crepe-full
|
||||||
|
- Separação vocal UVR5: suporte a modelos dereverb e modelos de-echo
|
||||||
|
- Adicionar nome e versão do experimento no nome do Index
|
||||||
|
- Suporte aos usuários para selecionar manualmente o formato de exportação dos áudios de saída durante o processamento de conversão de voz em lote e a separação vocal UVR5
|
||||||
|
- Não há mais suporte para o treinamento do modelo v1 32k
|
||||||
|
|
||||||
|
### 2023-05-13
|
||||||
|
- Limpar os códigos redundantes na versão antiga do tempo de execução no pacote de um clique: lib.infer_pack e uvr5_pack
|
||||||
|
- Correção do bug de pseudo multiprocessamento no pré-processamento do conjunto de treinamento
|
||||||
|
- Adição do ajuste do raio de filtragem mediana para o algoritmo de reconhecimento de inclinação da extração
|
||||||
|
- Suporte à reamostragem de pós-processamento para exportação de áudio
|
||||||
|
- A configuração "n_cpu" de multiprocessamento para treinamento foi alterada de "extração de f0" para "pré-processamento de dados e extração de f0"
|
||||||
|
- Detectar automaticamente os caminhos de Index na pasta de registros e fornecer uma função de lista suspensa
|
||||||
|
- Adicionar "Perguntas e respostas frequentes" na página da guia (você também pode consultar o wiki do RVC no github)
|
||||||
|
- Durante a inferência, o pitch da colheita é armazenado em cache quando se usa o mesmo caminho de áudio de entrada (finalidade: usando a extração do pitch da colheita, todo o pipeline passará por um processo longo e repetitivo de extração do pitch. Se o armazenamento em cache não for usado, os usuários que experimentarem diferentes configurações de raio de filtragem de timbre, Index e mediana de pitch terão um processo de espera muito doloroso após a primeira inferência)
|
||||||
|
|
||||||
|
### 2023-05-14
|
||||||
|
- Use o envelope de volume da entrada para misturar ou substituir o envelope de volume da saída (pode aliviar o problema de "muting de entrada e ruído de pequena amplitude de saída"). Se o ruído de fundo do áudio de entrada for alto, não é recomendável ativá-lo, e ele não é ativado por padrão (1 pode ser considerado como não ativado)
|
||||||
|
- Suporte ao salvamento de modelos pequenos extraídos em uma frequência especificada (se você quiser ver o desempenho em épocas diferentes, mas não quiser salvar todos os pontos de verificação grandes e extrair manualmente modelos pequenos pelo processamento ckpt todas as vezes, esse recurso será muito prático)
|
||||||
|
- Resolver o problema de "erros de conexão" causados pelo proxy global do servidor, definindo variáveis de ambiente
|
||||||
|
- Oferece suporte a modelos v2 pré-treinados (atualmente, apenas as versões 40k estão disponíveis publicamente para teste e as outras duas taxas de amostragem ainda não foram totalmente treinadas)
|
||||||
|
- Limita o volume excessivo que excede 1 antes da inferência
|
||||||
|
- Ajustou ligeiramente as configurações do pré-processamento do conjunto de treinamento
|
||||||
|
|
||||||
|
|
||||||
|
#######################
|
||||||
|
|
||||||
|
Histórico de registros de alterações:
|
||||||
|
|
||||||
|
### 2023-04-09
|
||||||
|
- Parâmetros de treinamento corrigidos para melhorar a taxa de utilização da GPU: A100 aumentou de 25% para cerca de 90%, V100: 50% para cerca de 90%, 2060S: 60% para cerca de 85%, P40: 25% para cerca de 95%; melhorou significativamente a velocidade de treinamento
|
||||||
|
- Parâmetro alterado: total batch_size agora é por GPU batch_size
|
||||||
|
- Total_epoch alterado: limite máximo aumentado de 100 para 1000; padrão aumentado de 10 para 20
|
||||||
|
- Corrigido o problema da extração de ckpt que reconhecia o pitch incorretamente, causando inferência anormal
|
||||||
|
- Corrigido o problema do treinamento distribuído que salvava o ckpt para cada classificação
|
||||||
|
- Aplicada a filtragem de recursos nan para extração de recursos
|
||||||
|
- Corrigido o problema com a entrada/saída silenciosa que produzia consoantes aleatórias ou ruído (os modelos antigos precisavam ser treinados novamente com um novo conjunto de dados)
|
||||||
|
|
||||||
|
### Atualização 2023-04-16
|
||||||
|
- Adicionada uma mini-GUI de alteração de voz local em tempo real, iniciada com um clique duplo em go-realtime-gui.bat
|
||||||
|
- Filtragem aplicada para bandas de frequência abaixo de 50 Hz durante o treinamento e a inferência
|
||||||
|
- Diminuição da extração mínima de tom do pyworld do padrão 80 para 50 para treinamento e inferência, permitindo que vozes masculinas de tom baixo entre 50-80 Hz não sejam silenciadas
|
||||||
|
- A WebUI suporta a alteração de idiomas de acordo com a localidade do sistema (atualmente suporta en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; o padrão é en_US se não for suportado)
|
||||||
|
- Correção do reconhecimento de algumas GPUs (por exemplo, falha no reconhecimento da V100-16G, falha no reconhecimento da P4)
|
||||||
|
|
||||||
|
### Atualização de 2023-04-28
|
||||||
|
- Atualizadas as configurações do Index faiss para maior velocidade e qualidade
|
||||||
|
- Removida a dependência do total_npy; o futuro compartilhamento de modelos não exigirá a entrada do total_npy
|
||||||
|
- Restrições desbloqueadas para as GPUs da série 16, fornecendo configurações de inferência de 4 GB para GPUs com VRAM de 4 GB
|
||||||
|
- Corrigido o erro na separação do acompanhamento vocal do UVR5 para determinados formatos de áudio
|
||||||
|
- A mini-GUI de alteração de voz em tempo real agora suporta modelos de pitch não 40k e que não são lentos
|
||||||
|
|
||||||
|
### Planos futuros:
|
||||||
|
Recursos:
|
||||||
|
- Opção de adição: extrair modelos pequenos para cada epoch salvo
|
||||||
|
- Adicionar opção: exportar mp3 adicional para o caminho especificado durante a inferência
|
||||||
|
- Suporte à guia de treinamento para várias pessoas (até 4 pessoas)
|
||||||
|
|
||||||
|
Modelo básico:
|
||||||
|
- Coletar arquivos wav de respiração para adicionar ao conjunto de dados de treinamento para corrigir o problema de sons de respiração distorcidos
|
||||||
|
- No momento, estamos treinando um modelo básico com um conjunto de dados de canto estendido, que será lançado no futuro
|
||||||
193
docs/pt/README.pt.md
Normal file
193
docs/pt/README.pt.md
Normal file
@ -0,0 +1,193 @@
|
|||||||
|
<div align="center">
|
||||||
|
|
||||||
|
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
||||||
|
Uma estrutura de conversão de voz fácil de usar baseada em VITS.<br><br>
|
||||||
|
|
||||||
|
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||||
|
|
||||||
|
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
||||||
|
|
||||||
|
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
||||||
|
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||||
|
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
||||||
|
|
||||||
|
[](https://discord.gg/HcsmBBGyVk)
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
------
|
||||||
|
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/en/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||||
|
|
||||||
|
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||||
|
|
||||||
|
|
||||||
|
Confira nosso [Vídeo de demonstração](https://www.bilibili.com/video/BV1pm4y1z7Gm/) aqui!
|
||||||
|
|
||||||
|
Treinamento/Inferência WebUI:go-web.bat
|
||||||
|

|
||||||
|
|
||||||
|
GUI de conversão de voz em tempo real:go-realtime-gui.bat
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
> O dataset para o modelo de pré-treinamento usa quase 50 horas de conjunto de dados de código aberto VCTK de alta qualidade.
|
||||||
|
|
||||||
|
> Dataset de músicas licenciadas de alta qualidade serão adicionados ao conjunto de treinamento, um após o outro, para seu uso, sem se preocupar com violação de direitos autorais.
|
||||||
|
|
||||||
|
> Aguarde o modelo básico pré-treinado do RVCv3, que possui parâmetros maiores, mais dados de treinamento, melhores resultados, velocidade de inferência inalterada e requer menos dados de treinamento para treinamento.
|
||||||
|
|
||||||
|
## Resumo
|
||||||
|
Este repositório possui os seguintes recursos:
|
||||||
|
+ Reduza o vazamento de tom substituindo o recurso de origem pelo recurso de conjunto de treinamento usando a recuperação top1;
|
||||||
|
+ Treinamento fácil e rápido, mesmo em placas gráficas relativamente ruins;
|
||||||
|
+ Treinar com uma pequena quantidade de dados também obtém resultados relativamente bons (>=10min de áudio com baixo ruído recomendado);
|
||||||
|
+ Suporta fusão de modelos para alterar timbres (usando guia de processamento ckpt-> mesclagem ckpt);
|
||||||
|
+ Interface Webui fácil de usar;
|
||||||
|
+ Use o modelo UVR5 para separar rapidamente vocais e instrumentos.
|
||||||
|
+ Use o mais poderoso algoritmo de extração de voz de alta frequência [InterSpeech2023-RMVPE](#Credits) para evitar o problema de som mudo. Fornece os melhores resultados (significativamente) e é mais rápido, com consumo de recursos ainda menor que o Crepe_full.
|
||||||
|
+ Suporta aceleração de placas gráficas AMD/Intel.
|
||||||
|
+ Aceleração de placas gráficas Intel ARC com suporte para IPEX.
|
||||||
|
|
||||||
|
## Preparando o ambiente
|
||||||
|
Os comandos a seguir precisam ser executados no ambiente Python versão 3.8 ou superior.
|
||||||
|
|
||||||
|
(Windows/Linux)
|
||||||
|
Primeiro instale as dependências principais através do pip:
|
||||||
|
```bash
|
||||||
|
# Instale as dependências principais relacionadas ao PyTorch, pule se instaladas
|
||||||
|
# Referência: https://pytorch.org/get-started/locally/
|
||||||
|
pip install torch torchvision torchaudio
|
||||||
|
|
||||||
|
#Para arquitetura Windows + Nvidia Ampere (RTX30xx), você precisa especificar a versão cuda correspondente ao pytorch de acordo com a experiência de https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/ 21
|
||||||
|
#pip instalar tocha torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||||
|
|
||||||
|
#Para placas Linux + AMD, você precisa usar as seguintes versões do pytorch:
|
||||||
|
#pip instalar tocha torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||||
|
```
|
||||||
|
|
||||||
|
Então pode usar poesia para instalar as outras dependências:
|
||||||
|
```bash
|
||||||
|
# Instale a ferramenta de gerenciamento de dependências Poetry, pule se instalada
|
||||||
|
# Referência: https://python-poetry.org/docs/#installation
|
||||||
|
curl -sSL https://install.python-poetry.org | python3 -
|
||||||
|
|
||||||
|
#Instale as dependências do projeto
|
||||||
|
poetry install
|
||||||
|
```
|
||||||
|
|
||||||
|
Você também pode usar pip para instalá-los:
|
||||||
|
```bash
|
||||||
|
|
||||||
|
for Nvidia graphics cards
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
for AMD/Intel graphics cards on Windows (DirectML):
|
||||||
|
pip install -r requirements-dml.txt
|
||||||
|
|
||||||
|
for Intel ARC graphics cards on Linux / WSL using Python 3.10:
|
||||||
|
pip install -r requirements-ipex.txt
|
||||||
|
|
||||||
|
for AMD graphics cards on Linux (ROCm):
|
||||||
|
pip install -r requirements-amd.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
------
|
||||||
|
Usuários de Mac podem instalar dependências via `run.sh`:
|
||||||
|
```bash
|
||||||
|
sh ./run.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
## Preparação de outros Pré-modelos
|
||||||
|
RVC requer outros pré-modelos para inferir e treinar.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
#Baixe todos os modelos necessários em https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
||||||
|
python tools/download_models.py
|
||||||
|
```
|
||||||
|
|
||||||
|
Ou apenas baixe-os você mesmo em nosso [Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||||
|
|
||||||
|
Aqui está uma lista de pré-modelos e outros arquivos que o RVC precisa:
|
||||||
|
```bash
|
||||||
|
./assets/hubert/hubert_base.pt
|
||||||
|
|
||||||
|
./assets/pretrained
|
||||||
|
|
||||||
|
./assets/uvr5_weights
|
||||||
|
|
||||||
|
Downloads adicionais são necessários se você quiser testar a versão v2 do modelo.
|
||||||
|
|
||||||
|
./assets/pretrained_v2
|
||||||
|
|
||||||
|
Se você deseja testar o modelo da versão v2 (o modelo da versão v2 alterou a entrada do recurso dimensional 256 do Hubert + final_proj de 9 camadas para o recurso dimensional 768 do Hubert de 12 camadas e adicionou 3 discriminadores de período), você precisará baixar recursos adicionais
|
||||||
|
|
||||||
|
./assets/pretrained_v2
|
||||||
|
|
||||||
|
#Se você estiver usando Windows, também pode precisar desses dois arquivos, pule se FFmpeg e FFprobe estiverem instalados
|
||||||
|
ffmpeg.exe
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||||
|
|
||||||
|
ffprobe.exe
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||||
|
|
||||||
|
Se quiser usar o algoritmo de extração de tom vocal SOTA RMVPE mais recente, você precisa baixar os pesos RMVPE e colocá-los no diretório raiz RVC
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||||
|
|
||||||
|
Para usuários de placas gráficas AMD/Intel, você precisa baixar:
|
||||||
|
|
||||||
|
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
Os usuários de placas gráficas Intel ARC precisam executar o comando `source /opt/intel/oneapi/setvars.sh` antes de iniciar o Webui.
|
||||||
|
|
||||||
|
Em seguida, use este comando para iniciar o Webui:
|
||||||
|
```bash
|
||||||
|
python infer-web.py
|
||||||
|
```
|
||||||
|
|
||||||
|
Se estiver usando Windows ou macOS, você pode baixar e extrair `RVC-beta.7z` para usar RVC diretamente usando `go-web.bat` no Windows ou `sh ./run.sh` no macOS para iniciar o Webui.
|
||||||
|
|
||||||
|
## Suporte ROCm para placas gráficas AMD (somente Linux)
|
||||||
|
Para usar o ROCm no Linux, instale todos os drivers necessários conforme descrito [aqui](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||||
|
|
||||||
|
No Arch use pacman para instalar o driver:
|
||||||
|
````
|
||||||
|
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||||
|
````
|
||||||
|
|
||||||
|
Talvez você também precise definir estas variáveis de ambiente (por exemplo, em um RX6700XT):
|
||||||
|
````
|
||||||
|
export ROCM_PATH=/opt/rocm
|
||||||
|
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||||
|
````
|
||||||
|
Verifique também se seu usuário faz parte do grupo `render` e `video`:
|
||||||
|
````
|
||||||
|
sudo usermod -aG render $USERNAME
|
||||||
|
sudo usermod -aG video $USERNAME
|
||||||
|
````
|
||||||
|
Depois disso, você pode executar o WebUI:
|
||||||
|
```bash
|
||||||
|
python infer-web.py
|
||||||
|
```
|
||||||
|
|
||||||
|
## Credits
|
||||||
|
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||||
|
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||||
|
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
||||||
|
+ [Gradio](https://github.com/gradio-app/gradio)
|
||||||
|
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
||||||
|
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
||||||
|
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
||||||
|
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
||||||
|
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
||||||
|
|
||||||
|
## Thanks to all contributors for their efforts
|
||||||
|
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
||||||
|
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
||||||
|
</a>
|
||||||
|
|
||||||
102
docs/pt/faiss_tips_pt.md
Normal file
102
docs/pt/faiss_tips_pt.md
Normal file
@ -0,0 +1,102 @@
|
|||||||
|
pONTAS de afinação FAISS
|
||||||
|
==================
|
||||||
|
# sobre faiss
|
||||||
|
faiss é uma biblioteca de pesquisas de vetores densos na área, desenvolvida pela pesquisa do facebook, que implementa com eficiência muitos métodos de pesquisa de área aproximada.
|
||||||
|
A Pesquisa Aproximada de área encontra vetores semelhantes rapidamente, sacrificando alguma precisão.
|
||||||
|
|
||||||
|
## faiss em RVC
|
||||||
|
No RVC, para a incorporação de recursos convertidos pelo HuBERT, buscamos incorporações semelhantes à incorporação gerada a partir dos dados de treinamento e as misturamos para obter uma conversão mais próxima do discurso original. No entanto, como essa pesquisa leva tempo se realizada de forma ingênua, a conversão de alta velocidade é realizada usando a pesquisa aproximada de área.
|
||||||
|
|
||||||
|
# visão geral da implementação
|
||||||
|
Em '/logs/nome-do-seu-modelo/3_feature256', onde o modelo está localizado, os recursos extraídos pelo HuBERT de cada dado de voz estão localizados.
|
||||||
|
A partir daqui, lemos os arquivos npy ordenados por nome de arquivo e concatenamos os vetores para criar big_npy. (Este vetor tem a forma [N, 256].)
|
||||||
|
Depois de salvar big_npy as /logs/nome-do-seu-modelo/total_fea.npy, treine-o com faiss.
|
||||||
|
|
||||||
|
Neste artigo, explicarei o significado desses parâmetros.
|
||||||
|
|
||||||
|
# Explicação do método
|
||||||
|
## Fábrica de Index
|
||||||
|
Uma fábrica de Index é uma notação faiss exclusiva que expressa um pipeline que conecta vários métodos de pesquisa de área aproximados como uma string.
|
||||||
|
Isso permite que você experimente vários métodos aproximados de pesquisa de área simplesmente alterando a cadeia de caracteres de fábrica do Index.
|
||||||
|
No RVC é usado assim:
|
||||||
|
|
||||||
|
```python
|
||||||
|
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
||||||
|
```
|
||||||
|
Entre os argumentos de index_factory, o primeiro é o número de dimensões do vetor, o segundo é a string de fábrica do Index e o terceiro é a distância a ser usada.
|
||||||
|
|
||||||
|
Para uma notação mais detalhada
|
||||||
|
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
||||||
|
|
||||||
|
## Construção de Index
|
||||||
|
Existem dois Indexs típicos usados como similaridade de incorporação da seguinte forma.
|
||||||
|
|
||||||
|
- Distância euclidiana (MÉTRICA_L2)
|
||||||
|
- Produto interno (METRIC_INNER_PRODUCT)
|
||||||
|
|
||||||
|
A distância euclidiana toma a diferença quadrática em cada dimensão, soma as diferenças em todas as dimensões e, em seguida, toma a raiz quadrada. Isso é o mesmo que a distância em 2D e 3D que usamos diariamente.
|
||||||
|
O produto interno não é usado como um Index de similaridade como é, e a similaridade de cosseno que leva o produto interno depois de ser normalizado pela norma L2 é geralmente usada.
|
||||||
|
|
||||||
|
O que é melhor depende do caso, mas a similaridade de cosseno é frequentemente usada na incorporação obtida pelo word2vec e modelos de recuperação de imagem semelhantes aprendidos pelo ArcFace. Se você quiser fazer a normalização l2 no vetor X com numpy, você pode fazê-lo com o seguinte código com eps pequeno o suficiente para evitar a divisão 0.
|
||||||
|
|
||||||
|
```python
|
||||||
|
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
||||||
|
```
|
||||||
|
|
||||||
|
Além disso, para a Construção de Index, você pode alterar o Index de distância usado para cálculo escolhendo o valor a ser passado como o terceiro argumento.
|
||||||
|
|
||||||
|
```python
|
||||||
|
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
||||||
|
```
|
||||||
|
|
||||||
|
## FI
|
||||||
|
IVF (Inverted file indexes) é um algoritmo semelhante ao Index invertido na pesquisa de texto completo.
|
||||||
|
Durante o aprendizado, o destino da pesquisa é agrupado com kmeans e o particionamento Voronoi é realizado usando o centro de cluster. A cada ponto de dados é atribuído um cluster, por isso criamos um dicionário que procura os pontos de dados dos clusters.
|
||||||
|
|
||||||
|
Por exemplo, se os clusters forem atribuídos da seguinte forma
|
||||||
|
|index|Cluster|
|
||||||
|
|-----|-------|
|
||||||
|
|1|A|
|
||||||
|
|2|B|
|
||||||
|
|3|A|
|
||||||
|
|4|C|
|
||||||
|
|5|B|
|
||||||
|
|
||||||
|
O Index invertido resultante se parece com isso:
|
||||||
|
|
||||||
|
| cluster | Index |
|
||||||
|
|-------|-----|
|
||||||
|
| A | 1, 3 |
|
||||||
|
| B | 2 5 |
|
||||||
|
| C | 4 |
|
||||||
|
|
||||||
|
Ao pesquisar, primeiro pesquisamos n_probe clusters dos clusters e, em seguida, calculamos as distâncias para os pontos de dados pertencentes a cada cluster.
|
||||||
|
|
||||||
|
# Parâmetro de recomendação
|
||||||
|
Existem diretrizes oficiais sobre como escolher um Index, então vou explicar de
|
||||||
|
acordo. https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
||||||
|
|
||||||
|
Para conjuntos de dados abaixo de 1M, o 4bit-PQ é o método mais eficiente disponível no faiss em abril de 2023.
|
||||||
|
Combinando isso com a fertilização in vitro, estreitando os candidatos com 4bit-PQ e, finalmente, recalcular a distância com um Index preciso pode ser descrito usando a seguinte fábrica de Indexs.
|
||||||
|
|
||||||
|
```python
|
||||||
|
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
||||||
|
```
|
||||||
|
|
||||||
|
## Parâmetros recomendados para FIV
|
||||||
|
Considere o caso de muitas FIVs. Por exemplo, se a quantização grosseira por FIV for realizada para o número de dados, isso é o mesmo que uma pesquisa exaustiva ingênua e é ineficiente.
|
||||||
|
Para 1M ou menos, os valores de FIV são recomendados entre 4*sqrt(N) ~ 16*sqrt(N) para N número de pontos de dados.
|
||||||
|
|
||||||
|
Como o tempo de cálculo aumenta proporcionalmente ao número de n_sondas, consulte a precisão e escolha adequadamente. Pessoalmente, não acho que o RVC precise de tanta precisão, então n_probe = 1 está bem.
|
||||||
|
|
||||||
|
## FastScan
|
||||||
|
O FastScan é um método que permite a aproximação de alta velocidade de distâncias por quantização de produto cartesiano, realizando-as em registros.
|
||||||
|
A quantização cartesiana do produto executa o agrupamento independentemente para cada dimensão d (geralmente d = 2) durante o aprendizado, calcula a distância entre os agrupamentos com antecedência e cria uma tabela de pesquisa. No momento da previsão, a distância de cada dimensão pode ser calculada em O(1) olhando para a tabela de pesquisa.
|
||||||
|
Portanto, o número que você especifica após PQ geralmente especifica metade da dimensão do vetor.
|
||||||
|
|
||||||
|
Para uma descrição mais detalhada do FastScan, consulte a documentação oficial.
|
||||||
|
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
||||||
|
|
||||||
|
## RFlat
|
||||||
|
RFlat é uma instrução para recalcular a distância aproximada calculada pelo FastScan com a distância exata especificada pelo terceiro argumento da Construção de Index.
|
||||||
|
Ao obter áreas k, os pontos k*k_factor são recalculados.
|
||||||
224
docs/pt/faq_pt.md
Normal file
224
docs/pt/faq_pt.md
Normal file
@ -0,0 +1,224 @@
|
|||||||
|
# <b>FAQ AI HUB BRASIL</b>
|
||||||
|
## <span style="color: #337dff;">O que é epoch, quantos utilizar, quanto de dataset utilizar e qual à configuração interessante?</span>
|
||||||
|
Epochs basicamente quantas vezes o seu dataset foi treinado.
|
||||||
|
|
||||||
|
Recomendado ler Q8 e Q9 no final dessa página pra entender mais sobre dataset e epochs
|
||||||
|
|
||||||
|
__**Não é uma regra, mas opinião:**__
|
||||||
|
|
||||||
|
### **Mangio-Crepe Hop Length**
|
||||||
|
- 64 pra cantores e dubladores
|
||||||
|
- 128(padrão) para os demais (editado)
|
||||||
|
|
||||||
|
### **Epochs e dataset**
|
||||||
|
600epoch para cantores - --dataset entre 10 e 50 min desnecessario mais que 50 minutos--
|
||||||
|
300epoch para os demais - --dataset entre 10 e 50 min desnecessario mais que 50 minutos--
|
||||||
|
|
||||||
|
### **Tom**
|
||||||
|
magio-crepe se for audios extraído de alguma musica
|
||||||
|
harvest se for de estúdio<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">O que é index?</span>
|
||||||
|
Basicamente o que define o sotaque. Quanto maior o numero, mas próximo o sotaque fica do original. Porém, quando o modelo é bem, não é necessário um index.<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">O que significa cada sigla (pm, harvest, crepe, magio-crepe, RMVPE)?</span>
|
||||||
|
|
||||||
|
- pm = extração mais rápida, mas discurso de qualidade inferior;
|
||||||
|
- harvest = graves melhores, mas extremamente lentos;
|
||||||
|
- dio = conversão rápida mas pitch ruim;
|
||||||
|
- crepe = melhor qualidade, mas intensivo em GPU;
|
||||||
|
- crepe-tiny = mesma coisa que o crepe, só que com a qualidade um pouco inferior;
|
||||||
|
- **mangio-crepe = melhor qualidade, mais otimizado; (MELHOR OPÇÃO)**
|
||||||
|
- mangio-crepe-tiny = mesma coisa que o mangio-crepe, só que com a qualidade um pouco inferior;
|
||||||
|
- RMVPE: um modelo robusto para estimativa de afinação vocal em música polifônica;<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">Pra rodar localmente, quais os requisitos minimos?</span>
|
||||||
|
Já tivemos relatos de pessoas com GTX 1050 rodando inferencia, se for treinar numa 1050 vai demorar muito mesmo e inferior a isso, normalmente da tela azul
|
||||||
|
|
||||||
|
O mais importante é placa de vídeo, vram na verdade
|
||||||
|
Se você tiver 4GB ou mais, você tem uma chance.
|
||||||
|
|
||||||
|
**NOS DOIS CASOS NÃO É RECOMENDADO UTILIZAR O PC ENQUANTO ESTÁ UTILIZNDO, CHANCE DE TELA AZUL É ALTA**
|
||||||
|
### Inference
|
||||||
|
Não é algo oficial para requisitos minimos
|
||||||
|
- Placa de vídeo: nvidia de 4gb
|
||||||
|
- Memoria ram: 8gb
|
||||||
|
- CPU: ?
|
||||||
|
- Armanezamento: 20gb (sem modelos)
|
||||||
|
|
||||||
|
### Treinamento de voz
|
||||||
|
Não é algo oficial para requisitos minimos
|
||||||
|
- Placa de vídeo: nvidia de 6gb
|
||||||
|
- Memoria ram: 16gb
|
||||||
|
- CPU: ?
|
||||||
|
- Armanezamento: 20gb (sem modelos)<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">Limite de GPU no Google Colab excedido, apenas CPU o que fazer?</span>
|
||||||
|
Recomendamos esperar outro dia pra liberar mais 15gb ou 12 horas pra você. Ou você pode contribuir com o Google pagando algum dos planos, ai aumenta seu limite.<br>
|
||||||
|
Utilizar apenas CPU no Google Colab demora DEMAIS.<hr>
|
||||||
|
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">Google Colab desconectando com muita frequencia, o que fazer?</span>
|
||||||
|
Neste caso realmente não tem muito o que fazer. Apenas aguardar o proprietário do código corrigir ou a gente do AI HUB Brasil achar alguma solução. Isso acontece por diversos motivos, um incluindo a Google barrando o treinamento de voz.<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">O que é Batch Size/Tamanho de lote e qual numero utilizar?</span>
|
||||||
|
Batch Size/Tamanho do lote é basicamente quantos epoch faz ao mesmo tempo. Se por 20, ele fazer 20 epoch ao mesmo tempo e isso faz pesar mais na máquina e etc.<br>
|
||||||
|
|
||||||
|
No Google Colab você pode utilizar até 20 de boa.<br>
|
||||||
|
Se rodando localmente, depende da sua placa de vídeo, começa por baixo (6) e vai testando.<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">Sobre backup na hora do treinamento</span>
|
||||||
|
Backup vai de cada um. Eu quando uso a ``easierGUI`` utilizo a cada 100 epoch (meu caso isolado).
|
||||||
|
No colab, se instavel, coloque a cada 10 epoch
|
||||||
|
Recomendo utilizarem entre 25 e 50 pra garantir.
|
||||||
|
|
||||||
|
Lembrando que cada arquivo geral é por volta de 50mb, então tenha muito cuidado quanto você coloca. Pois assim pode acabar lotando seu Google Drive ou seu PC.
|
||||||
|
|
||||||
|
Depois de finalizado, da pra apagar os epoch de backup.<hr>
|
||||||
|
|
||||||
|
## <span style="color: #337dff;">Como continuar da onde parou pra fazer mais epochs?</span>
|
||||||
|
Primeira coisa que gostaria de lembrar, não necessariamente quanto mais epochs melhor. Se fizer epochs demais vai dar **overtraining** o que pode ser ruim.
|
||||||
|
|
||||||
|
### GUI NORMAL
|
||||||
|
- Inicie normalmente a GUI novamente.
|
||||||
|
- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
|
||||||
|
- Ignore as opções ``Processar o Conjunto de dados`` e ``Extrair Tom``
|
||||||
|
- Antes de clicar pra treinar, arrume os epoch, bakcup e afins.
|
||||||
|
- Obviamente tem que ser um numero maior do qu estava em epoch.
|
||||||
|
- Backup você pode aumentar ou diminuir
|
||||||
|
- Agora você vai ver a opção ``Carregue o caminho G do modelo base pré-treinado:`` e ``Carregue o caminho D do modelo base pré-treinado:``
|
||||||
|
-Aqui você vai por o caminho dos modelos que estão em ``./logs/minha-voz``
|
||||||
|
- Vai ficar algo parecido com isso ``e:/RVC/logs/minha-voz/G_0000.pth`` e ``e:/RVC/logs/minha-voz/D_0000.pth``
|
||||||
|
-Coloque pra treinar
|
||||||
|
|
||||||
|
**Lembrando que a pasta logs tem que ter todos os arquivos e não somente o arquivo ``G`` e ``D``**
|
||||||
|
|
||||||
|
### EasierGUI
|
||||||
|
- Inicie normalmente a easierGUI novamente.
|
||||||
|
- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
|
||||||
|
- Selecione 'Treinar modelo', pode pular os 2 primeiros passos já que vamos continuar o treino.<hr><br>
|
||||||
|
|
||||||
|
|
||||||
|
# <b>FAQ Original traduzido</b>
|
||||||
|
## <b><span style="color: #337dff;">Q1: erro ffmpeg/erro utf8.</span></b>
|
||||||
|
Provavelmente não é um problema do FFmpeg, mas sim um problema de caminho de áudio;
|
||||||
|
|
||||||
|
O FFmpeg pode encontrar um erro ao ler caminhos contendo caracteres especiais como spaces e (), o que pode causar um erro FFmpeg; e quando o áudio do conjunto de treinamento contém caminhos chineses, gravá-lo em filelist.txt pode causar um erro utf8.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q2:Não é possível encontrar o arquivo de Index após "Treinamento com um clique".</span></b>
|
||||||
|
Se exibir "O treinamento está concluído. O programa é fechado ", então o modelo foi treinado com sucesso e os erros subsequentes são falsos;
|
||||||
|
|
||||||
|
A falta de um arquivo de index 'adicionado' após o treinamento com um clique pode ser devido ao conjunto de treinamento ser muito grande, fazendo com que a adição do index fique presa; isso foi resolvido usando o processamento em lote para adicionar o index, o que resolve o problema de sobrecarga de memória ao adicionar o index. Como solução temporária, tente clicar no botão "Treinar Index" novamente.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q3:Não é possível encontrar o modelo em “Modelo de voz” após o treinamento</span></b>
|
||||||
|
Clique em "Atualizar lista de voz" ou "Atualizar na EasyGUI e verifique novamente; se ainda não estiver visível, verifique se há erros durante o treinamento e envie capturas de tela do console, da interface do usuário da Web e dos ``logs/experiment_name/*.log`` para os desenvolvedores para análise posterior.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q4:Como compartilhar um modelo/Como usar os modelos dos outros?</span></b>
|
||||||
|
Os arquivos ``.pth`` armazenados em ``*/logs/minha-voz`` não são destinados para compartilhamento ou inference, mas para armazenar os checkpoits do experimento para reprodutibilidade e treinamento adicional. O modelo a ser compartilhado deve ser o arquivo ``.pth`` de 60+MB na pasta **weights**;
|
||||||
|
|
||||||
|
No futuro, ``weights/minha-voz.pth`` e ``logs/minha-voz/added_xxx.index`` serão mesclados em um único arquivo de ``weights/minha-voz.zip`` para eliminar a necessidade de entrada manual de index; portanto, compartilhe o arquivo zip, não somente o arquivo .pth, a menos que você queira continuar treinando em uma máquina diferente;
|
||||||
|
|
||||||
|
Copiar/compartilhar os vários arquivos .pth de centenas de MB da pasta de logs para a pasta de weights para inference forçada pode resultar em erros como falta de f0, tgt_sr ou outras chaves. Você precisa usar a guia ckpt na parte inferior para manualmente ou automaticamente (se as informações forem encontradas nos ``logs/minha-voz``), selecione se deseja incluir informações de tom e opções de taxa de amostragem de áudio de destino e, em seguida, extrair o modelo menor. Após a extração, haverá um arquivo pth de 60+ MB na pasta de weights, e você pode atualizar as vozes para usá-lo.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q5 Erro de conexão:</span></b>
|
||||||
|
Para sermos otimistas, aperte F5/recarregue a página, pode ter sido apenas um bug da GUI
|
||||||
|
|
||||||
|
Se não...
|
||||||
|
Você pode ter fechado o console (janela de linha de comando preta).
|
||||||
|
Ou o Google Colab, no caso do Colab, as vezes pode simplesmente fechar<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q6: Pop-up WebUI 'Valor esperado: linha 1 coluna 1 (caractere 0)'.</span></b>
|
||||||
|
Desative o proxy LAN do sistema/proxy global e atualize.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q7:Como treinar e inferir sem a WebUI?</span></b>
|
||||||
|
Script de treinamento:
|
||||||
|
<br>Você pode executar o treinamento em WebUI primeiro, e as versões de linha de comando do pré-processamento e treinamento do conjunto de dados serão exibidas na janela de mensagens.<br>
|
||||||
|
|
||||||
|
Script de inference:
|
||||||
|
<br>https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
||||||
|
|
||||||
|
|
||||||
|
por exemplo<br>
|
||||||
|
|
||||||
|
``runtime\python.exe myinfer.py 0 "E:\audios\1111.wav" "E:\RVC\logs\minha-voz\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True``<br>
|
||||||
|
|
||||||
|
|
||||||
|
f0up_key=sys.argv[1]<br>
|
||||||
|
input_path=sys.argv[2]<br>
|
||||||
|
index_path=sys.argv[3]<br>
|
||||||
|
f0method=sys.argv[4]#harvest or pm<br>
|
||||||
|
opt_path=sys.argv[5]<br>
|
||||||
|
model_path=sys.argv[6]<br>
|
||||||
|
index_rate=float(sys.argv[7])<br>
|
||||||
|
device=sys.argv[8]<br>
|
||||||
|
is_half=bool(sys.argv[9])<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q8: Erro Cuda/Cuda sem memória.</span></b>
|
||||||
|
Há uma pequena chance de que haja um problema com a configuração do CUDA ou o dispositivo não seja suportado; mais provavelmente, não há memória suficiente (falta de memória).<br>
|
||||||
|
|
||||||
|
Para treinamento, reduza o (batch size) tamanho do lote (se reduzir para 1 ainda não for suficiente, talvez seja necessário alterar a placa gráfica); para inference, ajuste as configurações x_pad, x_query, x_center e x_max no arquivo config.py conforme necessário. Cartões de memória 4G ou inferiores (por exemplo, 1060(3G) e várias placas 2G) podem ser abandonados, enquanto os placas de vídeo com memória 4G ainda têm uma chance.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q9:Quantos total_epoch são ótimos?</span></b>
|
||||||
|
Se a qualidade de áudio do conjunto de dados de treinamento for ruim e o nível de ruído for alto, **20-30 epochs** são suficientes. Defini-lo muito alto não melhorará a qualidade de áudio do seu conjunto de treinamento de baixa qualidade.<br>
|
||||||
|
|
||||||
|
Se a qualidade de áudio do conjunto de treinamento for alta, o nível de ruído for baixo e houver duração suficiente, você poderá aumentá-lo. **200 é aceitável** (uma vez que o treinamento é rápido e, se você puder preparar um conjunto de treinamento de alta qualidade, sua GPU provavelmente poderá lidar com uma duração de treinamento mais longa sem problemas).<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q10:Quanto tempo de treinamento é necessário?</span></b>
|
||||||
|
|
||||||
|
**Recomenda-se um conjunto de dados de cerca de 10 min a 50 min.**<br>
|
||||||
|
|
||||||
|
Com garantia de alta qualidade de som e baixo ruído de fundo, mais pode ser adicionado se o timbre do conjunto de dados for uniforme.<br>
|
||||||
|
|
||||||
|
Para um conjunto de treinamento de alto nível (limpo + distintivo), 5min a 10min é bom.<br>
|
||||||
|
|
||||||
|
Há algumas pessoas que treinaram com sucesso com dados de 1 a 2 minutos, mas o sucesso não é reproduzível por outros e não é muito informativo. <br>Isso requer que o conjunto de treinamento tenha um timbre muito distinto (por exemplo, um som de menina de anime arejado de alta frequência) e a qualidade do áudio seja alta;
|
||||||
|
Dados com menos de 1 minuto, já obtivemo sucesso. Mas não é recomendado.<hr>
|
||||||
|
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q11:Qual é a taxa do index e como ajustá-la?</span></b>
|
||||||
|
Se a qualidade do tom do modelo pré-treinado e da fonte de inference for maior do que a do conjunto de treinamento, eles podem trazer a qualidade do tom do resultado do inference, mas ao custo de um possível viés de tom em direção ao tom do modelo subjacente/fonte de inference, em vez do tom do conjunto de treinamento, que é geralmente referido como "vazamento de tom".<br>
|
||||||
|
|
||||||
|
A taxa de index é usada para reduzir/resolver o problema de vazamento de timbre. Se a taxa do index for definida como 1, teoricamente não há vazamento de timbre da fonte de inference e a qualidade do timbre é mais tendenciosa em relação ao conjunto de treinamento. Se o conjunto de treinamento tiver uma qualidade de som mais baixa do que a fonte de inference, uma taxa de index mais alta poderá reduzir a qualidade do som. Reduzi-lo a 0 não tem o efeito de usar a mistura de recuperação para proteger os tons definidos de treinamento.<br>
|
||||||
|
|
||||||
|
Se o conjunto de treinamento tiver boa qualidade de áudio e longa duração, aumente o total_epoch, quando o modelo em si é menos propenso a se referir à fonte inferida e ao modelo subjacente pré-treinado, e há pouco "vazamento de tom", o index_rate não é importante e você pode até não criar/compartilhar o arquivo de index.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q12:Como escolher o GPU ao inferir?</span></b>
|
||||||
|
No arquivo ``config.py``, selecione o número da placa em "device cuda:".<br>
|
||||||
|
|
||||||
|
O mapeamento entre o número da placa e a placa gráfica pode ser visto na seção de informações da placa gráfica da guia de treinamento.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q13:Como usar o modelo salvo no meio do treinamento?</span></b>
|
||||||
|
Salvar via extração de modelo na parte inferior da guia de processamento do ckpt.<hr>
|
||||||
|
|
||||||
|
## <b><span style="color: #337dff;">Q14: Erro de arquivo/memória (durante o treinamento)?</span></b>
|
||||||
|
Muitos processos e sua memória não é suficiente. Você pode corrigi-lo por:
|
||||||
|
|
||||||
|
1. Diminuir a entrada no campo "Threads da CPU".
|
||||||
|
2. Diminuir o tamanho do conjunto de dados.
|
||||||
|
|
||||||
|
## Q15: Como continuar treinando usando mais dados
|
||||||
|
|
||||||
|
passo 1: coloque todos os dados wav no path2.
|
||||||
|
|
||||||
|
etapa 2: exp_name2 + path2 -> processar conjunto de dados e extrair recurso.
|
||||||
|
|
||||||
|
passo 3: copie o arquivo G e D mais recente de exp_name1 (seu experimento anterior) para a pasta exp_name2.
|
||||||
|
|
||||||
|
passo 4: clique em "treinar o modelo" e ele continuará treinando desde o início da época anterior do modelo exp.
|
||||||
|
|
||||||
|
## Q16: erro sobre llvmlite.dll
|
||||||
|
|
||||||
|
OSError: Não foi possível carregar o arquivo de objeto compartilhado: llvmlite.dll
|
||||||
|
|
||||||
|
FileNotFoundError: Não foi possível encontrar o módulo lib\site-packages\llvmlite\binding\llvmlite.dll (ou uma de suas dependências). Tente usar o caminho completo com sintaxe de construtor.
|
||||||
|
|
||||||
|
O problema acontecerá no Windows, instale https://aka.ms/vs/17/release/vc_redist.x64.exe e será corrigido.
|
||||||
|
|
||||||
|
## Q17: RuntimeError: O tamanho expandido do tensor (17280) deve corresponder ao tamanho existente (0) na dimensão 1 não singleton. Tamanhos de destino: [1, 17280]. Tamanhos de tensor: [0]
|
||||||
|
|
||||||
|
Exclua os arquivos wav cujo tamanho seja significativamente menor que outros e isso não acontecerá novamente. Em seguida, clique em "treinar o modelo" e "treinar o índice".
|
||||||
|
|
||||||
|
## Q18: RuntimeError: O tamanho do tensor a (24) deve corresponder ao tamanho do tensor b (16) na dimensão não singleton 2
|
||||||
|
|
||||||
|
Não altere a taxa de amostragem e continue o treinamento. Caso seja necessário alterar, o nome do exp deverá ser alterado e o modelo será treinado do zero. Você também pode copiar o pitch e os recursos (pastas 0/1/2/2b) extraídos da última vez para acelerar o processo de treinamento.
|
||||||
|
|
||||||
65
docs/pt/training_tips_pt.md
Normal file
65
docs/pt/training_tips_pt.md
Normal file
@ -0,0 +1,65 @@
|
|||||||
|
Instruções e dicas para treinamento RVC
|
||||||
|
======================================
|
||||||
|
Estas DICAS explicam como o treinamento de dados é feito.
|
||||||
|
|
||||||
|
# Fluxo de treinamento
|
||||||
|
Explicarei ao longo das etapas na guia de treinamento da GUI.
|
||||||
|
|
||||||
|
## Passo 1
|
||||||
|
Defina o nome do experimento aqui.
|
||||||
|
|
||||||
|
Você também pode definir aqui se o modelo deve levar em consideração o pitch.
|
||||||
|
Se o modelo não considerar o tom, o modelo será mais leve, mas não será adequado para cantar.
|
||||||
|
|
||||||
|
Os dados de cada experimento são colocados em `/logs/nome-do-seu-modelo/`.
|
||||||
|
|
||||||
|
## Passo 2a
|
||||||
|
Carrega e pré-processa áudio.
|
||||||
|
|
||||||
|
### Carregar áudio
|
||||||
|
Se você especificar uma pasta com áudio, os arquivos de áudio dessa pasta serão lidos automaticamente.
|
||||||
|
Por exemplo, se você especificar `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` será carregado, mas `C:Users\hoge\voices\dir\voice.mp3` será Não carregado.
|
||||||
|
|
||||||
|
Como o ffmpeg é usado internamente para leitura de áudio, se a extensão for suportada pelo ffmpeg, ela será lida automaticamente.
|
||||||
|
Após converter para int16 com ffmpeg, converta para float32 e normalize entre -1 e 1.
|
||||||
|
|
||||||
|
### Eliminar ruído
|
||||||
|
O áudio é suavizado pelo filtfilt do scipy.
|
||||||
|
|
||||||
|
### Divisão de áudio
|
||||||
|
Primeiro, o áudio de entrada é dividido pela detecção de partes de silêncio que duram mais que um determinado período (max_sil_kept=5 segundos?). Após dividir o áudio no silêncio, divida o áudio a cada 4 segundos com uma sobreposição de 0,3 segundos. Para áudio separado em 4 segundos, após normalizar o volume, converta o arquivo wav para `/logs/nome-do-seu-modelo/0_gt_wavs` e, em seguida, converta-o para taxa de amostragem de 16k para `/logs/nome-do-seu-modelo/1_16k_wavs ` como um arquivo wav.
|
||||||
|
|
||||||
|
## Passo 2b
|
||||||
|
### Extrair pitch
|
||||||
|
Extraia informações de pitch de arquivos wav. Extraia as informações de pitch (=f0) usando o método incorporado em Parselmouth ou pyworld e salve-as em `/logs/nome-do-seu-modelo/2a_f0`. Em seguida, converta logaritmicamente as informações de pitch para um número inteiro entre 1 e 255 e salve-as em `/logs/nome-do-seu-modelo/2b-f0nsf`.
|
||||||
|
|
||||||
|
### Extrair feature_print
|
||||||
|
Converta o arquivo wav para incorporação antecipadamente usando HuBERT. Leia o arquivo wav salvo em `/logs/nome-do-seu-modelo/1_16k_wavs`, converta o arquivo wav em recursos de 256 dimensões com HuBERT e salve no formato npy em `/logs/nome-do-seu-modelo/3_feature256`.
|
||||||
|
|
||||||
|
## Passo 3
|
||||||
|
treinar o modelo.
|
||||||
|
### Glossário para iniciantes
|
||||||
|
No aprendizado profundo, o conjunto de dados é dividido e o aprendizado avança aos poucos. Em uma atualização do modelo (etapa), os dados batch_size são recuperados e previsões e correções de erros são realizadas. Fazer isso uma vez para um conjunto de dados conta como um epoch.
|
||||||
|
|
||||||
|
Portanto, o tempo de aprendizagem é o tempo de aprendizagem por etapa x (o número de dados no conjunto de dados/tamanho do lote) x o número de epoch. Em geral, quanto maior o tamanho do lote, mais estável se torna o aprendizado (tempo de aprendizado por etapa ÷ tamanho do lote) fica menor, mas usa mais memória GPU. A RAM da GPU pode ser verificada com o comando nvidia-smi. O aprendizado pode ser feito em pouco tempo aumentando o tamanho do lote tanto quanto possível de acordo com a máquina do ambiente de execução.
|
||||||
|
|
||||||
|
### Especifique o modelo pré-treinado
|
||||||
|
O RVC começa a treinar o modelo a partir de pesos pré-treinados em vez de 0, para que possa ser treinado com um pequeno conjunto de dados.
|
||||||
|
|
||||||
|
Por padrão
|
||||||
|
|
||||||
|
- Se você considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
|
||||||
|
- Se você não considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
|
||||||
|
|
||||||
|
Ao aprender, os parâmetros do modelo são salvos em `logs/nome-do-seu-modelo/G_{}.pth` e `logs/nome-do-seu-modelo/D_{}.pth` para cada save_every_epoch, mas especificando nesse caminho, você pode começar a aprender. Você pode reiniciar ou iniciar o treinamento a partir de weights de modelo aprendidos em um experimento diferente.
|
||||||
|
|
||||||
|
### Index de aprendizado
|
||||||
|
O RVC salva os valores de recursos do HuBERT usados durante o treinamento e, durante a inferência, procura valores de recursos que sejam semelhantes aos valores de recursos usados durante o aprendizado para realizar a inferência. Para realizar esta busca em alta velocidade, o index é aprendido previamente.
|
||||||
|
Para aprendizagem de index, usamos a biblioteca de pesquisa de associação de áreas aproximadas faiss. Leia o valor do recurso `logs/nome-do-seu-modelo/3_feature256` e use-o para aprender o index, e salve-o como `logs/nome-do-seu-modelo/add_XXX.index`.
|
||||||
|
|
||||||
|
(A partir da versão 20230428update, ele é lido do index e não é mais necessário salvar/especificar.)
|
||||||
|
|
||||||
|
### Descrição do botão
|
||||||
|
- Treinar modelo: Após executar o passo 2b, pressione este botão para treinar o modelo.
|
||||||
|
- Treinar índice de recursos: após treinar o modelo, execute o aprendizado do index.
|
||||||
|
- Treinamento com um clique: etapa 2b, treinamento de modelo e treinamento de index de recursos, tudo de uma vez.
|
||||||
@ -18,7 +18,7 @@ VITS'e dayalı kullanımı kolay bir Ses Dönüşümü çerçevesi.<br><br>
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
------
|
------
|
||||||
[**Değişiklik Geçmişi**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
[**Değişiklik Geçmişi**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/tr/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||||
|
|
||||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||||
|
|
||||||
|
|||||||
204
gui_v1.py
204
gui_v1.py
@ -1,6 +1,7 @@
|
|||||||
import os
|
import os
|
||||||
import sys
|
import sys
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
|
import shutil
|
||||||
|
|
||||||
load_dotenv()
|
load_dotenv()
|
||||||
|
|
||||||
@ -125,6 +126,8 @@ if __name__ == "__main__":
|
|||||||
self.index_rate: float = 0.0
|
self.index_rate: float = 0.0
|
||||||
self.n_cpu: int = min(n_cpu, 4)
|
self.n_cpu: int = min(n_cpu, 4)
|
||||||
self.f0method: str = "fcpe"
|
self.f0method: str = "fcpe"
|
||||||
|
self.sg_hostapi: str = ""
|
||||||
|
self.wasapi_exclusive: bool = False
|
||||||
self.sg_input_device: str = ""
|
self.sg_input_device: str = ""
|
||||||
self.sg_output_device: str = ""
|
self.sg_output_device: str = ""
|
||||||
|
|
||||||
@ -134,6 +137,7 @@ if __name__ == "__main__":
|
|||||||
self.config = Config()
|
self.config = Config()
|
||||||
self.function = "vc"
|
self.function = "vc"
|
||||||
self.delay_time = 0
|
self.delay_time = 0
|
||||||
|
self.hostapis = None
|
||||||
self.input_devices = None
|
self.input_devices = None
|
||||||
self.output_devices = None
|
self.output_devices = None
|
||||||
self.input_devices_indices = None
|
self.input_devices_indices = None
|
||||||
@ -144,7 +148,9 @@ if __name__ == "__main__":
|
|||||||
|
|
||||||
def load(self):
|
def load(self):
|
||||||
try:
|
try:
|
||||||
with open("configs/config.json", "r") as j:
|
if not os.path.exists("configs/inuse/config.json"):
|
||||||
|
shutil.copy("configs/config.json", "configs/inuse/config.json")
|
||||||
|
with open("configs/inuse/config.json", "r") as j:
|
||||||
data = json.load(j)
|
data = json.load(j)
|
||||||
data["sr_model"] = data["sr_type"] == "sr_model"
|
data["sr_model"] = data["sr_type"] == "sr_model"
|
||||||
data["sr_device"] = data["sr_type"] == "sr_device"
|
data["sr_device"] = data["sr_type"] == "sr_device"
|
||||||
@ -153,19 +159,35 @@ if __name__ == "__main__":
|
|||||||
data["crepe"] = data["f0method"] == "crepe"
|
data["crepe"] = data["f0method"] == "crepe"
|
||||||
data["rmvpe"] = data["f0method"] == "rmvpe"
|
data["rmvpe"] = data["f0method"] == "rmvpe"
|
||||||
data["fcpe"] = data["f0method"] == "fcpe"
|
data["fcpe"] = data["f0method"] == "fcpe"
|
||||||
if data["sg_input_device"] not in self.input_devices:
|
if data["sg_hostapi"] in self.hostapis:
|
||||||
|
self.update_devices(hostapi_name=data["sg_hostapi"])
|
||||||
|
if (
|
||||||
|
data["sg_input_device"] not in self.input_devices
|
||||||
|
or data["sg_output_device"] not in self.output_devices
|
||||||
|
):
|
||||||
|
self.update_devices()
|
||||||
|
data["sg_hostapi"] = self.hostapis[0]
|
||||||
|
data["sg_input_device"] = self.input_devices[
|
||||||
|
self.input_devices_indices.index(sd.default.device[0])
|
||||||
|
]
|
||||||
|
data["sg_output_device"] = self.output_devices[
|
||||||
|
self.output_devices_indices.index(sd.default.device[1])
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
data["sg_hostapi"] = self.hostapis[0]
|
||||||
data["sg_input_device"] = self.input_devices[
|
data["sg_input_device"] = self.input_devices[
|
||||||
self.input_devices_indices.index(sd.default.device[0])
|
self.input_devices_indices.index(sd.default.device[0])
|
||||||
]
|
]
|
||||||
if data["sg_output_device"] not in self.output_devices:
|
|
||||||
data["sg_output_device"] = self.output_devices[
|
data["sg_output_device"] = self.output_devices[
|
||||||
self.output_devices_indices.index(sd.default.device[1])
|
self.output_devices_indices.index(sd.default.device[1])
|
||||||
]
|
]
|
||||||
except:
|
except:
|
||||||
with open("configs/config.json", "w") as j:
|
with open("configs/inuse/config.json", "w") as j:
|
||||||
data = {
|
data = {
|
||||||
"pth_path": "",
|
"pth_path": "",
|
||||||
"index_path": "",
|
"index_path": "",
|
||||||
|
"sg_hostapi": self.hostapis[0],
|
||||||
|
"sg_wasapi_exclusive": False,
|
||||||
"sg_input_device": self.input_devices[
|
"sg_input_device": self.input_devices[
|
||||||
self.input_devices_indices.index(sd.default.device[0])
|
self.input_devices_indices.index(sd.default.device[0])
|
||||||
],
|
],
|
||||||
@ -233,12 +255,30 @@ if __name__ == "__main__":
|
|||||||
[
|
[
|
||||||
sg.Frame(
|
sg.Frame(
|
||||||
layout=[
|
layout=[
|
||||||
|
[
|
||||||
|
sg.Text(i18n("设备类型")),
|
||||||
|
sg.Combo(
|
||||||
|
self.hostapis,
|
||||||
|
key="sg_hostapi",
|
||||||
|
default_value=data.get("sg_hostapi", ""),
|
||||||
|
enable_events=True,
|
||||||
|
size=(20, 1),
|
||||||
|
),
|
||||||
|
sg.Checkbox(
|
||||||
|
i18n("独占 WASAPI 设备"),
|
||||||
|
key="sg_wasapi_exclusive",
|
||||||
|
default=data.get("sg_wasapi_exclusive", False),
|
||||||
|
enable_events=True,
|
||||||
|
),
|
||||||
|
],
|
||||||
[
|
[
|
||||||
sg.Text(i18n("输入设备")),
|
sg.Text(i18n("输入设备")),
|
||||||
sg.Combo(
|
sg.Combo(
|
||||||
self.input_devices,
|
self.input_devices,
|
||||||
key="sg_input_device",
|
key="sg_input_device",
|
||||||
default_value=data.get("sg_input_device", ""),
|
default_value=data.get("sg_input_device", ""),
|
||||||
|
enable_events=True,
|
||||||
|
size=(45, 1),
|
||||||
),
|
),
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
@ -247,6 +287,8 @@ if __name__ == "__main__":
|
|||||||
self.output_devices,
|
self.output_devices,
|
||||||
key="sg_output_device",
|
key="sg_output_device",
|
||||||
default_value=data.get("sg_output_device", ""),
|
default_value=data.get("sg_output_device", ""),
|
||||||
|
enable_events=True,
|
||||||
|
size=(45, 1),
|
||||||
),
|
),
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
@ -269,7 +311,7 @@ if __name__ == "__main__":
|
|||||||
sg.Text("", key="sr_stream"),
|
sg.Text("", key="sr_stream"),
|
||||||
],
|
],
|
||||||
],
|
],
|
||||||
title=i18n("音频设备(请使用同种类驱动)"),
|
title=i18n("音频设备"),
|
||||||
)
|
)
|
||||||
],
|
],
|
||||||
[
|
[
|
||||||
@ -365,7 +407,7 @@ if __name__ == "__main__":
|
|||||||
[
|
[
|
||||||
sg.Text(i18n("采样长度")),
|
sg.Text(i18n("采样长度")),
|
||||||
sg.Slider(
|
sg.Slider(
|
||||||
range=(0.02, 2.4),
|
range=(0.02, 1.5),
|
||||||
key="block_time",
|
key="block_time",
|
||||||
resolution=0.01,
|
resolution=0.01,
|
||||||
orientation="h",
|
orientation="h",
|
||||||
@ -481,9 +523,17 @@ if __name__ == "__main__":
|
|||||||
if event == sg.WINDOW_CLOSED:
|
if event == sg.WINDOW_CLOSED:
|
||||||
self.stop_stream()
|
self.stop_stream()
|
||||||
exit()
|
exit()
|
||||||
if event == "reload_devices":
|
if event == "reload_devices" or event == "sg_hostapi":
|
||||||
self.update_devices()
|
self.gui_config.sg_hostapi = values["sg_hostapi"]
|
||||||
if self.gui_config.sg_input_device not in self.input_devices:
|
self.update_devices(hostapi_name=values["sg_hostapi"])
|
||||||
|
if self.gui_config.sg_hostapi not in self.hostapis:
|
||||||
|
self.gui_config.sg_hostapi = self.hostapis[0]
|
||||||
|
self.window["sg_hostapi"].Update(values=self.hostapis)
|
||||||
|
self.window["sg_hostapi"].Update(value=self.gui_config.sg_hostapi)
|
||||||
|
if (
|
||||||
|
self.gui_config.sg_input_device not in self.input_devices
|
||||||
|
and len(self.input_devices) > 0
|
||||||
|
):
|
||||||
self.gui_config.sg_input_device = self.input_devices[0]
|
self.gui_config.sg_input_device = self.input_devices[0]
|
||||||
self.window["sg_input_device"].Update(values=self.input_devices)
|
self.window["sg_input_device"].Update(values=self.input_devices)
|
||||||
self.window["sg_input_device"].Update(
|
self.window["sg_input_device"].Update(
|
||||||
@ -502,6 +552,8 @@ if __name__ == "__main__":
|
|||||||
settings = {
|
settings = {
|
||||||
"pth_path": values["pth_path"],
|
"pth_path": values["pth_path"],
|
||||||
"index_path": values["index_path"],
|
"index_path": values["index_path"],
|
||||||
|
"sg_hostapi": values["sg_hostapi"],
|
||||||
|
"sg_wasapi_exclusive": values["sg_wasapi_exclusive"],
|
||||||
"sg_input_device": values["sg_input_device"],
|
"sg_input_device": values["sg_input_device"],
|
||||||
"sg_output_device": values["sg_output_device"],
|
"sg_output_device": values["sg_output_device"],
|
||||||
"sr_type": ["sr_model", "sr_device"][
|
"sr_type": ["sr_model", "sr_device"][
|
||||||
@ -532,7 +584,7 @@ if __name__ == "__main__":
|
|||||||
].index(True)
|
].index(True)
|
||||||
],
|
],
|
||||||
}
|
}
|
||||||
with open("configs/config.json", "w") as j:
|
with open("configs/inuse/config.json", "w") as j:
|
||||||
json.dump(settings, j)
|
json.dump(settings, j)
|
||||||
if self.stream is not None:
|
if self.stream is not None:
|
||||||
self.delay_time = (
|
self.delay_time = (
|
||||||
@ -544,7 +596,9 @@ if __name__ == "__main__":
|
|||||||
if values["I_noise_reduce"]:
|
if values["I_noise_reduce"]:
|
||||||
self.delay_time += min(values["crossfade_length"], 0.04)
|
self.delay_time += min(values["crossfade_length"], 0.04)
|
||||||
self.window["sr_stream"].update(self.gui_config.samplerate)
|
self.window["sr_stream"].update(self.gui_config.samplerate)
|
||||||
self.window["delay_time"].update(int(self.delay_time * 1000))
|
self.window["delay_time"].update(
|
||||||
|
int(np.round(self.delay_time * 1000))
|
||||||
|
)
|
||||||
# Parameter hot update
|
# Parameter hot update
|
||||||
if event == "threhold":
|
if event == "threhold":
|
||||||
self.gui_config.threhold = values["threhold"]
|
self.gui_config.threhold = values["threhold"]
|
||||||
@ -566,7 +620,9 @@ if __name__ == "__main__":
|
|||||||
self.delay_time += (
|
self.delay_time += (
|
||||||
1 if values["I_noise_reduce"] else -1
|
1 if values["I_noise_reduce"] else -1
|
||||||
) * min(values["crossfade_length"], 0.04)
|
) * min(values["crossfade_length"], 0.04)
|
||||||
self.window["delay_time"].update(int(self.delay_time * 1000))
|
self.window["delay_time"].update(
|
||||||
|
int(np.round(self.delay_time * 1000))
|
||||||
|
)
|
||||||
elif event == "O_noise_reduce":
|
elif event == "O_noise_reduce":
|
||||||
self.gui_config.O_noise_reduce = values["O_noise_reduce"]
|
self.gui_config.O_noise_reduce = values["O_noise_reduce"]
|
||||||
elif event == "use_pv":
|
elif event == "use_pv":
|
||||||
@ -594,6 +650,8 @@ if __name__ == "__main__":
|
|||||||
self.set_devices(values["sg_input_device"], values["sg_output_device"])
|
self.set_devices(values["sg_input_device"], values["sg_output_device"])
|
||||||
self.config.use_jit = False # values["use_jit"]
|
self.config.use_jit = False # values["use_jit"]
|
||||||
# self.device_latency = values["device_latency"]
|
# self.device_latency = values["device_latency"]
|
||||||
|
self.gui_config.sg_hostapi = values["sg_hostapi"]
|
||||||
|
self.gui_config.sg_wasapi_exclusive = values["sg_wasapi_exclusive"]
|
||||||
self.gui_config.sg_input_device = values["sg_input_device"]
|
self.gui_config.sg_input_device = values["sg_input_device"]
|
||||||
self.gui_config.sg_output_device = values["sg_output_device"]
|
self.gui_config.sg_output_device = values["sg_output_device"]
|
||||||
self.gui_config.pth_path = values["pth_path"]
|
self.gui_config.pth_path = values["pth_path"]
|
||||||
@ -644,6 +702,7 @@ if __name__ == "__main__":
|
|||||||
if self.gui_config.sr_type == "sr_model"
|
if self.gui_config.sr_type == "sr_model"
|
||||||
else self.get_device_samplerate()
|
else self.get_device_samplerate()
|
||||||
)
|
)
|
||||||
|
self.gui_config.channels = self.get_device_channels()
|
||||||
self.zc = self.gui_config.samplerate // 100
|
self.zc = self.gui_config.samplerate // 100
|
||||||
self.block_frame = (
|
self.block_frame = (
|
||||||
int(
|
int(
|
||||||
@ -686,19 +745,18 @@ if __name__ == "__main__":
|
|||||||
device=self.config.device,
|
device=self.config.device,
|
||||||
dtype=torch.float32,
|
dtype=torch.float32,
|
||||||
)
|
)
|
||||||
|
self.input_wav_denoise: torch.Tensor = self.input_wav.clone()
|
||||||
self.input_wav_res: torch.Tensor = torch.zeros(
|
self.input_wav_res: torch.Tensor = torch.zeros(
|
||||||
160 * self.input_wav.shape[0] // self.zc,
|
160 * self.input_wav.shape[0] // self.zc,
|
||||||
device=self.config.device,
|
device=self.config.device,
|
||||||
dtype=torch.float32,
|
dtype=torch.float32,
|
||||||
)
|
)
|
||||||
|
self.rms_buffer: np.ndarray = np.zeros(4 * self.zc, dtype="float32")
|
||||||
self.sola_buffer: torch.Tensor = torch.zeros(
|
self.sola_buffer: torch.Tensor = torch.zeros(
|
||||||
self.sola_buffer_frame, device=self.config.device, dtype=torch.float32
|
self.sola_buffer_frame, device=self.config.device, dtype=torch.float32
|
||||||
)
|
)
|
||||||
self.nr_buffer: torch.Tensor = self.sola_buffer.clone()
|
self.nr_buffer: torch.Tensor = self.sola_buffer.clone()
|
||||||
self.output_buffer: torch.Tensor = self.input_wav.clone()
|
self.output_buffer: torch.Tensor = self.input_wav.clone()
|
||||||
self.res_buffer: torch.Tensor = torch.zeros(
|
|
||||||
2 * self.zc, device=self.config.device, dtype=torch.float32
|
|
||||||
)
|
|
||||||
self.skip_head = self.extra_frame // self.zc
|
self.skip_head = self.extra_frame // self.zc
|
||||||
self.return_length = (
|
self.return_length = (
|
||||||
self.block_frame + self.sola_buffer_frame + self.sola_search_frame
|
self.block_frame + self.sola_buffer_frame + self.sola_search_frame
|
||||||
@ -740,13 +798,20 @@ if __name__ == "__main__":
|
|||||||
global flag_vc
|
global flag_vc
|
||||||
if not flag_vc:
|
if not flag_vc:
|
||||||
flag_vc = True
|
flag_vc = True
|
||||||
channels = 1 if sys.platform == "darwin" else 2
|
if (
|
||||||
|
"WASAPI" in self.gui_config.sg_hostapi
|
||||||
|
and self.gui_config.sg_wasapi_exclusive
|
||||||
|
):
|
||||||
|
extra_settings = sd.WasapiSettings(exclusive=True)
|
||||||
|
else:
|
||||||
|
extra_settings = None
|
||||||
self.stream = sd.Stream(
|
self.stream = sd.Stream(
|
||||||
channels=channels,
|
|
||||||
callback=self.audio_callback,
|
callback=self.audio_callback,
|
||||||
blocksize=self.block_frame,
|
blocksize=self.block_frame,
|
||||||
samplerate=self.gui_config.samplerate,
|
samplerate=self.gui_config.samplerate,
|
||||||
|
channels=self.gui_config.channels,
|
||||||
dtype="float32",
|
dtype="float32",
|
||||||
|
extra_settings=extra_settings,
|
||||||
)
|
)
|
||||||
self.stream.start()
|
self.stream.start()
|
||||||
|
|
||||||
@ -755,7 +820,7 @@ if __name__ == "__main__":
|
|||||||
if flag_vc:
|
if flag_vc:
|
||||||
flag_vc = False
|
flag_vc = False
|
||||||
if self.stream is not None:
|
if self.stream is not None:
|
||||||
self.stream.stop()
|
self.stream.abort()
|
||||||
self.stream.close()
|
self.stream.close()
|
||||||
self.stream = None
|
self.stream = None
|
||||||
|
|
||||||
@ -769,48 +834,54 @@ if __name__ == "__main__":
|
|||||||
start_time = time.perf_counter()
|
start_time = time.perf_counter()
|
||||||
indata = librosa.to_mono(indata.T)
|
indata = librosa.to_mono(indata.T)
|
||||||
if self.gui_config.threhold > -60:
|
if self.gui_config.threhold > -60:
|
||||||
|
indata = np.append(self.rms_buffer, indata)
|
||||||
rms = librosa.feature.rms(
|
rms = librosa.feature.rms(
|
||||||
y=indata, frame_length=4 * self.zc, hop_length=self.zc
|
y=indata, frame_length=4 * self.zc, hop_length=self.zc
|
||||||
)
|
)[:, 2:]
|
||||||
|
self.rms_buffer[:] = indata[-4 * self.zc :]
|
||||||
|
indata = indata[2 * self.zc - self.zc // 2 :]
|
||||||
db_threhold = (
|
db_threhold = (
|
||||||
librosa.amplitude_to_db(rms, ref=1.0)[0] < self.gui_config.threhold
|
librosa.amplitude_to_db(rms, ref=1.0)[0] < self.gui_config.threhold
|
||||||
)
|
)
|
||||||
for i in range(db_threhold.shape[0]):
|
for i in range(db_threhold.shape[0]):
|
||||||
if db_threhold[i]:
|
if db_threhold[i]:
|
||||||
indata[i * self.zc : (i + 1) * self.zc] = 0
|
indata[i * self.zc : (i + 1) * self.zc] = 0
|
||||||
|
indata = indata[self.zc // 2 :]
|
||||||
self.input_wav[: -self.block_frame] = self.input_wav[
|
self.input_wav[: -self.block_frame] = self.input_wav[
|
||||||
self.block_frame :
|
self.block_frame :
|
||||||
].clone()
|
].clone()
|
||||||
self.input_wav[-self.block_frame :] = torch.from_numpy(indata).to(
|
self.input_wav[-indata.shape[0] :] = torch.from_numpy(indata).to(
|
||||||
self.config.device
|
self.config.device
|
||||||
)
|
)
|
||||||
self.input_wav_res[: -self.block_frame_16k] = self.input_wav_res[
|
self.input_wav_res[: -self.block_frame_16k] = self.input_wav_res[
|
||||||
self.block_frame_16k :
|
self.block_frame_16k :
|
||||||
].clone()
|
].clone()
|
||||||
# input noise reduction and resampling
|
# input noise reduction and resampling
|
||||||
if self.gui_config.I_noise_reduce and self.function == "vc":
|
if self.gui_config.I_noise_reduce:
|
||||||
input_wav = self.input_wav[
|
self.input_wav_denoise[: -self.block_frame] = self.input_wav_denoise[
|
||||||
-self.sola_buffer_frame - self.block_frame - 2 * self.zc :
|
self.block_frame :
|
||||||
]
|
].clone()
|
||||||
|
input_wav = self.input_wav[-self.sola_buffer_frame - self.block_frame :]
|
||||||
input_wav = self.tg(
|
input_wav = self.tg(
|
||||||
input_wav.unsqueeze(0), self.input_wav.unsqueeze(0)
|
input_wav.unsqueeze(0), self.input_wav.unsqueeze(0)
|
||||||
)[0, 2 * self.zc :]
|
).squeeze(0)
|
||||||
input_wav[: self.sola_buffer_frame] *= self.fade_in_window
|
input_wav[: self.sola_buffer_frame] *= self.fade_in_window
|
||||||
input_wav[: self.sola_buffer_frame] += (
|
input_wav[: self.sola_buffer_frame] += (
|
||||||
self.nr_buffer * self.fade_out_window
|
self.nr_buffer * self.fade_out_window
|
||||||
)
|
)
|
||||||
|
self.input_wav_denoise[-self.block_frame :] = input_wav[
|
||||||
|
: self.block_frame
|
||||||
|
]
|
||||||
self.nr_buffer[:] = input_wav[self.block_frame :]
|
self.nr_buffer[:] = input_wav[self.block_frame :]
|
||||||
input_wav = torch.cat(
|
|
||||||
(self.res_buffer[:], input_wav[: self.block_frame])
|
|
||||||
)
|
|
||||||
self.res_buffer[:] = input_wav[-2 * self.zc :]
|
|
||||||
self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
|
self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
|
||||||
input_wav
|
self.input_wav_denoise[-self.block_frame - 2 * self.zc :]
|
||||||
)[160:]
|
)[160:]
|
||||||
else:
|
else:
|
||||||
self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
|
self.input_wav_res[-160 * (indata.shape[0] // self.zc + 1) :] = (
|
||||||
self.input_wav[-self.block_frame - 2 * self.zc :]
|
self.resampler(self.input_wav[-indata.shape[0] - 2 * self.zc :])[
|
||||||
)[160:]
|
160:
|
||||||
|
]
|
||||||
|
)
|
||||||
# infer
|
# infer
|
||||||
if self.function == "vc":
|
if self.function == "vc":
|
||||||
infer_wav = self.rvc.infer(
|
infer_wav = self.rvc.infer(
|
||||||
@ -822,14 +893,12 @@ if __name__ == "__main__":
|
|||||||
)
|
)
|
||||||
if self.resampler2 is not None:
|
if self.resampler2 is not None:
|
||||||
infer_wav = self.resampler2(infer_wav)
|
infer_wav = self.resampler2(infer_wav)
|
||||||
|
elif self.gui_config.I_noise_reduce:
|
||||||
|
infer_wav = self.input_wav_denoise[self.extra_frame :].clone()
|
||||||
else:
|
else:
|
||||||
infer_wav = self.input_wav[
|
infer_wav = self.input_wav[self.extra_frame :].clone()
|
||||||
-self.crossfade_frame - self.sola_search_frame - self.block_frame :
|
|
||||||
].clone()
|
|
||||||
# output noise reduction
|
# output noise reduction
|
||||||
if (self.gui_config.O_noise_reduce and self.function == "vc") or (
|
if self.gui_config.O_noise_reduce and self.function == "vc":
|
||||||
self.gui_config.I_noise_reduce and self.function == "im"
|
|
||||||
):
|
|
||||||
self.output_buffer[: -self.block_frame] = self.output_buffer[
|
self.output_buffer[: -self.block_frame] = self.output_buffer[
|
||||||
self.block_frame :
|
self.block_frame :
|
||||||
].clone()
|
].clone()
|
||||||
@ -839,16 +908,14 @@ if __name__ == "__main__":
|
|||||||
).squeeze(0)
|
).squeeze(0)
|
||||||
# volume envelop mixing
|
# volume envelop mixing
|
||||||
if self.gui_config.rms_mix_rate < 1 and self.function == "vc":
|
if self.gui_config.rms_mix_rate < 1 and self.function == "vc":
|
||||||
|
if self.gui_config.I_noise_reduce:
|
||||||
|
input_wav = self.input_wav_denoise[self.extra_frame :]
|
||||||
|
else:
|
||||||
|
input_wav = self.input_wav[self.extra_frame :]
|
||||||
rms1 = librosa.feature.rms(
|
rms1 = librosa.feature.rms(
|
||||||
y=self.input_wav_res[
|
y=input_wav[: infer_wav.shape[0]].cpu().numpy(),
|
||||||
160
|
frame_length=4 * self.zc,
|
||||||
* self.skip_head : 160
|
hop_length=self.zc,
|
||||||
* (self.skip_head + self.return_length)
|
|
||||||
]
|
|
||||||
.cpu()
|
|
||||||
.numpy(),
|
|
||||||
frame_length=640,
|
|
||||||
hop_length=160,
|
|
||||||
)
|
)
|
||||||
rms1 = torch.from_numpy(rms1).to(self.config.device)
|
rms1 = torch.from_numpy(rms1).to(self.config.device)
|
||||||
rms1 = F.interpolate(
|
rms1 = F.interpolate(
|
||||||
@ -907,19 +974,22 @@ if __name__ == "__main__":
|
|||||||
self.sola_buffer[:] = infer_wav[
|
self.sola_buffer[:] = infer_wav[
|
||||||
self.block_frame : self.block_frame + self.sola_buffer_frame
|
self.block_frame : self.block_frame + self.sola_buffer_frame
|
||||||
]
|
]
|
||||||
if sys.platform == "darwin":
|
outdata[:] = (
|
||||||
outdata[:] = infer_wav[: self.block_frame].cpu().numpy()[:, np.newaxis]
|
infer_wav[: self.block_frame]
|
||||||
else:
|
.repeat(self.gui_config.channels, 1)
|
||||||
outdata[:] = (
|
.t()
|
||||||
infer_wav[: self.block_frame].repeat(2, 1).t().cpu().numpy()
|
.cpu()
|
||||||
)
|
.numpy()
|
||||||
|
)
|
||||||
total_time = time.perf_counter() - start_time
|
total_time = time.perf_counter() - start_time
|
||||||
if flag_vc:
|
if flag_vc:
|
||||||
self.window["infer_time"].update(int(total_time * 1000))
|
self.window["infer_time"].update(int(total_time * 1000))
|
||||||
printt("Infer time: %.2f", total_time)
|
printt("Infer time: %.2f", total_time)
|
||||||
|
|
||||||
def update_devices(self):
|
def update_devices(self, hostapi_name=None):
|
||||||
"""获取设备列表"""
|
"""获取设备列表"""
|
||||||
|
global flag_vc
|
||||||
|
flag_vc = False
|
||||||
sd._terminate()
|
sd._terminate()
|
||||||
sd._initialize()
|
sd._initialize()
|
||||||
devices = sd.query_devices()
|
devices = sd.query_devices()
|
||||||
@ -927,25 +997,28 @@ if __name__ == "__main__":
|
|||||||
for hostapi in hostapis:
|
for hostapi in hostapis:
|
||||||
for device_idx in hostapi["devices"]:
|
for device_idx in hostapi["devices"]:
|
||||||
devices[device_idx]["hostapi_name"] = hostapi["name"]
|
devices[device_idx]["hostapi_name"] = hostapi["name"]
|
||||||
|
self.hostapis = [hostapi["name"] for hostapi in hostapis]
|
||||||
|
if hostapi_name not in self.hostapis:
|
||||||
|
hostapi_name = self.hostapis[0]
|
||||||
self.input_devices = [
|
self.input_devices = [
|
||||||
f"{d['name']} ({d['hostapi_name']})"
|
d["name"]
|
||||||
for d in devices
|
for d in devices
|
||||||
if d["max_input_channels"] > 0
|
if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||||
]
|
]
|
||||||
self.output_devices = [
|
self.output_devices = [
|
||||||
f"{d['name']} ({d['hostapi_name']})"
|
d["name"]
|
||||||
for d in devices
|
for d in devices
|
||||||
if d["max_output_channels"] > 0
|
if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||||
]
|
]
|
||||||
self.input_devices_indices = [
|
self.input_devices_indices = [
|
||||||
d["index"] if "index" in d else d["name"]
|
d["index"] if "index" in d else d["name"]
|
||||||
for d in devices
|
for d in devices
|
||||||
if d["max_input_channels"] > 0
|
if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||||
]
|
]
|
||||||
self.output_devices_indices = [
|
self.output_devices_indices = [
|
||||||
d["index"] if "index" in d else d["name"]
|
d["index"] if "index" in d else d["name"]
|
||||||
for d in devices
|
for d in devices
|
||||||
if d["max_output_channels"] > 0
|
if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||||
]
|
]
|
||||||
|
|
||||||
def set_devices(self, input_device, output_device):
|
def set_devices(self, input_device, output_device):
|
||||||
@ -964,4 +1037,13 @@ if __name__ == "__main__":
|
|||||||
sd.query_devices(device=sd.default.device[0])["default_samplerate"]
|
sd.query_devices(device=sd.default.device[0])["default_samplerate"]
|
||||||
)
|
)
|
||||||
|
|
||||||
|
def get_device_channels(self):
|
||||||
|
max_input_channels = sd.query_devices(device=sd.default.device[0])[
|
||||||
|
"max_input_channels"
|
||||||
|
]
|
||||||
|
max_output_channels = sd.query_devices(device=sd.default.device[1])[
|
||||||
|
"max_output_channels"
|
||||||
|
]
|
||||||
|
return min(max_input_channels, max_output_channels, 2)
|
||||||
|
|
||||||
gui = GUI()
|
gui = GUI()
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Version",
|
"版本": "Version",
|
||||||
"特征提取": "Feature extraction",
|
"特征提取": "Feature extraction",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Path to the feature index file. Leave blank to use the selected result from the dropdown:",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Path to the feature index file. Leave blank to use the selected result from the dropdown:",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recommended +12 key for male to female conversion, and -12 key for female to male conversion. If the sound range goes too far and the voice is distorted, you can also adjust it to the appropriate range by yourself.",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recommended +12 key for male to female conversion, and -12 key for female to male conversion. If the sound range goes too far and the voice is distorted, you can also adjust it to the appropriate range by yourself.",
|
||||||
"目标采样率": "Target sample rate:",
|
"目标采样率": "Target sample rate:",
|
||||||
"算法延迟(ms):": "Algorithmic delays(ms):",
|
"算法延迟(ms):": "Algorithmic delays(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Train model",
|
"训练模型": "Train model",
|
||||||
"训练特征索引": "Train feature index",
|
"训练特征索引": "Train feature index",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Training complete. You can check the training logs in the console or the 'train.log' file under the experiment folder.",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Training complete. You can check the training logs in the console or the 'train.log' file under the experiment folder.",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "Please specify the speaker/singer ID:",
|
"请指定说话人id": "Please specify the speaker/singer ID:",
|
||||||
"请选择index文件": "Please choose the .index file",
|
"请选择index文件": "Please choose the .index file",
|
||||||
"请选择pth文件": "Please choose the .pth file",
|
"请选择pth文件": "Please choose the .pth file",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Sample length",
|
"采样长度": "Sample length",
|
||||||
"重载设备列表": "Reload device list",
|
"重载设备列表": "Reload device list",
|
||||||
"音调设置": "Pitch settings",
|
"音调设置": "Pitch settings",
|
||||||
"音频设备(请使用同种类驱动)": "Audio device (please use the same type of driver)",
|
"音频设备": "Audio device",
|
||||||
"音高算法": "pitch detection algorithm",
|
"音高算法": "pitch detection algorithm",
|
||||||
"额外推理时长": "Extra inference time"
|
"额外推理时长": "Extra inference time"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Versión",
|
"版本": "Versión",
|
||||||
"特征提取": "Extracción de características",
|
"特征提取": "Extracción de características",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Ruta del archivo de la biblioteca de características, si está vacío, se utilizará el resultado de la selección desplegable",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Ruta del archivo de la biblioteca de características, si está vacío, se utilizará el resultado de la selección desplegable",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tecla +12 recomendada para conversión de voz de hombre a mujer, tecla -12 para conversión de voz de mujer a hombre. Si el rango de tono es demasiado amplio y causa distorsión, ajústelo usted mismo a un rango adecuado.",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tecla +12 recomendada para conversión de voz de hombre a mujer, tecla -12 para conversión de voz de mujer a hombre. Si el rango de tono es demasiado amplio y causa distorsión, ajústelo usted mismo a un rango adecuado.",
|
||||||
"目标采样率": "Tasa de muestreo objetivo",
|
"目标采样率": "Tasa de muestreo objetivo",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Entrenar Modelo",
|
"训练模型": "Entrenar Modelo",
|
||||||
"训练特征索引": "Índice de características",
|
"训练特征索引": "Índice de características",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entrenamiento finalizado, puede ver el registro de entrenamiento en la consola o en el archivo train.log en la carpeta del experimento",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entrenamiento finalizado, puede ver el registro de entrenamiento en la consola o en el archivo train.log en la carpeta del experimento",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "ID del modelo",
|
"请指定说话人id": "ID del modelo",
|
||||||
"请选择index文件": "Seleccione el archivo .index",
|
"请选择index文件": "Seleccione el archivo .index",
|
||||||
"请选择pth文件": "Seleccione el archivo .pth",
|
"请选择pth文件": "Seleccione el archivo .pth",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Longitud de muestreo",
|
"采样长度": "Longitud de muestreo",
|
||||||
"重载设备列表": "Actualizar lista de dispositivos",
|
"重载设备列表": "Actualizar lista de dispositivos",
|
||||||
"音调设置": "Ajuste de tono",
|
"音调设置": "Ajuste de tono",
|
||||||
"音频设备(请使用同种类驱动)": "Dispositivo de audio (utilice el mismo tipo de controlador)",
|
"音频设备": "Dispositivo de audio",
|
||||||
"音高算法": "Algoritmo de tono",
|
"音高算法": "Algoritmo de tono",
|
||||||
"额外推理时长": "Tiempo de inferencia adicional"
|
"额外推理时长": "Tiempo de inferencia adicional"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Version",
|
"版本": "Version",
|
||||||
"特征提取": "Extraction des caractéristiques",
|
"特征提取": "Extraction des caractéristiques",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Chemin d'accès au fichier d'index des caractéristiques. Laisser vide pour utiliser le résultat sélectionné dans la liste déroulante :",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Chemin d'accès au fichier d'index des caractéristiques. Laisser vide pour utiliser le résultat sélectionné dans la liste déroulante :",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Il est recommandé d'utiliser la clé +12 pour la conversion homme-femme et la clé -12 pour la conversion femme-homme. Si la plage sonore est trop large et que la voix est déformée, vous pouvez également l'ajuster vous-même à la plage appropriée.",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Il est recommandé d'utiliser la clé +12 pour la conversion homme-femme et la clé -12 pour la conversion femme-homme. Si la plage sonore est trop large et que la voix est déformée, vous pouvez également l'ajuster vous-même à la plage appropriée.",
|
||||||
"目标采样率": "Taux d'échantillonnage cible :",
|
"目标采样率": "Taux d'échantillonnage cible :",
|
||||||
"算法延迟(ms):": "Délais algorithmiques (ms):",
|
"算法延迟(ms):": "Délais algorithmiques (ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Entraîner le modèle",
|
"训练模型": "Entraîner le modèle",
|
||||||
"训练特征索引": "Entraîner l'index des caractéristiques",
|
"训练特征索引": "Entraîner l'index des caractéristiques",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entraînement terminé. Vous pouvez consulter les rapports d'entraînement dans la console ou dans le fichier 'train.log' situé dans le dossier de l'expérience.",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entraînement terminé. Vous pouvez consulter les rapports d'entraînement dans la console ou dans le fichier 'train.log' situé dans le dossier de l'expérience.",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "Veuillez spécifier l'ID de l'orateur ou du chanteur :",
|
"请指定说话人id": "Veuillez spécifier l'ID de l'orateur ou du chanteur :",
|
||||||
"请选择index文件": "Veuillez sélectionner le fichier d'index",
|
"请选择index文件": "Veuillez sélectionner le fichier d'index",
|
||||||
"请选择pth文件": "Veuillez sélectionner le fichier pth",
|
"请选择pth文件": "Veuillez sélectionner le fichier pth",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Longueur de l'échantillon",
|
"采样长度": "Longueur de l'échantillon",
|
||||||
"重载设备列表": "Recharger la liste des dispositifs",
|
"重载设备列表": "Recharger la liste des dispositifs",
|
||||||
"音调设置": "Réglages de la hauteur",
|
"音调设置": "Réglages de la hauteur",
|
||||||
"音频设备(请使用同种类驱动)": "Périphérique audio (veuillez utiliser le même type de pilote)",
|
"音频设备": "Périphérique audio",
|
||||||
"音高算法": "algorithme de détection de la hauteur",
|
"音高算法": "algorithme de détection de la hauteur",
|
||||||
"额外推理时长": "Temps d'inférence supplémentaire"
|
"额外推理时长": "Temps d'inférence supplémentaire"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Versione",
|
"版本": "Versione",
|
||||||
"特征提取": "Estrazione delle caratteristiche",
|
"特征提取": "Estrazione delle caratteristiche",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Percorso del file di indice delle caratteristiche. ",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Percorso del file di indice delle caratteristiche. ",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tonalità +12 consigliata per la conversione da maschio a femmina e tonalità -12 per la conversione da femmina a maschio. ",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tonalità +12 consigliata per la conversione da maschio a femmina e tonalità -12 per la conversione da femmina a maschio. ",
|
||||||
"目标采样率": "Frequenza di campionamento target:",
|
"目标采样率": "Frequenza di campionamento target:",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Addestra modello",
|
"训练模型": "Addestra modello",
|
||||||
"训练特征索引": "Addestra indice delle caratteristiche",
|
"训练特征索引": "Addestra indice delle caratteristiche",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Addestramento completato. ",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Addestramento completato. ",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "Si prega di specificare l'ID del locutore/cantante:",
|
"请指定说话人id": "Si prega di specificare l'ID del locutore/cantante:",
|
||||||
"请选择index文件": "请选择index文件",
|
"请选择index文件": "请选择index文件",
|
||||||
"请选择pth文件": "请选择pth 文件",
|
"请选择pth文件": "请选择pth 文件",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Lunghezza del campione",
|
"采样长度": "Lunghezza del campione",
|
||||||
"重载设备列表": "Ricaricare l'elenco dei dispositivi",
|
"重载设备列表": "Ricaricare l'elenco dei dispositivi",
|
||||||
"音调设置": "Impostazioni del tono",
|
"音调设置": "Impostazioni del tono",
|
||||||
"音频设备(请使用同种类驱动)": "Dispositivo audio (utilizzare lo stesso tipo di driver)",
|
"音频设备": "Dispositivo audio",
|
||||||
"音高算法": "音高算法",
|
"音高算法": "音高算法",
|
||||||
"额外推理时长": "Tempo di inferenza extra"
|
"额外推理时长": "Tempo di inferenza extra"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "バージョン",
|
"版本": "バージョン",
|
||||||
"特征提取": "特徴抽出",
|
"特征提取": "特徴抽出",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徴検索ライブラリへのパス 空の場合はドロップダウンで選択",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "特徴検索ライブラリへのパス 空の場合はドロップダウンで選択",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性から女性へは+12キーをお勧めします。女性から男性へは-12キーをお勧めします。音域が広すぎて音質が劣化した場合は、適切な音域に自分で調整してください。",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性から女性へは+12キーをお勧めします。女性から男性へは-12キーをお勧めします。音域が広すぎて音質が劣化した場合は、適切な音域に自分で調整してください。",
|
||||||
"目标采样率": "目標サンプリングレート",
|
"目标采样率": "目標サンプリングレート",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "モデルのトレーニング",
|
"训练模型": "モデルのトレーニング",
|
||||||
"训练特征索引": "特徴インデックスのトレーニング",
|
"训练特征索引": "特徴インデックスのトレーニング",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "トレーニング終了時に、トレーニングログやフォルダ内のtrain.logを確認することができます",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "トレーニング終了時に、トレーニングログやフォルダ内のtrain.logを確認することができます",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "話者IDを指定してください",
|
"请指定说话人id": "話者IDを指定してください",
|
||||||
"请选择index文件": "indexファイルを選択してください",
|
"请选择index文件": "indexファイルを選択してください",
|
||||||
"请选择pth文件": "pthファイルを選択してください",
|
"请选择pth文件": "pthファイルを選択してください",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "サンプル長",
|
"采样长度": "サンプル長",
|
||||||
"重载设备列表": "デバイスリストをリロードする",
|
"重载设备列表": "デバイスリストをリロードする",
|
||||||
"音调设置": "音程設定",
|
"音调设置": "音程設定",
|
||||||
"音频设备(请使用同种类驱动)": "オーディオデバイス(同じ種類のドライバーを使用してください)",
|
"音频设备": "オーディオデバイス",
|
||||||
"音高算法": "ピッチアルゴリズム",
|
"音高算法": "ピッチアルゴリズム",
|
||||||
"额外推理时长": "追加推論時間"
|
"额外推理时长": "追加推論時間"
|
||||||
}
|
}
|
||||||
|
|||||||
137
i18n/locale/ko_KR.json
Normal file
137
i18n/locale/ko_KR.json
Normal file
@ -0,0 +1,137 @@
|
|||||||
|
{
|
||||||
|
">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3인 경우 harvest 피치 인식 결과에 중간값 필터 적용, 필터 반경은 값으로 지정, 사용 시 무성음 감소 가능",
|
||||||
|
"A模型权重": "A 모델 가중치",
|
||||||
|
"A模型路径": "A 모델 경로",
|
||||||
|
"B模型路径": "B 모델 경로",
|
||||||
|
"E:\\语音音频+标注\\米津玄师\\src": "E:\\음성 오디오+표시\\米津玄师\\src",
|
||||||
|
"F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0 곡선 파일, 선택적, 한 줄에 하나의 피치, 기본 F0 및 음높이 조절 대체",
|
||||||
|
"Index Rate": "인덱스 비율",
|
||||||
|
"Onnx导出": "Onnx 내보내기",
|
||||||
|
"Onnx输出路径": "Onnx 출력 경로",
|
||||||
|
"RVC模型路径": "RVC 모델 경로",
|
||||||
|
"ckpt处理": "ckpt 처리",
|
||||||
|
"harvest进程数": "harvest 프로세스 수",
|
||||||
|
"index文件路径不可包含中文": "index 파일 경로는 중국어를 포함할 수 없음",
|
||||||
|
"pth文件路径不可包含中文": "pth 파일 경로는 중국어를 포함할 수 없음",
|
||||||
|
"rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe 카드 번호 설정: -로 구분된 입력 사용 카드 번호, 예: 0-0-1은 카드 0에서 2개 프로세스, 카드 1에서 1개 프로세스 실행",
|
||||||
|
"step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1: 실험 구성 작성. 실험 데이터는 logs에 저장, 각 실험은 하나의 폴더, 수동으로 실험 이름 경로 입력 필요, 실험 구성, 로그, 훈련된 모델 파일 포함.",
|
||||||
|
"step1:正在处理数据": "step1: 데이터 처리 중",
|
||||||
|
"step2:正在提取音高&正在提取特征": "step2: 음높이 추출 & 특징 추출 중",
|
||||||
|
"step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a: 훈련 폴더 아래 모든 오디오로 디코딩 가능한 파일을 자동 순회하며 슬라이스 정규화 진행, 실험 디렉토리 아래 2개의 wav 폴더 생성; 현재 단일 사용자 훈련만 지원.",
|
||||||
|
"step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "step2b: CPU를 사용하여 음높이 추출(모델이 음높이 포함 시), GPU를 사용하여 특징 추출(카드 번호 선택)",
|
||||||
|
"step3: 填写训练设置, 开始训练模型和索引": "step3: 훈련 설정 작성, 모델 및 인덱스 훈련 시작",
|
||||||
|
"step3a:正在训练模型": "step3a: 모델 훈련 중",
|
||||||
|
"一键训练": "원클릭 훈련",
|
||||||
|
"也可批量输入音频文件, 二选一, 优先读文件夹": "여러 오디오 파일을 일괄 입력할 수도 있음, 둘 중 하나 선택, 폴더 우선 읽기",
|
||||||
|
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "인간 목소리와 반주 분리 배치 처리, UVR5 모델 사용. <br>적절한 폴더 경로 예시: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(파일 관리자 주소 표시줄에서 복사하면 됨). <br>모델은 세 가지 유형으로 나뉨: <br>1. 인간 목소리 보존: 화음이 없는 오디오에 이것을 선택, HP5보다 주된 인간 목소리 보존에 더 좋음. 내장된 HP2와 HP3 두 모델, HP3는 약간의 반주 누락 가능성이 있지만 HP2보다 주된 인간 목소리 보존이 약간 더 좋음; <br>2. 주된 인간 목소리만 보존: 화음이 있는 오디오에 이것을 선택, 주된 인간 목소리에 약간의 약화 가능성 있음. 내장된 HP5 모델 하나; <br>3. 혼효음 제거, 지연 제거 모델(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb): 이중 채널 혼효음에는 최선의 선택, 단일 채널 혼효음은 제거할 수 없음;<br> (234)DeEcho: 지연 제거 효과. Aggressive는 Normal보다 더 철저하게 제거, DeReverb는 추가로 혼효음을 제거, 단일 채널 혼효음은 제거 가능하지만 고주파 중심의 판 혼효음은 완전히 제거하기 어려움.<br>혼효음/지연 제거, 부록: <br>1. DeEcho-DeReverb 모델의 처리 시간은 다른 두 개의 DeEcho 모델의 거의 2배임;<br>2. MDX-Net-Dereverb 모델은 상당히 느림;<br>3. 개인적으로 추천하는 가장 깨끗한 구성은 MDX-Net 다음에 DeEcho-Aggressive 사용.",
|
||||||
|
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "-로 구분하여 입력하는 카드 번호, 예: 0-1-2는 카드 0, 카드 1, 카드 2 사용",
|
||||||
|
"伴奏人声分离&去混响&去回声": "반주 인간 목소리 분리 & 혼효음 제거 & 에코 제거",
|
||||||
|
"使用模型采样率": "모델 샘플링 레이트 사용",
|
||||||
|
"使用设备采样率": "장치 샘플링 레이트 사용",
|
||||||
|
"保存名": "저장 이름",
|
||||||
|
"保存的文件名, 默认空为和源文件同名": "저장될 파일명, 기본적으로 빈 공간은 원본 파일과 동일한 이름으로",
|
||||||
|
"保存的模型名不带后缀": "저장된 모델명은 접미사 없음",
|
||||||
|
"保存频率save_every_epoch": "저장 빈도 save_every_epoch",
|
||||||
|
"保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "청자음과 호흡 소리를 보호, 전자음 찢김 등의 아티팩트 방지, 0.5까지 올려서 비활성화, 낮추면 보호 강도 증가하지만 인덱스 효과 감소 가능성 있음",
|
||||||
|
"修改": "수정",
|
||||||
|
"修改模型信息(仅支持weights文件夹下提取的小模型文件)": "모델 정보 수정(오직 weights 폴더 아래에서 추출된 작은 모델 파일만 지원)",
|
||||||
|
"停止音频转换": "오디오 변환 중지",
|
||||||
|
"全流程结束!": "전체 과정 완료!",
|
||||||
|
"刷新音色列表和索引路径": "음색 목록 및 인덱스 경로 새로고침",
|
||||||
|
"加载模型": "모델 로드",
|
||||||
|
"加载预训练底模D路径": "미리 훈련된 베이스 모델 D 경로 로드",
|
||||||
|
"加载预训练底模G路径": "미리 훈련된 베이스 모델 G 경로 로드",
|
||||||
|
"单次推理": "단일 추론",
|
||||||
|
"卸载音色省显存": "음색 언로드로 디스플레이 메모리 절약",
|
||||||
|
"变调(整数, 半音数量, 升八度12降八度-12)": "키 변경(정수, 반음 수, 옥타브 상승 12, 옥타브 하강 -12)",
|
||||||
|
"后处理重采样至最终采样率,0为不进行重采样": "후처리 재샘플링을 최종 샘플링 레이트로, 0은 재샘플링하지 않음",
|
||||||
|
"否": "아니오",
|
||||||
|
"启用相位声码器": "위상 보코더 활성화",
|
||||||
|
"响应阈值": "응답 임계값",
|
||||||
|
"响度因子": "음량 인자",
|
||||||
|
"处理数据": "데이터 처리",
|
||||||
|
"导出Onnx模型": "Onnx 모델 내보내기",
|
||||||
|
"导出文件格式": "내보낼 파일 형식",
|
||||||
|
"常见问题解答": "자주 묻는 질문",
|
||||||
|
"常规设置": "일반 설정",
|
||||||
|
"开始音频转换": "오디오 변환 시작",
|
||||||
|
"很遗憾您这没有能用的显卡来支持您训练": "사용 가능한 그래픽 카드가 없어 훈련을 지원할 수 없습니다",
|
||||||
|
"性能设置": "성능 설정",
|
||||||
|
"总训练轮数total_epoch": "총 훈련 라운드 수 total_epoch",
|
||||||
|
"批量推理": "일괄 추론",
|
||||||
|
"批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "일괄 변환, 변환할 오디오 파일 폴더 입력 또는 여러 오디오 파일 업로드, 지정된 폴더(기본값 opt)에 변환된 오디오 출력.",
|
||||||
|
"指定输出主人声文件夹": "주된 목소리 출력 폴더 지정",
|
||||||
|
"指定输出文件夹": "출력 파일 폴더 지정",
|
||||||
|
"指定输出非主人声文件夹": "주된 목소리가 아닌 출력 폴더 지정",
|
||||||
|
"推理时间(ms):": "추론 시간(ms):",
|
||||||
|
"推理音色": "추론 음색",
|
||||||
|
"提取": "추출",
|
||||||
|
"提取音高和处理数据使用的CPU进程数": "음높이 추출 및 데이터 처리에 사용되는 CPU 프로세스 수",
|
||||||
|
"是": "예",
|
||||||
|
"是否仅保存最新的ckpt文件以节省硬盘空间": "디스크 공간을 절약하기 위해 최신 ckpt 파일만 저장할지 여부",
|
||||||
|
"是否在每次保存时间点将最终小模型保存至weights文件夹": "저장 시마다 최종 소형 모델을 weights 폴더에 저장할지 여부",
|
||||||
|
"是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "모든 훈련 세트를 VRAM에 캐시할지 여부. 10분 미만의 소량 데이터는 캐시하여 훈련 속도를 높일 수 있지만, 대량 데이터 캐시는 VRAM을 과부하시키고 속도를 크게 향상시키지 못함",
|
||||||
|
"显卡信息": "그래픽 카드 정보",
|
||||||
|
"本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责. <br>如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录<b>LICENSE</b>.": "이 소프트웨어는 MIT 라이선스로 공개되며, 저자는 소프트웨어에 대해 어떠한 통제권도 가지지 않습니다. 모든 귀책사유는 소프트웨어 사용자 및 소프트웨어에서 생성된 결과물을 사용하는 당사자에게 있습니다. <br>해당 조항을 인정하지 않는 경우, 소프트웨어 패키지의 어떠한 코드나 파일도 사용하거나 인용할 수 없습니다. 자세한 내용은 루트 디렉토리의 <b>LICENSE</b>를 참조하세요.",
|
||||||
|
"查看": "보기",
|
||||||
|
"查看模型信息(仅支持weights文件夹下提取的小模型文件)": "모델 정보 보기(오직 weights 폴더에서 추출된 소형 모델 파일만 지원)",
|
||||||
|
"检索特征占比": "검색 특징 비율",
|
||||||
|
"模型": "모델",
|
||||||
|
"模型推理": "모델 추론",
|
||||||
|
"模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "모델 추출(logs 폴더 아래의 큰 파일 모델 경로 입력), 훈련 중간에 중단한 모델의 자동 추출 및 소형 파일 모델 저장이 안 되거나 중간 모델을 테스트하고 싶은 경우에 적합",
|
||||||
|
"模型是否带音高指导": "모델이 음높이 지도를 포함하는지 여부",
|
||||||
|
"模型是否带音高指导(唱歌一定要, 语音可以不要)": "모델이 음높이 지도를 포함하는지 여부(노래에는 반드시 필요, 음성에는 필요 없음)",
|
||||||
|
"模型是否带音高指导,1是0否": "모델이 음높이 지도를 포함하는지 여부, 1은 예, 0은 아니오",
|
||||||
|
"模型版本型号": "모델 버전 및 모델",
|
||||||
|
"模型融合, 可用于测试音色融合": "모델 융합, 음색 융합 테스트에 사용 가능",
|
||||||
|
"模型路径": "모델 경로",
|
||||||
|
"每张显卡的batch_size": "각 그래픽 카드의 batch_size",
|
||||||
|
"淡入淡出长度": "페이드 인/아웃 길이",
|
||||||
|
"版本": "버전",
|
||||||
|
"特征提取": "특징 추출",
|
||||||
|
"特征检索库文件路径,为空则使用下拉的选择结果": "특징 검색 라이브러리 파일 경로, 비어 있으면 드롭다운 선택 결과 사용",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "남성에서 여성으로 변경 시 +12 키 권장, 여성에서 남성으로 변경 시 -12 키 권장, 음역대 폭발로 음색이 왜곡되면 적절한 음역대로 조정 가능.",
|
||||||
|
"目标采样率": "목표 샘플링률",
|
||||||
|
"算法延迟(ms):": "알고리즘 지연(ms):",
|
||||||
|
"自动检测index路径,下拉式选择(dropdown)": "자동으로 index 경로 감지, 드롭다운 선택(dropdown)",
|
||||||
|
"融合": "융합",
|
||||||
|
"要改的模型信息": "변경할 모델 정보",
|
||||||
|
"要置入的模型信息": "삽입할 모델 정보",
|
||||||
|
"训练": "훈련",
|
||||||
|
"训练模型": "모델 훈련",
|
||||||
|
"训练特征索引": "특징 인덱스 훈련",
|
||||||
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "훈련 완료, 콘솔 훈련 로그 또는 실험 폴더 내의 train.log 확인 가능",
|
||||||
|
"设备类型": "设备类型",
|
||||||
|
"请指定说话人id": "화자 ID 지정 필요",
|
||||||
|
"请选择index文件": "index 파일 선택",
|
||||||
|
"请选择pth文件": "pth 파일 선택",
|
||||||
|
"请选择说话人id": "화자 ID 선택",
|
||||||
|
"转换": "변환",
|
||||||
|
"输入实验名": "실험명 입력",
|
||||||
|
"输入待处理音频文件夹路径": "처리할 오디오 파일 폴더 경로 입력",
|
||||||
|
"输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "처리할 오디오 파일 폴더 경로 입력(파일 탐색기 주소 표시줄에서 복사)",
|
||||||
|
"输入待处理音频文件路径(默认是正确格式示例)": "처리할 오디오 파일 경로 입력(기본적으로 올바른 형식 예시)",
|
||||||
|
"输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "입력 소스 볼륨 엔벨로프와 출력 볼륨 엔벨로프의 결합 비율 입력, 1에 가까울수록 출력 엔벨로프 사용",
|
||||||
|
"输入监听": "입력 모니터링",
|
||||||
|
"输入训练文件夹路径": "훈련 파일 폴더 경로 입력",
|
||||||
|
"输入设备": "입력 장치",
|
||||||
|
"输入降噪": "입력 노이즈 감소",
|
||||||
|
"输出信息": "출력 정보",
|
||||||
|
"输出变声": "출력 음성 변조",
|
||||||
|
"输出设备": "출력 장치",
|
||||||
|
"输出降噪": "출력 노이즈 감소",
|
||||||
|
"输出音频(右下角三个点,点了可以下载)": "출력 오디오(오른쪽 하단 세 개의 점, 클릭하면 다운로드 가능)",
|
||||||
|
"选择.index文件": ".index 파일 선택",
|
||||||
|
"选择.pth文件": ".pth 파일 선택",
|
||||||
|
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "음높이 추출 알고리즘 선택, 노래 입력 시 pm으로 속도 향상, harvest는 저음이 좋지만 매우 느림, crepe는 효과가 좋지만 GPU 사용",
|
||||||
|
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "음높이 추출 알고리즘 선택, 노래 입력 시 pm으로 속도 향상, harvest는 저음이 좋지만 매우 느림, crepe는 효과가 좋지만 GPU 사용, rmvpe는 효과가 가장 좋으며 GPU를 적게 사용",
|
||||||
|
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "음높이 추출 알고리즘 선택: 노래 입력 시 pm으로 속도 향상, 고품질 음성에는 CPU가 부족할 때 dio 사용, harvest는 품질이 더 좋지만 느림, rmvpe는 효과가 가장 좋으며 CPU/GPU를 적게 사용",
|
||||||
|
"采样率:": "샘플링률:",
|
||||||
|
"采样长度": "샘플링 길이",
|
||||||
|
"重载设备列表": "장치 목록 재로드",
|
||||||
|
"音调设置": "음조 설정",
|
||||||
|
"音频设备": "音频设备",
|
||||||
|
"音高算法": "음높이 알고리즘",
|
||||||
|
"额外推理时长": "추가 추론 시간"
|
||||||
|
}
|
||||||
137
i18n/locale/pt_BR.json
Normal file
137
i18n/locale/pt_BR.json
Normal file
@ -0,0 +1,137 @@
|
|||||||
|
{
|
||||||
|
">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3, use o filtro mediano para o resultado do reconhecimento do tom da heverst, e o valor é o raio do filtro, que pode enfraquecer o mudo.",
|
||||||
|
"A模型权重": "Peso (w) para o modelo A:",
|
||||||
|
"A模型路径": "Caminho para o Modelo A:",
|
||||||
|
"B模型路径": "Caminho para o Modelo B:",
|
||||||
|
"E:\\语音音频+标注\\米津玄师\\src": "E:\\meu-dataset",
|
||||||
|
"F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Arquivo de curva F0 (opcional). Um arremesso por linha. Substitui a modulação padrão F0 e tom:",
|
||||||
|
"Index Rate": "Taxa do Index",
|
||||||
|
"Onnx导出": "Exportar Onnx",
|
||||||
|
"Onnx输出路径": "Caminho de exportação ONNX:",
|
||||||
|
"RVC模型路径": "Caminho do Modelo RVC:",
|
||||||
|
"ckpt处理": "processamento ckpt",
|
||||||
|
"harvest进程数": "Número de processos harvest",
|
||||||
|
"index文件路径不可包含中文": "O caminho do arquivo de Index não pode conter caracteres chineses",
|
||||||
|
"pth文件路径不可包含中文": "o caminho do arquivo pth não pode conter caracteres chineses",
|
||||||
|
"rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Configuração do número do cartão rmvpe: Use - para separar os números dos cartões de entrada de diferentes processos. Por exemplo, 0-0-1 é usado para executar 2 processos no cartão 0 e 1 processo no cartão 1.",
|
||||||
|
"step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Etapa 1: Preencha a configuração experimental. Os dados experimentais são armazenados na pasta 'logs', com cada experimento tendo uma pasta separada. Digite manualmente o caminho do nome do experimento, que contém a configuração experimental, os logs e os arquivos de modelo treinados.",
|
||||||
|
"step1:正在处理数据": "Etapa 1: Processamento de dados",
|
||||||
|
"step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
|
||||||
|
"step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Etapa 2a: Percorra automaticamente todos os arquivos na pasta de treinamento que podem ser decodificados em áudio e execute a normalização da fatia. Gera 2 pastas wav no diretório do experimento. Atualmente, apenas o treinamento de um único cantor/palestrante é suportado.",
|
||||||
|
"step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Etapa 2b: Use a CPU para extrair o tom (se o modelo tiver tom), use a GPU para extrair recursos (selecione o índice da GPU):",
|
||||||
|
"step3: 填写训练设置, 开始训练模型和索引": "Etapa 3: Preencha as configurações de treinamento e comece a treinar o modelo e o Index",
|
||||||
|
"step3a:正在训练模型": "Etapa 3a: Treinamento do modelo iniciado",
|
||||||
|
"一键训练": "Treinamento com um clique",
|
||||||
|
"也可批量输入音频文件, 二选一, 优先读文件夹": "Você também pode inserir arquivos de áudio em lotes. Escolha uma das duas opções. É dada prioridade à leitura da pasta.",
|
||||||
|
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Processamento em lote para separação de acompanhamento vocal usando o modelo UVR5.<br>Exemplo de um formato de caminho de pasta válido: D:\\caminho\\para a pasta\\entrada\\ (copie-o da barra de endereços do gerenciador de arquivos).<br>O modelo é dividido em três categorias:<br>1. Preservar vocais: Escolha esta opção para áudio sem harmonias. Ele preserva os vocais melhor do que o HP5. Inclui dois modelos integrados: HP2 e HP3. O HP3 pode vazar ligeiramente o acompanhamento, mas preserva os vocais um pouco melhor do que o HP2.<br>2 Preservar apenas os vocais principais: Escolha esta opção para áudio com harmonias. Isso pode enfraquecer os vocais principais. Ele inclui um modelo embutido: HP5.<br>3. Modelos de de-reverb e de-delay (por FoxJoy):<br> (1) MDX-Net: A melhor escolha para remoção de reverb estéreo, mas não pode remover reverb mono;<br> (234) DeEcho: Remove efeitos de atraso. O modo agressivo remove mais completamente do que o modo normal. O DeReverb também remove reverb e pode remover reverb mono, mas não de forma muito eficaz para conteúdo de alta frequência fortemente reverberado.<br>Notas de de-reverb/de-delay:<br>1. O tempo de processamento para o modelo DeEcho-DeReverb é aproximadamente duas vezes maior que os outros dois modelos DeEcho.<br>2 O modelo MDX-Net-Dereverb é bastante lento.<br>3. A configuração mais limpa recomendada é aplicar MDX-Net primeiro e depois DeEcho-Aggressive.",
|
||||||
|
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Digite o (s) índice(s) da GPU separados por '-', por exemplo, 0-1-2 para usar a GPU 0, 1 e 2:",
|
||||||
|
"伴奏人声分离&去混响&去回声": "UVR5",
|
||||||
|
"使用模型采样率": "使用模型采样率",
|
||||||
|
"使用设备采样率": "使用设备采样率",
|
||||||
|
"保存名": "Salvar nome",
|
||||||
|
"保存的文件名, 默认空为和源文件同名": "Salvar nome do arquivo (padrão: igual ao arquivo de origem):",
|
||||||
|
"保存的模型名不带后缀": "Nome do modelo salvo (sem extensão):",
|
||||||
|
"保存频率save_every_epoch": "Faça backup a cada # de Epoch:",
|
||||||
|
"保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Proteja consoantes sem voz e sons respiratórios, evite artefatos como quebra de som eletrônico e desligue-o quando estiver cheio de 0,5. Diminua-o para aumentar a proteção, mas pode reduzir o efeito de indexação:",
|
||||||
|
"修改": "Editar",
|
||||||
|
"修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modificar informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
|
||||||
|
"停止音频转换": "Conversão de áudio",
|
||||||
|
"全流程结束!": "Todos os processos foram concluídos!",
|
||||||
|
"刷新音色列表和索引路径": "Atualizar lista de voz e caminho do Index",
|
||||||
|
"加载模型": "Modelo",
|
||||||
|
"加载预训练底模D路径": "Carregue o caminho D do modelo base pré-treinado:",
|
||||||
|
"加载预训练底模G路径": "Carregue o caminho G do modelo base pré-treinado:",
|
||||||
|
"单次推理": "Único",
|
||||||
|
"卸载音色省显存": "Descarregue a voz para liberar a memória da GPU:",
|
||||||
|
"变调(整数, 半音数量, 升八度12降八度-12)": "Mude o tom aqui. Se a voz for do mesmo sexo, não é necessario alterar (12 caso seja Masculino para feminino, -12 caso seja ao contrário).",
|
||||||
|
"后处理重采样至最终采样率,0为不进行重采样": "Reamostragem pós-processamento para a taxa de amostragem final, 0 significa sem reamostragem:",
|
||||||
|
"否": "Não",
|
||||||
|
"启用相位声码器": "启用相位声码器",
|
||||||
|
"响应阈值": "Limiar de resposta",
|
||||||
|
"响度因子": "Fator de volume",
|
||||||
|
"处理数据": "Processar o Conjunto de Dados",
|
||||||
|
"导出Onnx模型": "Exportar Modelo Onnx",
|
||||||
|
"导出文件格式": "Qual formato de arquivo você prefere?",
|
||||||
|
"常见问题解答": "FAQ (Perguntas frequentes)",
|
||||||
|
"常规设置": "Configurações gerais",
|
||||||
|
"开始音频转换": "Iniciar conversão de áudio",
|
||||||
|
"很遗憾您这没有能用的显卡来支持您训练": "Infelizmente, não há GPU compatível disponível para apoiar o seu treinamento.",
|
||||||
|
"性能设置": "Configurações de desempenho.",
|
||||||
|
"总训练轮数total_epoch": "Número total de ciclos(epoch) de treino (se escolher um valor alto demais, o seu modelo parecerá terrivelmente sobretreinado):",
|
||||||
|
"批量推理": "Conversão em Lote",
|
||||||
|
"批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversão em Massa.",
|
||||||
|
"指定输出主人声文件夹": "Especifique a pasta de saída para vocais:",
|
||||||
|
"指定输出文件夹": "Especifique a pasta de saída:",
|
||||||
|
"指定输出非主人声文件夹": "Informar a pasta de saída para acompanhamento:",
|
||||||
|
"推理时间(ms):": "Tempo de inferência (ms):",
|
||||||
|
"推理音色": "Escolha o seu Modelo:",
|
||||||
|
"提取": "Extrato",
|
||||||
|
"提取音高和处理数据使用的CPU进程数": "Número de processos de CPU usados para extração de tom e processamento de dados:",
|
||||||
|
"是": "Sim",
|
||||||
|
"是否仅保存最新的ckpt文件以节省硬盘空间": "Só deve salvar apenas o arquivo ckpt mais recente para economizar espaço em disco:",
|
||||||
|
"是否在每次保存时间点将最终小模型保存至weights文件夹": "Salve um pequeno modelo final na pasta 'weights' em cada ponto de salvamento:",
|
||||||
|
"是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Se deve armazenar em cache todos os conjuntos de treinamento na memória de vídeo. Pequenos dados com menos de 10 minutos podem ser armazenados em cache para acelerar o treinamento, e um cache de dados grande irá explodir a memória de vídeo e não aumentar muito a velocidade:",
|
||||||
|
"显卡信息": "Informações da GPU",
|
||||||
|
"本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责. <br>如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录<b>LICENSE</b>.": "<center>The Mangio-RVC 💻 | Tradução por Krisp e Rafael Godoy Ebert | AI HUB BRASIL<br> Este software é de código aberto sob a licença MIT. O autor não tem qualquer controle sobre o software. Aqueles que usam o software e divulgam os sons exportados pelo software são totalmente responsáveis. <br>Se você não concorda com este termo, você não pode usar ou citar nenhum código e arquivo no pacote de software. Para obter detalhes, consulte o diretório raiz <b>O acordo a ser seguido para uso <a href='https://raw.githubusercontent.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/main/LICENSE' target='_blank'>LICENSE</a></b></center>",
|
||||||
|
"查看": "Visualizar",
|
||||||
|
"查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Exibir informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
|
||||||
|
"检索特征占比": "Taxa de recurso de recuperação:",
|
||||||
|
"模型": "Modelo",
|
||||||
|
"模型推理": "Inference",
|
||||||
|
"模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Extração do modelo (insira o caminho do modelo de arquivo grande na pasta 'logs'). Isso é útil se você quiser interromper o treinamento no meio do caminho e extrair e salvar manualmente um arquivo de modelo pequeno, ou se quiser testar um modelo intermediário:",
|
||||||
|
"模型是否带音高指导": "Se o modelo tem orientação de tom:",
|
||||||
|
"模型是否带音高指导(唱歌一定要, 语音可以不要)": "Se o modelo tem orientação de tom (necessário para cantar, opcional para fala):",
|
||||||
|
"模型是否带音高指导,1是0否": "Se o modelo tem orientação de passo (1: sim, 0: não):",
|
||||||
|
"模型版本型号": "Versão:",
|
||||||
|
"模型融合, 可用于测试音色融合": "A fusão modelo, pode ser usada para testar a fusão do timbre",
|
||||||
|
"模型路径": "Caminho para o Modelo:",
|
||||||
|
"每张显卡的batch_size": "Batch Size (DEIXE COMO ESTÁ a menos que saiba o que está fazendo, no Colab pode deixar até 20!):",
|
||||||
|
"淡入淡出长度": "Comprimento de desvanecimento",
|
||||||
|
"版本": "Versão",
|
||||||
|
"特征提取": "Extrair Tom",
|
||||||
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Caminho para o arquivo de Index. Deixe em branco para usar o resultado selecionado no menu debaixo:",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recomendado +12 chave para conversão de homem para mulher e -12 chave para conversão de mulher para homem. Se a faixa de som for muito longe e a voz estiver distorcida, você também pode ajustá-la à faixa apropriada por conta própria.",
|
||||||
|
"目标采样率": "Taxa de amostragem:",
|
||||||
|
"算法延迟(ms):": "Atrasos algorítmicos (ms):",
|
||||||
|
"自动检测index路径,下拉式选择(dropdown)": "Detecte automaticamente o caminho do Index e selecione no menu suspenso:",
|
||||||
|
"融合": "Fusão",
|
||||||
|
"要改的模型信息": "Informações do modelo a ser modificado:",
|
||||||
|
"要置入的模型信息": "Informações do modelo a ser colocado:",
|
||||||
|
"训练": "Treinar",
|
||||||
|
"训练模型": "Treinar Modelo",
|
||||||
|
"训练特征索引": "Treinar Index",
|
||||||
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Após o término do treinamento, você pode verificar o log de treinamento do console ou train.log na pasta de experimentos",
|
||||||
|
"设备类型": "设备类型",
|
||||||
|
"请指定说话人id": "Especifique o ID do locutor/cantor:",
|
||||||
|
"请选择index文件": "Selecione o arquivo de Index",
|
||||||
|
"请选择pth文件": "Selecione o arquivo pth",
|
||||||
|
"请选择说话人id": "Selecione Palestrantes/Cantores ID:",
|
||||||
|
"转换": "Converter",
|
||||||
|
"输入实验名": "Nome da voz:",
|
||||||
|
"输入待处理音频文件夹路径": "Caminho da pasta de áudio a ser processada:",
|
||||||
|
"输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Caminho da pasta de áudio a ser processada (copie-o da barra de endereços do gerenciador de arquivos):",
|
||||||
|
"输入待处理音频文件路径(默认是正确格式示例)": "Caminho para o seu conjunto de dados (áudios, não zipado):",
|
||||||
|
"输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "O envelope de volume da fonte de entrada substitui a taxa de fusão do envelope de volume de saída, quanto mais próximo de 1, mais o envelope de saída é usado:",
|
||||||
|
"输入监听": "Monitoramento de entrada",
|
||||||
|
"输入训练文件夹路径": "Caminho da pasta de treinamento:",
|
||||||
|
"输入设备": "Dispositivo de entrada",
|
||||||
|
"输入降噪": "Redução de ruído de entrada",
|
||||||
|
"输出信息": "Informação de saída",
|
||||||
|
"输出变声": "Mudança de voz de saída",
|
||||||
|
"输出设备": "Dispositivo de saída",
|
||||||
|
"输出降噪": "Redução de ruído de saída",
|
||||||
|
"输出音频(右下角三个点,点了可以下载)": "Exportar áudio (clique nos três pontos no canto inferior direito para baixar)",
|
||||||
|
"选择.index文件": "Selecione o Index",
|
||||||
|
"选择.pth文件": "Selecione o Arquivo",
|
||||||
|
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||||
|
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'harvest': melhor qualidade, mas extração mais lenta); 'crepe': melhor qualidade, mas intensivo em GPU; 'magio-crepe': melhor opção; 'RMVPE': um modelo robusto para estimativa de afinação vocal em música polifônica;",
|
||||||
|
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'crepe': melhor qualidade (mas intensivo em GPU);\n rmvpe tem o melhor efeito e consome menos CPU/GPU.",
|
||||||
|
"采样率:": "采样率:",
|
||||||
|
"采样长度": "Comprimento da Amostra",
|
||||||
|
"重载设备列表": "Recarregar lista de dispositivos",
|
||||||
|
"音调设置": "Configurações de tom",
|
||||||
|
"音频设备": "音频设备",
|
||||||
|
"音高算法": "Algoritmo de detecção de pitch",
|
||||||
|
"额外推理时长": "Tempo extra de inferência"
|
||||||
|
}
|
||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Версия архитектуры модели:",
|
"版本": "Версия архитектуры модели:",
|
||||||
"特征提取": "Извлечь черты",
|
"特征提取": "Извлечь черты",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Путь к файлу индекса черт. Оставьте пустым, чтобы использовать выбранный вариант из списка ниже:",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Путь к файлу индекса черт. Оставьте пустым, чтобы использовать выбранный вариант из списка ниже:",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Рекомендуется выбрать +12 для конвертирования мужского голоса в женский и -12 для конвертирования женского в мужской. Если диапазон голоса слишком велик, и голос искажается, можно выбрать значение на свой вкус.",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Рекомендуется выбрать +12 для конвертирования мужского голоса в женский и -12 для конвертирования женского в мужской. Если диапазон голоса слишком велик, и голос искажается, можно выбрать значение на свой вкус.",
|
||||||
"目标采样率": "Частота дискретизации аудио:",
|
"目标采样率": "Частота дискретизации аудио:",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Обучить модель",
|
"训练模型": "Обучить модель",
|
||||||
"训练特征索引": "Обучить индекс черт",
|
"训练特征索引": "Обучить индекс черт",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Обучение модели завершено. Журнал обучения можно просмотреть в консоли или в файле 'train.log' в папке с моделью.",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Обучение модели завершено. Журнал обучения можно просмотреть в консоли или в файле 'train.log' в папке с моделью.",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "Номер говорящего/поющего:",
|
"请指定说话人id": "Номер говорящего/поющего:",
|
||||||
"请选择index文件": "Пожалуйста, выберите файл индекса",
|
"请选择index文件": "Пожалуйста, выберите файл индекса",
|
||||||
"请选择pth文件": "Пожалуйста, выберите файл pth",
|
"请选择pth文件": "Пожалуйста, выберите файл pth",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Длина сэмпла",
|
"采样长度": "Длина сэмпла",
|
||||||
"重载设备列表": "Обновить список устройств",
|
"重载设备列表": "Обновить список устройств",
|
||||||
"音调设置": "Настройка высоты звука",
|
"音调设置": "Настройка высоты звука",
|
||||||
"音频设备(请使用同种类驱动)": "Аудиоустройство (пожалуйста, используйте такой же тип драйвера)",
|
"音频设备": "Аудиоустройство",
|
||||||
"音高算法": "Алгоритм оценки высоты звука",
|
"音高算法": "Алгоритм оценки высоты звука",
|
||||||
"额外推理时长": "Доп. время переработки"
|
"额外推理时长": "Доп. время переработки"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "Sürüm",
|
"版本": "Sürüm",
|
||||||
"特征提取": "Özellik çıkartma",
|
"特征提取": "Özellik çıkartma",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Özellik indeksi dosyasının yolunu belirtin. Seçilen sonucu kullanmak için boş bırakın veya açılır menüden seçim yapın.",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "Özellik indeksi dosyasının yolunu belirtin. Seçilen sonucu kullanmak için boş bırakın veya açılır menüden seçim yapın.",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Erkekten kadına çevirmek için +12 tuş önerilir, kadından erkeğe çevirmek için ise -12 tuş önerilir. Eğer ses aralığı çok fazla genişler ve ses bozulursa, isteğe bağlı olarak uygun aralığa kendiniz de ayarlayabilirsiniz.",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Erkekten kadına çevirmek için +12 tuş önerilir, kadından erkeğe çevirmek için ise -12 tuş önerilir. Eğer ses aralığı çok fazla genişler ve ses bozulursa, isteğe bağlı olarak uygun aralığa kendiniz de ayarlayabilirsiniz.",
|
||||||
"目标采样率": "Hedef örnekleme oranı:",
|
"目标采样率": "Hedef örnekleme oranı:",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "Modeli Eğit",
|
"训练模型": "Modeli Eğit",
|
||||||
"训练特征索引": "Özellik Dizinini Eğit",
|
"训练特征索引": "Özellik Dizinini Eğit",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Eğitim tamamlandı. Eğitim günlüklerini konsolda veya deney klasörü altındaki train.log dosyasında kontrol edebilirsiniz.",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Eğitim tamamlandı. Eğitim günlüklerini konsolda veya deney klasörü altındaki train.log dosyasında kontrol edebilirsiniz.",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "Lütfen konuşmacı/sanatçı no belirtin:",
|
"请指定说话人id": "Lütfen konuşmacı/sanatçı no belirtin:",
|
||||||
"请选择index文件": "Lütfen .index dosyası seçin",
|
"请选择index文件": "Lütfen .index dosyası seçin",
|
||||||
"请选择pth文件": "Lütfen .pth dosyası seçin",
|
"请选择pth文件": "Lütfen .pth dosyası seçin",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "Örnekleme uzunluğu",
|
"采样长度": "Örnekleme uzunluğu",
|
||||||
"重载设备列表": "Cihaz listesini yeniden yükle",
|
"重载设备列表": "Cihaz listesini yeniden yükle",
|
||||||
"音调设置": "Pitch ayarları",
|
"音调设置": "Pitch ayarları",
|
||||||
"音频设备(请使用同种类驱动)": "Ses cihazı (aynı tür sürücüyü kullanın)",
|
"音频设备": "Ses cihazı",
|
||||||
"音高算法": "音高算法",
|
"音高算法": "音高算法",
|
||||||
"额外推理时长": "Ekstra çıkartma süresi"
|
"额外推理时长": "Ekstra çıkartma süresi"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "版本",
|
"版本": "版本",
|
||||||
"特征提取": "特征提取",
|
"特征提取": "特征提取",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特征检索库文件路径,为空则使用下拉的选择结果",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "特征检索库文件路径,为空则使用下拉的选择结果",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ",
|
||||||
"目标采样率": "目标采样率",
|
"目标采样率": "目标采样率",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "训练模型",
|
"训练模型": "训练模型",
|
||||||
"训练特征索引": "训练特征索引",
|
"训练特征索引": "训练特征索引",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "请指定说话人id",
|
"请指定说话人id": "请指定说话人id",
|
||||||
"请选择index文件": "请选择index文件",
|
"请选择index文件": "请选择index文件",
|
||||||
"请选择pth文件": "请选择pth文件",
|
"请选择pth文件": "请选择pth文件",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "采样长度",
|
"采样长度": "采样长度",
|
||||||
"重载设备列表": "重载设备列表",
|
"重载设备列表": "重载设备列表",
|
||||||
"音调设置": "音调设置",
|
"音调设置": "音调设置",
|
||||||
"音频设备(请使用同种类驱动)": "音频设备(请使用同种类驱动)",
|
"音频设备": "音频设备",
|
||||||
"音高算法": "音高算法",
|
"音高算法": "音高算法",
|
||||||
"额外推理时长": "额外推理时长"
|
"额外推理时长": "额外推理时长"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "版本",
|
"版本": "版本",
|
||||||
"特征提取": "特徵提取",
|
"特征提取": "特徵提取",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||||
"目标采样率": "目標取樣率",
|
"目标采样率": "目標取樣率",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "訓練模型",
|
"训练模型": "訓練模型",
|
||||||
"训练特征索引": "訓練特徵索引",
|
"训练特征索引": "訓練特徵索引",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "請指定說話人id",
|
"请指定说话人id": "請指定說話人id",
|
||||||
"请选择index文件": "请选择index文件",
|
"请选择index文件": "请选择index文件",
|
||||||
"请选择pth文件": "请选择pth文件",
|
"请选择pth文件": "请选择pth文件",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "取樣長度",
|
"采样长度": "取樣長度",
|
||||||
"重载设备列表": "重載設備列表",
|
"重载设备列表": "重載設備列表",
|
||||||
"音调设置": "音調設定",
|
"音调设置": "音調設定",
|
||||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
"音频设备": "音訊設備",
|
||||||
"音高算法": "音高演算法",
|
"音高算法": "音高演算法",
|
||||||
"额外推理时长": "額外推理時長"
|
"额外推理时长": "額外推理時長"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "版本",
|
"版本": "版本",
|
||||||
"特征提取": "特徵提取",
|
"特征提取": "特徵提取",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||||
"目标采样率": "目標取樣率",
|
"目标采样率": "目標取樣率",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "訓練模型",
|
"训练模型": "訓練模型",
|
||||||
"训练特征索引": "訓練特徵索引",
|
"训练特征索引": "訓練特徵索引",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "請指定說話人id",
|
"请指定说话人id": "請指定說話人id",
|
||||||
"请选择index文件": "请选择index文件",
|
"请选择index文件": "请选择index文件",
|
||||||
"请选择pth文件": "请选择pth文件",
|
"请选择pth文件": "请选择pth文件",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "取樣長度",
|
"采样长度": "取樣長度",
|
||||||
"重载设备列表": "重載設備列表",
|
"重载设备列表": "重載設備列表",
|
||||||
"音调设置": "音調設定",
|
"音调设置": "音調設定",
|
||||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
"音频设备": "音訊設備",
|
||||||
"音高算法": "音高演算法",
|
"音高算法": "音高演算法",
|
||||||
"额外推理时长": "額外推理時長"
|
"额外推理时长": "額外推理時長"
|
||||||
}
|
}
|
||||||
|
|||||||
@ -90,6 +90,7 @@
|
|||||||
"版本": "版本",
|
"版本": "版本",
|
||||||
"特征提取": "特徵提取",
|
"特征提取": "特徵提取",
|
||||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||||
|
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||||
"目标采样率": "目標取樣率",
|
"目标采样率": "目標取樣率",
|
||||||
"算法延迟(ms):": "算法延迟(ms):",
|
"算法延迟(ms):": "算法延迟(ms):",
|
||||||
@ -101,6 +102,7 @@
|
|||||||
"训练模型": "訓練模型",
|
"训练模型": "訓練模型",
|
||||||
"训练特征索引": "訓練特徵索引",
|
"训练特征索引": "訓練特徵索引",
|
||||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||||
|
"设备类型": "设备类型",
|
||||||
"请指定说话人id": "請指定說話人id",
|
"请指定说话人id": "請指定說話人id",
|
||||||
"请选择index文件": "请选择index文件",
|
"请选择index文件": "请选择index文件",
|
||||||
"请选择pth文件": "请选择pth文件",
|
"请选择pth文件": "请选择pth文件",
|
||||||
@ -129,7 +131,7 @@
|
|||||||
"采样长度": "取樣長度",
|
"采样长度": "取樣長度",
|
||||||
"重载设备列表": "重載設備列表",
|
"重载设备列表": "重載設備列表",
|
||||||
"音调设置": "音調設定",
|
"音调设置": "音調設定",
|
||||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
"音频设备": "音訊設備",
|
||||||
"音高算法": "音高演算法",
|
"音高算法": "音高演算法",
|
||||||
"额外推理时长": "額外推理時長"
|
"额外推理时长": "額外推理時長"
|
||||||
}
|
}
|
||||||
|
|||||||
55
infer-web.py
55
infer-web.py
@ -34,6 +34,7 @@ import logging
|
|||||||
|
|
||||||
|
|
||||||
logging.getLogger("numba").setLevel(logging.WARNING)
|
logging.getLogger("numba").setLevel(logging.WARNING)
|
||||||
|
logging.getLogger("httpx").setLevel(logging.WARNING)
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
@ -132,16 +133,25 @@ class ToolButton(gr.Button, gr.components.FormComponent):
|
|||||||
weight_root = os.getenv("weight_root")
|
weight_root = os.getenv("weight_root")
|
||||||
weight_uvr5_root = os.getenv("weight_uvr5_root")
|
weight_uvr5_root = os.getenv("weight_uvr5_root")
|
||||||
index_root = os.getenv("index_root")
|
index_root = os.getenv("index_root")
|
||||||
|
outside_index_root = os.getenv("outside_index_root")
|
||||||
|
|
||||||
names = []
|
names = []
|
||||||
for name in os.listdir(weight_root):
|
for name in os.listdir(weight_root):
|
||||||
if name.endswith(".pth"):
|
if name.endswith(".pth"):
|
||||||
names.append(name)
|
names.append(name)
|
||||||
index_paths = []
|
index_paths = []
|
||||||
for root, dirs, files in os.walk(index_root, topdown=False):
|
|
||||||
for name in files:
|
|
||||||
if name.endswith(".index") and "trained" not in name:
|
def lookup_indices(index_root):
|
||||||
index_paths.append("%s/%s" % (root, name))
|
global index_paths
|
||||||
|
for root, dirs, files in os.walk(index_root, topdown=False):
|
||||||
|
for name in files:
|
||||||
|
if name.endswith(".index") and "trained" not in name:
|
||||||
|
index_paths.append("%s/%s" % (root, name))
|
||||||
|
|
||||||
|
|
||||||
|
lookup_indices(index_root)
|
||||||
|
lookup_indices(outside_index_root)
|
||||||
uvr5_names = []
|
uvr5_names = []
|
||||||
for name in os.listdir(weight_uvr5_root):
|
for name in os.listdir(weight_uvr5_root):
|
||||||
if name.endswith(".pth") or "onnx" in name:
|
if name.endswith(".pth") or "onnx" in name:
|
||||||
@ -210,7 +220,6 @@ def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
|
|||||||
os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
|
os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
|
||||||
f = open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "w")
|
f = open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "w")
|
||||||
f.close()
|
f.close()
|
||||||
per = 3.0 if config.is_half else 3.7
|
|
||||||
cmd = '"%s" infer/modules/train/preprocess.py "%s" %s %s "%s/logs/%s" %s %.1f' % (
|
cmd = '"%s" infer/modules/train/preprocess.py "%s" %s %s "%s/logs/%s" %s %.1f' % (
|
||||||
config.python_cmd,
|
config.python_cmd,
|
||||||
trainset_dir,
|
trainset_dir,
|
||||||
@ -219,9 +228,9 @@ def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
|
|||||||
now_dir,
|
now_dir,
|
||||||
exp_dir,
|
exp_dir,
|
||||||
config.noparallel,
|
config.noparallel,
|
||||||
per,
|
config.preprocess_per,
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
# , stdin=PIPE, stdout=PIPE,stderr=PIPE,cwd=now_dir
|
# , stdin=PIPE, stdout=PIPE,stderr=PIPE,cwd=now_dir
|
||||||
p = Popen(cmd, shell=True)
|
p = Popen(cmd, shell=True)
|
||||||
# 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
|
# 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
|
||||||
@ -263,7 +272,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||||||
f0method,
|
f0method,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
p = Popen(
|
p = Popen(
|
||||||
cmd, shell=True, cwd=now_dir
|
cmd, shell=True, cwd=now_dir
|
||||||
) # , stdin=PIPE, stdout=PIPE,stderr=PIPE
|
) # , stdin=PIPE, stdout=PIPE,stderr=PIPE
|
||||||
@ -294,7 +303,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||||||
config.is_half,
|
config.is_half,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
p = Popen(
|
p = Popen(
|
||||||
cmd, shell=True, cwd=now_dir
|
cmd, shell=True, cwd=now_dir
|
||||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||||
@ -317,7 +326,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||||||
exp_dir,
|
exp_dir,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
p = Popen(
|
p = Popen(
|
||||||
cmd, shell=True, cwd=now_dir
|
cmd, shell=True, cwd=now_dir
|
||||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||||
@ -347,7 +356,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||||||
ps = []
|
ps = []
|
||||||
for idx, n_g in enumerate(gpus):
|
for idx, n_g in enumerate(gpus):
|
||||||
cmd = (
|
cmd = (
|
||||||
'"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s'
|
'"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s %s'
|
||||||
% (
|
% (
|
||||||
config.python_cmd,
|
config.python_cmd,
|
||||||
config.device,
|
config.device,
|
||||||
@ -357,9 +366,10 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||||||
now_dir,
|
now_dir,
|
||||||
exp_dir,
|
exp_dir,
|
||||||
version19,
|
version19,
|
||||||
|
config.is_half,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
p = Popen(
|
p = Popen(
|
||||||
cmd, shell=True, cwd=now_dir
|
cmd, shell=True, cwd=now_dir
|
||||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||||
@ -596,7 +606,7 @@ def click_train(
|
|||||||
version19,
|
version19,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
logger.info(cmd)
|
logger.info("Execute: " + cmd)
|
||||||
p = Popen(cmd, shell=True, cwd=now_dir)
|
p = Popen(cmd, shell=True, cwd=now_dir)
|
||||||
p.wait()
|
p.wait()
|
||||||
return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
|
return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
|
||||||
@ -663,6 +673,23 @@ def train_index(exp_dir1, version19):
|
|||||||
"%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
"%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
||||||
% (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
|
% (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
|
||||||
)
|
)
|
||||||
|
try:
|
||||||
|
os.link(
|
||||||
|
"%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
||||||
|
% (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
|
||||||
|
"%s/%s_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
||||||
|
% (
|
||||||
|
outside_index_root,
|
||||||
|
exp_dir,
|
||||||
|
n_ivf,
|
||||||
|
index_ivf.nprobe,
|
||||||
|
exp_dir1,
|
||||||
|
version19,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
infos.append("链接索引到%s" % (outside_index_root))
|
||||||
|
except:
|
||||||
|
infos.append("链接索引到%s失败" % (outside_index_root))
|
||||||
|
|
||||||
infos.append("adding")
|
infos.append("adding")
|
||||||
yield "\n".join(infos)
|
yield "\n".join(infos)
|
||||||
@ -675,7 +702,7 @@ def train_index(exp_dir1, version19):
|
|||||||
% (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
|
% (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
|
||||||
)
|
)
|
||||||
infos.append(
|
infos.append(
|
||||||
"成功构建索引,added_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
"成功构建索引 added_IVF%s_Flat_nprobe_%s_%s_%s.index"
|
||||||
% (n_ivf, index_ivf.nprobe, exp_dir1, version19)
|
% (n_ivf, index_ivf.nprobe, exp_dir1, version19)
|
||||||
)
|
)
|
||||||
# faiss.write_index(index, '%s/added_IVF%s_Flat_FastScan_%s.index'%(exp_dir,n_ivf,version19))
|
# faiss.write_index(index, '%s/added_IVF%s_Flat_FastScan_%s.index'%(exp_dir,n_ivf,version19))
|
||||||
|
|||||||
@ -143,7 +143,7 @@ if __name__ == "__main__":
|
|||||||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||||
# n_p=16
|
# n_p=16
|
||||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||||
printt(sys.argv)
|
printt(" ".join(sys.argv))
|
||||||
featureInput = FeatureInput()
|
featureInput = FeatureInput()
|
||||||
paths = []
|
paths = []
|
||||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||||
|
|||||||
@ -106,7 +106,7 @@ if __name__ == "__main__":
|
|||||||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||||
# n_p=16
|
# n_p=16
|
||||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||||
printt(sys.argv)
|
printt(" ".join(sys.argv))
|
||||||
featureInput = FeatureInput()
|
featureInput = FeatureInput()
|
||||||
paths = []
|
paths = []
|
||||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||||
|
|||||||
@ -104,7 +104,7 @@ if __name__ == "__main__":
|
|||||||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||||
# n_p=16
|
# n_p=16
|
||||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||||
printt(sys.argv)
|
printt(" ".join(sys.argv))
|
||||||
featureInput = FeatureInput()
|
featureInput = FeatureInput()
|
||||||
paths = []
|
paths = []
|
||||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||||
|
|||||||
@ -8,14 +8,16 @@ os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.0"
|
|||||||
device = sys.argv[1]
|
device = sys.argv[1]
|
||||||
n_part = int(sys.argv[2])
|
n_part = int(sys.argv[2])
|
||||||
i_part = int(sys.argv[3])
|
i_part = int(sys.argv[3])
|
||||||
if len(sys.argv) == 6:
|
if len(sys.argv) == 7:
|
||||||
exp_dir = sys.argv[4]
|
exp_dir = sys.argv[4]
|
||||||
version = sys.argv[5]
|
version = sys.argv[5]
|
||||||
|
is_half = sys.argv[6].lower() == "true"
|
||||||
else:
|
else:
|
||||||
i_gpu = sys.argv[4]
|
i_gpu = sys.argv[4]
|
||||||
exp_dir = sys.argv[5]
|
exp_dir = sys.argv[5]
|
||||||
os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
|
os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
|
||||||
version = sys.argv[6]
|
version = sys.argv[6]
|
||||||
|
is_half = sys.argv[7].lower() == "true"
|
||||||
import fairseq
|
import fairseq
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import soundfile as sf
|
import soundfile as sf
|
||||||
@ -49,10 +51,10 @@ def printt(strr):
|
|||||||
f.flush()
|
f.flush()
|
||||||
|
|
||||||
|
|
||||||
printt(sys.argv)
|
printt(" ".join(sys.argv))
|
||||||
model_path = "assets/hubert/hubert_base.pt"
|
model_path = "assets/hubert/hubert_base.pt"
|
||||||
|
|
||||||
printt(exp_dir)
|
printt("exp_dir: " + exp_dir)
|
||||||
wavPath = "%s/1_16k_wavs" % exp_dir
|
wavPath = "%s/1_16k_wavs" % exp_dir
|
||||||
outPath = (
|
outPath = (
|
||||||
"%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir
|
"%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir
|
||||||
@ -91,8 +93,9 @@ models, saved_cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
|||||||
model = models[0]
|
model = models[0]
|
||||||
model = model.to(device)
|
model = model.to(device)
|
||||||
printt("move model to %s" % device)
|
printt("move model to %s" % device)
|
||||||
if device not in ["mps", "cpu"]:
|
if is_half:
|
||||||
model = model.half()
|
if device not in ["mps", "cpu"]:
|
||||||
|
model = model.half()
|
||||||
model.eval()
|
model.eval()
|
||||||
|
|
||||||
todo = sorted(list(os.listdir(wavPath)))[i_part::n_part]
|
todo = sorted(list(os.listdir(wavPath)))[i_part::n_part]
|
||||||
@ -115,7 +118,7 @@ else:
|
|||||||
inputs = {
|
inputs = {
|
||||||
"source": (
|
"source": (
|
||||||
feats.half().to(device)
|
feats.half().to(device)
|
||||||
if device not in ["mps", "cpu"]
|
if is_half and device not in ["mps", "cpu"]
|
||||||
else feats.to(device)
|
else feats.to(device)
|
||||||
),
|
),
|
||||||
"padding_mask": padding_mask.to(device),
|
"padding_mask": padding_mask.to(device),
|
||||||
|
|||||||
@ -6,14 +6,13 @@ from scipy import signal
|
|||||||
|
|
||||||
now_dir = os.getcwd()
|
now_dir = os.getcwd()
|
||||||
sys.path.append(now_dir)
|
sys.path.append(now_dir)
|
||||||
print(sys.argv)
|
print(*sys.argv[1:])
|
||||||
inp_root = sys.argv[1]
|
inp_root = sys.argv[1]
|
||||||
sr = int(sys.argv[2])
|
sr = int(sys.argv[2])
|
||||||
n_p = int(sys.argv[3])
|
n_p = int(sys.argv[3])
|
||||||
exp_dir = sys.argv[4]
|
exp_dir = sys.argv[4]
|
||||||
noparallel = sys.argv[5] == "True"
|
noparallel = sys.argv[5] == "True"
|
||||||
per = float(sys.argv[6])
|
per = float(sys.argv[6])
|
||||||
import multiprocessing
|
|
||||||
import os
|
import os
|
||||||
import traceback
|
import traceback
|
||||||
|
|
||||||
@ -24,16 +23,13 @@ from scipy.io import wavfile
|
|||||||
from infer.lib.audio import load_audio
|
from infer.lib.audio import load_audio
|
||||||
from infer.lib.slicer2 import Slicer
|
from infer.lib.slicer2 import Slicer
|
||||||
|
|
||||||
mutex = multiprocessing.Lock()
|
|
||||||
f = open("%s/preprocess.log" % exp_dir, "a+")
|
f = open("%s/preprocess.log" % exp_dir, "a+")
|
||||||
|
|
||||||
|
|
||||||
def println(strr):
|
def println(strr):
|
||||||
mutex.acquire()
|
|
||||||
print(strr)
|
print(strr)
|
||||||
f.write("%s\n" % strr)
|
f.write("%s\n" % strr)
|
||||||
f.flush()
|
f.flush()
|
||||||
mutex.release()
|
|
||||||
|
|
||||||
|
|
||||||
class PreProcess:
|
class PreProcess:
|
||||||
@ -104,9 +100,9 @@ class PreProcess:
|
|||||||
idx1 += 1
|
idx1 += 1
|
||||||
break
|
break
|
||||||
self.norm_write(tmp_audio, idx0, idx1)
|
self.norm_write(tmp_audio, idx0, idx1)
|
||||||
println("%s->Suc." % path)
|
println("%s\t-> Success" % path)
|
||||||
except:
|
except:
|
||||||
println("%s->%s" % (path, traceback.format_exc()))
|
println("%s\t-> %s" % (path, traceback.format_exc()))
|
||||||
|
|
||||||
def pipeline_mp(self, infos):
|
def pipeline_mp(self, infos):
|
||||||
for path, idx0 in infos:
|
for path, idx0 in infos:
|
||||||
@ -138,7 +134,6 @@ class PreProcess:
|
|||||||
def preprocess_trainset(inp_root, sr, n_p, exp_dir, per):
|
def preprocess_trainset(inp_root, sr, n_p, exp_dir, per):
|
||||||
pp = PreProcess(sr, exp_dir, per)
|
pp = PreProcess(sr, exp_dir, per)
|
||||||
println("start preprocess")
|
println("start preprocess")
|
||||||
println(sys.argv)
|
|
||||||
pp.pipeline_mp_inp_dir(inp_root, n_p)
|
pp.pipeline_mp_inp_dir(inp_root, n_p)
|
||||||
println("end preprocess")
|
println("end preprocess")
|
||||||
|
|
||||||
|
|||||||
3642
poetry.lock
generated
3642
poetry.lock
generated
File diff suppressed because it is too large
Load Diff
@ -1,64 +0,0 @@
|
|||||||
[tool.poetry]
|
|
||||||
name = "rvc-beta"
|
|
||||||
version = "0.1.0"
|
|
||||||
description = ""
|
|
||||||
authors = ["lj1995"]
|
|
||||||
license = "MIT"
|
|
||||||
|
|
||||||
[tool.poetry.dependencies]
|
|
||||||
python = "^3.8"
|
|
||||||
torch = "^2.0.0"
|
|
||||||
torchaudio = "^2.0.1"
|
|
||||||
Cython = "^0.29.34"
|
|
||||||
gradio = "^4.11.0"
|
|
||||||
future = "^0.18.3"
|
|
||||||
pydub = "^0.25.1"
|
|
||||||
soundfile = "^0.12.1"
|
|
||||||
ffmpeg-python = "^0.2.0"
|
|
||||||
tensorboardX = "^2.6"
|
|
||||||
functorch = "^2.0.0"
|
|
||||||
fairseq = "^0.12.2"
|
|
||||||
faiss-cpu = "^1.7.2"
|
|
||||||
Jinja2 = "^3.1.2"
|
|
||||||
json5 = "^0.9.11"
|
|
||||||
librosa = "0.9.1"
|
|
||||||
llvmlite = "0.39.0"
|
|
||||||
Markdown = "^3.4.3"
|
|
||||||
matplotlib = "^3.7.1"
|
|
||||||
matplotlib-inline = "^0.1.6"
|
|
||||||
numba = "0.56.4"
|
|
||||||
numpy = "1.23.5"
|
|
||||||
scipy = "1.9.3"
|
|
||||||
praat-parselmouth = "^0.4.3"
|
|
||||||
Pillow = "9.3.0"
|
|
||||||
pyworld = "^0.3.2"
|
|
||||||
resampy = "^0.4.2"
|
|
||||||
scikit-learn = "^1.2.2"
|
|
||||||
starlette = "^0.27.0"
|
|
||||||
tensorboard = "^2.12.1"
|
|
||||||
tensorboard-data-server = "^0.7.0"
|
|
||||||
tensorboard-plugin-wit = "^1.8.1"
|
|
||||||
torchgen = "^0.0.1"
|
|
||||||
tqdm = "^4.65.0"
|
|
||||||
tornado = "^6.3"
|
|
||||||
Werkzeug = "^2.2.3"
|
|
||||||
uc-micro-py = "^1.0.1"
|
|
||||||
sympy = "^1.11.1"
|
|
||||||
tabulate = "^0.9.0"
|
|
||||||
PyYAML = "^6.0"
|
|
||||||
pyasn1 = "^0.4.8"
|
|
||||||
pyasn1-modules = "^0.2.8"
|
|
||||||
fsspec = "^2023.3.0"
|
|
||||||
absl-py = "^1.4.0"
|
|
||||||
audioread = "^3.0.0"
|
|
||||||
uvicorn = "^0.21.1"
|
|
||||||
colorama = "^0.4.6"
|
|
||||||
torchcrepe = "0.0.20"
|
|
||||||
python-dotenv = "^1.0.0"
|
|
||||||
av = "^10.0.0"
|
|
||||||
|
|
||||||
[tool.poetry.dev-dependencies]
|
|
||||||
|
|
||||||
[build-system]
|
|
||||||
requires = ["poetry-core>=1.0.0"]
|
|
||||||
build-backend = "poetry.core.masonry.api"
|
|
||||||
48
requirements-py311.txt
Normal file
48
requirements-py311.txt
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
joblib>=1.1.0
|
||||||
|
numba
|
||||||
|
numpy
|
||||||
|
scipy
|
||||||
|
librosa==0.9.1
|
||||||
|
llvmlite
|
||||||
|
fairseq @ git+https://github.com/One-sixth/fairseq.git
|
||||||
|
faiss-cpu
|
||||||
|
gradio==3.34.0
|
||||||
|
Cython
|
||||||
|
pydub>=0.25.1
|
||||||
|
soundfile>=0.12.1
|
||||||
|
ffmpeg-python>=0.2.0
|
||||||
|
tensorboardX
|
||||||
|
Jinja2>=3.1.2
|
||||||
|
json5
|
||||||
|
Markdown
|
||||||
|
matplotlib>=3.7.0
|
||||||
|
matplotlib-inline>=0.1.3
|
||||||
|
praat-parselmouth>=0.4.2
|
||||||
|
Pillow>=9.1.1
|
||||||
|
resampy>=0.4.2
|
||||||
|
scikit-learn
|
||||||
|
tensorboard
|
||||||
|
tqdm>=4.63.1
|
||||||
|
tornado>=6.1
|
||||||
|
Werkzeug>=2.2.3
|
||||||
|
uc-micro-py>=1.0.1
|
||||||
|
sympy>=1.11.1
|
||||||
|
tabulate>=0.8.10
|
||||||
|
PyYAML>=6.0
|
||||||
|
pyasn1>=0.4.8
|
||||||
|
pyasn1-modules>=0.2.8
|
||||||
|
fsspec>=2022.11.0
|
||||||
|
absl-py>=1.2.0
|
||||||
|
audioread
|
||||||
|
uvicorn>=0.21.1
|
||||||
|
colorama>=0.4.5
|
||||||
|
pyworld==0.3.2
|
||||||
|
httpx
|
||||||
|
onnxruntime; sys_platform == 'darwin'
|
||||||
|
onnxruntime-gpu; sys_platform != 'darwin'
|
||||||
|
torchcrepe==0.0.20
|
||||||
|
fastapi==0.88
|
||||||
|
torchfcpe
|
||||||
|
ffmpy==0.3.1
|
||||||
|
python-dotenv>=1.0.0
|
||||||
|
av
|
||||||
@ -1,11 +1,11 @@
|
|||||||
joblib>=1.1.0
|
joblib>=1.1.0
|
||||||
numba==0.56.4
|
numba
|
||||||
numpy==1.23.5
|
numpy
|
||||||
scipy
|
scipy
|
||||||
librosa==0.9.1
|
librosa==0.9.1
|
||||||
llvmlite==0.39.0
|
llvmlite
|
||||||
fairseq==0.12.2
|
fairseq
|
||||||
faiss-cpu==1.7.3
|
faiss-cpu
|
||||||
gradio==3.34.0
|
gradio==3.34.0
|
||||||
Cython
|
Cython
|
||||||
pydub>=0.25.1
|
pydub>=0.25.1
|
||||||
|
|||||||
11
run.sh
11
run.sh
@ -17,7 +17,7 @@ else
|
|||||||
requirements_file="requirements.txt"
|
requirements_file="requirements.txt"
|
||||||
|
|
||||||
# Check if Python 3.8 is installed
|
# Check if Python 3.8 is installed
|
||||||
if ! command -v python3 >/dev/null 2>&1; then
|
if ! command -v python3.8 >/dev/null 2>&1 || pyenv versions --bare | grep -q "3.8"; then
|
||||||
echo "Python 3 not found. Attempting to install 3.8..."
|
echo "Python 3 not found. Attempting to install 3.8..."
|
||||||
if [ "$(uname)" = "Darwin" ] && command -v brew >/dev/null 2>&1; then
|
if [ "$(uname)" = "Darwin" ] && command -v brew >/dev/null 2>&1; then
|
||||||
brew install python@3.8
|
brew install python@3.8
|
||||||
@ -30,18 +30,18 @@ else
|
|||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
|
|
||||||
python3 -m venv .venv
|
python3.8 -m venv .venv
|
||||||
. .venv/bin/activate
|
. .venv/bin/activate
|
||||||
|
|
||||||
# Check if required packages are installed and install them if not
|
# Check if required packages are installed and install them if not
|
||||||
if [ -f "${requirements_file}" ]; then
|
if [ -f "${requirements_file}" ]; then
|
||||||
installed_packages=$(python3 -m pip freeze)
|
installed_packages=$(python3.8 -m pip freeze)
|
||||||
while IFS= read -r package; do
|
while IFS= read -r package; do
|
||||||
expr "${package}" : "^#.*" > /dev/null && continue
|
expr "${package}" : "^#.*" > /dev/null && continue
|
||||||
package_name=$(echo "${package}" | sed 's/[<>=!].*//')
|
package_name=$(echo "${package}" | sed 's/[<>=!].*//')
|
||||||
if ! echo "${installed_packages}" | grep -q "${package_name}"; then
|
if ! echo "${installed_packages}" | grep -q "${package_name}"; then
|
||||||
echo "${package_name} not found. Attempting to install..."
|
echo "${package_name} not found. Attempting to install..."
|
||||||
python3 -m pip install --upgrade "${package}"
|
python3.8 -m pip install --upgrade "${package}"
|
||||||
fi
|
fi
|
||||||
done < "${requirements_file}"
|
done < "${requirements_file}"
|
||||||
else
|
else
|
||||||
@ -51,6 +51,7 @@ else
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
# Download models
|
# Download models
|
||||||
|
chmod +x tools/dlmodels.sh
|
||||||
./tools/dlmodels.sh
|
./tools/dlmodels.sh
|
||||||
|
|
||||||
if [ $? -ne 0 ]; then
|
if [ $? -ne 0 ]; then
|
||||||
@ -58,4 +59,4 @@ if [ $? -ne 0 ]; then
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
# Run the main script
|
# Run the main script
|
||||||
python3 infer-web.py --pycmd python3
|
python3.8 infer-web.py --pycmd python3.8
|
||||||
|
|||||||
@ -63,6 +63,9 @@ set hb=hubert_base.pt
|
|||||||
|
|
||||||
set dlhb=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt
|
set dlhb=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt
|
||||||
|
|
||||||
|
set rmvpe=rmvpe.pt
|
||||||
|
set dlrmvpe=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt
|
||||||
|
|
||||||
echo dir check start.
|
echo dir check start.
|
||||||
echo=
|
echo=
|
||||||
|
|
||||||
@ -332,7 +335,7 @@ if exist "%~dp0assets\uvr5_weights\onnx_dereverb_By_FoxJoy\%onnx_dereverb%" (
|
|||||||
|
|
||||||
echo checking %hb%
|
echo checking %hb%
|
||||||
if exist "%~dp0assets\hubert\%hb%" (
|
if exist "%~dp0assets\hubert\%hb%" (
|
||||||
echo %hb% in .\assets\hubert\pretrained checked.
|
echo %hb% in .\assets\hubert checked.
|
||||||
echo=
|
echo=
|
||||||
) else (
|
) else (
|
||||||
echo failed. starting download from huggingface.
|
echo failed. starting download from huggingface.
|
||||||
@ -341,6 +344,17 @@ if exist "%~dp0assets\hubert\%hb%" (
|
|||||||
echo=)
|
echo=)
|
||||||
)
|
)
|
||||||
|
|
||||||
|
echo checking %rmvpe%
|
||||||
|
if exist "%~dp0assets\rmvpe\%rmvpe%" (
|
||||||
|
echo %rmvpe% in .\assets\rmvpe checked.
|
||||||
|
echo=
|
||||||
|
) else (
|
||||||
|
echo failed. starting download from huggingface.
|
||||||
|
%~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlrmvpe% -d %~dp0assets\rmvpe\ -o %rmvpe%
|
||||||
|
if exist "%~dp0assets\rmvpe\%rmvpe%" (echo download successful.) else (echo please try again!
|
||||||
|
echo=)
|
||||||
|
)
|
||||||
|
|
||||||
echo required files check finished.
|
echo required files check finished.
|
||||||
echo envfiles check complete.
|
echo envfiles check complete.
|
||||||
pause
|
pause
|
||||||
|
|||||||
@ -1,566 +1,81 @@
|
|||||||
#!/bin/bash
|
#!/bin/sh
|
||||||
|
|
||||||
echo working dir is $(pwd)
|
printf "working dir is %s\n" "$PWD"
|
||||||
echo downloading requirement aria2 check.
|
echo "downloading requirement aria2 check."
|
||||||
|
|
||||||
if command -v aria2c &> /dev/null
|
if command -v aria2c > /dev/null 2>&1
|
||||||
then
|
then
|
||||||
echo "aria2c command found"
|
echo "aria2 command found"
|
||||||
else
|
else
|
||||||
echo failed. please install aria2
|
echo "failed. please install aria2"
|
||||||
sleep 5
|
|
||||||
exit 1
|
exit 1
|
||||||
fi
|
fi
|
||||||
|
|
||||||
d32="f0D32k.pth"
|
echo "dir check start."
|
||||||
d40="f0D40k.pth"
|
|
||||||
d48="f0D48k.pth"
|
|
||||||
g32="f0G32k.pth"
|
|
||||||
g40="f0G40k.pth"
|
|
||||||
g48="f0G48k.pth"
|
|
||||||
|
|
||||||
d40v2="f0D40k.pth"
|
check_dir() {
|
||||||
g40v2="f0G40k.pth"
|
[ -d "$1" ] && printf "dir %s checked\n" "$1" || \
|
||||||
|
printf "failed. generating dir %s\n" "$1" && mkdir -p "$1"
|
||||||
|
}
|
||||||
|
|
||||||
dld32="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D32k.pth"
|
check_dir "./assets/pretrained"
|
||||||
dld40="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D40k.pth"
|
check_dir "./assets/pretrained_v2"
|
||||||
dld48="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D48k.pth"
|
check_dir "./assets/uvr5_weights"
|
||||||
dlg32="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G32k.pth"
|
check_dir "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy"
|
||||||
dlg40="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G40k.pth"
|
|
||||||
dlg48="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G48k.pth"
|
|
||||||
|
|
||||||
dld40v2="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth"
|
echo "dir check finished."
|
||||||
dlg40v2="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth"
|
|
||||||
|
|
||||||
hp2_all="HP2_all_vocals.pth"
|
echo "required files check start."
|
||||||
hp3_all="HP3_all_vocals.pth"
|
check_file_pretrained() {
|
||||||
hp5_only="HP5_only_main_vocal.pth"
|
printf "checking %s\n" "$2"
|
||||||
VR_DeEchoAggressive="VR-DeEchoAggressive.pth"
|
if [ -f "./assets/""$1""/""$2""" ]; then
|
||||||
VR_DeEchoDeReverb="VR-DeEchoDeReverb.pth"
|
printf "%s in ./assets/%s checked.\n" "$2" "$1"
|
||||||
VR_DeEchoNormal="VR-DeEchoNormal.pth"
|
else
|
||||||
onnx_dereverb="vocals.onnx"
|
echo failed. starting download from huggingface.
|
||||||
rmvpe="rmvpe.pt"
|
if command -v aria2c > /dev/null 2>&1; then
|
||||||
|
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$1"/"$2" -d ./assets/"$1" -o "$2"
|
||||||
|
[ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
|
||||||
|
else
|
||||||
|
echo "aria2c command not found. Please install aria2c and try again."
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
dlhp2_all="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2_all_vocals.pth"
|
check_file_special() {
|
||||||
dlhp3_all="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP3_all_vocals.pth"
|
printf "checking %s\n" "$2"
|
||||||
dlhp5_only="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5_only_main_vocal.pth"
|
if [ -f "./assets/""$1""/""$2""" ]; then
|
||||||
dlVR_DeEchoAggressive="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoAggressive.pth"
|
printf "%s in ./assets/%s checked.\n" "$2" "$1"
|
||||||
dlVR_DeEchoDeReverb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoDeReverb.pth"
|
else
|
||||||
dlVR_DeEchoNormal="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoNormal.pth"
|
echo failed. starting download from huggingface.
|
||||||
dlonnx_dereverb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/onnx_dereverb_By_FoxJoy/vocals.onnx"
|
if command -v aria2c > /dev/null 2>&1; then
|
||||||
dlrmvpe="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt"
|
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$2" -d ./assets/"$1" -o "$2"
|
||||||
|
[ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
|
||||||
|
else
|
||||||
|
echo "aria2c command not found. Please install aria2c and try again."
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
hb="hubert_base.pt"
|
check_file_pretrained pretrained D32k.pth
|
||||||
|
check_file_pretrained pretrained D40k.pth
|
||||||
|
check_file_pretrained pretrained D48k.pth
|
||||||
|
check_file_pretrained pretrained G32k.pth
|
||||||
|
check_file_pretrained pretrained G40k.pth
|
||||||
|
check_file_pretrained pretrained G48k.pth
|
||||||
|
check_file_pretrained pretrained_v2 f0D40k.pth
|
||||||
|
check_file_pretrained pretrained_v2 f0G40k.pth
|
||||||
|
check_file_pretrained pretrained_v2 D40k.pth
|
||||||
|
check_file_pretrained pretrained_v2 G40k.pth
|
||||||
|
check_file_pretrained uvr5_weights HP2_all_vocals.pth
|
||||||
|
check_file_pretrained uvr5_weights HP3_all_vocals.pth
|
||||||
|
check_file_pretrained uvr5_weights HP5_only_main_vocal.pth
|
||||||
|
check_file_pretrained uvr5_weights VR-DeEchoAggressive.pth
|
||||||
|
check_file_pretrained uvr5_weights VR-DeEchoDeReverb.pth
|
||||||
|
check_file_pretrained uvr5_weights VR-DeEchoNormal.pth
|
||||||
|
check_file_pretrained uvr5_weights "onnx_dereverb_By_FoxJoy/vocals.onnx"
|
||||||
|
check_file_special rmvpe rmvpe.pt
|
||||||
|
check_file_special hubert hubert_base.pt
|
||||||
|
|
||||||
dlhb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt"
|
echo "required files check finished."
|
||||||
|
|
||||||
echo dir check start.
|
|
||||||
|
|
||||||
if [ -d "./assets/pretrained" ]; then
|
|
||||||
echo dir ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. generating dir ./assets/pretrained.
|
|
||||||
mkdir pretrained
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ -d "./assets/pretrained_v2" ]; then
|
|
||||||
echo dir ./assets/pretrained_v2 checked.
|
|
||||||
else
|
|
||||||
echo failed. generating dir ./assets/pretrained_v2.
|
|
||||||
mkdir pretrained_v2
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ -d "./assets/uvr5_weights" ]; then
|
|
||||||
echo dir ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. generating dir ./assets/uvr5_weights.
|
|
||||||
mkdir uvr5_weights
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ -d "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy" ]; then
|
|
||||||
echo dir ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy checked.
|
|
||||||
else
|
|
||||||
echo failed. generating dir ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy.
|
|
||||||
mkdir uvr5_weights/onnx_dereverb_By_FoxJoy
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo dir check finished.
|
|
||||||
|
|
||||||
echo required files check start.
|
|
||||||
|
|
||||||
echo checking D32k.pth
|
|
||||||
if [ -f "./assets/pretrained/D32k.pth" ]; then
|
|
||||||
echo D32k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D32k.pth -d ./assets/pretrained -o D32k.pth
|
|
||||||
if [ -f "./assets/pretrained/D32k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking D40k.pth
|
|
||||||
if [ -f "./assets/pretrained/D40k.pth" ]; then
|
|
||||||
echo D40k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D40k.pth -d ./assets/pretrained -o D40k.pth
|
|
||||||
if [ -f "./assets/pretrained/D40k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking D40k.pth
|
|
||||||
if [ -f "./assets/pretrained_v2/D40k.pth" ]; then
|
|
||||||
echo D40k.pth in ./assets/pretrained_v2 checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d ./assets/pretrained_v2 -o D40k.pth
|
|
||||||
if [ -f "./assets/pretrained_v2/D40k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking D48k.pth
|
|
||||||
if [ -f "./assets/pretrained/D48k.pth" ]; then
|
|
||||||
echo D48k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D48k.pth -d ./assets/pretrained -o D48k.pth
|
|
||||||
if [ -f "./assets/pretrained/D48k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking G32k.pth
|
|
||||||
if [ -f "./assets/pretrained/G32k.pth" ]; then
|
|
||||||
echo G32k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G32k.pth -d ./assets/pretrained -o G32k.pth
|
|
||||||
if [ -f "./assets/pretrained/G32k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking G40k.pth
|
|
||||||
if [ -f "./assets/pretrained/G40k.pth" ]; then
|
|
||||||
echo G40k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G40k.pth -d ./assets/pretrained -o G40k.pth
|
|
||||||
if [ -f "./assets/pretrained/G40k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking G40k.pth
|
|
||||||
if [ -f "./assets/pretrained_v2/G40k.pth" ]; then
|
|
||||||
echo G40k.pth in ./assets/pretrained_v2 checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d ./assets/pretrained_v2 -o G40k.pth
|
|
||||||
if [ -f "./assets/pretrained_v2/G40k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking G48k.pth
|
|
||||||
if [ -f "./assets/pretrained/G48k.pth" ]; then
|
|
||||||
echo G48k.pth in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G48k.pth -d ./assets/pretrained -o G48k.pth
|
|
||||||
if [ -f "./assets/pretrained/G48k.pth" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $d32
|
|
||||||
if [ -f "./assets/pretrained/$d32" ]; then
|
|
||||||
echo $d32 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld32 -d ./assets/pretrained -o $d32
|
|
||||||
if [ -f "./assets/pretrained/$d32" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $d40
|
|
||||||
if [ -f "./assets/pretrained/$d40" ]; then
|
|
||||||
echo $d40 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld40 -d ./assets/pretrained -o $d40
|
|
||||||
if [ -f "./assets/pretrained/$d40" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $d40v2
|
|
||||||
if [ -f "./assets/pretrained_v2/$d40v2" ]; then
|
|
||||||
echo $d40v2 in ./assets/pretrained_v2 checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld40v2 -d ./assets/pretrained_v2 -o $d40v2
|
|
||||||
if [ -f "./assets/pretrained_v2/$d40v2" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $d48
|
|
||||||
if [ -f "./assets/pretrained/$d48" ]; then
|
|
||||||
echo $d48 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld48 -d ./assets/pretrained -o $d48
|
|
||||||
if [ -f "./assets/pretrained/$d48" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $g32
|
|
||||||
if [ -f "./assets/pretrained/$g32" ]; then
|
|
||||||
echo $g32 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg32 -d ./assets/pretrained -o $g32
|
|
||||||
if [ -f "./assets/pretrained/$g32" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $g40
|
|
||||||
if [ -f "./assets/pretrained/$g40" ]; then
|
|
||||||
echo $g40 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg40 -d ./assets/pretrained -o $g40
|
|
||||||
if [ -f "./assets/pretrained/$g40" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $g40v2
|
|
||||||
if [ -f "./assets/pretrained_v2/$g40v2" ]; then
|
|
||||||
echo $g40v2 in ./assets/pretrained_v2 checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg40v2 -d ./assets/pretrained_v2 -o $g40v2
|
|
||||||
if [ -f "./assets/pretrained_v2/$g40v2" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $g48
|
|
||||||
if [ -f "./assets/pretrained/$g48" ]; then
|
|
||||||
echo $g48 in ./assets/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg48 -d ./assets/pretrained -o $g48
|
|
||||||
if [ -f "./assets/pretrained/$g48" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $hp2_all
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp2_all" ]; then
|
|
||||||
echo $hp2_all in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp2_all -d ./assets/uvr5_weights -o $hp2_all
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp2_all" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $hp3_all
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp3_all" ]; then
|
|
||||||
echo $hp3_all in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp3_all -d ./assets/uvr5_weights -o $hp3_all
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp3_all" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $hp5_only
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp5_only" ]; then
|
|
||||||
echo $hp5_only in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp5_only -d ./assets/uvr5_weights -o $hp5_only
|
|
||||||
if [ -f "./assets/uvr5_weights/$hp5_only" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $VR_DeEchoAggressive
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoAggressive" ]; then
|
|
||||||
echo $VR_DeEchoAggressive in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoAggressive -d ./assets/uvr5_weights -o $VR_DeEchoAggressive
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoAggressive" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $VR_DeEchoDeReverb
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoDeReverb" ]; then
|
|
||||||
echo $VR_DeEchoDeReverb in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoDeReverb -d ./assets/uvr5_weights -o $VR_DeEchoDeReverb
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoDeReverb" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $VR_DeEchoNormal
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoNormal" ]; then
|
|
||||||
echo $VR_DeEchoNormal in ./assets/uvr5_weights checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoNormal -d ./assets/uvr5_weights -o $VR_DeEchoNormal
|
|
||||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoNormal" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $onnx_dereverb
|
|
||||||
if [ -f "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy/$onnx_dereverb" ]; then
|
|
||||||
echo $onnx_dereverb in ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlonnx_dereverb -d ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy -o $onnx_dereverb
|
|
||||||
if [ -f "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy/$onnx_dereverb" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $rmvpe
|
|
||||||
if [ -f "./assets/rmvpe/$rmvpe" ]; then
|
|
||||||
echo $rmvpe in ./assets/rmvpe checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlrmvpe -d ./assets/rmvpe -o $rmvpe
|
|
||||||
if [ -f "./assets/rmvpe/$rmvpe" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo checking $hb
|
|
||||||
if [ -f "./assets/hubert/$hb" ]; then
|
|
||||||
echo $hb in ./assets/hubert/pretrained checked.
|
|
||||||
else
|
|
||||||
echo failed. starting download from huggingface.
|
|
||||||
if command -v aria2c &> /dev/null; then
|
|
||||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhb -d ./assets/hubert/ -o $hb
|
|
||||||
if [ -f "./assets/hubert/$hb" ]; then
|
|
||||||
echo download successful.
|
|
||||||
else
|
|
||||||
echo please try again!
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
echo aria2c command not found. Please install aria2c and try again.
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
echo required files check finished.
|
|
||||||
|
|||||||
@ -91,8 +91,12 @@ class RVC:
|
|||||||
self.pth_path: str = pth_path
|
self.pth_path: str = pth_path
|
||||||
self.index_path = index_path
|
self.index_path = index_path
|
||||||
self.index_rate = index_rate
|
self.index_rate = index_rate
|
||||||
self.cache_pitch: np.ndarray = np.zeros(1024, dtype="int32")
|
self.cache_pitch: torch.Tensor = torch.zeros(
|
||||||
self.cache_pitchf = np.zeros(1024, dtype="float32")
|
1024, device=self.device, dtype=torch.long
|
||||||
|
)
|
||||||
|
self.cache_pitchf = torch.zeros(
|
||||||
|
1024, device=self.device, dtype=torch.float32
|
||||||
|
)
|
||||||
|
|
||||||
if last_rvc is None:
|
if last_rvc is None:
|
||||||
models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
||||||
@ -199,15 +203,17 @@ class RVC:
|
|||||||
self.index_rate = new_index_rate
|
self.index_rate = new_index_rate
|
||||||
|
|
||||||
def get_f0_post(self, f0):
|
def get_f0_post(self, f0):
|
||||||
f0bak = f0.copy()
|
if not torch.is_tensor(f0):
|
||||||
f0_mel = 1127 * np.log(1 + f0 / 700)
|
f0 = torch.from_numpy(f0)
|
||||||
|
f0 = f0.float().to(self.device).squeeze()
|
||||||
|
f0_mel = 1127 * torch.log(1 + f0 / 700)
|
||||||
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * 254 / (
|
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * 254 / (
|
||||||
self.f0_mel_max - self.f0_mel_min
|
self.f0_mel_max - self.f0_mel_min
|
||||||
) + 1
|
) + 1
|
||||||
f0_mel[f0_mel <= 1] = 1
|
f0_mel[f0_mel <= 1] = 1
|
||||||
f0_mel[f0_mel > 255] = 255
|
f0_mel[f0_mel > 255] = 255
|
||||||
f0_coarse = np.rint(f0_mel).astype(np.int32)
|
f0_coarse = torch.round(f0_mel).long()
|
||||||
return f0_coarse, f0bak
|
return f0_coarse, f0
|
||||||
|
|
||||||
def get_f0(self, x, f0_up_key, n_cpu, method="harvest"):
|
def get_f0(self, x, f0_up_key, n_cpu, method="harvest"):
|
||||||
n_cpu = int(n_cpu)
|
n_cpu = int(n_cpu)
|
||||||
@ -301,7 +307,6 @@ class RVC:
|
|||||||
pd = torchcrepe.filter.median(pd, 3)
|
pd = torchcrepe.filter.median(pd, 3)
|
||||||
f0 = torchcrepe.filter.mean(f0, 3)
|
f0 = torchcrepe.filter.mean(f0, 3)
|
||||||
f0[pd < 0.1] = 0
|
f0[pd < 0.1] = 0
|
||||||
f0 = f0[0].cpu().numpy()
|
|
||||||
f0 *= pow(2, f0_up_key / 12)
|
f0 *= pow(2, f0_up_key / 12)
|
||||||
return self.get_f0_post(f0)
|
return self.get_f0_post(f0)
|
||||||
|
|
||||||
@ -337,7 +342,6 @@ class RVC:
|
|||||||
threshold=0.006,
|
threshold=0.006,
|
||||||
)
|
)
|
||||||
f0 *= pow(2, f0_up_key / 12)
|
f0 *= pow(2, f0_up_key / 12)
|
||||||
f0 = f0.squeeze().cpu().numpy()
|
|
||||||
return self.get_f0_post(f0)
|
return self.get_f0_post(f0)
|
||||||
|
|
||||||
def infer(
|
def infer(
|
||||||
@ -370,21 +374,30 @@ class RVC:
|
|||||||
if hasattr(self, "index") and self.index_rate != 0:
|
if hasattr(self, "index") and self.index_rate != 0:
|
||||||
npy = feats[0][skip_head // 2 :].cpu().numpy().astype("float32")
|
npy = feats[0][skip_head // 2 :].cpu().numpy().astype("float32")
|
||||||
score, ix = self.index.search(npy, k=8)
|
score, ix = self.index.search(npy, k=8)
|
||||||
weight = np.square(1 / score)
|
if (ix >= 0).all():
|
||||||
weight /= weight.sum(axis=1, keepdims=True)
|
weight = np.square(1 / score)
|
||||||
npy = np.sum(self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1)
|
weight /= weight.sum(axis=1, keepdims=True)
|
||||||
if self.config.is_half:
|
npy = np.sum(
|
||||||
npy = npy.astype("float16")
|
self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1
|
||||||
feats[0][skip_head // 2 :] = (
|
)
|
||||||
torch.from_numpy(npy).unsqueeze(0).to(self.device) * self.index_rate
|
if self.config.is_half:
|
||||||
+ (1 - self.index_rate) * feats[0][skip_head // 2 :]
|
npy = npy.astype("float16")
|
||||||
)
|
feats[0][skip_head // 2 :] = (
|
||||||
|
torch.from_numpy(npy).unsqueeze(0).to(self.device)
|
||||||
|
* self.index_rate
|
||||||
|
+ (1 - self.index_rate) * feats[0][skip_head // 2 :]
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
printt(
|
||||||
|
"Invalid index. You MUST use added_xxxx.index but not trained_xxxx.index!"
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
printt("Index search FAILED or disabled")
|
printt("Index search FAILED or disabled")
|
||||||
except:
|
except:
|
||||||
traceback.print_exc()
|
traceback.print_exc()
|
||||||
printt("Index search FAILED")
|
printt("Index search FAILED")
|
||||||
t3 = ttime()
|
t3 = ttime()
|
||||||
|
p_len = input_wav.shape[0] // 160
|
||||||
if self.if_f0 == 1:
|
if self.if_f0 == 1:
|
||||||
f0_extractor_frame = block_frame_16k + 800
|
f0_extractor_frame = block_frame_16k + 800
|
||||||
if f0method == "rmvpe":
|
if f0method == "rmvpe":
|
||||||
@ -392,25 +405,14 @@ class RVC:
|
|||||||
pitch, pitchf = self.get_f0(
|
pitch, pitchf = self.get_f0(
|
||||||
input_wav[-f0_extractor_frame:], self.f0_up_key, self.n_cpu, f0method
|
input_wav[-f0_extractor_frame:], self.f0_up_key, self.n_cpu, f0method
|
||||||
)
|
)
|
||||||
start_frame = block_frame_16k // 160
|
shift = block_frame_16k // 160
|
||||||
end_frame = len(self.cache_pitch) - (pitch.shape[0] - 4) + start_frame
|
self.cache_pitch[:-shift] = self.cache_pitch[shift:].clone()
|
||||||
self.cache_pitch[:] = np.append(
|
self.cache_pitchf[:-shift] = self.cache_pitchf[shift:].clone()
|
||||||
self.cache_pitch[start_frame:end_frame], pitch[3:-1]
|
self.cache_pitch[4 - pitch.shape[0] :] = pitch[3:-1]
|
||||||
)
|
self.cache_pitchf[4 - pitch.shape[0] :] = pitchf[3:-1]
|
||||||
self.cache_pitchf[:] = np.append(
|
cache_pitch = self.cache_pitch[None, -p_len:]
|
||||||
self.cache_pitchf[start_frame:end_frame], pitchf[3:-1]
|
cache_pitchf = self.cache_pitchf[None, -p_len:]
|
||||||
)
|
|
||||||
t4 = ttime()
|
t4 = ttime()
|
||||||
p_len = input_wav.shape[0] // 160
|
|
||||||
if self.if_f0 == 1:
|
|
||||||
cache_pitch = (
|
|
||||||
torch.LongTensor(self.cache_pitch[-p_len:]).to(self.device).unsqueeze(0)
|
|
||||||
)
|
|
||||||
cache_pitchf = (
|
|
||||||
torch.FloatTensor(self.cache_pitchf[-p_len:])
|
|
||||||
.to(self.device)
|
|
||||||
.unsqueeze(0)
|
|
||||||
)
|
|
||||||
feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
|
feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
|
||||||
feats = feats[:, :p_len, :]
|
feats = feats[:, :p_len, :]
|
||||||
p_len = torch.LongTensor([p_len]).to(self.device)
|
p_len = torch.LongTensor([p_len]).to(self.device)
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user