diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
deleted file mode 100644
index 5e395ff..0000000
--- a/.github/ISSUE_TEMPLATE/bug_report.md
+++ /dev/null
@@ -1,28 +0,0 @@
----
-name: Bug report
-about: Report a bug or a feature that is not working how you expect it to
-title: ''
-labels: 'Type: Bug'
-assignees: ''
-
----
-
-**Describe the bug**
-A clear and concise description of what the bug is.
-
-**To Reproduce**
-Steps to reproduce the behavior:
-1. Selected settings: '...'
-2. See error
-
-**Expected behavior**
-A clear and concise description of what you expected to happen.
-
-**Screenshots**
-If applicable, add screenshots to help explain your problem and annotate the images.
-
-**Desktop (please complete the following information):**
- - OS: [e.g. iOS]
-
-**Additional context**
-Add any other context about the problem here.
diff --git a/.github/ISSUE_TEMPLATE/design-improvement.md b/.github/ISSUE_TEMPLATE/design-improvement.md
deleted file mode 100644
index ac6f27d..0000000
--- a/.github/ISSUE_TEMPLATE/design-improvement.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-name: Design Improvement
-about: Create a report to help us improve the design of the application
-title: "[DESIGN IMPROVEMENT]"
-labels: 'Type: Enhancement'
-assignees: DilanBoskan
-
----
-
-**Describe the flaw**
-A clear and concise description of where the design flaw is to be found
-
-**Expected behavior**
-A desired solution to the flaw.
-
-**Screenshots**
-If applicable, add screenshots to help explain your problem and annotate the images.
-
-**Additional context**
-Add any other context about the problem here.
diff --git a/.github/ISSUE_TEMPLATE/installation-problem.md b/.github/ISSUE_TEMPLATE/installation-problem.md
deleted file mode 100644
index 5da502f..0000000
--- a/.github/ISSUE_TEMPLATE/installation-problem.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-name: Installation Problem
-about: Create a report to help us identify your problem with the installation
-title: "[INSTALLATION PROBLEM]"
-labels: ''
-assignees: ''
-
----
-
-**To Reproduce**
-On which installation step did you encounter the issue.
-
-**Screenshots**
-Add screenshots to help explain your problem.
-
-**Desktop (please complete the following information):**
- - OS: [e.g. iOS]
-
-**Additional context**
-Add any other context about the problem here.
diff --git a/README.md b/README.md
index 95146fa..897ce5f 100644
--- a/README.md
+++ b/README.md
@@ -1,46 +1,112 @@
-# Ultimate Vocal Remover GUI v5.1.0
- +# Ultimate Vocal Remover GUI v5.2.0
+
+# Ultimate Vocal Remover GUI v5.2.0
+ [](https://github.com/anjok07/ultimatevocalremovergui/releases/latest)
[](https://github.com/anjok07/ultimatevocalremovergui/releases)
## About
-This application is a GUI version of the vocal remover AI created and posted by GitHub user [tsurumeso](https://github.com/tsurumeso). This version also comes with eight high-performance models trained by us. You can find tsurumeso's original command-line version [here](https://github.com/tsurumeso/vocal-remover).
+This application uses state-of-the-art source searation models to remove vocals from audio files. UVR's core developers trained all of the models provided in this package.
-- **The Developers**
- - [Anjok07](https://github.com/anjok07)- Model collaborator & UVR developer.
- - [aufr33](https://github.com/aufr33) - Model collaborator & fellow UVR developer. This project wouldn't be what it is without your help. Thank you for your continued support!
- - [DilanBoskan](https://github.com/DilanBoskan) - Thank you for helping bring the GUI to life! Your contributions to this project are greatly appreciated.
- - [tsurumeso](https://github.com/tsurumeso) - The engineer who authored the original AI code. Thank you for the hard work and dedication you put into the AI code UVR is built on!
+- **Core Developers**
+ - [Anjok07](https://github.com/anjok07)
+ - [aufr33](https://github.com/aufr33)
+
+## Installation
+
+### Windows Installation
+
+This installation bundle contains the UVR interface, Python, PyTorch, and other dependencies needed to run the application effectively. No prerequisites required.
+
+- Please Note:
+ - This installer is intended for those running Windows 10 or higher.
+ - Application functionality for systems running Windows 7 or lower is not guaranteed.
+ - Application functionality for Intel Pentium & Celeron CPUs systems is not guaranteed.
+
+- Download the UVR installer via one of the following mirrors below:
+ - [pCloud Mirror](https://u.pcloud.link/publink/show?code=XZAX8HVZ03lxQbQtyqBLl07bTPaFPm1jUAbX)
+ - [Google Drive Mirror](https://drive.google.com/file/d/1ALH1WB3WjNnRQoPJFIiJHG9uVqH4U50Q/view?usp=sharing)
+
+- **Optional**
+ - The Model Expansion Pack can be downloaded [here]()
+ - Please navigate to the "Updates" tab within the Help Guide provided in the GUI for instructions on installing the Model Expansion pack.
+ - This version of the GUI is fully backward compatible with the v4 models.
+
+### Other Platforms
+
+This application can be run on Mac & Linux by performing a manual install (see the **Manual Developer Installation** section below for more information). Some features may not be available on non-Windows platforms.
+
+## Application Manual
+
+**General Options**
+
+
[](https://github.com/anjok07/ultimatevocalremovergui/releases/latest)
[](https://github.com/anjok07/ultimatevocalremovergui/releases)
## About
-This application is a GUI version of the vocal remover AI created and posted by GitHub user [tsurumeso](https://github.com/tsurumeso). This version also comes with eight high-performance models trained by us. You can find tsurumeso's original command-line version [here](https://github.com/tsurumeso/vocal-remover).
+This application uses state-of-the-art source searation models to remove vocals from audio files. UVR's core developers trained all of the models provided in this package.
-- **The Developers**
- - [Anjok07](https://github.com/anjok07)- Model collaborator & UVR developer.
- - [aufr33](https://github.com/aufr33) - Model collaborator & fellow UVR developer. This project wouldn't be what it is without your help. Thank you for your continued support!
- - [DilanBoskan](https://github.com/DilanBoskan) - Thank you for helping bring the GUI to life! Your contributions to this project are greatly appreciated.
- - [tsurumeso](https://github.com/tsurumeso) - The engineer who authored the original AI code. Thank you for the hard work and dedication you put into the AI code UVR is built on!
+- **Core Developers**
+ - [Anjok07](https://github.com/anjok07)
+ - [aufr33](https://github.com/aufr33)
+
+## Installation
+
+### Windows Installation
+
+This installation bundle contains the UVR interface, Python, PyTorch, and other dependencies needed to run the application effectively. No prerequisites required.
+
+- Please Note:
+ - This installer is intended for those running Windows 10 or higher.
+ - Application functionality for systems running Windows 7 or lower is not guaranteed.
+ - Application functionality for Intel Pentium & Celeron CPUs systems is not guaranteed.
+
+- Download the UVR installer via one of the following mirrors below:
+ - [pCloud Mirror](https://u.pcloud.link/publink/show?code=XZAX8HVZ03lxQbQtyqBLl07bTPaFPm1jUAbX)
+ - [Google Drive Mirror](https://drive.google.com/file/d/1ALH1WB3WjNnRQoPJFIiJHG9uVqH4U50Q/view?usp=sharing)
+
+- **Optional**
+ - The Model Expansion Pack can be downloaded [here]()
+ - Please navigate to the "Updates" tab within the Help Guide provided in the GUI for instructions on installing the Model Expansion pack.
+ - This version of the GUI is fully backward compatible with the v4 models.
+
+### Other Platforms
+
+This application can be run on Mac & Linux by performing a manual install (see the **Manual Developer Installation** section below for more information). Some features may not be available on non-Windows platforms.
+
+## Application Manual
+
+**General Options**
+
+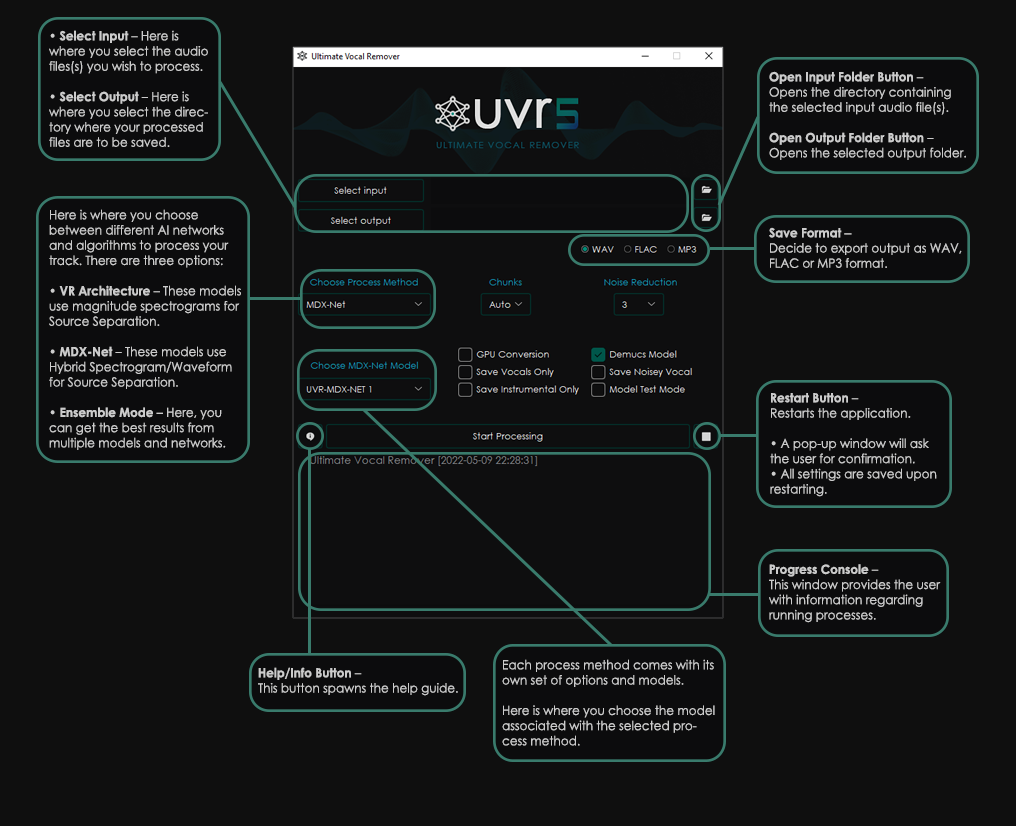 +
+**VR Architecture Options**
+
+
+
+**VR Architecture Options**
+
+ +
+**MDX-Net Options**
+
+
+
+**MDX-Net Options**
+
+ +
+**Ensemble Options**
+
+
+
+**Ensemble Options**
+
+ +
+**User Ensemble**
+
+
+
+**User Ensemble**
+
+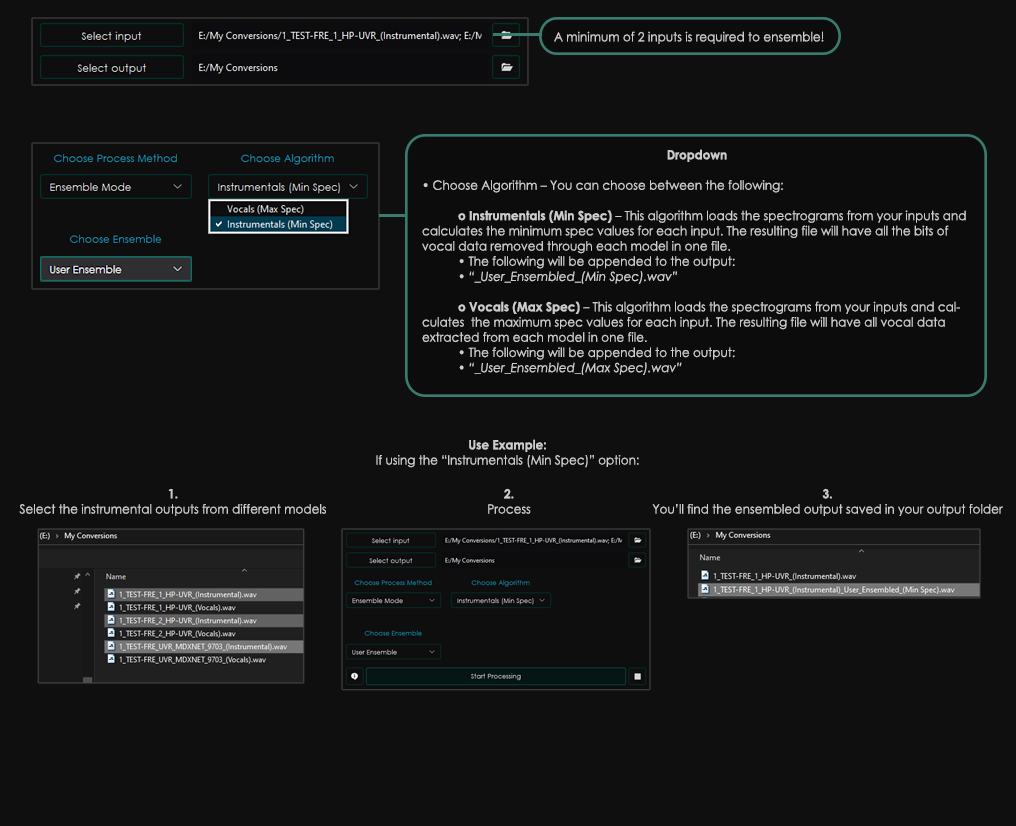 +
+### Other Application Notes
+
+- Nvidia GPUs with at least 8GBs of V-RAM are recommended.
+- This application is only compatible with 64-bit platforms.
+- This application relies on Sox - Sound Exchange for Noise Reduction.
+- This application relies on FFmpeg to process non-wav audio files.
+- The application will automatically remember your settings when closed.
+- Conversion times will significantly depend on your hardware.
+- These models are computationally intensive. Processing times might be slow on older or budget hardware. Please proceed with caution and pay attention to your PC to ensure it doesn't overheat. ***We are not responsible for any hardware damage.***
## Change Log
- **v4 vs. v5**
- The v5 models significantly outperform the v4 models.
- - The extraction's aggressiveness can be adjusted using the "Aggression Setting". The default value of 10 is optimal for most tracks.
+ - The extraction's aggressiveness can be adjusted using the "Aggression Setting." The default value of 10 is optimal for most tracks.
- All v2 and v4 models have been removed.
- - Ensemble Mode added - This allows the user to get the strongest result from each model.
+ - Ensemble Mode added - This allows the user to get the most robust result from each model.
- Stacked models have been entirely removed.
- - Stacked model feature has been replaced by the new aggression setting and model ensembling.
+ The new aggression setting and model ensembling have replaced the stacked model feature.
- The NFFT, HOP_SIZE, and SR values are now set internally.
+ - The MDX-NET AI engine and models have been added.
+ - This is a brand new feature added to the UVR GUI.
+ - 4 MDX-Net models trained by UVR developers are included in this package.
+ - The MDX-Net models provided were trained by the UVR core developers
+ - This network is less resource-intensive but incredibly powerful.
+ - MDX-Net is a Hybrid Waveform/Spectrogram network.
-- **Upcoming v5.2.0 Update**
- - MDX-NET AI engine and model support
+## Troubleshooting
-## Installation
+### Common Issues
-The application was made with Tkinter for cross-platform compatibility, so it should work with Windows, Mac, and Linux systems. However, this application has only been tested on Windows 10 & Linux Ubuntu.
+- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
-### Install Required Applications & Packages
+### Issue Reporting
-1. Download & install Python 3.9.8 [here](https://www.python.org/ftp/python/3.9.8/python-3.9.8-amd64.exe) (Windows link)
- - **Note:** Ensure the *"Add Python 3.9 to PATH"* box is checked
-2. Download the Source code zip here - https://github.com/Anjok07/ultimatevocalremovergui/archive/refs/heads/master.zip
-3. Download the models.zip here - https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.1.0/models.zip
+Please be as detailed as possible when posting a new issue.
+
+If possible, click the "Help Guide" button to the left of the "Start Processing" button and navigate to the "Error Log" tab for detailed error information that can be provided to us.
+
+## Manual Installation (For Developers)
+
+These instructions are for those installing UVR v5.2.0 **manually** only.
+
+1. Download & install Python 3.9 or lower (but no lower than 3.6) [here](https://www.python.org/downloads/)
+ - **Note:** Ensure the *"Add Python to PATH"* box is checked
+2. Download the Source code zip [here]()
+3. Download the models.zip [here]()
4. Extract the *ultimatevocalremovergui-master* folder within ultimatevocalremovergui-master.zip where ever you wish.
5. Extract the *models* folder within models.zip to the *ultimatevocalremovergui-master* directory.
- - **Note:** At this time, the GUI is hardcoded to run the models included in this package only.
6. Open the command prompt from the ultimatevocalremovergui-master directory and run the following commands, separately -
```
@@ -50,163 +116,36 @@ pip install --no-cache-dir -r requirements.txt
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
```
-### FFmpeg
+- FFmpeg
-FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg can be found on YouTube, WikiHow, Reddit, GitHub, and many other sources around the web.
+ - FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg is provided in the "More Info" tab within the Help Guide.
-- **Note:** If you are experiencing any errors when attempting to process any media files, not in the *.wav* format, please ensure FFmpeg is installed & configured correctly.
+- Running the GUI & Models
-### Running the GUI & Models
-
-- Open the file labeled *'VocalRemover.py'*.
- - It's recommended that you create a shortcut for the file labeled *'VocalRemover.py'* to your desktop for easy access.
- - **Note:** If you are unable to open the *'VocalRemover.py'* file, please go to the [**troubleshooting**](https://github.com/Anjok07/ultimatevocalremovergui/tree/beta#troubleshooting) section below.
-- **Note:** All output audio files will be in the *'.wav'* format.
-
-## Option Guide
-
-### Main Checkboxes
-- **GPU Conversion** - Selecting this option ensures the GPU is used to process conversions.
- - **Note:** This option will not work if you don't have a Cuda compatible GPU.
- - Nvidia GPUs are most compatible with Cuda.
- - **Note:** CPU conversions are much slower than those processed through the GPU.
-- **Post-process** - This option can potentially identify leftover instrumental artifacts within the vocal outputs. This option may improve the separation of *some* songs.
- - **Note:** Having this option selected can adversely affect the conversion process, depending on the track. Because of this, it's only recommended as a last resort.
-- **TTA** - This option performs Test-Time-Augmentation to improve the separation quality.
- - **Note:** Having this selected will increase the time it takes to complete a conversion.
-- **Output Image** - Selecting this option will include the spectrograms in *.jpg* format for the instrumental & vocal audio outputs.
-
-### Special Checkboxes
-- **Model Test Mode** - Only selectable when using the "*Single Model*" conversion method. This option makes it easier for users to test the results of different models and model combinations by eliminating the hassle of manually changing the filenames and creating new folders when processing the same track through multiple models. This option structures the model testing process.
- - When *' Model Test Mode'* is selected, the application will auto-generate a new folder in the *' Save to'* path you have chosen.
- - The new auto-generated folder will be named after the model(s) selected.
- - The output audio files will be saved to the auto-generated directory.
- - The filenames for the instrumental & vocal outputs will have the selected model(s) name(s) appended.
-- **Save All Outputs** - Only selectable when using the "*Ensemble Mode*" conversion method. This option will save all of the individual conversion outputs from each model within the ensemble.
- - When *'Save All Outputs'* is un-selected, the application will auto-delete all of the individual conversions generated by each model in the ensemble.
-
-### Additional Options
-
-- **Window Size** - The smaller your window size, the better your conversions will be. However, a smaller window means longer conversion times and heavier resource usage.
- - Here are the selectable window size values -
- - **1024** - Low conversion quality, shortest conversion time, low resource usage
- - **512** - Average conversion quality, average conversion time, normal resource usage
- - **320** - Better conversion quality, long conversion time, high resource usage
-- **Aggression Setting** - This option allows you to set how strong the vocal removal will be.
- - The range is 0-100.
- - Higher values perform deeper extractions.
- - The default is 10 for instrumental & vocal models.
- - Values over 10 can result in muddy-sounding instrumentals for the non-vocal models.
-- **Default Values:**
- - **Window Size** - 512
- - **Aggression Setting** - 10 (optimal setting for all conversions)
-
-### Other Buttons
-
-- **Open Export Directory** - This button will open your 'save to' directory. You will find it to the right of the *'Start Conversion'* button.
-
-## Models Included
-
-All of the models included in the release were trained on large datasets containing a diverse range of music genres and different training parameters.
-
-**Please Note:** Do not change the name of the models provided! The required parameters are specified and appended to the end of the filenames.
-
-- **Model Network Types**
- - **HP2** - The model layers are much larger. However, this makes them resource-heavy.
- - **HP** - The model layers are the standard size for UVR v5.
-
-### Main Models
-
-- **HP2_3BAND_44100_MSB2.pth** - This is a strong instrumental model trained using more data and new parameters.
-- **HP2_4BAND_44100_1.pth** - This is a strong instrumental model.
-- **HP2_4BAND_44100_2.pth** - This is a fine tuned version of the HP2_4BAND_44100_1.pth model.
-- **HP_4BAND_44100_A.pth** - This is a strong instrumental model.
-- **HP_4BAND_44100_B.pth** - This is a fine tuned version of the HP_4BAND_44100_A.pth model.
-- **HP_KAROKEE_4BAND_44100_SN.pth** - This is a model that removes main vocals while leaving background vocals intact.
-- **HP_Vocal_4BAND_44100.pth** - This model emphasizes vocal extraction. The vocal stem will be clean, but the instrumental might sound muddy.
-- **HP_Vocal_AGG_4BAND_44100.pth** - This model also emphasizes vocal extraction and is a bit more aggressive than the previous model.
-
-## Choose Conversion Method
-
-### Single Model
-
-Run your tracks through a single model only. This is the default conversion method.
-
-- **Choose Main Model** - Here is where you choose the main model to perform a deep vocal removal.
- - The *'Model Test Mode'* option makes it easier for users to test different models on given tracks.
-
-### Ensemble Mode
-
-Ensemble Mode will run your track(s) through multiple models and combine the resulting outputs for a more robust separation. Higher level ensembles will have stronger separations, as they use more models.
-
-- **Choose Ensemble** - Here, choose the ensemble you wish to run your track through.
- - **There are 4 ensembles you can choose from:**
- - **HP1 Models** - Level 1 Ensemble
- - **HP2 Models** - Level 2 Ensemble
- - **All HP Models** - Level 3 Ensemble
- - **Vocal Models** - Level 1 Vocal Ensemble
- - A directory is auto-generated with the name of the ensemble. This directory will contain all of the individual outputs generated by the ensemble and auto-delete once the conversions are complete if the *'Save All Outputs'* option is unchecked.
- - When checked, the *'Save All Outputs'* option saves all of the outputs generated by each model in the ensemble.
-
-- **List of models included in each ensemble:**
- - **HP1 Models**
- - HP_4BAND_44100_A
- - HP_4BAND_44100_B
- - **HP2 Models**
- - HP2_4BAND_44100_1
- - HP2_4BAND_44100_2
- - HP2_3BAND_44100_MSB2
- - **All HP Models**
- - HP_4BAND_44100_A
- - HP_4BAND_44100_B
- - HP2_4BAND_44100_1
- - HP2_4BAND_44100_2
- - HP2_3BAND_44100_MSB2
- - **Vocal Models**
- - HP_Vocal_4BAND_44100
- - HP_Vocal_AGG_4BAND_44100
-
-- **Please Note:** Ensemble mode is very resource heavy!
-
-## Other GUI Notes
-
-- The application will automatically remember your *'save to'* path upon closing and reopening until it's changed.
- - **Note:** The last directory accessed within the application will also be remembered.
-- Multiple conversions are supported.
-- The ability to drag & drop audio files to convert has also been added.
-- Conversion times will significantly depend on your hardware.
- - **Note:** This application will *not* be friendly to older or budget hardware. Please proceed with caution! Please pay attention to your PC and make sure it doesn't overheat. ***We are not responsible for any hardware damage.***
-
-## Troubleshooting
-
-### Common Issues
-
-- This application is not compatible with 32-bit versions of Python. Please make sure your version of Python is 64-bit.
-- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
-
-### Issue Reporting
-
-Please be as detailed as possible when posting a new issue. Make sure to provide any error outputs and/or screenshots/gif's to give us a clearer understanding of the issue you are experiencing.
-
-If the *'VocalRemover.py'* file won't open *under any circumstances* and all other resources have been exhausted, please do the following -
-
-1. Open the cmd prompt from the ultimatevocalremovergui-master directory
-2. Run the following command -
-```
-python VocalRemover.py
-```
-3. Copy and paste the error output shown in the cmd prompt to the issues center on the GitHub repository.
+ - Open the file labeled *'UVR.py'*.
+ - It's recommended that you create a shortcut for the file labeled *'UVR.py'* to your desktop for easy access.
+ - **Note:** If you are unable to open the *'UVR.py'* file, please go to the **troubleshooting** section below.
+ - **Note:** All output audio files will be in the *'.wav'* format.
## License
The **Ultimate Vocal Remover GUI** code is [MIT-licensed](LICENSE).
-- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers Anjok07, aufr33, & tsurumeso.
+- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers.
+
+## Credits
+
+- [DilanBoskan](https://github.com/DilanBoskan) - Your contributions at the start of this project were essential to the success of UVR. Thank you!
+- [Bas Curtiz](https://www.youtube.com/user/bascurtiz) - Designed the official UVR logo, icon, banner, splash screen, and interface.
+- [tsurumeso](https://github.com/tsurumeso) - Developed the original VR Architecture code.
+- [Kuielab & Woosung Choi](https://github.com/kuielab) - Developed the original MDX-Net AI code.
+- [Adefossez & Demucs](https://github.com/facebookresearch/demucs) - Developed the original MDX-Net AI code.
+- [Hv](https://github.com/NaJeongMo/Colab-for-MDX_B) - Helped implement chunks into the MDX-Net AI code. Thank you!
## Contributing
-- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and/or modify as they wish.
-- Please note that we do not maintain or directly support any of tsurumesos AI application code. We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
+- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and modify as they wish.
+- We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
## References
- [1] Takahashi et al., "Multi-scale Multi-band DenseNets for Audio Source Separation", https://arxiv.org/pdf/1706.09588.pdf
diff --git a/UVR.py b/UVR.py
new file mode 100644
index 0000000..6227261
--- /dev/null
+++ b/UVR.py
@@ -0,0 +1,1729 @@
+# GUI modules
+import os
+try:
+ with open(os.path.join(os.getcwd(), 'tmp', 'splash.txt'), 'w') as f:
+ f.write('1')
+except:
+ pass
+import pyperclip
+from gc import freeze
+import tkinter as tk
+from tkinter import *
+from tkinter.tix import *
+import webbrowser
+from tracemalloc import stop
+import lib_v5.sv_ttk
+import tkinter.ttk as ttk
+import tkinter.messagebox
+import tkinter.filedialog
+import tkinter.font
+from tkinterdnd2 import TkinterDnD, DND_FILES # Enable Drag & Drop
+import pyglet,tkinter
+from datetime import datetime
+# Images
+from PIL import Image
+from PIL import ImageTk
+import pickle # Save Data
+# Other Modules
+
+# Pathfinding
+import pathlib
+import sys
+import subprocess
+from collections import defaultdict
+# Used for live text displaying
+import queue
+import threading # Run the algorithm inside a thread
+from subprocess import call
+from pathlib import Path
+import ctypes as ct
+import subprocess # Run python file
+import inference_MDX
+import inference_v5
+import inference_v5_ensemble
+
+try:
+ with open(os.path.join(os.getcwd(), 'tmp', 'splash.txt'), 'w') as f:
+ f.write('1')
+except:
+ pass
+
+# Change the current working directory to the directory
+# this file sits in
+if getattr(sys, 'frozen', False):
+ # If the application is run as a bundle, the PyInstaller bootloader
+ # extends the sys module by a flag frozen=True and sets the app
+ # path into variable _MEIPASS'.
+ base_path = sys._MEIPASS
+else:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+
+os.chdir(base_path) # Change the current working directory to the base path
+
+#Images
+instrumentalModels_dir = os.path.join(base_path, 'models')
+banner_path = os.path.join(base_path, 'img', 'UVR-banner.png')
+efile_path = os.path.join(base_path, 'img', 'file.png')
+stop_path = os.path.join(base_path, 'img', 'stop.png')
+help_path = os.path.join(base_path, 'img', 'help.png')
+gen_opt_path = os.path.join(base_path, 'img', 'gen_opt.png')
+mdx_opt_path = os.path.join(base_path, 'img', 'mdx_opt.png')
+vr_opt_path = os.path.join(base_path, 'img', 'vr_opt.png')
+ense_opt_path = os.path.join(base_path, 'img', 'ense_opt.png')
+user_ens_opt_path = os.path.join(base_path, 'img', 'user_ens_opt.png')
+credits_path = os.path.join(base_path, 'img', 'credits.png')
+
+DEFAULT_DATA = {
+ 'exportPath': '',
+ 'inputPaths': [],
+ 'saveFormat': 'Wav',
+ 'gpu': False,
+ 'postprocess': False,
+ 'tta': False,
+ 'save': True,
+ 'output_image': False,
+ 'window_size': '512',
+ 'agg': 10,
+ 'modelFolder': False,
+ 'modelInstrumentalLabel': '',
+ 'aiModel': 'MDX-Net',
+ 'algo': 'Instrumentals (Min Spec)',
+ 'ensChoose': 'MDX-Net/VR Ensemble',
+ 'useModel': 'instrumental',
+ 'lastDir': None,
+ 'break': False,
+ #MDX-Net
+ 'demucsmodel': True,
+ 'non_red': False,
+ 'noise_reduc': True,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'chunks': 'Auto',
+ 'noisereduc_s': '3',
+ 'mixing': 'default',
+ 'mdxnetModel': 'UVR-MDX-NET 1',
+}
+
+def open_image(path: str, size: tuple = None, keep_aspect: bool = True, rotate: int = 0) -> ImageTk.PhotoImage:
+ """
+ Open the image on the path and apply given settings\n
+ Paramaters:
+ path(str):
+ Absolute path of the image
+ size(tuple):
+ first value - width
+ second value - height
+ keep_aspect(bool):
+ keep aspect ratio of image and resize
+ to maximum possible width and height
+ (maxima are given by size)
+ rotate(int):
+ clockwise rotation of image
+ Returns(ImageTk.PhotoImage):
+ Image of path
+ """
+ img = Image.open(path).convert(mode='RGBA')
+ ratio = img.height/img.width
+ img = img.rotate(angle=-rotate)
+ if size is not None:
+ size = (int(size[0]), int(size[1]))
+ if keep_aspect:
+ img = img.resize((size[0], int(size[0] * ratio)), Image.ANTIALIAS)
+ else:
+ img = img.resize(size, Image.ANTIALIAS)
+ return ImageTk.PhotoImage(img)
+
+def save_data(data):
+ """
+ Saves given data as a .pkl (pickle) file
+
+ Paramters:
+ data(dict):
+ Dictionary containing all the necessary data to save
+ """
+ # Open data file, create it if it does not exist
+ with open('data.pkl', 'wb') as data_file:
+ pickle.dump(data, data_file)
+
+def load_data() -> dict:
+ """
+ Loads saved pkl file and returns the stored data
+
+ Returns(dict):
+ Dictionary containing all the saved data
+ """
+ try:
+ with open('data.pkl', 'rb') as data_file: # Open data file
+ data = pickle.load(data_file)
+
+ return data
+ except (ValueError, FileNotFoundError):
+ # Data File is corrupted or not found so recreate it
+ save_data(data=DEFAULT_DATA)
+
+ return load_data()
+
+def drop(event, accept_mode: str = 'files'):
+ """
+ Drag & Drop verification process
+ """
+ global dnd
+ global dnddir
+
+ path = event.data
+
+ if accept_mode == 'folder':
+ path = path.replace('{', '').replace('}', '')
+ if not os.path.isdir(path):
+ tk.messagebox.showerror(title='Invalid Folder',
+ message='Your given export path is not a valid folder!')
+ return
+ # Set Variables
+ root.exportPath_var.set(path)
+ elif accept_mode == 'files':
+ # Clean path text and set path to the list of paths
+ path = path.replace('{', '')
+ path = path.split('} ')
+ path[-1] = path[-1].replace('}', '')
+ # Set Variables
+ dnd = 'yes'
+ root.inputPaths = path
+ root.update_inputPaths()
+ dnddir = os.path.dirname(path[0])
+ print('dnddir ', str(dnddir))
+ else:
+ # Invalid accept mode
+ return
+
+class ThreadSafeConsole(tk.Text):
+ """
+ Text Widget which is thread safe for tkinter
+ """
+ def __init__(self, master, **options):
+ tk.Text.__init__(self, master, **options)
+ self.queue = queue.Queue()
+ self.update_me()
+
+ def write(self, line):
+ self.queue.put(line)
+
+ def clear(self):
+ self.queue.put(None)
+
+ def update_me(self):
+ self.configure(state=tk.NORMAL)
+ try:
+ while 1:
+ line = self.queue.get_nowait()
+ if line is None:
+ self.delete(1.0, tk.END)
+ else:
+ self.insert(tk.END, str(line))
+ self.see(tk.END)
+ self.update_idletasks()
+ except queue.Empty:
+ pass
+ self.configure(state=tk.DISABLED)
+ self.after(100, self.update_me)
+
+class MainWindow(TkinterDnD.Tk):
+ # --Constants--
+ # Layout
+ IMAGE_HEIGHT = 140
+ FILEPATHS_HEIGHT = 85
+ OPTIONS_HEIGHT = 275
+ CONVERSIONBUTTON_HEIGHT = 35
+ COMMAND_HEIGHT = 200
+ PROGRESS_HEIGHT = 30
+ PADDING = 10
+
+ COL1_ROWS = 11
+ COL2_ROWS = 11
+
+ def __init__(self):
+ # Run the __init__ method on the tk.Tk class
+ super().__init__()
+
+ # Calculate window height
+ height = self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT
+ height += self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PROGRESS_HEIGHT
+ height += self.PADDING * 5 # Padding
+
+ # --Window Settings--
+ self.title('Ultimate Vocal Remover')
+ # Set Geometry and Center Window
+ self.geometry('{width}x{height}+{xpad}+{ypad}'.format(
+ width=620,
+ height=height,
+ xpad=int(self.winfo_screenwidth()/2 - 635/2),
+ ypad=int(self.winfo_screenheight()/2 - height/2 - 30)))
+ self.configure(bg='#0e0e0f') # Set background color to #0c0c0d
+ self.protocol("WM_DELETE_WINDOW", self.save_values)
+ self.resizable(False, False)
+ self.update()
+
+ # --Variables--
+ self.logo_img = open_image(path=banner_path,
+ size=(self.winfo_width(), 9999))
+ self.efile_img = open_image(path=efile_path,
+ size=(20, 20))
+ self.stop_img = open_image(path=stop_path,
+ size=(20, 20))
+ self.help_img = open_image(path=help_path,
+ size=(20, 20))
+ self.gen_opt_img = open_image(path=gen_opt_path,
+ size=(1016, 826))
+ self.mdx_opt_img = open_image(path=mdx_opt_path,
+ size=(1016, 826))
+ self.vr_opt_img = open_image(path=vr_opt_path,
+ size=(1016, 826))
+ self.ense_opt_img = open_image(path=ense_opt_path,
+ size=(1016, 826))
+ self.user_ens_opt_img = open_image(path=user_ens_opt_path,
+ size=(1016, 826))
+ self.credits_img = open_image(path=credits_path,
+ size=(100, 100))
+
+ self.instrumentalLabel_to_path = defaultdict(lambda: '')
+ self.lastInstrumentalModels = []
+
+ # -Tkinter Value Holders-
+ data = load_data()
+ # Paths
+ self.inputPaths = data['inputPaths']
+ self.inputPathop_var = tk.StringVar(value=data['inputPaths'])
+ self.exportPath_var = tk.StringVar(value=data['exportPath'])
+ self.saveFormat_var = tk.StringVar(value=data['saveFormat'])
+
+ # Processing Options
+ self.gpuConversion_var = tk.BooleanVar(value=data['gpu'])
+ self.postprocessing_var = tk.BooleanVar(value=data['postprocess'])
+ self.tta_var = tk.BooleanVar(value=data['tta'])
+ self.save_var = tk.BooleanVar(value=data['save'])
+ self.outputImage_var = tk.BooleanVar(value=data['output_image'])
+ # MDX-NET Specific Processing Options
+ self.demucsmodel_var = tk.BooleanVar(value=data['demucsmodel'])
+ self.non_red_var = tk.BooleanVar(value=data['non_red'])
+ self.noisereduc_var = tk.BooleanVar(value=data['noise_reduc'])
+ self.chunks_var = tk.StringVar(value=data['chunks'])
+ self.noisereduc_s_var = tk.StringVar(value=data['noisereduc_s'])
+ self.mixing_var = tk.StringVar(value=data['mixing']) #dropdown
+ # Models
+ self.instrumentalModel_var = tk.StringVar(value=data['modelInstrumentalLabel'])
+ # Model Test Mode
+ self.modelFolder_var = tk.BooleanVar(value=data['modelFolder'])
+ # Constants
+ self.winSize_var = tk.StringVar(value=data['window_size'])
+ self.agg_var = tk.StringVar(value=data['agg'])
+ # Instrumental or Vocal Only
+ self.voc_only_var = tk.BooleanVar(value=data['voc_only'])
+ self.inst_only_var = tk.BooleanVar(value=data['inst_only'])
+ # Choose Conversion Method
+ self.aiModel_var = tk.StringVar(value=data['aiModel'])
+ self.last_aiModel = self.aiModel_var.get()
+ # Choose Conversion Method
+ self.algo_var = tk.StringVar(value=data['algo'])
+ self.last_algo = self.aiModel_var.get()
+ # Choose Ensemble
+ self.ensChoose_var = tk.StringVar(value=data['ensChoose'])
+ self.last_ensChoose = self.ensChoose_var.get()
+ # Choose MDX-NET Model
+ self.mdxnetModel_var = tk.StringVar(value=data['mdxnetModel'])
+ self.last_mdxnetModel = self.mdxnetModel_var.get()
+ # Other
+ self.inputPathsEntry_var = tk.StringVar(value='')
+ self.lastDir = data['lastDir'] # nopep8
+ self.progress_var = tk.IntVar(value=0)
+ # Font
+ pyglet.font.add_file('lib_v5/fonts/centurygothic/GOTHIC.TTF')
+ self.font = tk.font.Font(family='Century Gothic', size=10)
+ self.fontRadio = tk.font.Font(family='Century Gothic', size=8)
+ # --Widgets--
+ self.create_widgets()
+ self.configure_widgets()
+ self.bind_widgets()
+ self.place_widgets()
+
+ self.update_available_models()
+ self.update_states()
+ self.update_loop()
+
+
+
+
+ # -Widget Methods-
+ def create_widgets(self):
+ """Create window widgets"""
+ self.title_Label = tk.Label(master=self, bg='#0e0e0f',
+ image=self.logo_img, compound=tk.TOP)
+ self.filePaths_Frame = ttk.Frame(master=self)
+ self.fill_filePaths_Frame()
+
+ self.options_Frame = ttk.Frame(master=self)
+ self.fill_options_Frame()
+
+ self.conversion_Button = ttk.Button(master=self,
+ text='Start Processing',
+ command=self.start_conversion)
+ self.stop_Button = ttk.Button(master=self,
+ image=self.stop_img,
+ command=self.restart)
+ self.help_Button = ttk.Button(master=self,
+ image=self.help_img,
+ command=self.help)
+
+ #ttk.Button(win, text= "Open", command= open_popup).pack()
+
+ self.efile_e_Button = ttk.Button(master=self,
+ image=self.efile_img,
+ command=self.open_exportPath_filedialog)
+
+ self.efile_i_Button = ttk.Button(master=self,
+ image=self.efile_img,
+ command=self.open_inputPath_filedialog)
+
+ self.progressbar = ttk.Progressbar(master=self, variable=self.progress_var)
+
+ self.command_Text = ThreadSafeConsole(master=self,
+ background='#0e0e0f',fg='#898b8e', font=('Century Gothic', 11),
+ borderwidth=0,)
+
+ self.command_Text.write(f'Ultimate Vocal Remover [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+
+
+ def configure_widgets(self):
+ """Change widget styling and appearance"""
+
+ #ttk.Style().configure('TCheckbutton', background='#0e0e0f',
+ # font=self.font, foreground='#d4d4d4')
+ #ttk.Style().configure('TRadiobutton', background='#0e0e0f',
+ # font=("Century Gothic", "8", "bold"), foreground='#d4d4d4')
+ #ttk.Style().configure('T', font=self.font, foreground='#d4d4d4')
+
+ #s = ttk.Style()
+ #s.configure('TButton', background='blue', foreground='black', font=('Century Gothic', '9', 'bold'), relief="groove")
+
+
+ def bind_widgets(self):
+ """Bind widgets to the drag & drop mechanic"""
+ self.filePaths_musicFile_Button.drop_target_register(DND_FILES)
+ self.filePaths_musicFile_Entry.drop_target_register(DND_FILES)
+ self.filePaths_saveTo_Button.drop_target_register(DND_FILES)
+ self.filePaths_saveTo_Entry.drop_target_register(DND_FILES)
+ self.filePaths_musicFile_Button.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='files'))
+ self.filePaths_musicFile_Entry.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='files'))
+ self.filePaths_saveTo_Button.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='folder'))
+ self.filePaths_saveTo_Entry.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='folder'))
+
+ def place_widgets(self):
+ """Place main widgets"""
+ self.title_Label.place(x=-2, y=-2)
+ self.filePaths_Frame.place(x=10, y=155, width=-20, height=self.FILEPATHS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.options_Frame.place(x=10, y=250, width=-50, height=self.OPTIONS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.conversion_Button.place(x=50, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=-60 - 40, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.efile_e_Button.place(x=-45, y=200, width=35, height=30,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.efile_i_Button.place(x=-45, y=160, width=35, height=30,
+ relx=1, rely=0, relwidth=0, relheight=0)
+
+ self.stop_Button.place(x=-10 - 35, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.help_Button.place(x=-10 - 600, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.command_Text.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.PADDING*3, width=-30, height=self.COMMAND_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.progressbar.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PADDING*4, width=-50, height=self.PROGRESS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+
+ def fill_filePaths_Frame(self):
+ """Fill Frame with neccessary widgets"""
+ # -Create Widgets-
+ # Save To Option
+ # Select Music Files Option
+
+ # Save To Option
+ self.filePaths_saveTo_Button = ttk.Button(master=self.filePaths_Frame,
+ text='Select output',
+ command=self.open_export_filedialog)
+ self.filePaths_saveTo_Entry = ttk.Entry(master=self.filePaths_Frame,
+
+ textvariable=self.exportPath_var,
+ state=tk.DISABLED
+ )
+ # Select Music Files Option
+ self.filePaths_musicFile_Button = ttk.Button(master=self.filePaths_Frame,
+ text='Select input',
+ command=self.open_file_filedialog)
+ self.filePaths_musicFile_Entry = ttk.Entry(master=self.filePaths_Frame,
+ textvariable=self.inputPathsEntry_var,
+ state=tk.DISABLED
+ )
+
+
+ # -Place Widgets-
+
+ # Select Music Files Option
+ self.filePaths_musicFile_Button.place(x=0, y=5, width=0, height=-10,
+ relx=0, rely=0, relwidth=0.3, relheight=0.5)
+ self.filePaths_musicFile_Entry.place(x=10, y=2.5, width=-50, height=-5,
+ relx=0.3, rely=0, relwidth=0.7, relheight=0.5)
+
+ # Save To Option
+ self.filePaths_saveTo_Button.place(x=0, y=5, width=0, height=-10,
+ relx=0, rely=0.5, relwidth=0.3, relheight=0.5)
+ self.filePaths_saveTo_Entry.place(x=10, y=2.5, width=-50, height=-5,
+ relx=0.3, rely=0.5, relwidth=0.7, relheight=0.5)
+
+
+ def fill_options_Frame(self):
+ """Fill Frame with neccessary widgets"""
+ # -Create Widgets-
+
+
+ # Save as wav
+ self.options_wav_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='WAV',
+ variable=self.saveFormat_var,
+ value='Wav'
+ )
+
+ # Save as flac
+ self.options_flac_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='FLAC',
+ variable=self.saveFormat_var,
+ value='Flac'
+ )
+
+ # Save as mp3
+ self.options_mpThree_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='MP3',
+ variable=self.saveFormat_var,
+ value='Mp3',
+ )
+
+ # -Column 1-
+
+ # Choose Conversion Method
+ self.options_aiModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose Process Method', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_aiModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.aiModel_var,
+ None, 'VR Architecture', 'MDX-Net', 'Ensemble Mode')
+ # Choose Instrumental Model
+ self.options_instrumentalModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose Main Model',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_instrumentalModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.instrumentalModel_var)
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose MDX-Net Model', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+
+ self.options_mdxnetModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.mdxnetModel_var,
+ None, 'UVR-MDX-NET 1', 'UVR-MDX-NET 2', 'UVR-MDX-NET 3', 'UVR-MDX-NET Karaoke')
+ # Ensemble Mode
+ self.options_ensChoose_Label = tk.Label(master=self.options_Frame,
+ text='Choose Ensemble', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_ensChoose_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.ensChoose_var,
+ None, 'MDX-Net/VR Ensemble', 'HP Models', 'Vocal Models', 'HP2 Models', 'All HP/HP2 Models', 'User Ensemble')
+
+ # Choose Agorithim
+ self.options_algo_Label = tk.Label(master=self.options_Frame,
+ text='Choose Algorithm', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_algo_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.algo_var,
+ None, 'Vocals (Max Spec)', 'Instrumentals (Min Spec)')#, 'Invert (Normal)', 'Invert (Spectral)')
+
+
+ # -Column 2-
+
+ # WINDOW SIZE
+ self.options_winSize_Label = tk.Label(master=self.options_Frame,
+ text='Window Size', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_winSize_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.winSize_var,
+ None, '320', '512','1024')
+ # MDX-chunks
+ self.options_chunks_Label = tk.Label(master=self.options_Frame,
+ text='Chunks',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_chunks_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.chunks_var,
+ None, 'Auto', '1', '5', '10', '15', '20',
+ '25', '30', '35', '40', '45', '50',
+ '55', '60', '65', '70', '75', '80',
+ '85', '90', '95', 'Full')
+
+ #Checkboxes
+ # GPU Selection
+ self.options_gpu_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='GPU Conversion',
+ variable=self.gpuConversion_var,
+ )
+
+ # Vocal Only
+ self.options_voc_only_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Vocals Only',
+ variable=self.voc_only_var,
+ )
+ # Instrumental Only
+ self.options_inst_only_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Instrumental Only',
+ variable=self.inst_only_var,
+ )
+ # TTA
+ self.options_tta_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='TTA',
+ variable=self.tta_var,
+ )
+
+ # MDX-Auto-Chunk
+ self.options_non_red_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Noisey Vocal',
+ variable=self.non_red_var,
+ )
+
+ # Postprocessing
+ self.options_post_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Post-Process',
+ variable=self.postprocessing_var,
+ )
+
+ # -Column 3-
+
+ # AGG
+ self.options_agg_Label = tk.Label(master=self.options_Frame,
+ text='Aggression Setting',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_agg_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.agg_var,
+ None, '1', '2', '3', '4', '5',
+ '6', '7', '8', '9', '10', '11',
+ '12', '13', '14', '15', '16', '17',
+ '18', '19', '20')
+
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label = tk.Label(master=self.options_Frame,
+ text='Noise Reduction',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_noisereduc_s_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.noisereduc_s_var,
+ None, 'None', '0', '1', '2', '3', '4', '5',
+ '6', '7', '8', '9', '10', '11',
+ '12', '13', '14', '15', '16', '17',
+ '18', '19', '20')
+
+
+ # Save Image
+ self.options_image_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Output Image',
+ variable=self.outputImage_var,
+ )
+
+ # MDX-Enable Demucs Model
+ self.options_demucsmodel_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Demucs Model',
+ variable=self.demucsmodel_var,
+ )
+
+ # MDX-Noise Reduction
+ self.options_noisereduc_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Noise Reduction',
+ variable=self.noisereduc_var,
+ )
+
+ # Ensemble Save Ensemble Outputs
+ self.options_save_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save All Outputs',
+ variable=self.save_var,
+ )
+
+ # Model Test Mode
+ self.options_modelFolder_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Model Test Mode',
+ variable=self.modelFolder_var,
+ )
+
+ # -Place Widgets-
+
+ # -Column 0-
+
+ # Save as
+ self.options_wav_Radiobutton.place(x=400, y=-5, width=0, height=6,
+ relx=0, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_flac_Radiobutton.place(x=271, y=-5, width=0, height=6,
+ relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_mpThree_Radiobutton.place(x=143, y=-5, width=0, height=6,
+ relx=2/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # -Column 1-
+
+ # Choose Conversion Method
+ self.options_aiModel_Label.place(x=0, y=0, width=0, height=-10,
+ relx=0, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_aiModel_Optionmenu.place(x=0, y=-2, width=0, height=7,
+ relx=0, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Main Model
+ self.options_instrumentalModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_instrumentalModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_mdxnetModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+
+ # Choose Algorithm
+ self.options_algo_Label.place(x=20, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_algo_Optionmenu.place(x=12, y=-2, width=0, height=7,
+ relx=1/3, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+
+ # -Column 2-
+
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---MDX-Net Specific---
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Checkboxes
+
+ #GPU Conversion
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # TTA
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-Keep Non_Reduced Vocal
+ self.options_non_red_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # -Column 3-
+
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Checkboxes
+ #---MDX-Net Specific---
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ #---VR Architecture Specific---
+ #Post-Process
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---Ensemble Specific---
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---MDX-Net & VR Architecture Specific---
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # Change States
+ self.aiModel_var.trace_add('write',
+ lambda *args: self.deselect_models())
+ self.ensChoose_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ self.inst_only_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ self.voc_only_var.trace_add('write',
+ lambda *args: self.update_states())
+ self.noisereduc_s_var.trace_add('write',
+ lambda *args: self.update_states())
+ self.non_red_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ # Opening filedialogs
+ def open_file_filedialog(self):
+ """Make user select music files"""
+ global dnd
+ global nondnd
+
+ if self.lastDir is not None:
+ if not os.path.isdir(self.lastDir):
+ self.lastDir = None
+
+ paths = tk.filedialog.askopenfilenames(
+ parent=self,
+ title=f'Select Music Files',
+ initialfile='',
+ initialdir=self.lastDir,
+ )
+ if paths: # Path selected
+ self.inputPaths = paths
+ dnd = 'no'
+ self.update_inputPaths()
+ nondnd = os.path.dirname(paths[0])
+ print('last dir', self.lastDir)
+
+ def open_export_filedialog(self):
+ """Make user select a folder to export the converted files in"""
+ path = tk.filedialog.askdirectory(
+ parent=self,
+ title=f'Select Folder',)
+ if path: # Path selected
+ self.exportPath_var.set(path)
+
+ def open_exportPath_filedialog(self):
+ filename = self.exportPath_var.get()
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def open_inputPath_filedialog(self):
+ """Open Input Directory"""
+
+ try:
+ if dnd == 'yes':
+ self.lastDir = str(dnddir)
+ filename = str(self.lastDir)
+ if sys.platform == "win32":
+ os.startfile(filename)
+ if dnd == 'no':
+ self.lastDir = str(nondnd)
+ filename = str(self.lastDir)
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ except:
+ filename = str(self.lastDir)
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+
+ def start_conversion(self):
+ """
+ Start the conversion for all the given mp3 and wav files
+ """
+
+ # -Get all variables-
+ export_path = self.exportPath_var.get()
+ input_paths = self.inputPaths
+ instrumentalModel_path = self.instrumentalLabel_to_path[self.instrumentalModel_var.get()] # nopep8
+ # mdxnetModel_path = self.mdxnetLabel_to_path[self.mdxnetModel_var.get()]
+ # Get constants
+ instrumental = self.instrumentalModel_var.get()
+ try:
+ if [bool(instrumental)].count(True) == 2: #CHECKTHIS
+ window_size = DEFAULT_DATA['window_size']
+ agg = DEFAULT_DATA['agg']
+ chunks = DEFAULT_DATA['chunks']
+ noisereduc_s = DEFAULT_DATA['noisereduc_s']
+ mixing = DEFAULT_DATA['mixing']
+ else:
+ window_size = int(self.winSize_var.get())
+ agg = int(self.agg_var.get())
+ chunks = str(self.chunks_var.get())
+ noisereduc_s = str(self.noisereduc_s_var.get())
+ mixing = str(self.mixing_var.get())
+ ensChoose = str(self.ensChoose_var.get())
+ mdxnetModel = str(self.mdxnetModel_var.get())
+
+ except SyntaxError: # Non integer was put in entry box
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Music File',
+ message='You have selected an invalid music file!\nPlease make sure that your files still exist and ends with either ".mp3", ".mp4", ".m4a", ".flac", ".wav"')
+ return
+
+ # -Check for invalid inputs-
+
+ for path in input_paths:
+ if not os.path.isfile(path):
+ tk.messagebox.showwarning(master=self,
+ title='Drag and Drop Feature Failed or Invalid Input',
+ message='The input is invalid, or the drag and drop feature failed to select your files properly.\n\nPlease try the following:\n\n1. Select your inputs using the \"Select Input\" button\n2. Verify the input is valid.\n3. Then try again.')
+ return
+
+
+ if self.aiModel_var.get() == 'VR Architecture':
+ if not os.path.isfile(instrumentalModel_path):
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Main Model File',
+ message='You have selected an invalid main model file!\nPlease make sure that your model file still exists!')
+ return
+
+ if not os.path.isdir(export_path):
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Export Directory',
+ message='You have selected an invalid export directory!\nPlease make sure that your directory still exists!')
+ return
+
+ if self.aiModel_var.get() == 'VR Architecture':
+ inference = inference_v5
+ elif self.aiModel_var.get() == 'Ensemble Mode':
+ inference = inference_v5_ensemble
+ elif self.aiModel_var.get() == 'MDX-Net':
+ inference = inference_MDX
+ else:
+ raise TypeError('This error should not occur.')
+
+ # -Run the algorithm-
+ threading.Thread(target=inference.main,
+ kwargs={
+ # Paths
+ 'input_paths': input_paths,
+ 'export_path': export_path,
+ 'saveFormat': self.saveFormat_var.get(),
+ # Processing Options
+ 'gpu': 0 if self.gpuConversion_var.get() else -1,
+ 'postprocess': self.postprocessing_var.get(),
+ 'tta': self.tta_var.get(),
+ 'save': self.save_var.get(),
+ 'output_image': self.outputImage_var.get(),
+ 'algo': self.algo_var.get(),
+ # Models
+ 'instrumentalModel': instrumentalModel_path,
+ 'vocalModel': '', # Always not needed
+ 'useModel': 'instrumental', # Always instrumental
+ # Model Folder
+ 'modelFolder': self.modelFolder_var.get(),
+ # Constants
+ 'window_size': window_size,
+ 'agg': agg,
+ 'break': False,
+ 'ensChoose': ensChoose,
+ 'mdxnetModel': mdxnetModel,
+ # Other Variables (Tkinter)
+ 'window': self,
+ 'text_widget': self.command_Text,
+ 'button_widget': self.conversion_Button,
+ 'inst_menu': self.options_instrumentalModel_Optionmenu,
+ 'progress_var': self.progress_var,
+ # MDX-Net Specific
+ 'demucsmodel': self.demucsmodel_var.get(),
+ 'non_red': self.non_red_var.get(),
+ 'noise_reduc': self.noisereduc_var.get(),
+ 'voc_only': self.voc_only_var.get(),
+ 'inst_only': self.inst_only_var.get(),
+ 'chunks': chunks,
+ 'noisereduc_s': noisereduc_s,
+ 'mixing': mixing,
+ },
+ daemon=True
+ ).start()
+
+ # Models
+ def update_inputPaths(self):
+ """Update the music file entry"""
+ if self.inputPaths:
+ # Non-empty Selection
+ text = '; '.join(self.inputPaths)
+ else:
+ # Empty Selection
+ text = ''
+ self.inputPathsEntry_var.set(text)
+
+
+
+ def update_loop(self):
+ """Update the dropdown menu"""
+ self.update_available_models()
+
+ self.after(3000, self.update_loop)
+
+ def update_available_models(self):
+ """
+ Loop through every model (.pth) in the models directory
+ and add to the select your model list
+ """
+ temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, 'Main_Models') # nopep8
+
+ # Main models
+ new_InstrumentalModels = os.listdir(temp_instrumentalModels_dir)
+ if new_InstrumentalModels != self.lastInstrumentalModels:
+ self.instrumentalLabel_to_path.clear()
+ self.options_instrumentalModel_Optionmenu['menu'].delete(0, 'end')
+ for file_name in new_InstrumentalModels:
+ if file_name.endswith('.pth'):
+ # Add Radiobutton to the Options Menu
+ self.options_instrumentalModel_Optionmenu['menu'].add_radiobutton(label=file_name,
+ command=tk._setit(self.instrumentalModel_var, file_name))
+ # Link the files name to its absolute path
+ self.instrumentalLabel_to_path[file_name] = os.path.join(temp_instrumentalModels_dir, file_name) # nopep8
+ self.lastInstrumentalModels = new_InstrumentalModels
+
+ def update_states(self):
+ """
+ Vary the states for all widgets based
+ on certain selections
+ """
+
+ if self.aiModel_var.get() == 'MDX-Net':
+ # Place Widgets
+
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_mdxnetModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.configure(state=tk.NORMAL)
+ self.options_demucsmodel_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # MDX-Keep Non_Reduced Vocal
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+ self.options_non_red_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # Forget widgets
+ self.options_ensChoose_Label.place_forget()
+ self.options_ensChoose_Optionmenu.place_forget()
+ self.options_instrumentalModel_Label.place_forget()
+ self.options_instrumentalModel_Optionmenu.place_forget()
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_tta_Checkbutton.configure(state=tk.DISABLED)
+ self.options_tta_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_winSize_Label.place_forget()
+ self.options_winSize_Optionmenu.place_forget()
+ self.options_agg_Label.place_forget()
+ self.options_agg_Optionmenu.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+
+
+ elif self.aiModel_var.get() == 'VR Architecture':
+ #Keep for Ensemble & VR Architecture Mode
+ # Choose Main Model
+ self.options_instrumentalModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_instrumentalModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Post-Process
+ self.options_post_Checkbutton.configure(state=tk.NORMAL)
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.configure(state=tk.NORMAL)
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Forget Widgets
+ self.options_ensChoose_Label.place_forget()
+ self.options_ensChoose_Optionmenu.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+
+ elif self.aiModel_var.get() == 'Ensemble Mode':
+ if self.ensChoose_var.get() == 'User Ensemble':
+ # Choose Algorithm
+ self.options_algo_Label.place(x=20, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_algo_Optionmenu.place(x=12, y=-2, width=0, height=7,
+ relx=1/3, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Forget Widgets
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_tta_Checkbutton.configure(state=tk.DISABLED)
+ self.options_tta_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_modelFolder_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_gpu_Checkbutton.configure(state=tk.DISABLED)
+ self.options_gpu_Checkbutton.place_forget()
+ self.options_voc_only_Checkbutton.configure(state=tk.DISABLED)
+ self.options_voc_only_Checkbutton.place_forget()
+ self.options_inst_only_Checkbutton.configure(state=tk.DISABLED)
+ self.options_inst_only_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_winSize_Label.place_forget()
+ self.options_winSize_Optionmenu.place_forget()
+ self.options_agg_Label.place_forget()
+ self.options_agg_Optionmenu.place_forget()
+
+ elif self.ensChoose_var.get() == 'MDX-Net/VR Ensemble':
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=-7, width=0, height=-10,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-5, width=-118, height=7,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=-7, width=0, height=-10,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-5, width=-118, height=7,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=8/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=9/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.configure(state=tk.NORMAL)
+ self.options_demucsmodel_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=8/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.configure(state=tk.NORMAL)
+ self.options_save_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=9/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # Forget Widgets
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_modelFolder_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ else:
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Post-Process
+ self.options_post_Checkbutton.configure(state=tk.NORMAL)
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.configure(state=tk.NORMAL)
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.configure(state=tk.NORMAL)
+ self.options_save_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Forget Widgets
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ self.options_instrumentalModel_Label.place_forget()
+ self.options_instrumentalModel_Optionmenu.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_modelFolder_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+
+
+ if self.inst_only_var.get() == True:
+ self.options_voc_only_Checkbutton.configure(state=tk.DISABLED)
+ self.voc_only_var.set(False)
+ self.non_red_var.set(False)
+ elif self.inst_only_var.get() == False:
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+
+ if self.voc_only_var.get() == True:
+ self.options_inst_only_Checkbutton.configure(state=tk.DISABLED)
+ self.inst_only_var.set(False)
+ elif self.voc_only_var.get() == False:
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+
+ if self.noisereduc_s_var.get() == 'None':
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.non_red_var.set(False)
+ if not self.noisereduc_s_var.get() == 'None':
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+
+
+ self.update_inputPaths()
+
+ def deselect_models(self):
+ """
+ Run this method on version change
+ """
+ if self.aiModel_var.get() == self.last_aiModel:
+ return
+ else:
+ self.last_aiModel = self.aiModel_var.get()
+
+ self.instrumentalModel_var.set('')
+ self.ensChoose_var.set('MDX-Net/VR Ensemble')
+ self.mdxnetModel_var.set('UVR-MDX-NET 1')
+
+ self.winSize_var.set(DEFAULT_DATA['window_size'])
+ self.agg_var.set(DEFAULT_DATA['agg'])
+ self.modelFolder_var.set(DEFAULT_DATA['modelFolder'])
+
+
+ self.update_available_models()
+ self.update_states()
+
+ def restart(self):
+ """
+ Restart the application after asking for confirmation
+ """
+ confirm = tk.messagebox.askyesno(title='Restart Confirmation',
+ message='This will restart the application and halt any running processes. Your current settings will be saved. \n\n Are you sure you wish to continue?')
+
+ if confirm:
+ self.save_values()
+
+ subprocess.Popen(f'UVR_Launcher.exe')
+ exit()
+ else:
+ pass
+
+ def help(self):
+ """
+ Open Help Guide
+ """
+ top= Toplevel(self)
+ top.geometry("1080x920")
+ top.title("UVR Help Guide")
+
+ top.resizable(False, False) # This code helps to disable windows from resizing
+
+ window_height = 920
+ window_width = 1080
+
+ screen_width = top.winfo_screenwidth()
+ screen_height = top.winfo_screenheight()
+
+ x_cordinate = int((screen_width/2) - (window_width/2))
+ y_cordinate = int((screen_height/2) - (window_height/2))
+
+ top.geometry("{}x{}+{}+{}".format(window_width, window_height, x_cordinate, y_cordinate))
+
+ # change title bar icon
+ top.iconbitmap('img\\UVR-Icon-v2.ico')
+
+ tabControl = ttk.Notebook(top)
+
+ tab1 = ttk.Frame(tabControl)
+ tab2 = ttk.Frame(tabControl)
+ tab3 = ttk.Frame(tabControl)
+ tab4 = ttk.Frame(tabControl)
+ tab5 = ttk.Frame(tabControl)
+ tab6 = ttk.Frame(tabControl)
+ tab7 = ttk.Frame(tabControl)
+ tab8 = ttk.Frame(tabControl)
+ tab9 = ttk.Frame(tabControl)
+
+ tabControl.add(tab1, text ='General Options')
+ tabControl.add(tab2, text ='VR Architecture Options')
+ tabControl.add(tab3, text ='MDX-Net Options')
+ tabControl.add(tab4, text ='Ensemble Mode')
+ tabControl.add(tab5, text ='User Ensemble')
+ tabControl.add(tab6, text ='More Info')
+ tabControl.add(tab7, text ='Credits')
+ tabControl.add(tab8, text ='Updates')
+ tabControl.add(tab9, text ='Error Log')
+
+ tabControl.pack(expand = 1, fill ="both")
+
+ #Configure the row/col of our frame and root window to be resizable and fill all available space
+ tab6.grid_rowconfigure(0, weight=1)
+ tab6.grid_columnconfigure(0, weight=1)
+
+ tab7.grid_rowconfigure(0, weight=1)
+ tab7.grid_columnconfigure(0, weight=1)
+
+ tab8.grid_rowconfigure(0, weight=1)
+ tab8.grid_columnconfigure(0, weight=1)
+
+ tab9.grid_rowconfigure(0, weight=1)
+ tab9.grid_columnconfigure(0, weight=1)
+
+ ttk.Label(tab1, image=self.gen_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab2, image=self.vr_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab3, image=self.mdx_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab4, image=self.ense_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab5, image=self.user_ens_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ #frame0
+ frame0=Frame(tab6,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Notes",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=15)
+
+ l0=Label(frame0,text="UVR is 100% free and open-source but MIT licensed.\nAll the models provided as part of UVR were trained by its core developers.\nPlease credit the core UVR developers if you choose to use any of our models or code for projects unrelated to UVR.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=2,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Resources",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=3,column=0,padx=20,pady=15, sticky=N)
+
+ link = Label(frame0, text="Ultimate Vocal Remover (Official GitHub)",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=4,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui"))
+
+ l0=Label(frame0,text="You can find updates, report issues, and give us a shout via our official GitHub.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=5,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="SoX - Sound eXchange",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=6,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://sourceforge.net/projects/sox/files/sox/14.4.2/sox-14.4.2-win32.zip/download"))
+
+ l0=Label(frame0,text="UVR relies on SoX for Noise Reduction. It's automatically included via the UVR installer but not the developer build.\nIf you are missing SoX, please download it via the link and extract the SoX archive to the following directory - lib_v5/sox",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=7,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="FFmpeg",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=8,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://www.wikihow.com/Install-FFmpeg-on-Windows"))
+
+ l0=Label(frame0,text="UVR relies on FFmpeg for processing non-wav audio files.\nIt's automatically included via the UVR installer but not the developer build.\nIf you are missing FFmpeg, please see the installation guide via the link provided.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=9,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="X-Minus AI",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=10,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://x-minus.pro/ai"))
+
+ l0=Label(frame0,text="Many of the models provided are also on X-Minus.\nThis resource primarily benefits users without the computing resources to run the GUI or models locally.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=11,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="Official UVR Patreon",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=12,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://www.patreon.com/uvr"))
+
+ l0=Label(frame0,text="If you wish to support and donate to this project, click the link above and become a Patreon!",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=13,column=0,padx=10,pady=10)
+
+ frame0=Frame(tab7,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ #inside frame0
+
+ l0=Label(frame0,text="Core UVR Developers",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=0,column=0,padx=20,pady=10, sticky=N)
+
+ l0=Label(frame0,image=self.credits_img,font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=1,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Anjok07\nAufr33",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=2,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Special Thanks",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=4,column=0,padx=20,pady=15)
+
+ l0=Label(frame0,text="DilanBoskan",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=5,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Your contributions at the start of this project were essential to the success of UVR. Thank you!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=6,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Tsurumeso",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=7,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/tsurumeso/vocal-remover"))
+
+ l0=Label(frame0,text="Developed the original VR Architecture AI code.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=8,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Kuielab & Woosung Choi",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=9,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/kuielab"))
+
+ l0=Label(frame0,text="Developed the original MDX-Net AI code.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=10,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="Bas Curtiz",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=11,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Designed the official UVR logo, icon, banner, splash screen, and interface.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=12,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Adefossez & Demucs",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=13,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/facebookresearch/demucs"))
+
+ l0=Label(frame0,text="Core developer of Facebook's Demucs Music Source Separation.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=14,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="Audio Separation Discord Community",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=15,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Thank you for the support!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=16,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="CC Karokee & Friends Discord Community",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=17,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Thank you for the support!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=18,column=0,padx=0,pady=0)
+
+ frame0=Frame(tab8,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Update Details",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=10)
+
+ l0=Label(frame0,text="Installing Model Expansion Pack",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=2,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="1. Download the model expansion pack via the provided link below.\n2. Once the download has completed, click the \"Open Models Directory\" button below.\n3. Extract the \'Main Models\' folder within the downloaded archive to the opened \"models\" directory.\n4. Without restarting the application, you will now see the new models appear under the VR Architecture model selection list.",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=3,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Model Expansion Pack",font=("Century Gothic", "11", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=4,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui/releases/tag/v5.2.0"))
+
+ l0=Button(frame0,text='Open Models Directory',font=("Century Gothic", "11"), command=self.open_Modelfolder_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=5,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="\n\n\nBackward Compatibility",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=6,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="The v4 Models are fully compatible with this GUI. \n1. If you already have them on your system, click the \"Open Models Directory\" button below. \n2. Place the files with extension \".pth\" into the \"Main Models\" directory. \n3. Now they will automatically appear in the VR Architecture model selection list.\n Note: The v2 models are not compatible with this GUI.\n",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=7,column=0,padx=0,pady=0)
+
+ l0=Button(frame0,text='Open Models Directory',font=("Century Gothic", "11"), command=self.open_Modelfolder_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=8,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="\n\n\nInstalling Future Updates",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=9,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="New updates and patches for this application can be found on the official UVR Releases GitHub page (link below).\nAny new update instructions will likely require the use of the \"Open Application Directory\" button below.",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=10,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="UVR Releases GitHub Page",font=("Century Gothic", "11", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=11,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui/releases"))
+
+ l0=Button(frame0,text='Open Application Directory',font=("Century Gothic", "11"), command=self.open_appdir_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=12,column=0,padx=0,pady=0)
+
+ frame0=Frame(tab9,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Error Details",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=10)
+
+ l0=Label(frame0,text="This tab will show the raw details of the last error received.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=2,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="(Click the error console below to copy the error)\n",font=("Century Gothic", "10"), justify="center", fg="#F6F6F7")
+ l0.grid(row=3,column=0,padx=0,pady=0)
+
+ with open("errorlog.txt", "r") as f:
+ l0=Button(frame0,text=f.read(),font=("Century Gothic", "11"), command=self.copy_clip, justify="left", wraplength=1000, fg="#FF0000", bg="black", relief="sunken")
+ l0.grid(row=4,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="",font=("Century Gothic", "10"), justify="center", fg="#F6F6F7")
+ l0.grid(row=5,column=0,padx=0,pady=0)
+
+ def copy_clip(self):
+ copy_t = open("errorlog.txt", "r").read()
+ pyperclip.copy(copy_t)
+
+ def open_Modelfolder_filedialog(self):
+ """Let user paste a ".pth" model to use for the vocal seperation"""
+ filename = 'models'
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def open_appdir_filedialog(self):
+
+ pathname = '.'
+
+ print(pathname)
+
+ if sys.platform == "win32":
+ os.startfile(pathname)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def save_values(self):
+ """
+ Save the data of the application
+ """
+ # Get constants
+ instrumental = self.instrumentalModel_var.get()
+ if [bool(instrumental)].count(True) == 2: #Checkthis
+ window_size = DEFAULT_DATA['window_size']
+ agg = DEFAULT_DATA['agg']
+ chunks = DEFAULT_DATA['chunks']
+ noisereduc_s = DEFAULT_DATA['noisereduc_s']
+ mixing = DEFAULT_DATA['mixing']
+ else:
+ window_size = self.winSize_var.get()
+ agg = self.agg_var.get()
+ chunks = self.chunks_var.get()
+ noisereduc_s = self.noisereduc_s_var.get()
+ mixing = self.mixing_var.get()
+
+ # -Save Data-
+ save_data(data={
+ 'exportPath': self.exportPath_var.get(),
+ 'inputPaths': self.inputPaths,
+ 'saveFormat': self.saveFormat_var.get(),
+ 'gpu': self.gpuConversion_var.get(),
+ 'postprocess': self.postprocessing_var.get(),
+ 'tta': self.tta_var.get(),
+ 'save': self.save_var.get(),
+ 'output_image': self.outputImage_var.get(),
+ 'window_size': window_size,
+ 'agg': agg,
+ 'useModel': 'instrumental',
+ 'lastDir': self.lastDir,
+ 'modelFolder': self.modelFolder_var.get(),
+ 'modelInstrumentalLabel': self.instrumentalModel_var.get(),
+ 'aiModel': self.aiModel_var.get(),
+ 'algo': self.algo_var.get(),
+ 'ensChoose': self.ensChoose_var.get(),
+ 'mdxnetModel': self.mdxnetModel_var.get(),
+ #MDX-Net
+ 'demucsmodel': self.demucsmodel_var.get(),
+ 'non_red': self.non_red_var.get(),
+ 'noise_reduc': self.noisereduc_var.get(),
+ 'voc_only': self.voc_only_var.get(),
+ 'inst_only': self.inst_only_var.get(),
+ 'chunks': chunks,
+ 'noisereduc_s': noisereduc_s,
+ 'mixing': mixing,
+ })
+
+ self.destroy()
+
+if __name__ == "__main__":
+
+ root = MainWindow()
+
+ root.tk.call(
+ 'wm',
+ 'iconphoto',
+ root._w,
+ tk.PhotoImage(file='img\\GUI-icon.png')
+ )
+
+ lib_v5.sv_ttk.set_theme("dark")
+ lib_v5.sv_ttk.use_dark_theme() # Set dark theme
+
+ #Define a callback function
+ def callback(url):
+ webbrowser.open_new_tab(url)
+
+ root.mainloop()
diff --git a/VocalRemover.py b/VocalRemover.py
deleted file mode 100644
index 9fd172b..0000000
--- a/VocalRemover.py
+++ /dev/null
@@ -1,786 +0,0 @@
-# GUI modules
-import tkinter as tk
-import tkinter.ttk as ttk
-import tkinter.messagebox
-import tkinter.filedialog
-import tkinter.font
-from tkinterdnd2 import TkinterDnD, DND_FILES # Enable Drag & Drop
-from datetime import datetime
-# Images
-from PIL import Image
-from PIL import ImageTk
-import pickle # Save Data
-# Other Modules
-import subprocess # Run python file
-# Pathfinding
-import pathlib
-import sys
-import os
-import subprocess
-from collections import defaultdict
-# Used for live text displaying
-import queue
-import threading # Run the algorithm inside a thread
-
-
-from pathlib import Path
-
-import inference_v5
-import inference_v5_ensemble
-# import win32gui, win32con
-
-# the_program_to_hide = win32gui.GetForegroundWindow()
-# win32gui.ShowWindow(the_program_to_hide , win32con.SW_HIDE)
-
-# Change the current working directory to the directory
-# this file sits in
-if getattr(sys, 'frozen', False):
- # If the application is run as a bundle, the PyInstaller bootloader
- # extends the sys module by a flag frozen=True and sets the app
- # path into variable _MEIPASS'.
- base_path = sys._MEIPASS
-else:
- base_path = os.path.dirname(os.path.abspath(__file__))
-
-os.chdir(base_path) # Change the current working directory to the base path
-
-instrumentalModels_dir = os.path.join(base_path, 'models')
-banner_path = os.path.join(base_path, 'img', 'UVR-banner.png')
-efile_path = os.path.join(base_path, 'img', 'file.png')
-DEFAULT_DATA = {
- 'exportPath': '',
- 'inputPaths': [],
- 'gpu': False,
- 'postprocess': False,
- 'tta': False,
- 'save': True,
- 'output_image': False,
- 'window_size': '512',
- 'agg': 10,
- 'modelFolder': False,
- 'modelInstrumentalLabel': '',
- 'aiModel': 'Single Model',
- 'ensChoose': 'HP1 Models',
- 'useModel': 'instrumental',
- 'lastDir': None,
-}
-
-def open_image(path: str, size: tuple = None, keep_aspect: bool = True, rotate: int = 0) -> ImageTk.PhotoImage:
- """
- Open the image on the path and apply given settings\n
- Paramaters:
- path(str):
- Absolute path of the image
- size(tuple):
- first value - width
- second value - height
- keep_aspect(bool):
- keep aspect ratio of image and resize
- to maximum possible width and height
- (maxima are given by size)
- rotate(int):
- clockwise rotation of image
- Returns(ImageTk.PhotoImage):
- Image of path
- """
- img = Image.open(path).convert(mode='RGBA')
- ratio = img.height/img.width
- img = img.rotate(angle=-rotate)
- if size is not None:
- size = (int(size[0]), int(size[1]))
- if keep_aspect:
- img = img.resize((size[0], int(size[0] * ratio)), Image.ANTIALIAS)
- else:
- img = img.resize(size, Image.ANTIALIAS)
- return ImageTk.PhotoImage(img)
-
-def save_data(data):
- """
- Saves given data as a .pkl (pickle) file
-
- Paramters:
- data(dict):
- Dictionary containing all the necessary data to save
- """
- # Open data file, create it if it does not exist
- with open('data.pkl', 'wb') as data_file:
- pickle.dump(data, data_file)
-
-def load_data() -> dict:
- """
- Loads saved pkl file and returns the stored data
-
- Returns(dict):
- Dictionary containing all the saved data
- """
- try:
- with open('data.pkl', 'rb') as data_file: # Open data file
- data = pickle.load(data_file)
-
- return data
- except (ValueError, FileNotFoundError):
- # Data File is corrupted or not found so recreate it
- save_data(data=DEFAULT_DATA)
-
- return load_data()
-
-def drop(event, accept_mode: str = 'files'):
- """
- Drag & Drop verification process
- """
- path = event.data
-
- if accept_mode == 'folder':
- path = path.replace('{', '').replace('}', '')
- if not os.path.isdir(path):
- tk.messagebox.showerror(title='Invalid Folder',
- message='Your given export path is not a valid folder!')
- return
- # Set Variables
- root.exportPath_var.set(path)
- elif accept_mode == 'files':
- # Clean path text and set path to the list of paths
- path = path.replace('{', '')
- path = path.split('} ')
- path[-1] = path[-1].replace('}', '')
- # Set Variables
- root.inputPaths = path
- root.update_inputPaths()
- else:
- # Invalid accept mode
- return
-
-class ThreadSafeConsole(tk.Text):
- """
- Text Widget which is thread safe for tkinter
- """
- def __init__(self, master, **options):
- tk.Text.__init__(self, master, **options)
- self.queue = queue.Queue()
- self.update_me()
-
- def write(self, line):
- self.queue.put(line)
-
- def clear(self):
- self.queue.put(None)
-
- def update_me(self):
- self.configure(state=tk.NORMAL)
- try:
- while 1:
- line = self.queue.get_nowait()
- if line is None:
- self.delete(1.0, tk.END)
- else:
- self.insert(tk.END, str(line))
- self.see(tk.END)
- self.update_idletasks()
- except queue.Empty:
- pass
- self.configure(state=tk.DISABLED)
- self.after(100, self.update_me)
-
-class MainWindow(TkinterDnD.Tk):
- # --Constants--
- # Layout
- IMAGE_HEIGHT = 140
- FILEPATHS_HEIGHT = 80
- OPTIONS_HEIGHT = 190
- CONVERSIONBUTTON_HEIGHT = 35
- COMMAND_HEIGHT = 200
- PROGRESS_HEIGHT = 26
- PADDING = 10
-
- COL1_ROWS = 6
- COL2_ROWS = 6
- COL3_ROWS = 6
-
- def __init__(self):
- # Run the __init__ method on the tk.Tk class
- super().__init__()
- # Calculate window height
- height = self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT
- height += self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PROGRESS_HEIGHT
- height += self.PADDING * 5 # Padding
-
- # --Window Settings--
- self.title('Vocal Remover')
- # Set Geometry and Center Window
- self.geometry('{width}x{height}+{xpad}+{ypad}'.format(
- width=620,
- height=height,
- xpad=int(self.winfo_screenwidth()/2 - 550/2),
- ypad=int(self.winfo_screenheight()/2 - height/2 - 30)))
- self.configure(bg='#000000') # Set background color to black
- self.protocol("WM_DELETE_WINDOW", self.save_values)
- self.resizable(False, False)
- self.update()
-
- # --Variables--
- self.logo_img = open_image(path=banner_path,
- size=(self.winfo_width(), 9999))
- self.efile_img = open_image(path=efile_path,
- size=(20, 20))
- self.instrumentalLabel_to_path = defaultdict(lambda: '')
- self.lastInstrumentalModels = []
- # -Tkinter Value Holders-
- data = load_data()
- # Paths
- self.exportPath_var = tk.StringVar(value=data['exportPath'])
- self.inputPaths = data['inputPaths']
- # Processing Options
- self.gpuConversion_var = tk.BooleanVar(value=data['gpu'])
- self.postprocessing_var = tk.BooleanVar(value=data['postprocess'])
- self.tta_var = tk.BooleanVar(value=data['tta'])
- self.save_var = tk.BooleanVar(value=data['save'])
- self.outputImage_var = tk.BooleanVar(value=data['output_image'])
- # Models
- self.instrumentalModel_var = tk.StringVar(value=data['modelInstrumentalLabel'])
- # Model Test Mode
- self.modelFolder_var = tk.BooleanVar(value=data['modelFolder'])
- # Constants
- self.winSize_var = tk.StringVar(value=data['window_size'])
- self.agg_var = tk.StringVar(value=data['agg'])
- # Choose Conversion Method
- self.aiModel_var = tk.StringVar(value=data['aiModel'])
- self.last_aiModel = self.aiModel_var.get()
- # Choose Ensemble
- self.ensChoose_var = tk.StringVar(value=data['ensChoose'])
- self.last_ensChoose = self.ensChoose_var.get()
- # Other
- self.inputPathsEntry_var = tk.StringVar(value='')
- self.lastDir = data['lastDir'] # nopep8
- self.progress_var = tk.IntVar(value=0)
- # Font
- self.font = tk.font.Font(family='Microsoft JhengHei', size=9, weight='bold')
- # --Widgets--
- self.create_widgets()
- self.configure_widgets()
- self.bind_widgets()
- self.place_widgets()
- self.update_available_models()
- self.update_states()
- self.update_loop()
-
- # -Widget Methods-
- def create_widgets(self):
- """Create window widgets"""
- self.title_Label = tk.Label(master=self, bg='black',
- image=self.logo_img, compound=tk.TOP)
- self.filePaths_Frame = tk.Frame(master=self, bg='black')
- self.fill_filePaths_Frame()
-
- self.options_Frame = tk.Frame(master=self, bg='black')
- self.fill_options_Frame()
-
- self.conversion_Button = ttk.Button(master=self,
- text='Start Conversion',
- command=self.start_conversion)
- self.efile_Button = ttk.Button(master=self,
- image=self.efile_img,
- command=self.open_newModel_filedialog)
-
- self.progressbar = ttk.Progressbar(master=self,
- variable=self.progress_var)
-
- self.command_Text = ThreadSafeConsole(master=self,
- background='#a0a0a0',
- borderwidth=0,)
- self.command_Text.write(f'COMMAND LINE [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]') # nopep8
-
- def configure_widgets(self):
- """Change widget styling and appearance"""
-
- ttk.Style().configure('TCheckbutton', background='black',
- font=self.font, foreground='white')
- ttk.Style().configure('TRadiobutton', background='black',
- font=self.font, foreground='white')
- ttk.Style().configure('T', font=self.font, foreground='white')
-
- def bind_widgets(self):
- """Bind widgets to the drag & drop mechanic"""
- self.filePaths_saveTo_Button.drop_target_register(DND_FILES)
- self.filePaths_saveTo_Entry.drop_target_register(DND_FILES)
- self.filePaths_musicFile_Button.drop_target_register(DND_FILES)
- self.filePaths_musicFile_Entry.drop_target_register(DND_FILES)
- self.filePaths_saveTo_Button.dnd_bind('<>',
- lambda e: drop(e, accept_mode='folder'))
- self.filePaths_saveTo_Entry.dnd_bind('<>',
- lambda e: drop(e, accept_mode='folder'))
- self.filePaths_musicFile_Button.dnd_bind('<>',
- lambda e: drop(e, accept_mode='files'))
- self.filePaths_musicFile_Entry.dnd_bind('<>',
- lambda e: drop(e, accept_mode='files'))
-
- def place_widgets(self):
- """Place main widgets"""
- self.title_Label.place(x=-2, y=-2)
- self.filePaths_Frame.place(x=10, y=155, width=-20, height=self.FILEPATHS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.options_Frame.place(x=25, y=250, width=-50, height=self.OPTIONS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.conversion_Button.place(x=10, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=-20 - 40, height=self.CONVERSIONBUTTON_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.efile_Button.place(x=-10 - 35, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
- relx=1, rely=0, relwidth=0, relheight=0)
- self.command_Text.place(x=15, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.PADDING*3, width=-30, height=self.COMMAND_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.progressbar.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PADDING*4, width=-50, height=self.PROGRESS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
-
- def fill_filePaths_Frame(self):
- """Fill Frame with neccessary widgets"""
- # -Create Widgets-
- # Save To Option
- self.filePaths_saveTo_Button = ttk.Button(master=self.filePaths_Frame,
- text='Save to',
- command=self.open_export_filedialog)
- self.filePaths_saveTo_Entry = ttk.Entry(master=self.filePaths_Frame,
-
- textvariable=self.exportPath_var,
- state=tk.DISABLED
- )
- # Select Music Files Option
- self.filePaths_musicFile_Button = ttk.Button(master=self.filePaths_Frame,
- text='Select Your Audio File(s)',
- command=self.open_file_filedialog)
- self.filePaths_musicFile_Entry = ttk.Entry(master=self.filePaths_Frame,
- textvariable=self.inputPathsEntry_var,
- state=tk.DISABLED
- )
- # -Place Widgets-
- # Save To Option
- self.filePaths_saveTo_Button.place(x=0, y=5, width=0, height=-10,
- relx=0, rely=0, relwidth=0.3, relheight=0.5)
- self.filePaths_saveTo_Entry.place(x=10, y=7, width=-20, height=-14,
- relx=0.3, rely=0, relwidth=0.7, relheight=0.5)
- # Select Music Files Option
- self.filePaths_musicFile_Button.place(x=0, y=5, width=0, height=-10,
- relx=0, rely=0.5, relwidth=0.4, relheight=0.5)
- self.filePaths_musicFile_Entry.place(x=10, y=7, width=-20, height=-14,
- relx=0.4, rely=0.5, relwidth=0.6, relheight=0.5)
-
- def fill_options_Frame(self):
- """Fill Frame with neccessary widgets"""
- # -Create Widgets-
- # -Column 1-
- # GPU Selection
- self.options_gpu_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='GPU Conversion',
- variable=self.gpuConversion_var,
- )
- # Postprocessing
- self.options_post_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Post-Process',
- variable=self.postprocessing_var,
- )
- # TTA
- self.options_tta_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='TTA',
- variable=self.tta_var,
- )
- # Save Ensemble Outputs
- self.options_save_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Save All Outputs',
- variable=self.save_var,
- )
- # Save Image
- self.options_image_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Output Image',
- variable=self.outputImage_var,
- )
-
- # Model Test Mode
- self.options_modelFolder_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Model Test Mode',
- variable=self.modelFolder_var,
- )
- # -Column 2-
-
- # Choose Conversion Method
- self.options_aiModel_Label = tk.Label(master=self.options_Frame,
- text='Choose Conversion Method', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_aiModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.aiModel_var,
- None, 'Single Model', 'Ensemble Mode')
- # Ensemble Mode
- self.options_ensChoose_Label = tk.Label(master=self.options_Frame,
- text='Choose Ensemble', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_ensChoose_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.ensChoose_var,
- None, 'HP1 Models', 'HP2 Models', 'All HP Models', 'Vocal Models')
- # -Column 3-
-
- # WINDOW SIZE
- self.options_winSize_Label = tk.Label(master=self.options_Frame,
- text='Window Size', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_winSize_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.winSize_var,
- None, '320', '512','1024')
-
- # AGG
- self.options_agg_Entry = ttk.Entry(master=self.options_Frame,
- textvariable=self.agg_var, justify='center')
- self.options_agg_Label = tk.Label(master=self.options_Frame,
- text='Aggression Setting',
- background='#404040', font=self.font, foreground='white', relief="groove")
-
- # "Save to", "Select Your Audio File(s)"", and "Start Conversion" Button Style
- s = ttk.Style()
- s.configure('TButton', background='blue', foreground='black', font=('Microsoft JhengHei', '9', 'bold'), relief="groove")
-
- # -Column 3-
- # Choose Instrumental Model
- self.options_instrumentalModel_Label = tk.Label(master=self.options_Frame,
- text='Choose Main Model',
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_instrumentalModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.instrumentalModel_var)
-
- # -Place Widgets-
-
- # -Column 1-
- self.options_gpu_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=0, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_post_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=1/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_tta_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_image_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
-
- # -Column 2-
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
-
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=1/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- # Conversion Method
- self.options_aiModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_aiModel_Optionmenu.place(x=-15, y=4, width=0, height=-10,
- relx=1/3, rely=1/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- # -Column 3-
-
- # WINDOW
- self.options_winSize_Label.place(x=35, y=6, width=-40, height=-10,
- relx=2/3, rely=0, relwidth=1/3, relheight=1/self.COL3_ROWS)
- self.options_winSize_Optionmenu.place(x=80, y=6, width=-133, height=-10,
- relx=2/3, rely=1/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
-
- # AGG
- self.options_agg_Label.place(x=35, y=6, width=-40, height=-10,
- relx=2/3, rely=2/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
- self.options_agg_Entry.place(x=80, y=6, width=-133, height=-10,
- relx=2/3, rely=3/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
-
- # Model deselect
- self.aiModel_var.trace_add('write',
- lambda *args: self.deselect_models())
-
- # Opening filedialogs
- def open_file_filedialog(self):
- """Make user select music files"""
- if self.lastDir is not None:
- if not os.path.isdir(self.lastDir):
- self.lastDir = None
-
- paths = tk.filedialog.askopenfilenames(
- parent=self,
- title=f'Select Music Files',
- initialfile='',
- initialdir=self.lastDir,
- )
- if paths: # Path selected
- self.inputPaths = paths
- self.update_inputPaths()
- self.lastDir = os.path.dirname(paths[0])
-
- def open_export_filedialog(self):
- """Make user select a folder to export the converted files in"""
- path = tk.filedialog.askdirectory(
- parent=self,
- title=f'Select Folder',)
- if path: # Path selected
- self.exportPath_var.set(path)
-
- def open_newModel_filedialog(self):
- """Let user paste a ".pth" model to use for the vocal seperation"""
- filename = self.exportPath_var.get()
-
- if sys.platform == "win32":
- os.startfile(filename)
- else:
- opener = "open" if sys.platform == "darwin" else "xdg-open"
- subprocess.call([opener, filename])
-
- def start_conversion(self):
- """
- Start the conversion for all the given mp3 and wav files
- """
- # -Get all variables-
- export_path = self.exportPath_var.get()
- input_paths = self.inputPaths
- instrumentalModel_path = self.instrumentalLabel_to_path[self.instrumentalModel_var.get()] # nopep8
- # Get constants
- instrumental = self.instrumentalModel_var.get()
- try:
- if [bool(instrumental)].count(True) == 2: #CHECKTHIS
- window_size = DEFAULT_DATA['window_size']
- agg = DEFAULT_DATA['agg']
- else:
- window_size = int(self.winSize_var.get())
- agg = int(self.agg_var.get())
- ensChoose = str(self.ensChoose_var.get())
- except ValueError: # Non integer was put in entry box
- tk.messagebox.showwarning(master=self,
- title='Invalid Input',
- message='Please make sure you only input integer numbers!')
- return
- except SyntaxError: # Non integer was put in entry box
- tk.messagebox.showwarning(master=self,
- title='Invalid Music File',
- message='You have selected an invalid music file!\nPlease make sure that your files still exist and ends with either ".mp3", ".mp4", ".m4a", ".flac", ".wav"')
- return
-
- # -Check for invalid inputs-
- for path in input_paths:
- if not os.path.isfile(path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Music File',
- message='You have selected an invalid music file! Please make sure that the file still exists!',
- detail=f'File path: {path}')
- return
- if self.aiModel_var.get() == 'Single Model':
- if not os.path.isfile(instrumentalModel_path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Main Model File',
- message='You have selected an invalid main model file!\nPlease make sure that your model file still exists!')
- return
-
- if not os.path.isdir(export_path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Export Directory',
- message='You have selected an invalid export directory!\nPlease make sure that your directory still exists!')
- return
-
- if self.aiModel_var.get() == 'Single Model':
- inference = inference_v5
- elif self.aiModel_var.get() == 'Ensemble Mode':
- inference = inference_v5_ensemble
- else:
- raise TypeError('This error should not occur.')
-
- # -Run the algorithm-
- threading.Thread(target=inference.main,
- kwargs={
- # Paths
- 'input_paths': input_paths,
- 'export_path': export_path,
- # Processing Options
- 'gpu': 0 if self.gpuConversion_var.get() else -1,
- 'postprocess': self.postprocessing_var.get(),
- 'tta': self.tta_var.get(),
- 'save': self.save_var.get(),
- 'output_image': self.outputImage_var.get(),
- # Models
- 'instrumentalModel': instrumentalModel_path,
- 'vocalModel': '', # Always not needed
- 'useModel': 'instrumental', # Always instrumental
- # Model Folder
- 'modelFolder': self.modelFolder_var.get(),
- # Constants
- 'window_size': window_size,
- 'agg': agg,
- 'ensChoose': ensChoose,
- # Other Variables (Tkinter)
- 'window': self,
- 'text_widget': self.command_Text,
- 'button_widget': self.conversion_Button,
- 'inst_menu': self.options_instrumentalModel_Optionmenu,
- 'progress_var': self.progress_var,
- },
- daemon=True
- ).start()
-
- # Models
- def update_inputPaths(self):
- """Update the music file entry"""
- if self.inputPaths:
- # Non-empty Selection
- text = '; '.join(self.inputPaths)
- else:
- # Empty Selection
- text = ''
- self.inputPathsEntry_var.set(text)
-
- def update_loop(self):
- """Update the dropdown menu"""
- self.update_available_models()
-
- self.after(3000, self.update_loop)
-
- def update_available_models(self):
- """
- Loop through every model (.pth) in the models directory
- and add to the select your model list
- """
- #temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, self.aiModel_var.get(), 'Main Models') # nopep8
- temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, 'Main Models') # nopep8
-
- # Main models
- new_InstrumentalModels = os.listdir(temp_instrumentalModels_dir)
- if new_InstrumentalModels != self.lastInstrumentalModels:
- self.instrumentalLabel_to_path.clear()
- self.options_instrumentalModel_Optionmenu['menu'].delete(0, 'end')
- for file_name in new_InstrumentalModels:
- if file_name.endswith('.pth'):
- # Add Radiobutton to the Options Menu
- self.options_instrumentalModel_Optionmenu['menu'].add_radiobutton(label=file_name,
- command=tk._setit(self.instrumentalModel_var, file_name))
- # Link the files name to its absolute path
- self.instrumentalLabel_to_path[file_name] = os.path.join(temp_instrumentalModels_dir, file_name) # nopep8
- self.lastInstrumentalModels = new_InstrumentalModels
-
- def update_states(self):
- """
- Vary the states for all widgets based
- on certain selections
- """
- if self.aiModel_var.get() == 'Single Model':
- self.options_ensChoose_Label.place_forget()
- self.options_ensChoose_Optionmenu.place_forget()
- self.options_save_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- else:
- self.options_instrumentalModel_Label.place_forget()
- self.options_instrumentalModel_Optionmenu.place_forget()
- self.options_modelFolder_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.configure(state=tk.NORMAL)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- if self.aiModel_var.get() == 'Ensemble Mode':
- self.options_instrumentalModel_Label.place_forget()
- self.options_instrumentalModel_Optionmenu.place_forget()
- self.options_modelFolder_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.configure(state=tk.NORMAL)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- else:
- self.options_ensChoose_Label.place_forget()
- self.options_ensChoose_Optionmenu.place_forget()
- self.options_save_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
-
- self.update_inputPaths()
-
- def deselect_models(self):
- """
- Run this method on version change
- """
- if self.aiModel_var.get() == self.last_aiModel:
- return
- else:
- self.last_aiModel = self.aiModel_var.get()
-
- self.instrumentalModel_var.set('')
- self.ensChoose_var.set('HP1 Models')
-
- self.winSize_var.set(DEFAULT_DATA['window_size'])
- self.agg_var.set(DEFAULT_DATA['agg'])
- self.modelFolder_var.set(DEFAULT_DATA['modelFolder'])
-
-
- self.update_available_models()
- self.update_states()
-
- # def restart(self):
- # """
- # Restart the application after asking for confirmation
- # """
- # save = tk.messagebox.askyesno(title='Confirmation',
- # message='The application will restart. Do you want to save the data?')
- # if save:
- # self.save_values()
- # subprocess.Popen(f'..App\Python\python.exe "{__file__}"')
- # exit()
-
- def save_values(self):
- """
- Save the data of the application
- """
- # Get constants
- instrumental = self.instrumentalModel_var.get()
- if [bool(instrumental)].count(True) == 2: #Checkthis
- window_size = DEFAULT_DATA['window_size']
- agg = DEFAULT_DATA['agg']
- else:
- window_size = self.winSize_var.get()
- agg = self.agg_var.get()
-
- # -Save Data-
- save_data(data={
- 'exportPath': self.exportPath_var.get(),
- 'inputPaths': self.inputPaths,
- 'gpu': self.gpuConversion_var.get(),
- 'postprocess': self.postprocessing_var.get(),
- 'tta': self.tta_var.get(),
- 'save': self.save_var.get(),
- 'output_image': self.outputImage_var.get(),
- 'window_size': window_size,
- 'agg': agg,
- 'useModel': 'instrumental',
- 'lastDir': self.lastDir,
- 'modelFolder': self.modelFolder_var.get(),
- 'modelInstrumentalLabel': self.instrumentalModel_var.get(),
- 'aiModel': self.aiModel_var.get(),
- 'ensChoose': self.ensChoose_var.get(),
- })
-
- self.destroy()
-
-if __name__ == "__main__":
- root = MainWindow()
-
- root.mainloop()
diff --git a/demucs/__init__.py b/demucs/__init__.py
new file mode 100644
index 0000000..d4182e3
--- /dev/null
+++ b/demucs/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+__version__ = "2.0.3"
diff --git a/demucs/__main__.py b/demucs/__main__.py
new file mode 100644
index 0000000..5148f20
--- /dev/null
+++ b/demucs/__main__.py
@@ -0,0 +1,317 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import json
+import math
+import os
+import sys
+import time
+from dataclasses import dataclass, field
+
+import torch as th
+from torch import distributed, nn
+from torch.nn.parallel.distributed import DistributedDataParallel
+
+from .augment import FlipChannels, FlipSign, Remix, Scale, Shift
+from .compressed import get_compressed_datasets
+from .model import Demucs
+from .parser import get_name, get_parser
+from .raw import Rawset
+from .repitch import RepitchedWrapper
+from .pretrained import load_pretrained, SOURCES
+from .tasnet import ConvTasNet
+from .test import evaluate
+from .train import train_model, validate_model
+from .utils import (human_seconds, load_model, save_model, get_state,
+ save_state, sizeof_fmt, get_quantizer)
+from .wav import get_wav_datasets, get_musdb_wav_datasets
+
+
+@dataclass
+class SavedState:
+ metrics: list = field(default_factory=list)
+ last_state: dict = None
+ best_state: dict = None
+ optimizer: dict = None
+
+
+def main():
+ parser = get_parser()
+ args = parser.parse_args()
+ name = get_name(parser, args)
+ print(f"Experiment {name}")
+
+ if args.musdb is None and args.rank == 0:
+ print(
+ "You must provide the path to the MusDB dataset with the --musdb flag. "
+ "To download the MusDB dataset, see https://sigsep.github.io/datasets/musdb.html.",
+ file=sys.stderr)
+ sys.exit(1)
+
+ eval_folder = args.evals / name
+ eval_folder.mkdir(exist_ok=True, parents=True)
+ args.logs.mkdir(exist_ok=True)
+ metrics_path = args.logs / f"{name}.json"
+ eval_folder.mkdir(exist_ok=True, parents=True)
+ args.checkpoints.mkdir(exist_ok=True, parents=True)
+ args.models.mkdir(exist_ok=True, parents=True)
+
+ if args.device is None:
+ device = "cpu"
+ if th.cuda.is_available():
+ device = "cuda"
+ else:
+ device = args.device
+
+ th.manual_seed(args.seed)
+ # Prevents too many threads to be started when running `museval` as it can be quite
+ # inefficient on NUMA architectures.
+ os.environ["OMP_NUM_THREADS"] = "1"
+ os.environ["MKL_NUM_THREADS"] = "1"
+
+ if args.world_size > 1:
+ if device != "cuda" and args.rank == 0:
+ print("Error: distributed training is only available with cuda device", file=sys.stderr)
+ sys.exit(1)
+ th.cuda.set_device(args.rank % th.cuda.device_count())
+ distributed.init_process_group(backend="nccl",
+ init_method="tcp://" + args.master,
+ rank=args.rank,
+ world_size=args.world_size)
+
+ checkpoint = args.checkpoints / f"{name}.th"
+ checkpoint_tmp = args.checkpoints / f"{name}.th.tmp"
+ if args.restart and checkpoint.exists() and args.rank == 0:
+ checkpoint.unlink()
+
+ if args.test or args.test_pretrained:
+ args.epochs = 1
+ args.repeat = 0
+ if args.test:
+ model = load_model(args.models / args.test)
+ else:
+ model = load_pretrained(args.test_pretrained)
+ elif args.tasnet:
+ model = ConvTasNet(audio_channels=args.audio_channels,
+ samplerate=args.samplerate, X=args.X,
+ segment_length=4 * args.samples,
+ sources=SOURCES)
+ else:
+ model = Demucs(
+ audio_channels=args.audio_channels,
+ channels=args.channels,
+ context=args.context,
+ depth=args.depth,
+ glu=args.glu,
+ growth=args.growth,
+ kernel_size=args.kernel_size,
+ lstm_layers=args.lstm_layers,
+ rescale=args.rescale,
+ rewrite=args.rewrite,
+ stride=args.conv_stride,
+ resample=args.resample,
+ normalize=args.normalize,
+ samplerate=args.samplerate,
+ segment_length=4 * args.samples,
+ sources=SOURCES,
+ )
+ model.to(device)
+ if args.init:
+ model.load_state_dict(load_pretrained(args.init).state_dict())
+
+ if args.show:
+ print(model)
+ size = sizeof_fmt(4 * sum(p.numel() for p in model.parameters()))
+ print(f"Model size {size}")
+ return
+
+ try:
+ saved = th.load(checkpoint, map_location='cpu')
+ except IOError:
+ saved = SavedState()
+
+ optimizer = th.optim.Adam(model.parameters(), lr=args.lr)
+
+ quantizer = None
+ quantizer = get_quantizer(model, args, optimizer)
+
+ if saved.last_state is not None:
+ model.load_state_dict(saved.last_state, strict=False)
+ if saved.optimizer is not None:
+ optimizer.load_state_dict(saved.optimizer)
+
+ model_name = f"{name}.th"
+ if args.save_model:
+ if args.rank == 0:
+ model.to("cpu")
+ model.load_state_dict(saved.best_state)
+ save_model(model, quantizer, args, args.models / model_name)
+ return
+ elif args.save_state:
+ model_name = f"{args.save_state}.th"
+ if args.rank == 0:
+ model.to("cpu")
+ model.load_state_dict(saved.best_state)
+ state = get_state(model, quantizer)
+ save_state(state, args.models / model_name)
+ return
+
+ if args.rank == 0:
+ done = args.logs / f"{name}.done"
+ if done.exists():
+ done.unlink()
+
+ augment = [Shift(args.data_stride)]
+ if args.augment:
+ augment += [FlipSign(), FlipChannels(), Scale(),
+ Remix(group_size=args.remix_group_size)]
+ augment = nn.Sequential(*augment).to(device)
+ print("Agumentation pipeline:", augment)
+
+ if args.mse:
+ criterion = nn.MSELoss()
+ else:
+ criterion = nn.L1Loss()
+
+ # Setting number of samples so that all convolution windows are full.
+ # Prevents hard to debug mistake with the prediction being shifted compared
+ # to the input mixture.
+ samples = model.valid_length(args.samples)
+ print(f"Number of training samples adjusted to {samples}")
+ samples = samples + args.data_stride
+ if args.repitch:
+ # We need a bit more audio samples, to account for potential
+ # tempo change.
+ samples = math.ceil(samples / (1 - 0.01 * args.max_tempo))
+
+ args.metadata.mkdir(exist_ok=True, parents=True)
+ if args.raw:
+ train_set = Rawset(args.raw / "train",
+ samples=samples,
+ channels=args.audio_channels,
+ streams=range(1, len(model.sources) + 1),
+ stride=args.data_stride)
+
+ valid_set = Rawset(args.raw / "valid", channels=args.audio_channels)
+ elif args.wav:
+ train_set, valid_set = get_wav_datasets(args, samples, model.sources)
+ elif args.is_wav:
+ train_set, valid_set = get_musdb_wav_datasets(args, samples, model.sources)
+ else:
+ train_set, valid_set = get_compressed_datasets(args, samples)
+
+ if args.repitch:
+ train_set = RepitchedWrapper(
+ train_set,
+ proba=args.repitch,
+ max_tempo=args.max_tempo)
+
+ best_loss = float("inf")
+ for epoch, metrics in enumerate(saved.metrics):
+ print(f"Epoch {epoch:03d}: "
+ f"train={metrics['train']:.8f} "
+ f"valid={metrics['valid']:.8f} "
+ f"best={metrics['best']:.4f} "
+ f"ms={metrics.get('true_model_size', 0):.2f}MB "
+ f"cms={metrics.get('compressed_model_size', 0):.2f}MB "
+ f"duration={human_seconds(metrics['duration'])}")
+ best_loss = metrics['best']
+
+ if args.world_size > 1:
+ dmodel = DistributedDataParallel(model,
+ device_ids=[th.cuda.current_device()],
+ output_device=th.cuda.current_device())
+ else:
+ dmodel = model
+
+ for epoch in range(len(saved.metrics), args.epochs):
+ begin = time.time()
+ model.train()
+ train_loss, model_size = train_model(
+ epoch, train_set, dmodel, criterion, optimizer, augment,
+ quantizer=quantizer,
+ batch_size=args.batch_size,
+ device=device,
+ repeat=args.repeat,
+ seed=args.seed,
+ diffq=args.diffq,
+ workers=args.workers,
+ world_size=args.world_size)
+ model.eval()
+ valid_loss = validate_model(
+ epoch, valid_set, model, criterion,
+ device=device,
+ rank=args.rank,
+ split=args.split_valid,
+ overlap=args.overlap,
+ world_size=args.world_size)
+
+ ms = 0
+ cms = 0
+ if quantizer and args.rank == 0:
+ ms = quantizer.true_model_size()
+ cms = quantizer.compressed_model_size(num_workers=min(40, args.world_size * 10))
+
+ duration = time.time() - begin
+ if valid_loss < best_loss and ms <= args.ms_target:
+ best_loss = valid_loss
+ saved.best_state = {
+ key: value.to("cpu").clone()
+ for key, value in model.state_dict().items()
+ }
+
+ saved.metrics.append({
+ "train": train_loss,
+ "valid": valid_loss,
+ "best": best_loss,
+ "duration": duration,
+ "model_size": model_size,
+ "true_model_size": ms,
+ "compressed_model_size": cms,
+ })
+ if args.rank == 0:
+ json.dump(saved.metrics, open(metrics_path, "w"))
+
+ saved.last_state = model.state_dict()
+ saved.optimizer = optimizer.state_dict()
+ if args.rank == 0 and not args.test:
+ th.save(saved, checkpoint_tmp)
+ checkpoint_tmp.rename(checkpoint)
+
+ print(f"Epoch {epoch:03d}: "
+ f"train={train_loss:.8f} valid={valid_loss:.8f} best={best_loss:.4f} ms={ms:.2f}MB "
+ f"cms={cms:.2f}MB "
+ f"duration={human_seconds(duration)}")
+
+ if args.world_size > 1:
+ distributed.barrier()
+
+ del dmodel
+ model.load_state_dict(saved.best_state)
+ if args.eval_cpu:
+ device = "cpu"
+ model.to(device)
+ model.eval()
+ evaluate(model, args.musdb, eval_folder,
+ is_wav=args.is_wav,
+ rank=args.rank,
+ world_size=args.world_size,
+ device=device,
+ save=args.save,
+ split=args.split_valid,
+ shifts=args.shifts,
+ overlap=args.overlap,
+ workers=args.eval_workers)
+ model.to("cpu")
+ if args.rank == 0:
+ if not (args.test or args.test_pretrained):
+ save_model(model, quantizer, args, args.models / model_name)
+ print("done")
+ done.write_text("done")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/audio.py b/demucs/audio.py
new file mode 100644
index 0000000..b29f156
--- /dev/null
+++ b/demucs/audio.py
@@ -0,0 +1,172 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+import json
+import subprocess as sp
+from pathlib import Path
+
+import julius
+import numpy as np
+import torch
+
+from .utils import temp_filenames
+
+
+def _read_info(path):
+ stdout_data = sp.check_output([
+ 'ffprobe', "-loglevel", "panic",
+ str(path), '-print_format', 'json', '-show_format', '-show_streams'
+ ])
+ return json.loads(stdout_data.decode('utf-8'))
+
+
+class AudioFile:
+ """
+ Allows to read audio from any format supported by ffmpeg, as well as resampling or
+ converting to mono on the fly. See :method:`read` for more details.
+ """
+ def __init__(self, path: Path):
+ self.path = Path(path)
+ self._info = None
+
+ def __repr__(self):
+ features = [("path", self.path)]
+ features.append(("samplerate", self.samplerate()))
+ features.append(("channels", self.channels()))
+ features.append(("streams", len(self)))
+ features_str = ", ".join(f"{name}={value}" for name, value in features)
+ return f"AudioFile({features_str})"
+
+ @property
+ def info(self):
+ if self._info is None:
+ self._info = _read_info(self.path)
+ return self._info
+
+ @property
+ def duration(self):
+ return float(self.info['format']['duration'])
+
+ @property
+ def _audio_streams(self):
+ return [
+ index for index, stream in enumerate(self.info["streams"])
+ if stream["codec_type"] == "audio"
+ ]
+
+ def __len__(self):
+ return len(self._audio_streams)
+
+ def channels(self, stream=0):
+ return int(self.info['streams'][self._audio_streams[stream]]['channels'])
+
+ def samplerate(self, stream=0):
+ return int(self.info['streams'][self._audio_streams[stream]]['sample_rate'])
+
+ def read(self,
+ seek_time=None,
+ duration=None,
+ streams=slice(None),
+ samplerate=None,
+ channels=None,
+ temp_folder=None):
+ """
+ Slightly more efficient implementation than stempeg,
+ in particular, this will extract all stems at once
+ rather than having to loop over one file multiple times
+ for each stream.
+
+ Args:
+ seek_time (float): seek time in seconds or None if no seeking is needed.
+ duration (float): duration in seconds to extract or None to extract until the end.
+ streams (slice, int or list): streams to extract, can be a single int, a list or
+ a slice. If it is a slice or list, the output will be of size [S, C, T]
+ with S the number of streams, C the number of channels and T the number of samples.
+ If it is an int, the output will be [C, T].
+ samplerate (int): if provided, will resample on the fly. If None, no resampling will
+ be done. Original sampling rate can be obtained with :method:`samplerate`.
+ channels (int): if 1, will convert to mono. We do not rely on ffmpeg for that
+ as ffmpeg automatically scale by +3dB to conserve volume when playing on speakers.
+ See https://sound.stackexchange.com/a/42710.
+ Our definition of mono is simply the average of the two channels. Any other
+ value will be ignored.
+ temp_folder (str or Path or None): temporary folder to use for decoding.
+
+
+ """
+ streams = np.array(range(len(self)))[streams]
+ single = not isinstance(streams, np.ndarray)
+ if single:
+ streams = [streams]
+
+ if duration is None:
+ target_size = None
+ query_duration = None
+ else:
+ target_size = int((samplerate or self.samplerate()) * duration)
+ query_duration = float((target_size + 1) / (samplerate or self.samplerate()))
+
+ with temp_filenames(len(streams)) as filenames:
+ command = ['ffmpeg', '-y']
+ command += ['-loglevel', 'panic']
+ if seek_time:
+ command += ['-ss', str(seek_time)]
+ command += ['-i', str(self.path)]
+ for stream, filename in zip(streams, filenames):
+ command += ['-map', f'0:{self._audio_streams[stream]}']
+ if query_duration is not None:
+ command += ['-t', str(query_duration)]
+ command += ['-threads', '1']
+ command += ['-f', 'f32le']
+ if samplerate is not None:
+ command += ['-ar', str(samplerate)]
+ command += [filename]
+
+ sp.run(command, check=True)
+ wavs = []
+ for filename in filenames:
+ wav = np.fromfile(filename, dtype=np.float32)
+ wav = torch.from_numpy(wav)
+ wav = wav.view(-1, self.channels()).t()
+ if channels is not None:
+ wav = convert_audio_channels(wav, channels)
+ if target_size is not None:
+ wav = wav[..., :target_size]
+ wavs.append(wav)
+ wav = torch.stack(wavs, dim=0)
+ if single:
+ wav = wav[0]
+ return wav
+
+
+def convert_audio_channels(wav, channels=2):
+ """Convert audio to the given number of channels."""
+ *shape, src_channels, length = wav.shape
+ if src_channels == channels:
+ pass
+ elif channels == 1:
+ # Case 1:
+ # The caller asked 1-channel audio, but the stream have multiple
+ # channels, downmix all channels.
+ wav = wav.mean(dim=-2, keepdim=True)
+ elif src_channels == 1:
+ # Case 2:
+ # The caller asked for multiple channels, but the input file have
+ # one single channel, replicate the audio over all channels.
+ wav = wav.expand(*shape, channels, length)
+ elif src_channels >= channels:
+ # Case 3:
+ # The caller asked for multiple channels, and the input file have
+ # more channels than requested. In that case return the first channels.
+ wav = wav[..., :channels, :]
+ else:
+ # Case 4: What is a reasonable choice here?
+ raise ValueError('The audio file has less channels than requested but is not mono.')
+ return wav
+
+
+def convert_audio(wav, from_samplerate, to_samplerate, channels):
+ wav = convert_audio_channels(wav, channels)
+ return julius.resample_frac(wav, from_samplerate, to_samplerate)
diff --git a/demucs/compressed.py b/demucs/compressed.py
new file mode 100644
index 0000000..eb8fbb7
--- /dev/null
+++ b/demucs/compressed.py
@@ -0,0 +1,115 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import json
+from fractions import Fraction
+from concurrent import futures
+
+import musdb
+from torch import distributed
+
+from .audio import AudioFile
+
+
+def get_musdb_tracks(root, *args, **kwargs):
+ mus = musdb.DB(root, *args, **kwargs)
+ return {track.name: track.path for track in mus}
+
+
+class StemsSet:
+ def __init__(self, tracks, metadata, duration=None, stride=1,
+ samplerate=44100, channels=2, streams=slice(None)):
+
+ self.metadata = []
+ for name, path in tracks.items():
+ meta = dict(metadata[name])
+ meta["path"] = path
+ meta["name"] = name
+ self.metadata.append(meta)
+ if duration is not None and meta["duration"] < duration:
+ raise ValueError(f"Track {name} duration is too small {meta['duration']}")
+ self.metadata.sort(key=lambda x: x["name"])
+ self.duration = duration
+ self.stride = stride
+ self.channels = channels
+ self.samplerate = samplerate
+ self.streams = streams
+
+ def __len__(self):
+ return sum(self._examples_count(m) for m in self.metadata)
+
+ def _examples_count(self, meta):
+ if self.duration is None:
+ return 1
+ else:
+ return int((meta["duration"] - self.duration) // self.stride + 1)
+
+ def track_metadata(self, index):
+ for meta in self.metadata:
+ examples = self._examples_count(meta)
+ if index >= examples:
+ index -= examples
+ continue
+ return meta
+
+ def __getitem__(self, index):
+ for meta in self.metadata:
+ examples = self._examples_count(meta)
+ if index >= examples:
+ index -= examples
+ continue
+ streams = AudioFile(meta["path"]).read(seek_time=index * self.stride,
+ duration=self.duration,
+ channels=self.channels,
+ samplerate=self.samplerate,
+ streams=self.streams)
+ return (streams - meta["mean"]) / meta["std"]
+
+
+def _get_track_metadata(path):
+ # use mono at 44kHz as reference. For any other settings data won't be perfectly
+ # normalized but it should be good enough.
+ audio = AudioFile(path)
+ mix = audio.read(streams=0, channels=1, samplerate=44100)
+ return {"duration": audio.duration, "std": mix.std().item(), "mean": mix.mean().item()}
+
+
+def _build_metadata(tracks, workers=10):
+ pendings = []
+ with futures.ProcessPoolExecutor(workers) as pool:
+ for name, path in tracks.items():
+ pendings.append((name, pool.submit(_get_track_metadata, path)))
+ return {name: p.result() for name, p in pendings}
+
+
+def _build_musdb_metadata(path, musdb, workers):
+ tracks = get_musdb_tracks(musdb)
+ metadata = _build_metadata(tracks, workers)
+ path.parent.mkdir(exist_ok=True, parents=True)
+ json.dump(metadata, open(path, "w"))
+
+
+def get_compressed_datasets(args, samples):
+ metadata_file = args.metadata / "musdb.json"
+ if not metadata_file.is_file() and args.rank == 0:
+ _build_musdb_metadata(metadata_file, args.musdb, args.workers)
+ if args.world_size > 1:
+ distributed.barrier()
+ metadata = json.load(open(metadata_file))
+ duration = Fraction(samples, args.samplerate)
+ stride = Fraction(args.data_stride, args.samplerate)
+ train_set = StemsSet(get_musdb_tracks(args.musdb, subsets=["train"], split="train"),
+ metadata,
+ duration=duration,
+ stride=stride,
+ streams=slice(1, None),
+ samplerate=args.samplerate,
+ channels=args.audio_channels)
+ valid_set = StemsSet(get_musdb_tracks(args.musdb, subsets=["train"], split="valid"),
+ metadata,
+ samplerate=args.samplerate,
+ channels=args.audio_channels)
+ return train_set, valid_set
diff --git a/demucs/model.py b/demucs/model.py
new file mode 100644
index 0000000..e9d932f
--- /dev/null
+++ b/demucs/model.py
@@ -0,0 +1,202 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import math
+
+import julius
+from torch import nn
+
+from .utils import capture_init, center_trim
+
+
+class BLSTM(nn.Module):
+ def __init__(self, dim, layers=1):
+ super().__init__()
+ self.lstm = nn.LSTM(bidirectional=True, num_layers=layers, hidden_size=dim, input_size=dim)
+ self.linear = nn.Linear(2 * dim, dim)
+
+ def forward(self, x):
+ x = x.permute(2, 0, 1)
+ x = self.lstm(x)[0]
+ x = self.linear(x)
+ x = x.permute(1, 2, 0)
+ return x
+
+
+def rescale_conv(conv, reference):
+ std = conv.weight.std().detach()
+ scale = (std / reference)**0.5
+ conv.weight.data /= scale
+ if conv.bias is not None:
+ conv.bias.data /= scale
+
+
+def rescale_module(module, reference):
+ for sub in module.modules():
+ if isinstance(sub, (nn.Conv1d, nn.ConvTranspose1d)):
+ rescale_conv(sub, reference)
+
+
+class Demucs(nn.Module):
+ @capture_init
+ def __init__(self,
+ sources,
+ audio_channels=2,
+ channels=64,
+ depth=6,
+ rewrite=True,
+ glu=True,
+ rescale=0.1,
+ resample=True,
+ kernel_size=8,
+ stride=4,
+ growth=2.,
+ lstm_layers=2,
+ context=3,
+ normalize=False,
+ samplerate=44100,
+ segment_length=4 * 10 * 44100):
+ """
+ Args:
+ sources (list[str]): list of source names
+ audio_channels (int): stereo or mono
+ channels (int): first convolution channels
+ depth (int): number of encoder/decoder layers
+ rewrite (bool): add 1x1 convolution to each encoder layer
+ and a convolution to each decoder layer.
+ For the decoder layer, `context` gives the kernel size.
+ glu (bool): use glu instead of ReLU
+ resample_input (bool): upsample x2 the input and downsample /2 the output.
+ rescale (int): rescale initial weights of convolutions
+ to get their standard deviation closer to `rescale`
+ kernel_size (int): kernel size for convolutions
+ stride (int): stride for convolutions
+ growth (float): multiply (resp divide) number of channels by that
+ for each layer of the encoder (resp decoder)
+ lstm_layers (int): number of lstm layers, 0 = no lstm
+ context (int): kernel size of the convolution in the
+ decoder before the transposed convolution. If > 1,
+ will provide some context from neighboring time
+ steps.
+ samplerate (int): stored as meta information for easing
+ future evaluations of the model.
+ segment_length (int): stored as meta information for easing
+ future evaluations of the model. Length of the segments on which
+ the model was trained.
+ """
+
+ super().__init__()
+ self.audio_channels = audio_channels
+ self.sources = sources
+ self.kernel_size = kernel_size
+ self.context = context
+ self.stride = stride
+ self.depth = depth
+ self.resample = resample
+ self.channels = channels
+ self.normalize = normalize
+ self.samplerate = samplerate
+ self.segment_length = segment_length
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ if glu:
+ activation = nn.GLU(dim=1)
+ ch_scale = 2
+ else:
+ activation = nn.ReLU()
+ ch_scale = 1
+ in_channels = audio_channels
+ for index in range(depth):
+ encode = []
+ encode += [nn.Conv1d(in_channels, channels, kernel_size, stride), nn.ReLU()]
+ if rewrite:
+ encode += [nn.Conv1d(channels, ch_scale * channels, 1), activation]
+ self.encoder.append(nn.Sequential(*encode))
+
+ decode = []
+ if index > 0:
+ out_channels = in_channels
+ else:
+ out_channels = len(self.sources) * audio_channels
+ if rewrite:
+ decode += [nn.Conv1d(channels, ch_scale * channels, context), activation]
+ decode += [nn.ConvTranspose1d(channels, out_channels, kernel_size, stride)]
+ if index > 0:
+ decode.append(nn.ReLU())
+ self.decoder.insert(0, nn.Sequential(*decode))
+ in_channels = channels
+ channels = int(growth * channels)
+
+ channels = in_channels
+
+ if lstm_layers:
+ self.lstm = BLSTM(channels, lstm_layers)
+ else:
+ self.lstm = None
+
+ if rescale:
+ rescale_module(self, reference=rescale)
+
+ def valid_length(self, length):
+ """
+ Return the nearest valid length to use with the model so that
+ there is no time steps left over in a convolutions, e.g. for all
+ layers, size of the input - kernel_size % stride = 0.
+
+ If the mixture has a valid length, the estimated sources
+ will have exactly the same length when context = 1. If context > 1,
+ the two signals can be center trimmed to match.
+
+ For training, extracts should have a valid length.For evaluation
+ on full tracks we recommend passing `pad = True` to :method:`forward`.
+ """
+ if self.resample:
+ length *= 2
+ for _ in range(self.depth):
+ length = math.ceil((length - self.kernel_size) / self.stride) + 1
+ length = max(1, length)
+ length += self.context - 1
+ for _ in range(self.depth):
+ length = (length - 1) * self.stride + self.kernel_size
+
+ if self.resample:
+ length = math.ceil(length / 2)
+ return int(length)
+
+ def forward(self, mix):
+ x = mix
+
+ if self.normalize:
+ mono = mix.mean(dim=1, keepdim=True)
+ mean = mono.mean(dim=-1, keepdim=True)
+ std = mono.std(dim=-1, keepdim=True)
+ else:
+ mean = 0
+ std = 1
+
+ x = (x - mean) / (1e-5 + std)
+
+ if self.resample:
+ x = julius.resample_frac(x, 1, 2)
+
+ saved = []
+ for encode in self.encoder:
+ x = encode(x)
+ saved.append(x)
+ if self.lstm:
+ x = self.lstm(x)
+ for decode in self.decoder:
+ skip = center_trim(saved.pop(-1), x)
+ x = x + skip
+ x = decode(x)
+
+ if self.resample:
+ x = julius.resample_frac(x, 2, 1)
+ x = x * std + mean
+ x = x.view(x.size(0), len(self.sources), self.audio_channels, x.size(-1))
+ return x
diff --git a/demucs/parser.py b/demucs/parser.py
new file mode 100644
index 0000000..4e8a19c
--- /dev/null
+++ b/demucs/parser.py
@@ -0,0 +1,244 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import os
+from pathlib import Path
+
+
+def get_parser():
+ parser = argparse.ArgumentParser("demucs", description="Train and evaluate Demucs.")
+ default_raw = None
+ default_musdb = None
+ if 'DEMUCS_RAW' in os.environ:
+ default_raw = Path(os.environ['DEMUCS_RAW'])
+ if 'DEMUCS_MUSDB' in os.environ:
+ default_musdb = Path(os.environ['DEMUCS_MUSDB'])
+ parser.add_argument(
+ "--raw",
+ type=Path,
+ default=default_raw,
+ help="Path to raw audio, can be faster, see python3 -m demucs.raw to extract.")
+ parser.add_argument("--no_raw", action="store_const", const=None, dest="raw")
+ parser.add_argument("-m",
+ "--musdb",
+ type=Path,
+ default=default_musdb,
+ help="Path to musdb root")
+ parser.add_argument("--is_wav", action="store_true",
+ help="Indicate that the MusDB dataset is in wav format (i.e. MusDB-HQ).")
+ parser.add_argument("--metadata", type=Path, default=Path("metadata/"),
+ help="Folder where metadata information is stored.")
+ parser.add_argument("--wav", type=Path,
+ help="Path to a wav dataset. This should contain a 'train' and a 'valid' "
+ "subfolder.")
+ parser.add_argument("--samplerate", type=int, default=44100)
+ parser.add_argument("--audio_channels", type=int, default=2)
+ parser.add_argument("--samples",
+ default=44100 * 10,
+ type=int,
+ help="number of samples to feed in")
+ parser.add_argument("--data_stride",
+ default=44100,
+ type=int,
+ help="Stride for chunks, shorter = longer epochs")
+ parser.add_argument("-w", "--workers", default=10, type=int, help="Loader workers")
+ parser.add_argument("--eval_workers", default=2, type=int, help="Final evaluation workers")
+ parser.add_argument("-d",
+ "--device",
+ help="Device to train on, default is cuda if available else cpu")
+ parser.add_argument("--eval_cpu", action="store_true", help="Eval on test will be run on cpu.")
+ parser.add_argument("--dummy", help="Dummy parameter, useful to create a new checkpoint file")
+ parser.add_argument("--test", help="Just run the test pipeline + one validation. "
+ "This should be a filename relative to the models/ folder.")
+ parser.add_argument("--test_pretrained", help="Just run the test pipeline + one validation, "
+ "on a pretrained model. ")
+
+ parser.add_argument("--rank", default=0, type=int)
+ parser.add_argument("--world_size", default=1, type=int)
+ parser.add_argument("--master")
+
+ parser.add_argument("--checkpoints",
+ type=Path,
+ default=Path("checkpoints"),
+ help="Folder where to store checkpoints etc")
+ parser.add_argument("--evals",
+ type=Path,
+ default=Path("evals"),
+ help="Folder where to store evals and waveforms")
+ parser.add_argument("--save",
+ action="store_true",
+ help="Save estimated for the test set waveforms")
+ parser.add_argument("--logs",
+ type=Path,
+ default=Path("logs"),
+ help="Folder where to store logs")
+ parser.add_argument("--models",
+ type=Path,
+ default=Path("models"),
+ help="Folder where to store trained models")
+ parser.add_argument("-R",
+ "--restart",
+ action='store_true',
+ help='Restart training, ignoring previous run')
+
+ parser.add_argument("--seed", type=int, default=42)
+ parser.add_argument("-e", "--epochs", type=int, default=180, help="Number of epochs")
+ parser.add_argument("-r",
+ "--repeat",
+ type=int,
+ default=2,
+ help="Repeat the train set, longer epochs")
+ parser.add_argument("-b", "--batch_size", type=int, default=64)
+ parser.add_argument("--lr", type=float, default=3e-4)
+ parser.add_argument("--mse", action="store_true", help="Use MSE instead of L1")
+ parser.add_argument("--init", help="Initialize from a pre-trained model.")
+
+ # Augmentation options
+ parser.add_argument("--no_augment",
+ action="store_false",
+ dest="augment",
+ default=True,
+ help="No basic data augmentation.")
+ parser.add_argument("--repitch", type=float, default=0.2,
+ help="Probability to do tempo/pitch change")
+ parser.add_argument("--max_tempo", type=float, default=12,
+ help="Maximum relative tempo change in %% when using repitch.")
+
+ parser.add_argument("--remix_group_size",
+ type=int,
+ default=4,
+ help="Shuffle sources using group of this size. Useful to somewhat "
+ "replicate multi-gpu training "
+ "on less GPUs.")
+ parser.add_argument("--shifts",
+ type=int,
+ default=10,
+ help="Number of random shifts used for the shift trick.")
+ parser.add_argument("--overlap",
+ type=float,
+ default=0.25,
+ help="Overlap when --split_valid is passed.")
+
+ # See model.py for doc
+ parser.add_argument("--growth",
+ type=float,
+ default=2.,
+ help="Number of channels between two layers will increase by this factor")
+ parser.add_argument("--depth",
+ type=int,
+ default=6,
+ help="Number of layers for the encoder and decoder")
+ parser.add_argument("--lstm_layers", type=int, default=2, help="Number of layers for the LSTM")
+ parser.add_argument("--channels",
+ type=int,
+ default=64,
+ help="Number of channels for the first encoder layer")
+ parser.add_argument("--kernel_size",
+ type=int,
+ default=8,
+ help="Kernel size for the (transposed) convolutions")
+ parser.add_argument("--conv_stride",
+ type=int,
+ default=4,
+ help="Stride for the (transposed) convolutions")
+ parser.add_argument("--context",
+ type=int,
+ default=3,
+ help="Context size for the decoder convolutions "
+ "before the transposed convolutions")
+ parser.add_argument("--rescale",
+ type=float,
+ default=0.1,
+ help="Initial weight rescale reference")
+ parser.add_argument("--no_resample", action="store_false",
+ default=True, dest="resample",
+ help="No Resampling of the input/output x2")
+ parser.add_argument("--no_glu",
+ action="store_false",
+ default=True,
+ dest="glu",
+ help="Replace all GLUs by ReLUs")
+ parser.add_argument("--no_rewrite",
+ action="store_false",
+ default=True,
+ dest="rewrite",
+ help="No 1x1 rewrite convolutions")
+ parser.add_argument("--normalize", action="store_true")
+ parser.add_argument("--no_norm_wav", action="store_false", dest='norm_wav', default=True)
+
+ # Tasnet options
+ parser.add_argument("--tasnet", action="store_true")
+ parser.add_argument("--split_valid",
+ action="store_true",
+ help="Predict chunks by chunks for valid and test. Required for tasnet")
+ parser.add_argument("--X", type=int, default=8)
+
+ # Other options
+ parser.add_argument("--show",
+ action="store_true",
+ help="Show model architecture, size and exit")
+ parser.add_argument("--save_model", action="store_true",
+ help="Skip traning, just save final model "
+ "for the current checkpoint value.")
+ parser.add_argument("--save_state",
+ help="Skip training, just save state "
+ "for the current checkpoint value. You should "
+ "provide a model name as argument.")
+
+ # Quantization options
+ parser.add_argument("--q-min-size", type=float, default=1,
+ help="Only quantize layers over this size (in MB)")
+ parser.add_argument(
+ "--qat", type=int, help="If provided, use QAT training with that many bits.")
+
+ parser.add_argument("--diffq", type=float, default=0)
+ parser.add_argument(
+ "--ms-target", type=float, default=162,
+ help="Model size target in MB, when using DiffQ. Best model will be kept "
+ "only if it is smaller than this target.")
+
+ return parser
+
+
+def get_name(parser, args):
+ """
+ Return the name of an experiment given the args. Some parameters are ignored,
+ for instance --workers, as they do not impact the final result.
+ """
+ ignore_args = set([
+ "checkpoints",
+ "deterministic",
+ "eval",
+ "evals",
+ "eval_cpu",
+ "eval_workers",
+ "logs",
+ "master",
+ "rank",
+ "restart",
+ "save",
+ "save_model",
+ "save_state",
+ "show",
+ "workers",
+ "world_size",
+ ])
+ parts = []
+ name_args = dict(args.__dict__)
+ for name, value in name_args.items():
+ if name in ignore_args:
+ continue
+ if value != parser.get_default(name):
+ if isinstance(value, Path):
+ parts.append(f"{name}={value.name}")
+ else:
+ parts.append(f"{name}={value}")
+ if parts:
+ name = " ".join(parts)
+ else:
+ name = "default"
+ return name
diff --git a/demucs/pretrained.py b/demucs/pretrained.py
new file mode 100644
index 0000000..6aac5db
--- /dev/null
+++ b/demucs/pretrained.py
@@ -0,0 +1,107 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+# author: adefossez
+
+import logging
+
+from diffq import DiffQuantizer
+import torch.hub
+
+from .model import Demucs
+from .tasnet import ConvTasNet
+from .utils import set_state
+
+logger = logging.getLogger(__name__)
+ROOT = "https://dl.fbaipublicfiles.com/demucs/v3.0/"
+
+PRETRAINED_MODELS = {
+ 'demucs': 'e07c671f',
+ 'demucs48_hq': '28a1282c',
+ 'demucs_extra': '3646af93',
+ 'demucs_quantized': '07afea75',
+ 'tasnet': 'beb46fac',
+ 'tasnet_extra': 'df3777b2',
+ 'demucs_unittest': '09ebc15f',
+}
+
+SOURCES = ["drums", "bass", "other", "vocals"]
+
+
+def get_url(name):
+ sig = PRETRAINED_MODELS[name]
+ return ROOT + name + "-" + sig[:8] + ".th"
+
+
+def is_pretrained(name):
+ return name in PRETRAINED_MODELS
+
+
+def load_pretrained(name):
+ if name == "demucs":
+ return demucs(pretrained=True)
+ elif name == "demucs48_hq":
+ return demucs(pretrained=True, hq=True, channels=48)
+ elif name == "demucs_extra":
+ return demucs(pretrained=True, extra=True)
+ elif name == "demucs_quantized":
+ return demucs(pretrained=True, quantized=True)
+ elif name == "demucs_unittest":
+ return demucs_unittest(pretrained=True)
+ elif name == "tasnet":
+ return tasnet(pretrained=True)
+ elif name == "tasnet_extra":
+ return tasnet(pretrained=True, extra=True)
+ else:
+ raise ValueError(f"Invalid pretrained name {name}")
+
+
+def _load_state(name, model, quantizer=None):
+ url = get_url(name)
+ state = torch.hub.load_state_dict_from_url(url, map_location='cpu', check_hash=True)
+ set_state(model, quantizer, state)
+ if quantizer:
+ quantizer.detach()
+
+
+def demucs_unittest(pretrained=True):
+ model = Demucs(channels=4, sources=SOURCES)
+ if pretrained:
+ _load_state('demucs_unittest', model)
+ return model
+
+
+def demucs(pretrained=True, extra=False, quantized=False, hq=False, channels=64):
+ if not pretrained and (extra or quantized or hq):
+ raise ValueError("if extra or quantized is True, pretrained must be True.")
+ model = Demucs(sources=SOURCES, channels=channels)
+ if pretrained:
+ name = 'demucs'
+ if channels != 64:
+ name += str(channels)
+ quantizer = None
+ if sum([extra, quantized, hq]) > 1:
+ raise ValueError("Only one of extra, quantized, hq, can be True.")
+ if quantized:
+ quantizer = DiffQuantizer(model, group_size=8, min_size=1)
+ name += '_quantized'
+ if extra:
+ name += '_extra'
+ if hq:
+ name += '_hq'
+ _load_state(name, model, quantizer)
+ return model
+
+
+def tasnet(pretrained=True, extra=False):
+ if not pretrained and extra:
+ raise ValueError("if extra is True, pretrained must be True.")
+ model = ConvTasNet(X=10, sources=SOURCES)
+ if pretrained:
+ name = 'tasnet'
+ if extra:
+ name = 'tasnet_extra'
+ _load_state(name, model)
+ return model
diff --git a/demucs/raw.py b/demucs/raw.py
new file mode 100644
index 0000000..d4941ad
--- /dev/null
+++ b/demucs/raw.py
@@ -0,0 +1,173 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import os
+from collections import defaultdict, namedtuple
+from pathlib import Path
+
+import musdb
+import numpy as np
+import torch as th
+import tqdm
+from torch.utils.data import DataLoader
+
+from .audio import AudioFile
+
+ChunkInfo = namedtuple("ChunkInfo", ["file_index", "offset", "local_index"])
+
+
+class Rawset:
+ """
+ Dataset of raw, normalized, float32 audio files
+ """
+ def __init__(self, path, samples=None, stride=None, channels=2, streams=None):
+ self.path = Path(path)
+ self.channels = channels
+ self.samples = samples
+ if stride is None:
+ stride = samples if samples is not None else 0
+ self.stride = stride
+ entries = defaultdict(list)
+ for root, folders, files in os.walk(self.path, followlinks=True):
+ folders.sort()
+ files.sort()
+ for file in files:
+ if file.endswith(".raw"):
+ path = Path(root) / file
+ name, stream = path.stem.rsplit('.', 1)
+ entries[(path.parent.relative_to(self.path), name)].append(int(stream))
+
+ self._entries = list(entries.keys())
+
+ sizes = []
+ self._lengths = []
+ ref_streams = sorted(entries[self._entries[0]])
+ assert ref_streams == list(range(len(ref_streams)))
+ if streams is None:
+ self.streams = ref_streams
+ else:
+ self.streams = streams
+ for entry in sorted(entries.keys()):
+ streams = entries[entry]
+ assert sorted(streams) == ref_streams
+ file = self._path(*entry)
+ length = file.stat().st_size // (4 * channels)
+ if samples is None:
+ sizes.append(1)
+ else:
+ if length < samples:
+ self._entries.remove(entry)
+ continue
+ sizes.append((length - samples) // stride + 1)
+ self._lengths.append(length)
+ if not sizes:
+ raise ValueError(f"Empty dataset {self.path}")
+ self._cumulative_sizes = np.cumsum(sizes)
+ self._sizes = sizes
+
+ def __len__(self):
+ return self._cumulative_sizes[-1]
+
+ @property
+ def total_length(self):
+ return sum(self._lengths)
+
+ def chunk_info(self, index):
+ file_index = np.searchsorted(self._cumulative_sizes, index, side='right')
+ if file_index == 0:
+ local_index = index
+ else:
+ local_index = index - self._cumulative_sizes[file_index - 1]
+ return ChunkInfo(offset=local_index * self.stride,
+ file_index=file_index,
+ local_index=local_index)
+
+ def _path(self, folder, name, stream=0):
+ return self.path / folder / (name + f'.{stream}.raw')
+
+ def __getitem__(self, index):
+ chunk = self.chunk_info(index)
+ entry = self._entries[chunk.file_index]
+
+ length = self.samples or self._lengths[chunk.file_index]
+ streams = []
+ to_read = length * self.channels * 4
+ for stream_index, stream in enumerate(self.streams):
+ offset = chunk.offset * 4 * self.channels
+ file = open(self._path(*entry, stream=stream), 'rb')
+ file.seek(offset)
+ content = file.read(to_read)
+ assert len(content) == to_read
+ content = np.frombuffer(content, dtype=np.float32)
+ content = content.copy() # make writable
+ streams.append(th.from_numpy(content).view(length, self.channels).t())
+ return th.stack(streams, dim=0)
+
+ def name(self, index):
+ chunk = self.chunk_info(index)
+ folder, name = self._entries[chunk.file_index]
+ return folder / name
+
+
+class MusDBSet:
+ def __init__(self, mus, streams=slice(None), samplerate=44100, channels=2):
+ self.mus = mus
+ self.streams = streams
+ self.samplerate = samplerate
+ self.channels = channels
+
+ def __len__(self):
+ return len(self.mus.tracks)
+
+ def __getitem__(self, index):
+ track = self.mus.tracks[index]
+ return (track.name, AudioFile(track.path).read(channels=self.channels,
+ seek_time=0,
+ streams=self.streams,
+ samplerate=self.samplerate))
+
+
+def build_raw(mus, destination, normalize, workers, samplerate, channels):
+ destination.mkdir(parents=True, exist_ok=True)
+ loader = DataLoader(MusDBSet(mus, channels=channels, samplerate=samplerate),
+ batch_size=1,
+ num_workers=workers,
+ collate_fn=lambda x: x[0])
+ for name, streams in tqdm.tqdm(loader):
+ if normalize:
+ ref = streams[0].mean(dim=0) # use mono mixture as reference
+ streams = (streams - ref.mean()) / ref.std()
+ for index, stream in enumerate(streams):
+ open(destination / (name + f'.{index}.raw'), "wb").write(stream.t().numpy().tobytes())
+
+
+def main():
+ parser = argparse.ArgumentParser('rawset')
+ parser.add_argument('--workers', type=int, default=10)
+ parser.add_argument('--samplerate', type=int, default=44100)
+ parser.add_argument('--channels', type=int, default=2)
+ parser.add_argument('musdb', type=Path)
+ parser.add_argument('destination', type=Path)
+
+ args = parser.parse_args()
+
+ build_raw(musdb.DB(root=args.musdb, subsets=["train"], split="train"),
+ args.destination / "train",
+ normalize=True,
+ channels=args.channels,
+ samplerate=args.samplerate,
+ workers=args.workers)
+ build_raw(musdb.DB(root=args.musdb, subsets=["train"], split="valid"),
+ args.destination / "valid",
+ normalize=True,
+ samplerate=args.samplerate,
+ channels=args.channels,
+ workers=args.workers)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/separate.py b/demucs/separate.py
new file mode 100644
index 0000000..3fc7af9
--- /dev/null
+++ b/demucs/separate.py
@@ -0,0 +1,185 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import sys
+from pathlib import Path
+import subprocess
+
+import julius
+import torch as th
+import torchaudio as ta
+
+from .audio import AudioFile, convert_audio_channels
+from .pretrained import is_pretrained, load_pretrained
+from .utils import apply_model, load_model
+
+
+def load_track(track, device, audio_channels, samplerate):
+ errors = {}
+ wav = None
+
+ try:
+ wav = AudioFile(track).read(
+ streams=0,
+ samplerate=samplerate,
+ channels=audio_channels).to(device)
+ except FileNotFoundError:
+ errors['ffmpeg'] = 'Ffmpeg is not installed.'
+ except subprocess.CalledProcessError:
+ errors['ffmpeg'] = 'FFmpeg could not read the file.'
+
+ if wav is None:
+ try:
+ wav, sr = ta.load(str(track))
+ except RuntimeError as err:
+ errors['torchaudio'] = err.args[0]
+ else:
+ wav = convert_audio_channels(wav, audio_channels)
+ wav = wav.to(device)
+ wav = julius.resample_frac(wav, sr, samplerate)
+
+ if wav is None:
+ print(f"Could not load file {track}. "
+ "Maybe it is not a supported file format? ")
+ for backend, error in errors.items():
+ print(f"When trying to load using {backend}, got the following error: {error}")
+ sys.exit(1)
+ return wav
+
+
+def encode_mp3(wav, path, bitrate=320, samplerate=44100, channels=2, verbose=False):
+ try:
+ import lameenc
+ except ImportError:
+ print("Failed to call lame encoder. Maybe it is not installed? "
+ "On windows, run `python.exe -m pip install -U lameenc`, "
+ "on OSX/Linux, run `python3 -m pip install -U lameenc`, "
+ "then try again.", file=sys.stderr)
+ sys.exit(1)
+ encoder = lameenc.Encoder()
+ encoder.set_bit_rate(bitrate)
+ encoder.set_in_sample_rate(samplerate)
+ encoder.set_channels(channels)
+ encoder.set_quality(2) # 2-highest, 7-fastest
+ if not verbose:
+ encoder.silence()
+ wav = wav.transpose(0, 1).numpy()
+ mp3_data = encoder.encode(wav.tobytes())
+ mp3_data += encoder.flush()
+ with open(path, "wb") as f:
+ f.write(mp3_data)
+
+
+def main():
+ parser = argparse.ArgumentParser("demucs.separate",
+ description="Separate the sources for the given tracks")
+ parser.add_argument("tracks", nargs='+', type=Path, default=[], help='Path to tracks')
+ parser.add_argument("-n",
+ "--name",
+ default="demucs_quantized",
+ help="Model name. See README.md for the list of pretrained models. "
+ "Default is demucs_quantized.")
+ parser.add_argument("-v", "--verbose", action="store_true")
+ parser.add_argument("-o",
+ "--out",
+ type=Path,
+ default=Path("separated"),
+ help="Folder where to put extracted tracks. A subfolder "
+ "with the model name will be created.")
+ parser.add_argument("--models",
+ type=Path,
+ default=Path("models"),
+ help="Path to trained models. "
+ "Also used to store downloaded pretrained models")
+ parser.add_argument("-d",
+ "--device",
+ default="cuda" if th.cuda.is_available() else "cpu",
+ help="Device to use, default is cuda if available else cpu")
+ parser.add_argument("--shifts",
+ default=0,
+ type=int,
+ help="Number of random shifts for equivariant stabilization."
+ "Increase separation time but improves quality for Demucs. 10 was used "
+ "in the original paper.")
+ parser.add_argument("--overlap",
+ default=0.25,
+ type=float,
+ help="Overlap between the splits.")
+ parser.add_argument("--no-split",
+ action="store_false",
+ dest="split",
+ default=True,
+ help="Doesn't split audio in chunks. This can use large amounts of memory.")
+ parser.add_argument("--float32",
+ action="store_true",
+ help="Convert the output wavefile to use pcm f32 format instead of s16. "
+ "This should not make a difference if you just plan on listening to the "
+ "audio but might be needed to compute exactly metrics like SDR etc.")
+ parser.add_argument("--int16",
+ action="store_false",
+ dest="float32",
+ help="Opposite of --float32, here for compatibility.")
+ parser.add_argument("--mp3", action="store_true",
+ help="Convert the output wavs to mp3.")
+ parser.add_argument("--mp3-bitrate",
+ default=320,
+ type=int,
+ help="Bitrate of converted mp3.")
+
+ args = parser.parse_args()
+ name = args.name + ".th"
+ model_path = args.models / name
+ if model_path.is_file():
+ model = load_model(model_path)
+ else:
+ if is_pretrained(args.name):
+ model = load_pretrained(args.name)
+ else:
+ print(f"No pre-trained model {args.name}", file=sys.stderr)
+ sys.exit(1)
+ model.to(args.device)
+
+ out = args.out / args.name
+ out.mkdir(parents=True, exist_ok=True)
+ print(f"Separated tracks will be stored in {out.resolve()}")
+ for track in args.tracks:
+ if not track.exists():
+ print(
+ f"File {track} does not exist. If the path contains spaces, "
+ "please try again after surrounding the entire path with quotes \"\".",
+ file=sys.stderr)
+ continue
+ print(f"Separating track {track}")
+ wav = load_track(track, args.device, model.audio_channels, model.samplerate)
+
+ ref = wav.mean(0)
+ wav = (wav - ref.mean()) / ref.std()
+ sources = apply_model(model, wav, shifts=args.shifts, split=args.split,
+ overlap=args.overlap, progress=True)
+ sources = sources * ref.std() + ref.mean()
+
+ track_folder = out / track.name.rsplit(".", 1)[0]
+ track_folder.mkdir(exist_ok=True)
+ for source, name in zip(sources, model.sources):
+ source = source / max(1.01 * source.abs().max(), 1)
+ if args.mp3 or not args.float32:
+ source = (source * 2**15).clamp_(-2**15, 2**15 - 1).short()
+ source = source.cpu()
+ stem = str(track_folder / name)
+ if args.mp3:
+ encode_mp3(source, stem + ".mp3",
+ bitrate=args.mp3_bitrate,
+ samplerate=model.samplerate,
+ channels=model.audio_channels,
+ verbose=args.verbose)
+ else:
+ wavname = str(track_folder / f"{name}.wav")
+ ta.save(wavname, source, sample_rate=model.samplerate)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/tasnet.py b/demucs/tasnet.py
new file mode 100644
index 0000000..ecc1257
--- /dev/null
+++ b/demucs/tasnet.py
@@ -0,0 +1,452 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+# Created on 2018/12
+# Author: Kaituo XU
+# Modified on 2019/11 by Alexandre Defossez, added support for multiple output channels
+# Here is the original license:
+# The MIT License (MIT)
+#
+# Copyright (c) 2018 Kaituo XU
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .utils import capture_init
+
+EPS = 1e-8
+
+
+def overlap_and_add(signal, frame_step):
+ outer_dimensions = signal.size()[:-2]
+ frames, frame_length = signal.size()[-2:]
+
+ subframe_length = math.gcd(frame_length, frame_step) # gcd=Greatest Common Divisor
+ subframe_step = frame_step // subframe_length
+ subframes_per_frame = frame_length // subframe_length
+ output_size = frame_step * (frames - 1) + frame_length
+ output_subframes = output_size // subframe_length
+
+ subframe_signal = signal.view(*outer_dimensions, -1, subframe_length)
+
+ frame = torch.arange(0, output_subframes,
+ device=signal.device).unfold(0, subframes_per_frame, subframe_step)
+ frame = frame.long() # signal may in GPU or CPU
+ frame = frame.contiguous().view(-1)
+
+ result = signal.new_zeros(*outer_dimensions, output_subframes, subframe_length)
+ result.index_add_(-2, frame, subframe_signal)
+ result = result.view(*outer_dimensions, -1)
+ return result
+
+
+class ConvTasNet(nn.Module):
+ @capture_init
+ def __init__(self,
+ sources,
+ N=256,
+ L=20,
+ B=256,
+ H=512,
+ P=3,
+ X=8,
+ R=4,
+ audio_channels=2,
+ norm_type="gLN",
+ causal=False,
+ mask_nonlinear='relu',
+ samplerate=44100,
+ segment_length=44100 * 2 * 4):
+ """
+ Args:
+ sources: list of sources
+ N: Number of filters in autoencoder
+ L: Length of the filters (in samples)
+ B: Number of channels in bottleneck 1 × 1-conv block
+ H: Number of channels in convolutional blocks
+ P: Kernel size in convolutional blocks
+ X: Number of convolutional blocks in each repeat
+ R: Number of repeats
+ norm_type: BN, gLN, cLN
+ causal: causal or non-causal
+ mask_nonlinear: use which non-linear function to generate mask
+ """
+ super(ConvTasNet, self).__init__()
+ # Hyper-parameter
+ self.sources = sources
+ self.C = len(sources)
+ self.N, self.L, self.B, self.H, self.P, self.X, self.R = N, L, B, H, P, X, R
+ self.norm_type = norm_type
+ self.causal = causal
+ self.mask_nonlinear = mask_nonlinear
+ self.audio_channels = audio_channels
+ self.samplerate = samplerate
+ self.segment_length = segment_length
+ # Components
+ self.encoder = Encoder(L, N, audio_channels)
+ self.separator = TemporalConvNet(
+ N, B, H, P, X, R, self.C, norm_type, causal, mask_nonlinear)
+ self.decoder = Decoder(N, L, audio_channels)
+ # init
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_normal_(p)
+
+ def valid_length(self, length):
+ return length
+
+ def forward(self, mixture):
+ """
+ Args:
+ mixture: [M, T], M is batch size, T is #samples
+ Returns:
+ est_source: [M, C, T]
+ """
+ mixture_w = self.encoder(mixture)
+ est_mask = self.separator(mixture_w)
+ est_source = self.decoder(mixture_w, est_mask)
+
+ # T changed after conv1d in encoder, fix it here
+ T_origin = mixture.size(-1)
+ T_conv = est_source.size(-1)
+ est_source = F.pad(est_source, (0, T_origin - T_conv))
+ return est_source
+
+
+class Encoder(nn.Module):
+ """Estimation of the nonnegative mixture weight by a 1-D conv layer.
+ """
+ def __init__(self, L, N, audio_channels):
+ super(Encoder, self).__init__()
+ # Hyper-parameter
+ self.L, self.N = L, N
+ # Components
+ # 50% overlap
+ self.conv1d_U = nn.Conv1d(audio_channels, N, kernel_size=L, stride=L // 2, bias=False)
+
+ def forward(self, mixture):
+ """
+ Args:
+ mixture: [M, T], M is batch size, T is #samples
+ Returns:
+ mixture_w: [M, N, K], where K = (T-L)/(L/2)+1 = 2T/L-1
+ """
+ mixture_w = F.relu(self.conv1d_U(mixture)) # [M, N, K]
+ return mixture_w
+
+
+class Decoder(nn.Module):
+ def __init__(self, N, L, audio_channels):
+ super(Decoder, self).__init__()
+ # Hyper-parameter
+ self.N, self.L = N, L
+ self.audio_channels = audio_channels
+ # Components
+ self.basis_signals = nn.Linear(N, audio_channels * L, bias=False)
+
+ def forward(self, mixture_w, est_mask):
+ """
+ Args:
+ mixture_w: [M, N, K]
+ est_mask: [M, C, N, K]
+ Returns:
+ est_source: [M, C, T]
+ """
+ # D = W * M
+ source_w = torch.unsqueeze(mixture_w, 1) * est_mask # [M, C, N, K]
+ source_w = torch.transpose(source_w, 2, 3) # [M, C, K, N]
+ # S = DV
+ est_source = self.basis_signals(source_w) # [M, C, K, ac * L]
+ m, c, k, _ = est_source.size()
+ est_source = est_source.view(m, c, k, self.audio_channels, -1).transpose(2, 3).contiguous()
+ est_source = overlap_and_add(est_source, self.L // 2) # M x C x ac x T
+ return est_source
+
+
+class TemporalConvNet(nn.Module):
+ def __init__(self, N, B, H, P, X, R, C, norm_type="gLN", causal=False, mask_nonlinear='relu'):
+ """
+ Args:
+ N: Number of filters in autoencoder
+ B: Number of channels in bottleneck 1 × 1-conv block
+ H: Number of channels in convolutional blocks
+ P: Kernel size in convolutional blocks
+ X: Number of convolutional blocks in each repeat
+ R: Number of repeats
+ C: Number of speakers
+ norm_type: BN, gLN, cLN
+ causal: causal or non-causal
+ mask_nonlinear: use which non-linear function to generate mask
+ """
+ super(TemporalConvNet, self).__init__()
+ # Hyper-parameter
+ self.C = C
+ self.mask_nonlinear = mask_nonlinear
+ # Components
+ # [M, N, K] -> [M, N, K]
+ layer_norm = ChannelwiseLayerNorm(N)
+ # [M, N, K] -> [M, B, K]
+ bottleneck_conv1x1 = nn.Conv1d(N, B, 1, bias=False)
+ # [M, B, K] -> [M, B, K]
+ repeats = []
+ for r in range(R):
+ blocks = []
+ for x in range(X):
+ dilation = 2**x
+ padding = (P - 1) * dilation if causal else (P - 1) * dilation // 2
+ blocks += [
+ TemporalBlock(B,
+ H,
+ P,
+ stride=1,
+ padding=padding,
+ dilation=dilation,
+ norm_type=norm_type,
+ causal=causal)
+ ]
+ repeats += [nn.Sequential(*blocks)]
+ temporal_conv_net = nn.Sequential(*repeats)
+ # [M, B, K] -> [M, C*N, K]
+ mask_conv1x1 = nn.Conv1d(B, C * N, 1, bias=False)
+ # Put together
+ self.network = nn.Sequential(layer_norm, bottleneck_conv1x1, temporal_conv_net,
+ mask_conv1x1)
+
+ def forward(self, mixture_w):
+ """
+ Keep this API same with TasNet
+ Args:
+ mixture_w: [M, N, K], M is batch size
+ returns:
+ est_mask: [M, C, N, K]
+ """
+ M, N, K = mixture_w.size()
+ score = self.network(mixture_w) # [M, N, K] -> [M, C*N, K]
+ score = score.view(M, self.C, N, K) # [M, C*N, K] -> [M, C, N, K]
+ if self.mask_nonlinear == 'softmax':
+ est_mask = F.softmax(score, dim=1)
+ elif self.mask_nonlinear == 'relu':
+ est_mask = F.relu(score)
+ else:
+ raise ValueError("Unsupported mask non-linear function")
+ return est_mask
+
+
+class TemporalBlock(nn.Module):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ norm_type="gLN",
+ causal=False):
+ super(TemporalBlock, self).__init__()
+ # [M, B, K] -> [M, H, K]
+ conv1x1 = nn.Conv1d(in_channels, out_channels, 1, bias=False)
+ prelu = nn.PReLU()
+ norm = chose_norm(norm_type, out_channels)
+ # [M, H, K] -> [M, B, K]
+ dsconv = DepthwiseSeparableConv(out_channels, in_channels, kernel_size, stride, padding,
+ dilation, norm_type, causal)
+ # Put together
+ self.net = nn.Sequential(conv1x1, prelu, norm, dsconv)
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, B, K]
+ Returns:
+ [M, B, K]
+ """
+ residual = x
+ out = self.net(x)
+ # TODO: when P = 3 here works fine, but when P = 2 maybe need to pad?
+ return out + residual # look like w/o F.relu is better than w/ F.relu
+ # return F.relu(out + residual)
+
+
+class DepthwiseSeparableConv(nn.Module):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ norm_type="gLN",
+ causal=False):
+ super(DepthwiseSeparableConv, self).__init__()
+ # Use `groups` option to implement depthwise convolution
+ # [M, H, K] -> [M, H, K]
+ depthwise_conv = nn.Conv1d(in_channels,
+ in_channels,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=in_channels,
+ bias=False)
+ if causal:
+ chomp = Chomp1d(padding)
+ prelu = nn.PReLU()
+ norm = chose_norm(norm_type, in_channels)
+ # [M, H, K] -> [M, B, K]
+ pointwise_conv = nn.Conv1d(in_channels, out_channels, 1, bias=False)
+ # Put together
+ if causal:
+ self.net = nn.Sequential(depthwise_conv, chomp, prelu, norm, pointwise_conv)
+ else:
+ self.net = nn.Sequential(depthwise_conv, prelu, norm, pointwise_conv)
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, H, K]
+ Returns:
+ result: [M, B, K]
+ """
+ return self.net(x)
+
+
+class Chomp1d(nn.Module):
+ """To ensure the output length is the same as the input.
+ """
+ def __init__(self, chomp_size):
+ super(Chomp1d, self).__init__()
+ self.chomp_size = chomp_size
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, H, Kpad]
+ Returns:
+ [M, H, K]
+ """
+ return x[:, :, :-self.chomp_size].contiguous()
+
+
+def chose_norm(norm_type, channel_size):
+ """The input of normlization will be (M, C, K), where M is batch size,
+ C is channel size and K is sequence length.
+ """
+ if norm_type == "gLN":
+ return GlobalLayerNorm(channel_size)
+ elif norm_type == "cLN":
+ return ChannelwiseLayerNorm(channel_size)
+ elif norm_type == "id":
+ return nn.Identity()
+ else: # norm_type == "BN":
+ # Given input (M, C, K), nn.BatchNorm1d(C) will accumulate statics
+ # along M and K, so this BN usage is right.
+ return nn.BatchNorm1d(channel_size)
+
+
+# TODO: Use nn.LayerNorm to impl cLN to speed up
+class ChannelwiseLayerNorm(nn.Module):
+ """Channel-wise Layer Normalization (cLN)"""
+ def __init__(self, channel_size):
+ super(ChannelwiseLayerNorm, self).__init__()
+ self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.beta = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ self.gamma.data.fill_(1)
+ self.beta.data.zero_()
+
+ def forward(self, y):
+ """
+ Args:
+ y: [M, N, K], M is batch size, N is channel size, K is length
+ Returns:
+ cLN_y: [M, N, K]
+ """
+ mean = torch.mean(y, dim=1, keepdim=True) # [M, 1, K]
+ var = torch.var(y, dim=1, keepdim=True, unbiased=False) # [M, 1, K]
+ cLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
+ return cLN_y
+
+
+class GlobalLayerNorm(nn.Module):
+ """Global Layer Normalization (gLN)"""
+ def __init__(self, channel_size):
+ super(GlobalLayerNorm, self).__init__()
+ self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.beta = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ self.gamma.data.fill_(1)
+ self.beta.data.zero_()
+
+ def forward(self, y):
+ """
+ Args:
+ y: [M, N, K], M is batch size, N is channel size, K is length
+ Returns:
+ gLN_y: [M, N, K]
+ """
+ # TODO: in torch 1.0, torch.mean() support dim list
+ mean = y.mean(dim=1, keepdim=True).mean(dim=2, keepdim=True) # [M, 1, 1]
+ var = (torch.pow(y - mean, 2)).mean(dim=1, keepdim=True).mean(dim=2, keepdim=True)
+ gLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
+ return gLN_y
+
+
+if __name__ == "__main__":
+ torch.manual_seed(123)
+ M, N, L, T = 2, 3, 4, 12
+ K = 2 * T // L - 1
+ B, H, P, X, R, C, norm_type, causal = 2, 3, 3, 3, 2, 2, "gLN", False
+ mixture = torch.randint(3, (M, T))
+ # test Encoder
+ encoder = Encoder(L, N)
+ encoder.conv1d_U.weight.data = torch.randint(2, encoder.conv1d_U.weight.size())
+ mixture_w = encoder(mixture)
+ print('mixture', mixture)
+ print('U', encoder.conv1d_U.weight)
+ print('mixture_w', mixture_w)
+ print('mixture_w size', mixture_w.size())
+
+ # test TemporalConvNet
+ separator = TemporalConvNet(N, B, H, P, X, R, C, norm_type=norm_type, causal=causal)
+ est_mask = separator(mixture_w)
+ print('est_mask', est_mask)
+
+ # test Decoder
+ decoder = Decoder(N, L)
+ est_mask = torch.randint(2, (B, K, C, N))
+ est_source = decoder(mixture_w, est_mask)
+ print('est_source', est_source)
+
+ # test Conv-TasNet
+ conv_tasnet = ConvTasNet(N, L, B, H, P, X, R, C, norm_type=norm_type)
+ est_source = conv_tasnet(mixture)
+ print('est_source', est_source)
+ print('est_source size', est_source.size())
diff --git a/demucs/test.py b/demucs/test.py
new file mode 100644
index 0000000..4140914
--- /dev/null
+++ b/demucs/test.py
@@ -0,0 +1,109 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import gzip
+import sys
+from concurrent import futures
+
+import musdb
+import museval
+import torch as th
+import tqdm
+from scipy.io import wavfile
+from torch import distributed
+
+from .audio import convert_audio
+from .utils import apply_model
+
+
+def evaluate(model,
+ musdb_path,
+ eval_folder,
+ workers=2,
+ device="cpu",
+ rank=0,
+ save=False,
+ shifts=0,
+ split=False,
+ overlap=0.25,
+ is_wav=False,
+ world_size=1):
+ """
+ Evaluate model using museval. Run the model
+ on a single GPU, the bottleneck being the call to museval.
+ """
+
+ output_dir = eval_folder / "results"
+ output_dir.mkdir(exist_ok=True, parents=True)
+ json_folder = eval_folder / "results/test"
+ json_folder.mkdir(exist_ok=True, parents=True)
+
+ # we load tracks from the original musdb set
+ test_set = musdb.DB(musdb_path, subsets=["test"], is_wav=is_wav)
+ src_rate = 44100 # hardcoded for now...
+
+ for p in model.parameters():
+ p.requires_grad = False
+ p.grad = None
+
+ pendings = []
+ with futures.ProcessPoolExecutor(workers or 1) as pool:
+ for index in tqdm.tqdm(range(rank, len(test_set), world_size), file=sys.stdout):
+ track = test_set.tracks[index]
+
+ out = json_folder / f"{track.name}.json.gz"
+ if out.exists():
+ continue
+
+ mix = th.from_numpy(track.audio).t().float()
+ ref = mix.mean(dim=0) # mono mixture
+ mix = (mix - ref.mean()) / ref.std()
+ mix = convert_audio(mix, src_rate, model.samplerate, model.audio_channels)
+ estimates = apply_model(model, mix.to(device),
+ shifts=shifts, split=split, overlap=overlap)
+ estimates = estimates * ref.std() + ref.mean()
+
+ estimates = estimates.transpose(1, 2)
+ references = th.stack(
+ [th.from_numpy(track.targets[name].audio).t() for name in model.sources])
+ references = convert_audio(references, src_rate,
+ model.samplerate, model.audio_channels)
+ references = references.transpose(1, 2).numpy()
+ estimates = estimates.cpu().numpy()
+ win = int(1. * model.samplerate)
+ hop = int(1. * model.samplerate)
+ if save:
+ folder = eval_folder / "wav/test" / track.name
+ folder.mkdir(exist_ok=True, parents=True)
+ for name, estimate in zip(model.sources, estimates):
+ wavfile.write(str(folder / (name + ".wav")), 44100, estimate)
+
+ if workers:
+ pendings.append((track.name, pool.submit(
+ museval.evaluate, references, estimates, win=win, hop=hop)))
+ else:
+ pendings.append((track.name, museval.evaluate(
+ references, estimates, win=win, hop=hop)))
+ del references, mix, estimates, track
+
+ for track_name, pending in tqdm.tqdm(pendings, file=sys.stdout):
+ if workers:
+ pending = pending.result()
+ sdr, isr, sir, sar = pending
+ track_store = museval.TrackStore(win=44100, hop=44100, track_name=track_name)
+ for idx, target in enumerate(model.sources):
+ values = {
+ "SDR": sdr[idx].tolist(),
+ "SIR": sir[idx].tolist(),
+ "ISR": isr[idx].tolist(),
+ "SAR": sar[idx].tolist()
+ }
+
+ track_store.add_target(target_name=target, values=values)
+ json_path = json_folder / f"{track_name}.json.gz"
+ gzip.open(json_path, "w").write(track_store.json.encode('utf-8'))
+ if world_size > 1:
+ distributed.barrier()
diff --git a/demucs/utils.py b/demucs/utils.py
new file mode 100644
index 0000000..4364184
--- /dev/null
+++ b/demucs/utils.py
@@ -0,0 +1,323 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import errno
+import functools
+import hashlib
+import inspect
+import io
+import os
+import random
+import socket
+import tempfile
+import warnings
+import zlib
+from contextlib import contextmanager
+
+from diffq import UniformQuantizer, DiffQuantizer
+import torch as th
+import tqdm
+from torch import distributed
+from torch.nn import functional as F
+
+
+def center_trim(tensor, reference):
+ """
+ Center trim `tensor` with respect to `reference`, along the last dimension.
+ `reference` can also be a number, representing the length to trim to.
+ If the size difference != 0 mod 2, the extra sample is removed on the right side.
+ """
+ if hasattr(reference, "size"):
+ reference = reference.size(-1)
+ delta = tensor.size(-1) - reference
+ if delta < 0:
+ raise ValueError("tensor must be larger than reference. " f"Delta is {delta}.")
+ if delta:
+ tensor = tensor[..., delta // 2:-(delta - delta // 2)]
+ return tensor
+
+
+def average_metric(metric, count=1.):
+ """
+ Average `metric` which should be a float across all hosts. `count` should be
+ the weight for this particular host (i.e. number of examples).
+ """
+ metric = th.tensor([count, count * metric], dtype=th.float32, device='cuda')
+ distributed.all_reduce(metric, op=distributed.ReduceOp.SUM)
+ return metric[1].item() / metric[0].item()
+
+
+def free_port(host='', low=20000, high=40000):
+ """
+ Return a port number that is most likely free.
+ This could suffer from a race condition although
+ it should be quite rare.
+ """
+ sock = socket.socket()
+ while True:
+ port = random.randint(low, high)
+ try:
+ sock.bind((host, port))
+ except OSError as error:
+ if error.errno == errno.EADDRINUSE:
+ continue
+ raise
+ return port
+
+
+def sizeof_fmt(num, suffix='B'):
+ """
+ Given `num` bytes, return human readable size.
+ Taken from https://stackoverflow.com/a/1094933
+ """
+ for unit in ['', 'Ki', 'Mi', 'Gi', 'Ti', 'Pi', 'Ei', 'Zi']:
+ if abs(num) < 1024.0:
+ return "%3.1f%s%s" % (num, unit, suffix)
+ num /= 1024.0
+ return "%.1f%s%s" % (num, 'Yi', suffix)
+
+
+def human_seconds(seconds, display='.2f'):
+ """
+ Given `seconds` seconds, return human readable duration.
+ """
+ value = seconds * 1e6
+ ratios = [1e3, 1e3, 60, 60, 24]
+ names = ['us', 'ms', 's', 'min', 'hrs', 'days']
+ last = names.pop(0)
+ for name, ratio in zip(names, ratios):
+ if value / ratio < 0.3:
+ break
+ value /= ratio
+ last = name
+ return f"{format(value, display)} {last}"
+
+
+class TensorChunk:
+ def __init__(self, tensor, offset=0, length=None):
+ total_length = tensor.shape[-1]
+ assert offset >= 0
+ assert offset < total_length
+
+ if length is None:
+ length = total_length - offset
+ else:
+ length = min(total_length - offset, length)
+
+ self.tensor = tensor
+ self.offset = offset
+ self.length = length
+ self.device = tensor.device
+
+ @property
+ def shape(self):
+ shape = list(self.tensor.shape)
+ shape[-1] = self.length
+ return shape
+
+ def padded(self, target_length):
+ delta = target_length - self.length
+ total_length = self.tensor.shape[-1]
+ assert delta >= 0
+
+ start = self.offset - delta // 2
+ end = start + target_length
+
+ correct_start = max(0, start)
+ correct_end = min(total_length, end)
+
+ pad_left = correct_start - start
+ pad_right = end - correct_end
+
+ out = F.pad(self.tensor[..., correct_start:correct_end], (pad_left, pad_right))
+ assert out.shape[-1] == target_length
+ return out
+
+
+def tensor_chunk(tensor_or_chunk):
+ if isinstance(tensor_or_chunk, TensorChunk):
+ return tensor_or_chunk
+ else:
+ assert isinstance(tensor_or_chunk, th.Tensor)
+ return TensorChunk(tensor_or_chunk)
+
+
+def apply_model(model, mix, shifts=None, split=False,
+ overlap=0.25, transition_power=1., progress=False):
+ """
+ Apply model to a given mixture.
+
+ Args:
+ shifts (int): if > 0, will shift in time `mix` by a random amount between 0 and 0.5 sec
+ and apply the oppositve shift to the output. This is repeated `shifts` time and
+ all predictions are averaged. This effectively makes the model time equivariant
+ and improves SDR by up to 0.2 points.
+ split (bool): if True, the input will be broken down in 8 seconds extracts
+ and predictions will be performed individually on each and concatenated.
+ Useful for model with large memory footprint like Tasnet.
+ progress (bool): if True, show a progress bar (requires split=True)
+ """
+ assert transition_power >= 1, "transition_power < 1 leads to weird behavior."
+ device = mix.device
+ channels, length = mix.shape
+ if split:
+ out = th.zeros(len(model.sources), channels, length, device=device)
+ sum_weight = th.zeros(length, device=device)
+ segment = model.segment_length
+ stride = int((1 - overlap) * segment)
+ offsets = range(0, length, stride)
+ scale = stride / model.samplerate
+ if progress:
+ offsets = tqdm.tqdm(offsets, unit_scale=scale, ncols=120, unit='seconds')
+ # We start from a triangle shaped weight, with maximal weight in the middle
+ # of the segment. Then we normalize and take to the power `transition_power`.
+ # Large values of transition power will lead to sharper transitions.
+ weight = th.cat([th.arange(1, segment // 2 + 1),
+ th.arange(segment - segment // 2, 0, -1)]).to(device)
+ assert len(weight) == segment
+ # If the overlap < 50%, this will translate to linear transition when
+ # transition_power is 1.
+ weight = (weight / weight.max())**transition_power
+ for offset in offsets:
+ chunk = TensorChunk(mix, offset, segment)
+ chunk_out = apply_model(model, chunk, shifts=shifts)
+ chunk_length = chunk_out.shape[-1]
+ out[..., offset:offset + segment] += weight[:chunk_length] * chunk_out
+ sum_weight[offset:offset + segment] += weight[:chunk_length]
+ offset += segment
+ assert sum_weight.min() > 0
+ out /= sum_weight
+ return out
+ elif shifts:
+ max_shift = int(0.5 * model.samplerate)
+ mix = tensor_chunk(mix)
+ padded_mix = mix.padded(length + 2 * max_shift)
+ out = 0
+ for _ in range(shifts):
+ offset = random.randint(0, max_shift)
+ shifted = TensorChunk(padded_mix, offset, length + max_shift - offset)
+ shifted_out = apply_model(model, shifted)
+ out += shifted_out[..., max_shift - offset:]
+ out /= shifts
+ return out
+ else:
+ valid_length = model.valid_length(length)
+ mix = tensor_chunk(mix)
+ padded_mix = mix.padded(valid_length)
+ with th.no_grad():
+ out = model(padded_mix.unsqueeze(0))[0]
+ return center_trim(out, length)
+
+
+@contextmanager
+def temp_filenames(count, delete=True):
+ names = []
+ try:
+ for _ in range(count):
+ names.append(tempfile.NamedTemporaryFile(delete=False).name)
+ yield names
+ finally:
+ if delete:
+ for name in names:
+ os.unlink(name)
+
+
+def get_quantizer(model, args, optimizer=None):
+ quantizer = None
+ if args.diffq:
+ quantizer = DiffQuantizer(
+ model, min_size=args.q_min_size, group_size=8)
+ if optimizer is not None:
+ quantizer.setup_optimizer(optimizer)
+ elif args.qat:
+ quantizer = UniformQuantizer(
+ model, bits=args.qat, min_size=args.q_min_size)
+ return quantizer
+
+
+def load_model(path, strict=False):
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ load_from = path
+ package = th.load(load_from, 'cpu')
+
+ klass = package["klass"]
+ args = package["args"]
+ kwargs = package["kwargs"]
+
+ if strict:
+ model = klass(*args, **kwargs)
+ else:
+ sig = inspect.signature(klass)
+ for key in list(kwargs):
+ if key not in sig.parameters:
+ warnings.warn("Dropping inexistant parameter " + key)
+ del kwargs[key]
+ model = klass(*args, **kwargs)
+
+ state = package["state"]
+ training_args = package["training_args"]
+ quantizer = get_quantizer(model, training_args)
+
+ set_state(model, quantizer, state)
+ return model
+
+
+def get_state(model, quantizer):
+ if quantizer is None:
+ state = {k: p.data.to('cpu') for k, p in model.state_dict().items()}
+ else:
+ state = quantizer.get_quantized_state()
+ buf = io.BytesIO()
+ th.save(state, buf)
+ state = {'compressed': zlib.compress(buf.getvalue())}
+ return state
+
+
+def set_state(model, quantizer, state):
+ if quantizer is None:
+ model.load_state_dict(state)
+ else:
+ buf = io.BytesIO(zlib.decompress(state["compressed"]))
+ state = th.load(buf, "cpu")
+ quantizer.restore_quantized_state(state)
+
+ return state
+
+
+def save_state(state, path):
+ buf = io.BytesIO()
+ th.save(state, buf)
+ sig = hashlib.sha256(buf.getvalue()).hexdigest()[:8]
+
+ path = path.parent / (path.stem + "-" + sig + path.suffix)
+ path.write_bytes(buf.getvalue())
+
+
+def save_model(model, quantizer, training_args, path):
+ args, kwargs = model._init_args_kwargs
+ klass = model.__class__
+
+ state = get_state(model, quantizer)
+
+ save_to = path
+ package = {
+ 'klass': klass,
+ 'args': args,
+ 'kwargs': kwargs,
+ 'state': state,
+ 'training_args': training_args,
+ }
+ th.save(package, save_to)
+
+
+def capture_init(init):
+ @functools.wraps(init)
+ def __init__(self, *args, **kwargs):
+ self._init_args_kwargs = (args, kwargs)
+ init(self, *args, **kwargs)
+
+ return __init__
diff --git a/demucs/wav.py b/demucs/wav.py
new file mode 100644
index 0000000..a65c3b2
--- /dev/null
+++ b/demucs/wav.py
@@ -0,0 +1,174 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from collections import OrderedDict
+import hashlib
+import math
+import json
+from pathlib import Path
+
+import julius
+import torch as th
+from torch import distributed
+import torchaudio as ta
+from torch.nn import functional as F
+
+from .audio import convert_audio_channels
+from .compressed import get_musdb_tracks
+
+MIXTURE = "mixture"
+EXT = ".wav"
+
+
+def _track_metadata(track, sources):
+ track_length = None
+ track_samplerate = None
+ for source in sources + [MIXTURE]:
+ file = track / f"{source}{EXT}"
+ info = ta.info(str(file))
+ length = info.num_frames
+ if track_length is None:
+ track_length = length
+ track_samplerate = info.sample_rate
+ elif track_length != length:
+ raise ValueError(
+ f"Invalid length for file {file}: "
+ f"expecting {track_length} but got {length}.")
+ elif info.sample_rate != track_samplerate:
+ raise ValueError(
+ f"Invalid sample rate for file {file}: "
+ f"expecting {track_samplerate} but got {info.sample_rate}.")
+ if source == MIXTURE:
+ wav, _ = ta.load(str(file))
+ wav = wav.mean(0)
+ mean = wav.mean().item()
+ std = wav.std().item()
+
+ return {"length": length, "mean": mean, "std": std, "samplerate": track_samplerate}
+
+
+def _build_metadata(path, sources):
+ meta = {}
+ path = Path(path)
+ for file in path.iterdir():
+ meta[file.name] = _track_metadata(file, sources)
+ return meta
+
+
+class Wavset:
+ def __init__(
+ self,
+ root, metadata, sources,
+ length=None, stride=None, normalize=True,
+ samplerate=44100, channels=2):
+ """
+ Waveset (or mp3 set for that matter). Can be used to train
+ with arbitrary sources. Each track should be one folder inside of `path`.
+ The folder should contain files named `{source}.{ext}`.
+ Files will be grouped according to `sources` (each source is a list of
+ filenames).
+
+ Sample rate and channels will be converted on the fly.
+
+ `length` is the sample size to extract (in samples, not duration).
+ `stride` is how many samples to move by between each example.
+ """
+ self.root = Path(root)
+ self.metadata = OrderedDict(metadata)
+ self.length = length
+ self.stride = stride or length
+ self.normalize = normalize
+ self.sources = sources
+ self.channels = channels
+ self.samplerate = samplerate
+ self.num_examples = []
+ for name, meta in self.metadata.items():
+ track_length = int(self.samplerate * meta['length'] / meta['samplerate'])
+ if length is None or track_length < length:
+ examples = 1
+ else:
+ examples = int(math.ceil((track_length - self.length) / self.stride) + 1)
+ self.num_examples.append(examples)
+
+ def __len__(self):
+ return sum(self.num_examples)
+
+ def get_file(self, name, source):
+ return self.root / name / f"{source}{EXT}"
+
+ def __getitem__(self, index):
+ for name, examples in zip(self.metadata, self.num_examples):
+ if index >= examples:
+ index -= examples
+ continue
+ meta = self.metadata[name]
+ num_frames = -1
+ offset = 0
+ if self.length is not None:
+ offset = int(math.ceil(
+ meta['samplerate'] * self.stride * index / self.samplerate))
+ num_frames = int(math.ceil(
+ meta['samplerate'] * self.length / self.samplerate))
+ wavs = []
+ for source in self.sources:
+ file = self.get_file(name, source)
+ wav, _ = ta.load(str(file), frame_offset=offset, num_frames=num_frames)
+ wav = convert_audio_channels(wav, self.channels)
+ wavs.append(wav)
+
+ example = th.stack(wavs)
+ example = julius.resample_frac(example, meta['samplerate'], self.samplerate)
+ if self.normalize:
+ example = (example - meta['mean']) / meta['std']
+ if self.length:
+ example = example[..., :self.length]
+ example = F.pad(example, (0, self.length - example.shape[-1]))
+ return example
+
+
+def get_wav_datasets(args, samples, sources):
+ sig = hashlib.sha1(str(args.wav).encode()).hexdigest()[:8]
+ metadata_file = args.metadata / (sig + ".json")
+ train_path = args.wav / "train"
+ valid_path = args.wav / "valid"
+ if not metadata_file.is_file() and args.rank == 0:
+ train = _build_metadata(train_path, sources)
+ valid = _build_metadata(valid_path, sources)
+ json.dump([train, valid], open(metadata_file, "w"))
+ if args.world_size > 1:
+ distributed.barrier()
+ train, valid = json.load(open(metadata_file))
+ train_set = Wavset(train_path, train, sources,
+ length=samples, stride=args.data_stride,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ valid_set = Wavset(valid_path, valid, [MIXTURE] + sources,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ return train_set, valid_set
+
+
+def get_musdb_wav_datasets(args, samples, sources):
+ metadata_file = args.metadata / "musdb_wav.json"
+ root = args.musdb / "train"
+ if not metadata_file.is_file() and args.rank == 0:
+ metadata = _build_metadata(root, sources)
+ json.dump(metadata, open(metadata_file, "w"))
+ if args.world_size > 1:
+ distributed.barrier()
+ metadata = json.load(open(metadata_file))
+
+ train_tracks = get_musdb_tracks(args.musdb, is_wav=True, subsets=["train"], split="train")
+ metadata_train = {name: meta for name, meta in metadata.items() if name in train_tracks}
+ metadata_valid = {name: meta for name, meta in metadata.items() if name not in train_tracks}
+ train_set = Wavset(root, metadata_train, sources,
+ length=samples, stride=args.data_stride,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ valid_set = Wavset(root, metadata_valid, [MIXTURE] + sources,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ return train_set, valid_set
diff --git a/diffq/__init__.py b/diffq/__init__.py
new file mode 100644
index 0000000..2b997ee
--- /dev/null
+++ b/diffq/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+# flake8: noqa
+"""
+This package implements different quantization strategies:
+
+- `diffq.uniform.UniformQuantizer`: classic uniform quantization over n bits.
+- `diffq.diffq.DiffQuantizer`: differentiable quantizer based on scaled noise injection.
+
+Also, do check `diffq.base.BaseQuantizer` for the common methods of all Quantizers.
+"""
+
+from .uniform import UniformQuantizer
+from .diffq import DiffQuantizer
diff --git a/diffq/base.py b/diffq/base.py
new file mode 100644
index 0000000..9bd5276
--- /dev/null
+++ b/diffq/base.py
@@ -0,0 +1,262 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from dataclasses import dataclass
+from concurrent import futures
+from fnmatch import fnmatch
+from functools import partial
+import io
+import math
+from multiprocessing import cpu_count
+import typing as tp
+import zlib
+
+import torch
+
+
+class BaseQuantizer:
+ @dataclass
+ class _QuantizedParam:
+ name: str
+ param: torch.nn.Parameter
+ module: torch.nn.Module
+ # If a Parameter is used multiple times, `other` can be used
+ # to share state between the different Quantizers
+ other: tp.Optional[tp.Any]
+
+ def __init__(self, model: torch.nn.Module, min_size: float = 0.01, float16: bool = False,
+ exclude: tp.Optional[tp.List[str]] = [], detect_bound: bool = True):
+ self.model = model
+ self.min_size = min_size
+ self.float16 = float16
+ self.exclude = exclude
+ self.detect_bound = detect_bound
+ self._quantized = False
+ self._pre_handle = self.model.register_forward_pre_hook(self._forward_pre_hook)
+ self._post_handle = self.model.register_forward_hook(self._forward_hook)
+
+ self._quantized_state = None
+ self._qparams = []
+ self._float16 = []
+ self._others = []
+ self._rnns = []
+
+ self._saved = []
+
+ self._find_params()
+
+ def _find_params(self):
+ min_params = self.min_size * 2**20 // 4
+ previous = {}
+ for module_name, module in self.model.named_modules():
+ if isinstance(module, torch.nn.RNNBase):
+ self._rnns.append(module)
+ for name, param in list(module.named_parameters(recurse=False)):
+ full_name = f"{module_name}.{name}"
+ matched = False
+ for pattern in self.exclude:
+ if fnmatch(full_name, pattern) or fnmatch(name, pattern):
+ matched = True
+ break
+
+ if param.numel() <= min_params or matched:
+ if id(param) in previous:
+ continue
+ if self.detect_bound:
+ previous[id(param)] = None
+ if self.float16:
+ self._float16.append(param)
+ else:
+ self._others.append(param)
+ else:
+ qparam = self._register_param(name, param, module, previous.get(id(param)))
+ if self.detect_bound:
+ previous[id(param)] = qparam
+ self._qparams.append(qparam)
+
+ def _register_param(self, name, param, module, other):
+ return self.__class__._QuantizedParam(name, param, module, other)
+
+ def _forward_pre_hook(self, module, input):
+ if self.model.training:
+ self._quantized_state = None
+ if self._quantized:
+ self.unquantize()
+ if self._pre_forward_train():
+ self._fix_rnns()
+ else:
+ self.quantize()
+
+ def _forward_hook(self, module, input, output):
+ if self.model.training:
+ if self._post_forward_train():
+ self._fix_rnns(flatten=False) # Hacky, next forward will flatten
+
+ def quantize(self, save=True):
+ """
+ Immediately apply quantization to the model parameters.
+ If `save` is True, save a copy of the unquantized parameters, that can be
+ restored with `unquantize()`.
+ """
+ if self._quantized:
+ return
+ if save:
+ self._saved = [qp.param.data.to('cpu', copy=True)
+ for qp in self._qparams if qp.other is None]
+ self.restore_quantized_state(self.get_quantized_state())
+ self._quantized = True
+ self._fix_rnns()
+
+ def unquantize(self):
+ """
+ Revert a previous call to `quantize()`.
+ """
+ if not self._quantized:
+ raise RuntimeError("Can only be called on a quantized model.")
+ if not self._saved:
+ raise RuntimeError("Nothing to restore.")
+ for qparam in self._qparams:
+ if qparam.other is None:
+ qparam.param.data[:] = self._saved.pop(0)
+ assert len(self._saved) == 0
+ self._quantized = False
+ self._fix_rnns()
+
+ def _pre_forward_train(self) -> bool:
+ """
+ Called once before each forward for continuous quantization.
+ Should return True if parameters were changed.
+ """
+ return False
+
+ def _post_forward_train(self) -> bool:
+ """
+ Called once after each forward (to restore state for instance).
+ Should return True if parameters were changed.
+ """
+ return False
+
+ def _fix_rnns(self, flatten=True):
+ """
+ To be called after quantization happened to fix RNNs.
+ """
+ for rnn in self._rnns:
+ rnn._flat_weights = [
+ (lambda wn: getattr(rnn, wn) if hasattr(rnn, wn) else None)(wn)
+ for wn in rnn._flat_weights_names]
+ if flatten:
+ rnn.flatten_parameters()
+
+ def get_quantized_state(self):
+ """
+ Returns sufficient quantized information to rebuild the model state.
+
+ ..Note::
+ To achieve maximum compression, you should compress this with
+ gzip or other, as quantized weights are not optimally coded!
+ """
+ if self._quantized_state is None:
+ self._quantized_state = self._get_quantized_state()
+ return self._quantized_state
+
+ def _get_quantized_state(self):
+ """
+ Actual implementation for `get_quantized_state`.
+ """
+ float16_params = []
+ for p in self._float16:
+ q = p.data.half()
+ float16_params.append(q)
+
+ return {
+ "quantized": [self._quantize_param(qparam) for qparam in self._qparams
+ if qparam.other is None],
+ "float16": float16_params,
+ "others": [p.data.clone() for p in self._others],
+ }
+
+ def _quantize_param(self, qparam: _QuantizedParam) -> tp.Any:
+ """
+ To be overriden.
+ """
+ raise NotImplementedError()
+
+ def _unquantize_param(self, qparam: _QuantizedParam, quantized: tp.Any) -> torch.Tensor:
+ """
+ To be overriden.
+ """
+ raise NotImplementedError()
+
+ def restore_quantized_state(self, state) -> None:
+ """
+ Restore the state of the model from the quantized state.
+ """
+ for p, q in zip(self._float16, state["float16"]):
+ p.data[:] = q.to(p)
+
+ for p, q in zip(self._others, state["others"]):
+ p.data[:] = q
+
+ remaining = list(state["quantized"])
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ # Only unquantize first appearance of nn.Parameter.
+ continue
+ quantized = remaining.pop(0)
+ qparam.param.data[:] = self._unquantize_param(qparam, quantized)
+ self._fix_rnns()
+
+ def detach(self) -> None:
+ """
+ Detach from the model, removes hooks and anything else.
+ """
+ self._pre_handle.remove()
+ self._post_handle.remove()
+
+ def model_size(self) -> torch.Tensor:
+ """
+ Returns an estimate of the quantized model size.
+ """
+ total = torch.tensor(0.)
+ for p in self._float16:
+ total += 16 * p.numel()
+ for p in self._others:
+ total += 32 * p.numel()
+ return total / 2**20 / 8 # bits to MegaBytes
+
+ def true_model_size(self) -> float:
+ """
+ Return the true quantized model size, in MB, without extra
+ compression.
+ """
+ return self.model_size().item()
+
+ def compressed_model_size(self, compress_level=-1, num_workers=8) -> float:
+ """
+ Return the compressed quantized model size, in MB.
+
+ Args:
+ compress_level (int): compression level used with zlib,
+ see `zlib.compress` for details.
+ num_workers (int): will split the final big byte representation in that
+ many chunks processed in parallels.
+ """
+ out = io.BytesIO()
+ torch.save(self.get_quantized_state(), out)
+ ms = _parallel_compress_len(out.getvalue(), compress_level, num_workers)
+ return ms / 2 ** 20
+
+
+def _compress_len(data, compress_level):
+ return len(zlib.compress(data, level=compress_level))
+
+
+def _parallel_compress_len(data, compress_level, num_workers):
+ num_workers = min(cpu_count(), num_workers)
+ chunk_size = int(math.ceil(len(data) / num_workers))
+ chunks = [data[offset:offset + chunk_size] for offset in range(0, len(data), chunk_size)]
+ with futures.ProcessPoolExecutor(num_workers) as pool:
+ return sum(pool.map(partial(_compress_len, compress_level=compress_level), chunks))
diff --git a/diffq/diffq.py b/diffq/diffq.py
new file mode 100644
index 0000000..b475ec7
--- /dev/null
+++ b/diffq/diffq.py
@@ -0,0 +1,286 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+"""
+Differentiable quantizer based on scaled noise injection.
+"""
+from dataclasses import dataclass
+import math
+import typing as tp
+
+import torch
+
+from .base import BaseQuantizer
+from .uniform import uniform_quantize, uniform_unquantize
+from .utils import simple_repr
+
+
+class DiffQuantizer(BaseQuantizer):
+ @dataclass
+ class _QuantizedParam(BaseQuantizer._QuantizedParam):
+ logit: torch.nn.Parameter
+
+ def __init__(self, model: torch.nn.Module, min_size: float = 0.01, float16: bool = False,
+ group_size: int = 1, min_bits: float = 2, max_bits: float = 15,
+ param="bits", noise="gaussian",
+ init_bits: float = 8, extra_bits: float = 0, suffix: str = "_diffq",
+ exclude: tp.List[str] = [], detect_bound: bool = True):
+ """
+ Differentiable quantizer based on scaled noise injection.
+ For every parameter `p` in the model, this introduces a number of bits parameter
+ `b` with the same dimensions (when group_size = 1).
+ Before each forward, `p` is replaced by `p + U`
+ with U uniform iid noise with range [-d/2, d/2], with `d` the uniform quantization
+ step for `b` bits.
+ This noise approximates the quantization noise in a differentiable manner, both
+ with respect to the unquantized parameter `p` and the number of bits `b`.
+
+ At eveluation (as detected with `model.eval()`), the model is replaced
+ by its true quantized version, and restored when going back to training.
+
+ When doing actual quantization (for serialization, or evaluation),
+ the number of bits is rounded to the nearest integer, and needs to be stored along.
+ This will cost a few bits per dimension. To reduce this cost, one can use `group_size`,
+ which will use a single noise level for multiple weight entries.
+
+ You can use the `DiffQuantizer.model_size` method to get a differentiable estimate of the
+ model size in MB. You can then use this estimate as a penalty in your training loss.
+
+ Args:
+ model (torch.nn.Module): model to quantize
+ min_size (float): minimum size in MB of a parameter to be quantized.
+ float16 (bool): if a layer is smaller than min_size, should we still do float16?
+ group_size (int): weight entries are groupped together to reduce the number
+ of noise scales to store. This should divide the size of all parameters
+ bigger than min_size.
+ min_bits (float): minimal number of bits.
+ max_bits (float): maximal number of bits.
+ init_bits (float): initial number of bits.
+ extra_bits (float): extra bits to add for actual quantization (before roundoff).
+ suffix (str): suffix used for the name of the extra noise scale parameters.
+ exclude (list[str]): list of patterns used to match parameters to exclude.
+ For instance `['bias']` to exclude all bias terms.
+ detect_bound (bool): if True, will detect bound parameters and reuse
+ the same quantized tensor for both, as well as the same number of bits.
+
+ ..Warning::
+ You must call `model.training()` and `model.eval()` for `DiffQuantizer` work properly.
+
+ """
+ self.group_size = group_size
+ self.min_bits = min_bits
+ self.max_bits = max_bits
+ self.init_bits = init_bits
+ self.extra_bits = extra_bits
+ self.suffix = suffix
+ self.param = param
+ self.noise = noise
+ assert noise in ["gaussian", "uniform"]
+ self._optimizer_setup = False
+
+ self._min_noise = 1 / (2 ** self.max_bits - 1)
+ self._max_noise = 1 / (2 ** self.min_bits - 1)
+
+ assert group_size >= 0
+ assert min_bits < init_bits < max_bits, \
+ "init_bits must be between min_bits and max_bits excluded3"
+
+ for name, _ in model.named_parameters():
+ if name.endswith(suffix):
+ raise RuntimeError("The model already has some noise scales parameters, "
+ "maybe you used twice a DiffQuantizer on the same model?.")
+
+ super().__init__(model, min_size, float16, exclude, detect_bound)
+
+ def _get_bits(self, logit: torch.Tensor):
+ if self.param == "noise":
+ return torch.log2(1 + 1 / self._get_noise_scale(logit))
+ else:
+ t = torch.sigmoid(logit)
+ return self.max_bits * t + (1 - t) * self.min_bits
+
+ def _get_noise_scale(self, logit: torch.Tensor):
+ if self.param == "noise":
+ t = torch.sigmoid(logit)
+ return torch.exp(t * math.log(self._min_noise) + (1 - t) * math.log(self._max_noise))
+ else:
+ return 1 / (2 ** self._get_bits(logit) - 1)
+
+ def _register_param(self, name, param, module, other):
+ if other is not None:
+ return self.__class__._QuantizedParam(
+ name=name, param=param, module=module, logit=other.logit, other=other)
+ assert self.group_size == 0 or param.numel() % self.group_size == 0
+ # we want the initial number of bits to be init_bits.
+ if self.param == "noise":
+ noise_scale = 1 / (2 ** self.init_bits - 1)
+ t = (math.log(noise_scale) - math.log(self._max_noise)) / (
+ math.log(self._min_noise) - math.log(self._max_noise))
+ else:
+ t = (self.init_bits - self.min_bits) / (self.max_bits - self.min_bits)
+ assert 0 < t < 1
+ logit = torch.logit(torch.tensor(float(t)))
+ assert abs(self._get_bits(logit) - self.init_bits) < 1e-5
+ if self.group_size > 0:
+ nparam = param.numel() // self.group_size
+ else:
+ nparam = 1
+ logit = torch.nn.Parameter(
+ torch.full(
+ (nparam,),
+ logit,
+ device=param.device))
+ module.register_parameter(name + self.suffix, logit)
+ return self.__class__._QuantizedParam(
+ name=name, param=param, module=module, logit=logit, other=None)
+
+ def clear_optimizer(self, optimizer: torch.optim.Optimizer):
+ params = [qp.logit for qp in self._qparams]
+
+ for group in optimizer.param_groups:
+ new_params = []
+ for q in list(group["params"]):
+ matched = False
+ for p in params:
+ if p is q:
+ matched = True
+ if not matched:
+ new_params.append(q)
+ group["params"][:] = new_params
+
+ def setup_optimizer(self, optimizer: torch.optim.Optimizer,
+ lr: float = 1e-3, **kwargs):
+ """
+ Setup the optimizer to tune the number of bits. In particular, this will deactivate
+ weight decay for the bits parameters.
+
+ Args:
+ optimizer (torch.Optimizer): optimizer to use.
+ lr (float): specific learning rate for the bits parameters. 1e-3
+ is perfect for Adam.,w
+ kwargs (dict): overrides for other optimization parameters for the bits.
+ """
+ assert not self._optimizer_setup
+ self._optimizer_setup = True
+
+ params = [qp.logit for qp in self._qparams]
+
+ for group in optimizer.param_groups:
+ for q in list(group["params"]):
+ for p in params:
+ if p is q:
+ raise RuntimeError("You should create the optimizer "
+ "before the quantizer!")
+
+ group = {"params": params, "lr": lr, "weight_decay": 0}
+ group.update(kwargs)
+ optimizer.add_param_group(group)
+
+ def no_optimizer(self):
+ """
+ Call this if you do not want to use an optimizer.
+ """
+ self._optimizer_setup = True
+
+ def check_unused(self):
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ continue
+ grad = qparam.param.grad
+ if grad is None or (grad == 0).all():
+ if qparam.logit.grad is not None:
+ qparam.logit.grad.data.zero_()
+
+ def model_size(self, exact=False):
+ """
+ Differentiable estimate of the model size.
+ The size is returned in MB.
+
+ If `exact` is True, then the output is no longer differentiable but
+ reflect exactly an achievable size, even without compression,
+ i.e.same as returned by `naive_model_size()`.
+ """
+ total = super().model_size()
+ subtotal = 0
+ for qparam in self._qparams:
+ # only count the first appearance of a Parameter
+ if qparam.other is not None:
+ continue
+ bits = self.extra_bits + self._get_bits(qparam.logit)
+ if exact:
+ bits = bits.round().clamp(1, 15)
+ if self.group_size == 0:
+ group_size = qparam.param.numel()
+ else:
+ group_size = self.group_size
+ subtotal += group_size * bits.sum()
+ subtotal += 2 * 32 # param scale
+
+ # Number of bits to represent each number of bits
+ bits_bits = math.ceil(math.log2(1 + (bits.max().round().item() - self.min_bits)))
+ subtotal += 8 # 8 bits for bits_bits
+ subtotal += bits_bits * bits.numel()
+
+ subtotal /= 2 ** 20 * 8 # bits -> MegaBytes
+ return total + subtotal
+
+ def true_model_size(self):
+ """
+ Naive model size without zlib compression.
+ """
+ return self.model_size(exact=True).item()
+
+ def _pre_forward_train(self):
+ if not self._optimizer_setup:
+ raise RuntimeError("You must call `setup_optimizer()` on your optimizer "
+ "before starting training.")
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ noisy = qparam.other.module._parameters[qparam.other.name]
+ else:
+ bits = self._get_bits(qparam.logit)[:, None]
+ if self.group_size == 0:
+ p_flat = qparam.param.view(-1)
+ else:
+ p_flat = qparam.param.view(-1, self.group_size)
+ scale = p_flat.max() - p_flat.min()
+ unit = 1 / (2**bits - 1)
+ if self.noise == "uniform":
+ noise_source = (torch.rand_like(p_flat) - 0.5)
+ elif self.noise == "gaussian":
+ noise_source = torch.randn_like(p_flat) / 2
+ noise = scale * unit * noise_source
+ noisy = p_flat + noise
+ # We bypass the checks by PyTorch on parameters being leafs
+ qparam.module._parameters[qparam.name] = noisy.view_as(qparam.param)
+ return True
+
+ def _post_forward_train(self):
+ for qparam in self._qparams:
+ qparam.module._parameters[qparam.name] = qparam.param
+ return True
+
+ def _quantize_param(self, qparam: _QuantizedParam) -> tp.Any:
+ bits = self.extra_bits + self._get_bits(qparam.logit)
+ bits = bits.round().clamp(1, 15)[:, None].byte()
+ if self.group_size == 0:
+ p = qparam.param.data.view(-1)
+ else:
+ p = qparam.param.data.view(-1, self.group_size)
+ levels, scales = uniform_quantize(p, bits)
+ return levels, scales, bits
+
+ def _unquantize_param(self, qparam: _QuantizedParam, quantized: tp.Any) -> torch.Tensor:
+ levels, param_scale, bits = quantized
+ return uniform_unquantize(levels, param_scale, bits).view_as(qparam.param.data)
+
+ def detach(self):
+ super().detach()
+ for qparam in self._qparams:
+ delattr(qparam.module, qparam.name + self.suffix)
+
+ def __repr__(self):
+ return simple_repr(self)
diff --git a/diffq/uniform.py b/diffq/uniform.py
new file mode 100644
index 0000000..f61e912
--- /dev/null
+++ b/diffq/uniform.py
@@ -0,0 +1,121 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+"""
+Classic uniform quantization over n bits.
+"""
+from typing import Tuple
+import torch
+
+from .base import BaseQuantizer
+from .utils import simple_repr
+
+
+def uniform_quantize(p: torch.Tensor, bits: torch.Tensor = torch.tensor(8.)):
+ """
+ Quantize the given weights over `bits` bits.
+
+ Returns:
+ - quantized levels
+ - (min, max) range.
+
+ """
+ assert (bits >= 1).all() and (bits <= 15).all()
+ num_levels = (2 ** bits.float()).long()
+ mn = p.min().item()
+ mx = p.max().item()
+ p = (p - mn) / (mx - mn) # put p in [0, 1]
+ unit = 1 / (num_levels - 1) # quantization unit
+ levels = (p / unit).round()
+ if (bits <= 8).all():
+ levels = levels.byte()
+ else:
+ levels = levels.short()
+ return levels, (mn, mx)
+
+
+def uniform_unquantize(levels: torch.Tensor, scales: Tuple[float, float],
+ bits: torch.Tensor = torch.tensor(8.)):
+ """
+ Unquantize the weights from the levels and scale. Return a float32 tensor.
+ """
+ mn, mx = scales
+ num_levels = 2 ** bits.float()
+ unit = 1 / (num_levels - 1)
+ levels = levels.float()
+ p = levels * unit # in [0, 1]
+ return p * (mx - mn) + mn
+
+
+class UniformQuantizer(BaseQuantizer):
+ def __init__(self, model: torch.nn.Module, bits: float = 8., min_size: float = 0.01,
+ float16: bool = False, qat: bool = False, exclude=[], detect_bound=True):
+ """
+ Args:
+ model (torch.nn.Module): model to quantize
+ bits (float): number of bits to quantize over.
+ min_size (float): minimum size in MB of a parameter to be quantized.
+ float16 (bool): if a layer is smaller than min_size, should we still do float16?
+ qat (bool): perform quantized aware training.
+ exclude (list[str]): list of patterns used to match parameters to exclude.
+ For instance `['bias']` to exclude all bias terms.
+ detect_bound (bool): if True, will detect bound parameters and reuse
+ the same quantized tensor for both.
+ """
+ self.bits = float(bits)
+ self.qat = qat
+
+ super().__init__(model, min_size, float16, exclude, detect_bound)
+
+ def __repr__(self):
+ return simple_repr(self, )
+
+ def _pre_forward_train(self):
+ if self.qat:
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ new_param = qparam.other.module._parameters[qparam.other.name]
+ else:
+ quantized = self._quantize_param(qparam)
+ qvalue = self._unquantize_param(qparam, quantized)
+ new_param = qparam.param + (qvalue - qparam.param).detach()
+ qparam.module._parameters[qparam.name] = new_param
+ return True
+ return False
+
+ def _post_forward_train(self):
+ if self.qat:
+ for qparam in self._qparams:
+ qparam.module._parameters[qparam.name] = qparam.param
+ return True
+ return False
+
+ def _quantize_param(self, qparam):
+ levels, scales = uniform_quantize(qparam.param.data, torch.tensor(self.bits))
+ return (levels, scales)
+
+ def _unquantize_param(self, qparam, quantized):
+ levels, scales = quantized
+ return uniform_unquantize(levels, scales, torch.tensor(self.bits))
+
+ def model_size(self):
+ """
+ Non differentiable model size in MB.
+ """
+ total = super().model_size()
+ subtotal = 0
+ for qparam in self._qparams:
+ if qparam.other is None: # if parameter is bound, count only one copy.
+ subtotal += self.bits * qparam.param.numel() + 64 # 2 float for the overall scales
+ subtotal /= 2**20 * 8 # bits to MegaBytes
+ return total + subtotal
+
+ def true_model_size(self):
+ """
+ Return the true quantized model size, in MB, without extra
+ compression.
+ """
+ return self.model_size().item()
diff --git a/diffq/utils.py b/diffq/utils.py
new file mode 100644
index 0000000..be6ab52
--- /dev/null
+++ b/diffq/utils.py
@@ -0,0 +1,37 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import inspect
+from typing import Optional, List
+
+
+def simple_repr(obj, attrs: Optional[List[str]] = None, overrides={}):
+ """
+ Return a simple representation string for `obj`.
+ If `attrs` is not None, it should be a list of attributes to include.
+ """
+ params = inspect.signature(obj.__class__).parameters
+ attrs_repr = []
+ if attrs is None:
+ attrs = params.keys()
+ for attr in attrs:
+ display = False
+ if attr in overrides:
+ value = overrides[attr]
+ elif hasattr(obj, attr):
+ value = getattr(obj, attr)
+ else:
+ continue
+ if attr in params:
+ param = params[attr]
+ if param.default is inspect._empty or value != param.default:
+ display = True
+ else:
+ display = True
+
+ if display:
+ attrs_repr.append(f"{attr}={value}")
+ return f"{obj.__class__.__name__}({','.join(attrs_repr)})"
diff --git a/img/File.png b/img/File.png
new file mode 100644
index 0000000..f0efc7d
Binary files /dev/null and b/img/File.png differ
diff --git a/img/GUI-Icon.png b/img/GUI-Icon.png
new file mode 100644
index 0000000..302bee1
Binary files /dev/null and b/img/GUI-Icon.png differ
diff --git a/img/UVR-Icon-v2.ico b/img/UVR-Icon-v2.ico
new file mode 100644
index 0000000..1c9d5d0
Binary files /dev/null and b/img/UVR-Icon-v2.ico differ
diff --git a/img/UVR-Icon.ico b/img/UVR-Icon.ico
index 944b30e..c3169b9 100644
Binary files a/img/UVR-Icon.ico and b/img/UVR-Icon.ico differ
diff --git a/img/UVR-banner-2.png b/img/UVR-banner-2.png
deleted file mode 100644
index 4819e91..0000000
Binary files a/img/UVR-banner-2.png and /dev/null differ
diff --git a/img/UVR-banner.png b/img/UVR-banner.png
index 768498a..8d96dfd 100644
Binary files a/img/UVR-banner.png and b/img/UVR-banner.png differ
diff --git a/img/UVRV52.png b/img/UVRV52.png
deleted file mode 100644
index 24038bd..0000000
Binary files a/img/UVRV52.png and /dev/null differ
diff --git a/img/UVRv5.png b/img/UVRv5.png
new file mode 100644
index 0000000..09f7486
Binary files /dev/null and b/img/UVRv5.png differ
diff --git a/img/credits.png b/img/credits.png
new file mode 100644
index 0000000..f32a494
Binary files /dev/null and b/img/credits.png differ
diff --git a/img/ense_opt.png b/img/ense_opt.png
new file mode 100644
index 0000000..7e3889d
Binary files /dev/null and b/img/ense_opt.png differ
diff --git a/img/file.png b/img/file.png
deleted file mode 100644
index e6c2a78..0000000
Binary files a/img/file.png and /dev/null differ
diff --git a/img/gen_opt.png b/img/gen_opt.png
new file mode 100644
index 0000000..decafa5
Binary files /dev/null and b/img/gen_opt.png differ
diff --git a/img/help.png b/img/help.png
new file mode 100644
index 0000000..411803a
Binary files /dev/null and b/img/help.png differ
diff --git a/img/icon.png b/img/icon.png
new file mode 100644
index 0000000..c43f125
Binary files /dev/null and b/img/icon.png differ
diff --git a/img/mdx_opt.png b/img/mdx_opt.png
new file mode 100644
index 0000000..3ed1e51
Binary files /dev/null and b/img/mdx_opt.png differ
diff --git a/img/splash.bmp b/img/splash.bmp
new file mode 100644
index 0000000..e96677e
Binary files /dev/null and b/img/splash.bmp differ
diff --git a/img/stop.png b/img/stop.png
new file mode 100644
index 0000000..e094d1b
Binary files /dev/null and b/img/stop.png differ
diff --git a/img/user_ens_opt.png b/img/user_ens_opt.png
new file mode 100644
index 0000000..b32c0e3
Binary files /dev/null and b/img/user_ens_opt.png differ
diff --git a/img/vr_opt.png b/img/vr_opt.png
new file mode 100644
index 0000000..c11ff56
Binary files /dev/null and b/img/vr_opt.png differ
diff --git a/inference_MDX.py b/inference_MDX.py
new file mode 100644
index 0000000..ba1b40a
--- /dev/null
+++ b/inference_MDX.py
@@ -0,0 +1,1051 @@
+import os
+from pickle import STOP
+from tracemalloc import stop
+from turtle import update
+import subprocess
+from unittest import skip
+from pathlib import Path
+import os.path
+from datetime import datetime
+import pydub
+import shutil
+#MDX-Net
+#----------------------------------------
+import soundfile as sf
+import torch
+import numpy as np
+from demucs.model import Demucs
+from demucs.utils import apply_model
+from models import get_models, spec_effects
+import onnxruntime as ort
+import time
+import os
+from tqdm import tqdm
+import warnings
+import sys
+import librosa
+import psutil
+#----------------------------------------
+from lib_v5 import spec_utils
+from lib_v5.model_param_init import ModelParameters
+import torch
+
+# Command line text parsing and widget manipulation
+import tkinter as tk
+import traceback # Error Message Recent Calls
+import time # Timer
+
+class Predictor():
+ def __init__(self):
+ pass
+
+ def prediction_setup(self, demucs_name,
+ channels=64):
+ if data['demucsmodel']:
+ self.demucs = Demucs(sources=["drums", "bass", "other", "vocals"], channels=channels)
+ widget_text.write(base_text + 'Loading Demucs model... ')
+ update_progress(**progress_kwargs,
+ step=0.05)
+ self.demucs.to(device)
+ self.demucs.load_state_dict(torch.load(demucs_name))
+ widget_text.write('Done!\n')
+ self.demucs.eval()
+ self.onnx_models = {}
+ c = 0
+
+ self.models = get_models('tdf_extra', load=False, device=cpu, stems='vocals')
+ widget_text.write(base_text + 'Loading ONNX model... ')
+ update_progress(**progress_kwargs,
+ step=0.1)
+ c+=1
+
+ if data['gpu'] >= 0:
+ if torch.cuda.is_available():
+ run_type = ['CUDAExecutionProvider']
+ else:
+ data['gpu'] = -1
+ widget_text.write("\n" + base_text + "No NVIDIA GPU detected. Switching to CPU... ")
+ run_type = ['CPUExecutionProvider']
+ else:
+ run_type = ['CPUExecutionProvider']
+
+ self.onnx_models[c] = ort.InferenceSession(os.path.join('models/MDX_Net_Models', model_set), providers=run_type)
+ widget_text.write('Done!\n')
+
+ def prediction(self, m):
+ #mix, rate = sf.read(m)
+ mix, rate = librosa.load(m, mono=False, sr=44100)
+ if mix.ndim == 1:
+ mix = np.asfortranarray([mix,mix])
+ mix = mix.T
+ sources = self.demix(mix.T)
+ widget_text.write(base_text + 'Inferences complete!\n')
+ c = -1
+
+ #Main Save Path
+ save_path = os.path.dirname(_basename)
+
+ #Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+
+ #Instrumental Path
+ Instrumental_name = '(Instrumental)'
+ if data['modelFolder']:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ Instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ Instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ else:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+ Instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+ Instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+
+ #Non-Reduced Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ non_reduced_vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ non_reduced_vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ else:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+ non_reduced_vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+ non_reduced_vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+
+
+ if os.path.isfile(non_reduced_vocal_path):
+ file_exists_n = 'there'
+ else:
+ file_exists_n = 'not_there'
+
+ if os.path.isfile(vocal_path):
+ file_exists_v = 'there'
+ else:
+ file_exists_v = 'not_there'
+
+ if os.path.isfile(Instrumental_path):
+ file_exists_i = 'there'
+ else:
+ file_exists_i = 'not_there'
+
+ print('Is there already a voc file there? ', file_exists_v)
+
+ if not data['noisereduc_s'] == 'None':
+ c += 1
+
+ if not data['demucsmodel']:
+
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing to save Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving vocals... ')
+
+ sf.write(non_reduced_vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ widget_text.write('Done!\n')
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ else:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+
+ sf.write(non_reduced_vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ widget_text.write('Done!\n')
+ else:
+ c += 1
+
+ if not data['demucsmodel']:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ else:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+
+ if data['voc_only'] and not data['inst_only']:
+ pass
+
+ else:
+ finalfiles = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':[str(music_file), vocal_path],
+ }
+ ]
+ widget_text.write(base_text + 'Saving Instrumental... ')
+ for i, e in tqdm(enumerate(finalfiles)):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ update_progress(**progress_kwargs,
+ step=(1))
+ sf.write(Instrumental_path, spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+
+
+ if data['inst_only']:
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+
+ widget_text.write('Done!\n')
+
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(Instrumental_path)
+ musfile.export(Instrumental_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(Instrumental_path)
+ except:
+ pass
+ if data['non_red'] == True:
+ musfile = pydub.AudioSegment.from_wav(non_reduced_vocal_path)
+ musfile.export(non_reduced_vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ widget_text.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ widget_text.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ else:
+ widget_text.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ widget_text.write(base_text + 'Please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}":\n\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(Instrumental_path)
+ musfile.export(Instrumental_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(Instrumental_path)
+ except:
+ pass
+ if data['non_red'] == True:
+ musfile = pydub.AudioSegment.from_wav(non_reduced_vocal_path)
+ musfile.export(non_reduced_vocal_path_flac, format="flac")
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ widget_text.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ widget_text.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ else:
+ widget_text.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ widget_text.write(base_text + 'Please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}":\n\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
+ try:
+ print('Is there already a voc file there? ', file_exists_v)
+ print('Is there already a non_voc file there? ', file_exists_n)
+ except:
+ pass
+
+
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ elif data['non_red'] == True:
+ pass
+ elif data['inst_only']:
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ widget_text.write(base_text + 'Completed Seperation!\n')
+
+ def demix(self, mix):
+ # 1 = demucs only
+ # 0 = onnx only
+ if data['chunks'] == 'Full':
+ chunk_set = 0
+ else:
+ chunk_set = data['chunks']
+
+ if data['chunks'] == 'Auto':
+ if data['gpu'] == 0:
+ try:
+ gpu_mem = round(torch.cuda.get_device_properties(0).total_memory/1.074e+9)
+ except:
+ widget_text.write(base_text + 'NVIDIA GPU Required for conversion!\n')
+ if int(gpu_mem) <= int(5):
+ chunk_set = int(5)
+ widget_text.write(base_text + 'Chunk size auto-set to 5... \n')
+ if gpu_mem in [6, 7]:
+ chunk_set = int(30)
+ widget_text.write(base_text + 'Chunk size auto-set to 30... \n')
+ if gpu_mem in [8, 9, 10, 11, 12, 13, 14, 15]:
+ chunk_set = int(40)
+ widget_text.write(base_text + 'Chunk size auto-set to 40... \n')
+ if int(gpu_mem) >= int(16):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ if data['gpu'] == -1:
+ sys_mem = psutil.virtual_memory().total >> 30
+ if int(sys_mem) <= int(4):
+ chunk_set = int(1)
+ widget_text.write(base_text + 'Chunk size auto-set to 1... \n')
+ if sys_mem in [5, 6, 7, 8]:
+ chunk_set = int(10)
+ widget_text.write(base_text + 'Chunk size auto-set to 10... \n')
+ if sys_mem in [9, 10, 11, 12, 13, 14, 15, 16]:
+ chunk_set = int(25)
+ widget_text.write(base_text + 'Chunk size auto-set to 25... \n')
+ if int(sys_mem) >= int(17):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ elif data['chunks'] == 'Full':
+ chunk_set = 0
+ widget_text.write(base_text + "Chunk size set to full... \n")
+ else:
+ chunk_set = int(data['chunks'])
+ widget_text.write(base_text + "Chunk size user-set to "f"{chunk_set}... \n")
+
+ samples = mix.shape[-1]
+ margin = margin_set
+ chunk_size = chunk_set*44100
+ assert not margin == 0, 'margin cannot be zero!'
+ if margin > chunk_size:
+ margin = chunk_size
+
+ b = np.array([[[0.5]], [[0.5]], [[0.7]], [[0.9]]])
+ segmented_mix = {}
+
+ if chunk_set == 0 or samples < chunk_size:
+ chunk_size = samples
+
+ counter = -1
+ for skip in range(0, samples, chunk_size):
+ counter+=1
+
+ s_margin = 0 if counter == 0 else margin
+ end = min(skip+chunk_size+margin, samples)
+
+ start = skip-s_margin
+
+ segmented_mix[skip] = mix[:,start:end].copy()
+ if end == samples:
+ break
+
+ if not data['demucsmodel']:
+ sources = self.demix_base(segmented_mix, margin_size=margin)
+
+ else: # both, apply spec effects
+ base_out = self.demix_base(segmented_mix, margin_size=margin)
+ demucs_out = self.demix_demucs(segmented_mix, margin_size=margin)
+ nan_count = np.count_nonzero(np.isnan(demucs_out)) + np.count_nonzero(np.isnan(base_out))
+ if nan_count > 0:
+ print('Warning: there are {} nan values in the array(s).'.format(nan_count))
+ demucs_out, base_out = np.nan_to_num(demucs_out), np.nan_to_num(base_out)
+ sources = {}
+
+ sources[3] = (spec_effects(wave=[demucs_out[3],base_out[0]],
+ algorithm='default',
+ value=b[3])*1.03597672895) # compensation
+ return sources
+
+ def demix_base(self, mixes, margin_size):
+ chunked_sources = []
+ onnxitera = len(mixes)
+ onnxitera_calc = onnxitera * 2
+ gui_progress_bar_onnx = 0
+ widget_text.write(base_text + "Running ONNX Inference...\n")
+ widget_text.write(base_text + "Processing "f"{onnxitera} slices... ")
+ print(' Running ONNX Inference...')
+ for mix in mixes:
+ gui_progress_bar_onnx += 1
+ if data['demucsmodel']:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.5/onnxitera_calc * gui_progress_bar_onnx)))
+ else:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.9/onnxitera * gui_progress_bar_onnx)))
+ cmix = mixes[mix]
+ sources = []
+ n_sample = cmix.shape[1]
+
+ mod = 0
+ for model in self.models:
+ mod += 1
+ trim = model.n_fft//2
+ gen_size = model.chunk_size-2*trim
+ pad = gen_size - n_sample%gen_size
+ mix_p = np.concatenate((np.zeros((2,trim)), cmix, np.zeros((2,pad)), np.zeros((2,trim))), 1)
+ mix_waves = []
+ i = 0
+ while i < n_sample + pad:
+ waves = np.array(mix_p[:, i:i+model.chunk_size])
+ mix_waves.append(waves)
+ i += gen_size
+ mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(cpu)
+ with torch.no_grad():
+ _ort = self.onnx_models[mod]
+ spek = model.stft(mix_waves)
+
+ tar_waves = model.istft(torch.tensor(_ort.run(None, {'input': spek.cpu().numpy()})[0]))#.cpu()
+
+ tar_signal = tar_waves[:,:,trim:-trim].transpose(0,1).reshape(2, -1).numpy()[:, :-pad]
+
+ start = 0 if mix == 0 else margin_size
+ end = None if mix == list(mixes.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ sources.append(tar_signal[:,start:end])
+
+
+ chunked_sources.append(sources)
+ _sources = np.concatenate(chunked_sources, axis=-1)
+ del self.onnx_models
+ widget_text.write('Done!\n')
+ return _sources
+
+ def demix_demucs(self, mix, margin_size):
+ processed = {}
+ demucsitera = len(mix)
+ demucsitera_calc = demucsitera * 2
+ gui_progress_bar_demucs = 0
+ widget_text.write(base_text + "Running Demucs Inference...\n")
+ widget_text.write(base_text + "Processing "f"{len(mix)} slices... ")
+ print(' Running Demucs Inference...')
+ for nmix in mix:
+ gui_progress_bar_demucs += 1
+ update_progress(**progress_kwargs,
+ step=(0.35 + (1.05/demucsitera_calc * gui_progress_bar_demucs)))
+ cmix = mix[nmix]
+ cmix = torch.tensor(cmix, dtype=torch.float32)
+ ref = cmix.mean(0)
+ cmix = (cmix - ref.mean()) / ref.std()
+ shift_set = 0
+ with torch.no_grad():
+ sources = apply_model(self.demucs, cmix.to(device), split=True, overlap=overlap_set, shifts=shift_set)
+ sources = (sources * ref.std() + ref.mean()).cpu().numpy()
+ sources[[0,1]] = sources[[1,0]]
+
+ start = 0 if nmix == 0 else margin_size
+ end = None if nmix == list(mix.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ processed[nmix] = sources[:,:,start:end].copy()
+
+ sources = list(processed.values())
+ sources = np.concatenate(sources, axis=-1)
+ widget_text.write('Done!\n')
+ return sources
+
+data = {
+ # Paths
+ 'input_paths': None,
+ 'export_path': None,
+ 'saveFormat': 'Wav',
+ # Processing Options
+ 'demucsmodel': True,
+ 'gpu': -1,
+ 'chunks': 10,
+ 'non_red': False,
+ 'noisereduc_s': 3,
+ 'mixing': 'default',
+ 'modelFolder': False,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'break': False,
+ # Choose Model
+ 'mdxnetModel': 'UVR-MDX-NET 1',
+ 'high_end_process': 'mirroring',
+}
+default_chunks = data['chunks']
+default_noisereduc_s = data['noisereduc_s']
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+warnings.filterwarnings("ignore")
+cpu = torch.device('cpu')
+device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+
+def hide_opt():
+ with open(os.devnull, "w") as devnull:
+ old_stdout = sys.stdout
+ sys.stdout = devnull
+ try:
+ yield
+ finally:
+ sys.stdout = old_stdout
+
+def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
+ **kwargs: dict):
+
+ global widget_text
+ global gui_progress_bar
+ global music_file
+ global channel_set
+ global margin_set
+ global overlap_set
+ global default_chunks
+ global default_noisereduc_s
+ global _basename
+ global _mixture
+ global progress_kwargs
+ global base_text
+ global model_set
+ global model_set_name
+
+ # Update default settings
+ default_chunks = data['chunks']
+ default_noisereduc_s = data['noisereduc_s']
+
+ channel_set = int(64)
+ margin_set = int(44100)
+ overlap_set = float(0.5)
+
+ widget_text = text_widget
+ gui_progress_bar = progress_var
+
+ #Error Handling
+
+ onnxmissing = "[ONNXRuntimeError] : 3 : NO_SUCHFILE"
+ onnxmemerror = "onnxruntime::CudaCall CUDA failure 2: out of memory"
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: MDX-Net' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ data.update(kwargs)
+
+ if data['mdxnetModel'] == 'UVR-MDX-NET 1':
+ model_set = 'UVR_MDXNET_9703.onnx'
+ model_set_name = 'UVR_MDXNET_9703'
+ if data['mdxnetModel'] == 'UVR-MDX-NET 2':
+ model_set = 'UVR_MDXNET_9682.onnx'
+ model_set_name = 'UVR_MDXNET_9682'
+ if data['mdxnetModel'] == 'UVR-MDX-NET 3':
+ model_set = 'UVR_MDXNET_9662.onnx'
+ model_set_name = 'UVR_MDXNET_9662'
+ if data['mdxnetModel'] == 'UVR-MDX-NET Karaoke':
+ model_set = 'UVR_MDXNET_KARA.onnx'
+ model_set_name = 'UVR_MDXNET_Karaoke'
+
+ stime = time.perf_counter()
+ progress_var.set(0)
+ text_widget.clear()
+ button_widget.configure(state=tk.DISABLED) # Disable Button
+
+ try: #Load File(s)
+ for file_num, music_file in tqdm(enumerate(data['input_paths'], start=1)):
+
+ _mixture = f'{data["input_paths"]}'
+ _basename = f'{data["export_path"]}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+
+ # -Get text and update progress-
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=file_num)
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': file_num}
+
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ else:
+ if not os.path.isfile("lib_v5\sox\sox.exe"):
+ data['noisereduc_s'] = 'None'
+ data['non_red'] = False
+ widget_text.write(base_text + 'SoX is missing and required for noise reduction.\n')
+ widget_text.write(base_text + 'See the \"More Info\" tab in the Help Guide.\n')
+ widget_text.write(base_text + 'Noise Reduction will be disabled until SoX is available.\n\n')
+
+ update_progress(**progress_kwargs,
+ step=0)
+
+ e = os.path.join(data["export_path"])
+
+ demucsmodel = 'models/Demucs_Model/demucs_extra-3646af93_org.th'
+
+ pred = Predictor()
+ pred.prediction_setup(demucs_name=demucsmodel,
+ channels=channel_set)
+
+ # split
+ pred.prediction(
+ m=music_file,
+ )
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmissing in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application could not detect this MDX-Net model on your system.\n')
+ text_widget.write(f'Please make sure all the models are present in the correct directory.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application could not detect this MDX-Net model on your system.\n' +
+ f'Please make sure all the models are present in the correct directory.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmemerror in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'\nPlease do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'\nPlease do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ print(traceback_text)
+ print(type(e).__name__, e)
+ print(message)
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
+ progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ progress_var.set(0)
+
+ text_widget.write(f'\nConversion(s) Completed!\n')
+
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+
+if __name__ == '__main__':
+ start_time = time.time()
+ main()
+ print("Successfully completed music demixing.");print('Total time: {0:.{1}f}s'.format(time.time() - start_time, 1))
+
diff --git a/inference_v5.py b/inference_v5.py
index 4ca9b4a..e1ee13c 100644
--- a/inference_v5.py
+++ b/inference_v5.py
@@ -1,9 +1,10 @@
from functools import total_ordering
-import pprint
-import argparse
import os
import importlib
from statistics import mode
+import pydub
+import shutil
+import hashlib
import cv2
import librosa
@@ -16,6 +17,7 @@ from lib_v5 import dataset
from lib_v5 import spec_utils
from lib_v5.model_param_init import ModelParameters
import torch
+from datetime import datetime
# Command line text parsing and widget manipulation
from collections import defaultdict
@@ -36,17 +38,21 @@ data = {
# Paths
'input_paths': None,
'export_path': None,
+ 'saveFormat': 'wav',
# Processing Options
'gpu': -1,
'postprocess': True,
'tta': True,
'output_image': True,
+ 'voc_only': False,
+ 'inst_only': False,
# Models
'instrumentalModel': None,
'useModel': None,
# Constants
'window_size': 512,
- 'agg': 10
+ 'agg': 10,
+ 'high_end_process': 'mirroring'
}
default_window_size = data['window_size']
@@ -88,25 +94,34 @@ def determineModelFolderName():
def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
**kwargs: dict):
- global args
global model_params_d
global nn_arch_sizes
-
+ global nn_architecture
+
+ #Error Handling
+
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: VR Architecture' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
nn_arch_sizes = [
31191, # default
33966, 123821, 123812, 537238 # custom
]
- p = argparse.ArgumentParser()
- p.add_argument('--paramone', type=str, default='lib_v5/modelparams/4band_44100.json')
- p.add_argument('--paramtwo', type=str, default='lib_v5/modelparams/4band_v2.json')
- p.add_argument('--paramthree', type=str, default='lib_v5/modelparams/3band_44100_msb2.json')
- p.add_argument('--paramfour', type=str, default='lib_v5/modelparams/4band_v2_sn.json')
- p.add_argument('--aggressiveness',type=float, default=data['agg']/100)
- p.add_argument('--nn_architecture', type=str, choices= ['auto'] + list('{}KB'.format(s) for s in nn_arch_sizes), default='auto')
- p.add_argument('--high_end_process', type=str, default='mirroring')
- args = p.parse_args()
-
+ nn_architecture = list('{}KB'.format(s) for s in nn_arch_sizes)
+
+
def save_files(wav_instrument, wav_vocals):
"""Save output music files"""
vocal_name = '(Vocals)'
@@ -133,22 +148,207 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# -Save files-
# Instrumental
if instrumental_name is not None:
- instrumental_path = '{save_path}/{file_name}.wav'.format(
- save_path=save_path,
- file_name=f'{os.path.basename(base_name)}_{instrumental_name}{appendModelFolderName}',
- )
-
- sf.write(instrumental_path,
- wav_instrument, mp.param['sr'])
+ if data['modelFolder']:
+ instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ else:
+ instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+ instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+ instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+
+ if os.path.isfile(instrumental_path):
+ file_exists_i = 'there'
+ else:
+ file_exists_i = 'not_there'
+
+ if VModel in model_name and data['voc_only']:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+ elif VModel in model_name and data['inst_only']:
+ pass
+ elif data['voc_only']:
+ pass
+ else:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+
# Vocal
if vocal_name is not None:
- vocal_path = '{save_path}/{file_name}.wav'.format(
- save_path=save_path,
- file_name=f'{os.path.basename(base_name)}_{vocal_name}{appendModelFolderName}',
- )
- sf.write(vocal_path,
- wav_vocals, mp.param['sr'])
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+
+ if os.path.isfile(vocal_path):
+ file_exists_v = 'there'
+ else:
+ file_exists_v = 'not_there'
+ if VModel in model_name and data['inst_only']:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+ elif VModel in model_name and data['voc_only']:
+ pass
+ elif data['inst_only']:
+ pass
+ else:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ if VModel in model_name:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ else:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
data.update(kwargs)
# Update default settings
@@ -164,16 +364,12 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
vocal_remover = VocalRemover(data, text_widget)
modelFolderName = determineModelFolderName()
- if modelFolderName:
- folder_path = f'{data["export_path"]}{modelFolderName}'
- if not os.path.isdir(folder_path):
- os.mkdir(folder_path)
# Separation Preperation
try: #Load File(s)
for file_num, music_file in enumerate(data['input_paths'], start=1):
# Determine File Name
- base_name = f'{data["export_path"]}{modelFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+ base_name = f'{data["export_path"]}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
model_name = os.path.basename(data[f'{data["useModel"]}Model'])
model = vocal_remover.models[data['useModel']]
@@ -187,36 +383,220 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
update_progress(**progress_kwargs,
step=0)
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
#Load Model
text_widget.write(base_text + 'Loading models...')
-
- if 'auto' == args.nn_architecture:
- model_size = math.ceil(os.stat(data['instrumentalModel']).st_size / 1024)
- args.nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+ model_size = math.ceil(os.stat(data['instrumentalModel']).st_size / 1024)
+ nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+
+ nets = importlib.import_module('lib_v5.nets' + f'_{nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
+
+ aggresive_set = float(data['agg']/100)
- nets = importlib.import_module('lib_v5.nets' + f'_{args.nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
-
ModelName=(data['instrumentalModel'])
- ModelParam1="4BAND_44100"
- ModelParam2="4BAND_44100_B"
- ModelParam3="MSB2"
- ModelParam4="4BAND_44100_SN"
-
- if ModelParam1 in ModelName:
- model_params_d=args.paramone
- if ModelParam2 in ModelName:
- model_params_d=args.paramtwo
- if ModelParam3 in ModelName:
- model_params_d=args.paramthree
- if ModelParam4 in ModelName:
- model_params_d=args.paramfour
+ #Package Models
+
+ model_hash = hashlib.md5(open(ModelName,'rb').read()).hexdigest()
+ print(model_hash)
+
+ #v5 Models
+
+ if model_hash == '47939caf0cfe52a0e81442b85b971dfd':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '4e4ecb9764c50a8c414fee6e10395bbe':
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if model_hash == 'e60a1e84803ce4efc0a6551206cc4b71':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'a82f14e75892e55e994376edbf0c8435':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '6dd9eaa6f0420af9f1d403aaafa4cc06':
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if model_hash == '5c7bbca45a187e81abbbd351606164e5':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'd6b2cb685a058a091e5e7098192d3233':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'c1b9f38170a7c90e96f027992eb7c62b':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'c3448ec923fa0edf3d03a19e633faa53':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
- print('Model Parameters:', model_params_d)
+ #v4 Models
+
+ if model_hash == '6a00461c51c2920fd68937d4609ed6c8':
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if model_hash == '0ab504864d20f1bd378fe9c81ef37140':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '7dd21065bf91c10f7fccb57d7d83b07f':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '80ab74d65e515caa3622728d2de07d23':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == 'edc115e7fc523245062200c00caa847f':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == '28063e9f6ab5b341c5f6d3c67f2045b7':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == 'b58090534c52cbc3e9b5104bad666ef2':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == '0cdab9947f1b0928705f518f3c78ea8f':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == 'ae702fed0238afb5346db8356fe25f13':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ #User Models
+
+ #1 Band
+ if '1band_sr16000_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if '1band_sr32000_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if '1band_sr33075_hl384' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if '1band_sr44100_hl256' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl256.json')
+ param_name=str('1band_sr44100_hl256')
+ if '1band_sr44100_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if '1band_sr44100_hl1024' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ #2 Band
+ if '2band_44100_lofi' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_44100_lofi.json')
+ param_name=str('2band_44100_lofi')
+ if '2band_32000' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_32000.json')
+ param_name=str('2band_32000')
+ if '2band_48000' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_48000.json')
+ param_name=str('2band_48000')
+
+ #3 Band
+ if '3band_44100' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100.json')
+ param_name=str('3band_44100')
+ if '3band_44100_mid' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100_mid.json')
+ param_name=str('3band_44100_mid')
+ if '3band_44100_msb2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+
+ #4 Band
+ if '4band_44100' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if '4band_44100_mid' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_mid.json')
+ param_name=str('4band_44100_mid')
+ if '4band_44100_msb' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_msb.json')
+ param_name=str('4band_44100_msb')
+ if '4band_44100_msb2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_msb2.json')
+ param_name=str('4band_44100_msb2')
+ if '4band_44100_reverse' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_reverse.json')
+ param_name=str('4band_44100_reverse')
+ if '4band_44100_sw' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_sw.json')
+ param_name=str('4band_44100_sw')
+ if '4band_v2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if '4band_v2_sn' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if 'tmodelparam' in ModelName:
+ model_params_d=str('lib_v5/modelparams/tmodelparam.json')
+ param_name=str('User Model Param Set')
+
+ text_widget.write(' Done!\n')
+
+ try:
+ print('Model Parameters:', model_params_d)
+ text_widget.write(base_text + 'Loading assigned model parameters ' + '\"' + param_name + '\"... ')
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Model parameters are missing.\n\n')
+ text_widget.write(f'Please check the following:\n')
+ text_widget.write(f'1. Make sure the model is still present.\n')
+ text_widget.write(f'2. If you are running a model that was not originally included in this package, \nplease append the modelparam name to the model name.\n')
+ text_widget.write(f' - Example if using \"4band_v2.json\" modelparam: \"model_4band_v2.pth\"\n\n')
+ text_widget.write(f'Please address this and try again.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Model parameters are missing.\n\n' +
+ f'Please check the following:\n' +
+ f'1. Make sure the model is still present.\n' +
+ f'2. If you are running a model that was not originally included in this package, please append the modelparam name to the model name.\n' +
+ f' - Example if using \"4band_v2.json\" modelparam: \"model_4band_v2.pth\"\n\n' +
+ f'Please address this and try again.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
mp = ModelParameters(model_params_d)
-
+ text_widget.write('Done!\n')
# -Instrumental-
if os.path.isfile(data['instrumentalModel']):
device = torch.device('cpu')
@@ -230,7 +610,6 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
vocal_remover.models['instrumental'] = model
vocal_remover.devices['instrumental'] = device
- text_widget.write(' Done!\n')
model_name = os.path.basename(data[f'{data["useModel"]}Model'])
@@ -238,7 +617,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# -Go through the different steps of seperation-
# Wave source
- text_widget.write(base_text + 'Loading wave source...')
+ text_widget.write(base_text + 'Loading audio source...')
X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
@@ -261,7 +640,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
mp.param['mid_side_b2'], mp.param['reverse'])
- if d == bands_n and args.high_end_process != 'none':
+ if d == bands_n and data['high_end_process'] != 'none':
input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
@@ -270,7 +649,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
update_progress(**progress_kwargs,
step=0.1)
- text_widget.write(base_text + 'Stft of wave source...')
+ text_widget.write(base_text + 'Loading the stft of audio source...')
text_widget.write(' Done!\n')
@@ -350,7 +729,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
else:
return pred * coef, X_mag, np.exp(1.j * X_phase)
- aggressiveness = {'value': args.aggressiveness, 'split_bin': mp.param['band'][1]['crop_stop']}
+ aggressiveness = {'value': aggresive_set, 'split_bin': mp.param['band'][1]['crop_stop']}
if data['tta']:
text_widget.write(base_text + "Running Inferences (TTA)...\n")
@@ -365,42 +744,78 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
step=0.9)
# Postprocess
if data['postprocess']:
- text_widget.write(base_text + 'Post processing...')
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- text_widget.write(' Done!\n')
+ try:
+ text_widget.write(base_text + 'Post processing...')
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ text_widget.write(' Done!\n')
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Post process failed, check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run Post Processing on "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
update_progress(**progress_kwargs,
step=0.95)
# Inverse stft
- text_widget.write(base_text + 'Inverse stft of instruments and vocals...') # nopep8
y_spec_m = pred * X_phase
v_spec_m = X_spec_m - y_spec_m
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, y_spec_m, input_high_end, mp)
-
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Instrumental... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], y_spec_m, input_high_end, mp)
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
else:
wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, v_spec_m, input_high_end, mp)
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Vocals... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], v_spec_m, input_high_end, mp)
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
else:
wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
-
- text_widget.write('Done!\n')
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
update_progress(**progress_kwargs,
step=1)
# Save output music files
- text_widget.write(base_text + 'Saving Files...')
save_files(wav_instrument, wav_vocals)
- text_widget.write(' Done!\n')
update_progress(**progress_kwargs,
step=1)
@@ -415,25 +830,196 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
image = spec_utils.spectrogram_to_image(v_spec_m)
_, bin_image = cv2.imencode('.jpg', image)
bin_image.tofile(f)
+
text_widget.write(base_text + 'Completed Seperation!\n\n')
except Exception as e:
traceback_text = ''.join(traceback.format_tb(e.__traceback__))
- message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\nFile: {music_file}\nPlease contact the creator and attach a screenshot of this error with the file and settings that caused it!'
- tk.messagebox.showerror(master=window,
- title='Untracked Error',
- message=message)
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
print(traceback_text)
print(type(e).__name__, e)
print(message)
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) # Enable Button
return
-
- os.remove('temp.wav')
+
+ try:
+ os.remove('temp.wav')
+ except:
+ pass
progress_var.set(0)
- text_widget.write(f'\nConversion(s) Completed!\n')
+ text_widget.write(f'Conversion(s) Completed!\n')
text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) # Enable Button
\ No newline at end of file
diff --git a/inference_v5_ensemble.py b/inference_v5_ensemble.py
index 43acdd5..ede48d9 100644
--- a/inference_v5_ensemble.py
+++ b/inference_v5_ensemble.py
@@ -1,15 +1,35 @@
from functools import total_ordering
-import pprint
-import argparse
+import importlib
import os
from statistics import mode
+from pathlib import Path
+import pydub
+import hashlib
+
+import subprocess
+import soundfile as sf
+import torch
+import numpy as np
+from demucs.model import Demucs
+from demucs.utils import apply_model
+from models import get_models, spec_effects
+import onnxruntime as ort
+import time
+import os
+from tqdm import tqdm
+import warnings
+import sys
+import librosa
+import psutil
import cv2
+import math
import librosa
import numpy as np
import soundfile as sf
import shutil
from tqdm import tqdm
+from datetime import datetime
from lib_v5 import dataset
from lib_v5 import spec_utils
@@ -22,6 +42,480 @@ import tkinter as tk
import traceback # Error Message Recent Calls
import time # Timer
+class Predictor():
+ def __init__(self):
+ pass
+
+ def prediction_setup(self, demucs_name,
+ channels=64):
+ if data['demucsmodel']:
+ self.demucs = Demucs(sources=["drums", "bass", "other", "vocals"], channels=channels)
+ widget_text.write(base_text + 'Loading Demucs model... ')
+ update_progress(**progress_kwargs,
+ step=0.05)
+ self.demucs.to(device)
+ self.demucs.load_state_dict(torch.load(demucs_name))
+ widget_text.write('Done!\n')
+ self.demucs.eval()
+ self.onnx_models = {}
+ c = 0
+
+ self.models = get_models('tdf_extra', load=False, device=cpu, stems='vocals')
+ widget_text.write(base_text + 'Loading ONNX model... ')
+ update_progress(**progress_kwargs,
+ step=0.1)
+ c+=1
+
+ if data['gpu'] >= 0:
+ if torch.cuda.is_available():
+ run_type = ['CUDAExecutionProvider']
+ else:
+ data['gpu'] = -1
+ widget_text.write("\n" + base_text + "No NVIDIA GPU detected. Switching to CPU... ")
+ run_type = ['CPUExecutionProvider']
+ else:
+ run_type = ['CPUExecutionProvider']
+
+ self.onnx_models[c] = ort.InferenceSession(os.path.join('models/MDX_Net_Models', model_set), providers=run_type)
+ widget_text.write('Done!\n')
+
+ def prediction(self, m):
+ #mix, rate = sf.read(m)
+ mix, rate = librosa.load(m, mono=False, sr=44100)
+ if mix.ndim == 1:
+ mix = np.asfortranarray([mix,mix])
+ mix = mix.T
+ sources = self.demix(mix.T)
+ widget_text.write(base_text + 'Inferences complete!\n')
+ c = -1
+
+ #Main Save Path
+ save_path = os.path.dirname(base_name)
+
+ #Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}',)
+
+ #Instrumental Path
+ Instrumental_name = '(Instrumental)'
+ if data['modelFolder']:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{Instrumental_name}',)
+ else:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{Instrumental_name}',)
+
+ #Non-Reduced Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}_No_Reduction',)
+ else:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}_No_Reduction',)
+
+ if os.path.isfile(non_reduced_vocal_path):
+ file_exists_n = 'there'
+ else:
+ file_exists_n = 'not_there'
+
+ if os.path.isfile(vocal_path):
+ file_exists = 'there'
+ else:
+ file_exists = 'not_there'
+
+ if not data['noisereduc_s'] == 'None':
+ c += 1
+ if not data['demucsmodel']:
+ if data['inst_only'] and not data['voc_only']:
+ widget_text.write(base_text + 'Preparing to save Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving vocals... ')
+ sf.write(non_reduced_vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ widget_text.write('Done!\n')
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ else:
+ if data['inst_only'] and not data['voc_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(non_reduced_vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ widget_text.write('Done!\n')
+ else:
+ c += 1
+ if not data['demucsmodel']:
+ widget_text.write(base_text + 'Saving Vocals..')
+ sf.write(vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ finalfiles = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':[str(music_file), vocal_path],
+ }
+ ]
+ widget_text.write(base_text + 'Saving Instrumental... ')
+ for i, e in tqdm(enumerate(finalfiles)):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ update_progress(**progress_kwargs,
+ step=(1))
+ sf.write(Instrumental_path, spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+ if data['inst_only']:
+ if file_exists == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+
+ widget_text.write('Done!\n')
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ elif data['inst_only']:
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ widget_text.write(base_text + 'Completed Seperation!\n\n')
+
+ def demix(self, mix):
+ # 1 = demucs only
+ # 0 = onnx only
+ if data['chunks'] == 'Full':
+ chunk_set = 0
+ else:
+ chunk_set = data['chunks']
+
+ if data['chunks'] == 'Auto':
+ if data['gpu'] == 0:
+ try:
+ gpu_mem = round(torch.cuda.get_device_properties(0).total_memory/1.074e+9)
+ except:
+ widget_text.write(base_text + 'NVIDIA GPU Required for conversion!\n')
+ if int(gpu_mem) <= int(5):
+ chunk_set = int(5)
+ widget_text.write(base_text + 'Chunk size auto-set to 5... \n')
+ if gpu_mem in [6, 7]:
+ chunk_set = int(30)
+ widget_text.write(base_text + 'Chunk size auto-set to 30... \n')
+ if gpu_mem in [8, 9, 10, 11, 12, 13, 14, 15]:
+ chunk_set = int(40)
+ widget_text.write(base_text + 'Chunk size auto-set to 40... \n')
+ if int(gpu_mem) >= int(16):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ if data['gpu'] == -1:
+ sys_mem = psutil.virtual_memory().total >> 30
+ if int(sys_mem) <= int(4):
+ chunk_set = int(1)
+ widget_text.write(base_text + 'Chunk size auto-set to 1... \n')
+ if sys_mem in [5, 6, 7, 8]:
+ chunk_set = int(10)
+ widget_text.write(base_text + 'Chunk size auto-set to 10... \n')
+ if sys_mem in [9, 10, 11, 12, 13, 14, 15, 16]:
+ chunk_set = int(25)
+ widget_text.write(base_text + 'Chunk size auto-set to 25... \n')
+ if int(sys_mem) >= int(17):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ elif data['chunks'] == 'Full':
+ chunk_set = 0
+ widget_text.write(base_text + "Chunk size set to full... \n")
+ else:
+ chunk_set = int(data['chunks'])
+ widget_text.write(base_text + "Chunk size user-set to "f"{chunk_set}... \n")
+
+ samples = mix.shape[-1]
+ margin = margin_set
+ chunk_size = chunk_set*44100
+ assert not margin == 0, 'margin cannot be zero!'
+ if margin > chunk_size:
+ margin = chunk_size
+
+ b = np.array([[[0.5]], [[0.5]], [[0.7]], [[0.9]]])
+ segmented_mix = {}
+
+ if chunk_set == 0 or samples < chunk_size:
+ chunk_size = samples
+
+ counter = -1
+ for skip in range(0, samples, chunk_size):
+ counter+=1
+
+ s_margin = 0 if counter == 0 else margin
+ end = min(skip+chunk_size+margin, samples)
+
+ start = skip-s_margin
+
+ segmented_mix[skip] = mix[:,start:end].copy()
+ if end == samples:
+ break
+
+ if not data['demucsmodel']:
+ sources = self.demix_base(segmented_mix, margin_size=margin)
+
+ else: # both, apply spec effects
+ base_out = self.demix_base(segmented_mix, margin_size=margin)
+ demucs_out = self.demix_demucs(segmented_mix, margin_size=margin)
+ nan_count = np.count_nonzero(np.isnan(demucs_out)) + np.count_nonzero(np.isnan(base_out))
+ if nan_count > 0:
+ print('Warning: there are {} nan values in the array(s).'.format(nan_count))
+ demucs_out, base_out = np.nan_to_num(demucs_out), np.nan_to_num(base_out)
+ sources = {}
+
+ sources[3] = (spec_effects(wave=[demucs_out[3],base_out[0]],
+ algorithm='default',
+ value=b[3])*1.03597672895) # compensation
+ return sources
+
+ def demix_base(self, mixes, margin_size):
+ chunked_sources = []
+ onnxitera = len(mixes)
+ onnxitera_calc = onnxitera * 2
+ gui_progress_bar_onnx = 0
+ widget_text.write(base_text + "Running ONNX Inference...\n")
+ widget_text.write(base_text + "Processing "f"{onnxitera} slices... ")
+ print(' Running ONNX Inference...')
+ for mix in mixes:
+ gui_progress_bar_onnx += 1
+ if data['demucsmodel']:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.5/onnxitera_calc * gui_progress_bar_onnx)))
+ else:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.9/onnxitera * gui_progress_bar_onnx)))
+ cmix = mixes[mix]
+ sources = []
+ n_sample = cmix.shape[1]
+
+ mod = 0
+ for model in self.models:
+ mod += 1
+ trim = model.n_fft//2
+ gen_size = model.chunk_size-2*trim
+ pad = gen_size - n_sample%gen_size
+ mix_p = np.concatenate((np.zeros((2,trim)), cmix, np.zeros((2,pad)), np.zeros((2,trim))), 1)
+ mix_waves = []
+ i = 0
+ while i < n_sample + pad:
+ waves = np.array(mix_p[:, i:i+model.chunk_size])
+ mix_waves.append(waves)
+ i += gen_size
+ mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(cpu)
+ with torch.no_grad():
+ _ort = self.onnx_models[mod]
+ spek = model.stft(mix_waves)
+
+ tar_waves = model.istft(torch.tensor(_ort.run(None, {'input': spek.cpu().numpy()})[0]))#.cpu()
+
+ tar_signal = tar_waves[:,:,trim:-trim].transpose(0,1).reshape(2, -1).numpy()[:, :-pad]
+
+ start = 0 if mix == 0 else margin_size
+ end = None if mix == list(mixes.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ sources.append(tar_signal[:,start:end])
+
+
+ chunked_sources.append(sources)
+ _sources = np.concatenate(chunked_sources, axis=-1)
+ del self.onnx_models
+ widget_text.write('Done!\n')
+ return _sources
+
+ def demix_demucs(self, mix, margin_size):
+ processed = {}
+ demucsitera = len(mix)
+ demucsitera_calc = demucsitera * 2
+ gui_progress_bar_demucs = 0
+ widget_text.write(base_text + "Running Demucs Inference...\n")
+ widget_text.write(base_text + "Processing "f"{len(mix)} slices... ")
+ print(' Running Demucs Inference...')
+ for nmix in mix:
+ gui_progress_bar_demucs += 1
+ update_progress(**progress_kwargs,
+ step=(0.35 + (1.05/demucsitera_calc * gui_progress_bar_demucs)))
+ cmix = mix[nmix]
+ cmix = torch.tensor(cmix, dtype=torch.float32)
+ ref = cmix.mean(0)
+ cmix = (cmix - ref.mean()) / ref.std()
+ shift_set = 0
+ with torch.no_grad():
+ sources = apply_model(self.demucs, cmix.to(device), split=True, overlap=overlap_set, shifts=shift_set)
+ sources = (sources * ref.std() + ref.mean()).cpu().numpy()
+ sources[[0,1]] = sources[[1,0]]
+
+ start = 0 if nmix == 0 else margin_size
+ end = None if nmix == list(mix.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ processed[nmix] = sources[:,:,start:end].copy()
+
+ sources = list(processed.values())
+ sources = np.concatenate(sources, axis=-1)
+ widget_text.write('Done!\n')
+ return sources
+
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+warnings.filterwarnings("ignore")
+cpu = torch.device('cpu')
+device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+
+def hide_opt():
+ with open(os.devnull, "w") as devnull:
+ old_stdout = sys.stdout
+ sys.stdout = devnull
+ try:
+ yield
+ finally:
+ sys.stdout = old_stdout
+
+class VocalRemover(object):
+
+ def __init__(self, data, text_widget: tk.Text):
+ self.data = data
+ self.text_widget = text_widget
+ self.models = defaultdict(lambda: None)
+ self.devices = defaultdict(lambda: None)
+ # self.offset = model.offset
+
+
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+def determineModelFolderName():
+ """
+ Determine the name that is used for the folder and appended
+ to the back of the music files
+ """
+ modelFolderName = ''
+ if not data['modelFolder']:
+ # Model Test Mode not selected
+ return modelFolderName
+
+ # -Instrumental-
+ if os.path.isfile(data['instrumentalModel']):
+ modelFolderName += os.path.splitext(os.path.basename(data['instrumentalModel']))[0]
+
+ if modelFolderName:
+ modelFolderName = '/' + modelFolderName
+
+ return modelFolderName
+
class VocalRemover(object):
def __init__(self, data, text_widget: tk.Text):
@@ -33,23 +527,36 @@ data = {
# Paths
'input_paths': None,
'export_path': None,
+ 'saveFormat': 'wav',
# Processing Options
'gpu': -1,
'postprocess': True,
'tta': True,
- 'save': True,
'output_image': True,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'demucsmodel': True,
+ 'gpu': -1,
+ 'chunks': 'auto',
+ 'non_red': False,
+ 'noisereduc_s': 3,
+ 'mixing': 'default',
+ 'ensChoose': 'HP1 Models',
+ 'algo': 'Instrumentals (Min Spec)',
# Models
'instrumentalModel': None,
'useModel': None,
# Constants
'window_size': 512,
'agg': 10,
- 'ensChoose': 'HP1 Models'
+ 'high_end_process': 'mirroring'
}
default_window_size = data['window_size']
default_agg = data['agg']
+default_chunks = data['chunks']
+default_noisereduc_s = data['noisereduc_s']
+
def update_progress(progress_var, total_files, file_num, step: float = 1):
"""Calculate the progress for the progress widget in the GUI"""
@@ -68,20 +575,61 @@ def get_baseText(total_files, file_num):
def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
**kwargs: dict):
- global args
- global nn_arch_sizes
+ global widget_text
+ global gui_progress_bar
+ global music_file
+ global channel_set
+ global margin_set
+ global overlap_set
+ global default_chunks
+ global default_noisereduc_s
+ global base_name
+ global progress_kwargs
+ global base_text
+ global model_set
+ global model_set_name
+ global ModelName_2
+ model_set = 'UVR_MDXNET_9703.onnx'
+ model_set_name = 'UVR_MDXNET_9703'
+
+ # Update default settings
+ default_chunks = data['chunks']
+ default_noisereduc_s = data['noisereduc_s']
+
+ channel_set = int(64)
+ margin_set = int(44100)
+ overlap_set = float(0.5)
+
+ widget_text = text_widget
+ gui_progress_bar = progress_var
+
+ #Error Handling
+
+ onnxmissing = "[ONNXRuntimeError] : 3 : NO_SUCHFILE"
+ onnxmemerror = "onnxruntime::CudaCall CUDA failure 2: out of memory"
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: Ensemble Mode' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ global nn_arch_sizes
+ global nn_architecture
+
nn_arch_sizes = [
31191, # default
- 33966, 123821, 123812, 537238 # custom
+ 33966, 123821, 123812, 537238, 537227 # custom
]
-
- p = argparse.ArgumentParser()
- p.add_argument('--aggressiveness',type=float, default=data['agg']/100)
- p.add_argument('--high_end_process', type=str, default='mirroring')
- args = p.parse_args()
-
-
+
def save_files(wav_instrument, wav_vocals):
"""Save output music files"""
vocal_name = '(Vocals)'
@@ -100,6 +648,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# For instrumental the instrumental is the temp file
# and for vocal the instrumental is the temp file due
# to reversement
+
sf.write(f'temp.wav',
wav_instrument, mp.param['sr'])
@@ -110,17 +659,35 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
save_path=save_path,
file_name = f'{os.path.basename(base_name)}_{ModelName_1}_{instrumental_name}',
)
-
- sf.write(instrumental_path,
- wav_instrument, mp.param['sr'])
+
+ if VModel in ModelName_1 and data['voc_only']:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+ elif VModel in ModelName_1 and data['inst_only']:
+ pass
+ elif data['voc_only']:
+ pass
+ else:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+
# Vocal
if vocal_name is not None:
vocal_path = '{save_path}/{file_name}.wav'.format(
save_path=save_path,
file_name=f'{os.path.basename(base_name)}_{ModelName_1}_{vocal_name}',
)
- sf.write(vocal_path,
- wav_vocals, mp.param['sr'])
+
+ if VModel in ModelName_1 and data['inst_only']:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+ elif VModel in ModelName_1 and data['voc_only']:
+ pass
+ elif data['inst_only']:
+ pass
+ else:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
data.update(kwargs)
@@ -135,471 +702,1376 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
text_widget.clear()
button_widget.configure(state=tk.DISABLED) # Disable Button
+ if os.path.exists('models/Main_Models/7_HP2-UVR.pth') \
+ or os.path.exists('models/Main_Models/8_HP2-UVR.pth') \
+ or os.path.exists('models/Main_Models/9_HP2-UVR.pth'):
+ hp2_ens = 'on'
+ else:
+ hp2_ens = 'off'
+
+ print('Do all of the HP models exist? ' + hp2_ens)
+
# Separation Preperation
try: #Ensemble Dictionary
- HP1_Models = [
- {
- 'model_name':'HP_4BAND_44100_A',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_A.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/2'
- },
- {
- 'model_name':'HP_4BAND_44100_B',
- 'model_params':'lib_v5/modelparams/4band_v2.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_B.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/2'
- }
- ]
-
- HP2_Models = [
- {
- 'model_name':'HP2_4BAND_44100_1',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_1.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 1/3'
- },
- {
- 'model_name':'HP2_4BAND_44100_2',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 2/3'
- },
- {
- 'model_name':'HP2_3BAND_44100_MSB2',
- 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
- 'model_location':'models/Main Models/HP2_3BAND_44100_MSB2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 3/3'
- }
- ]
-
- All_HP_Models = [
- {
- 'model_name':'HP_4BAND_44100_A',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_A.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/5'
- },
- {
- 'model_name':'HP_4BAND_44100_B',
- 'model_params':'lib_v5/modelparams/4band_v2.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_B.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/5'
- },
- {
- 'model_name':'HP2_4BAND_44100_1',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_1.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 3/5'
-
- },
- {
- 'model_name':'HP2_4BAND_44100_2',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 4/5'
-
- },
- {
- 'model_name':'HP2_3BAND_44100_MSB2',
- 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
- 'model_location':'models/Main Models/HP2_3BAND_44100_MSB2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 5/5'
- }
- ]
-
- Vocal_Models = [
- {
- 'model_name':'HP_Vocal_4BAND_44100',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_Vocal_4BAND_44100.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/2'
- },
- {
- 'model_name':'HP_Vocal_AGG_4BAND_44100',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_Vocal_AGG_4BAND_44100.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/2'
- }
- ]
- if data['ensChoose'] == 'HP1 Models':
- loops = HP1_Models
- ensefolder = 'HP_Models_Saved_Outputs'
- ensemode = 'HP_Models'
- if data['ensChoose'] == 'HP2 Models':
- loops = HP2_Models
- ensefolder = 'HP2_Models_Saved_Outputs'
- ensemode = 'HP2_Models'
- if data['ensChoose'] == 'All HP Models':
- loops = All_HP_Models
- ensefolder = 'All_HP_Models_Saved_Outputs'
- ensemode = 'All_HP_Models'
- if data['ensChoose'] == 'Vocal Models':
- loops = Vocal_Models
- ensefolder = 'Vocal_Models_Saved_Outputs'
- ensemode = 'Vocal_Models'
-
- #Prepare Audiofile(s)
- for file_num, music_file in enumerate(data['input_paths'], start=1):
- # -Get text and update progress-
- base_text = get_baseText(total_files=len(data['input_paths']),
- file_num=file_num)
- progress_kwargs = {'progress_var': progress_var,
- 'total_files': len(data['input_paths']),
- 'file_num': file_num}
- update_progress(**progress_kwargs,
- step=0)
-
- #Prepare to loop models
- for i, c in tqdm(enumerate(loops), disable=True, desc='Iterations..'):
-
- text_widget.write(c['loop_name'] + '\n\n')
-
- text_widget.write(base_text + 'Loading ' + c['model_name'] + '... ')
-
- arch_now = c['using_archtecture']
-
- if arch_now == '123821KB':
- from lib_v5 import nets_123821KB as nets
- elif arch_now == '537238KB':
- from lib_v5 import nets_537238KB as nets
- elif arch_now == '537227KB':
- from lib_v5 import nets_537227KB as nets
-
- def determineenseFolderName():
- """
- Determine the name that is used for the folder and appended
- to the back of the music files
- """
- enseFolderName = ''
-
- if str(ensefolder):
- enseFolderName += os.path.splitext(os.path.basename(ensefolder))[0]
-
- if enseFolderName:
- enseFolderName = '/' + enseFolderName
-
- return enseFolderName
-
- enseFolderName = determineenseFolderName()
- if enseFolderName:
- folder_path = f'{data["export_path"]}{enseFolderName}'
- if not os.path.isdir(folder_path):
- os.mkdir(folder_path)
-
- # Determine File Name
- base_name = f'{data["export_path"]}{enseFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
- enseExport = f'{data["export_path"]}{enseFolderName}/'
- trackname = f'{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
-
- ModelName_1=(c['model_name'])
-
- print('Model Parameters:', c['model_params'])
-
- mp = ModelParameters(c['model_params'])
-
- #Load model
- if os.path.isfile(c['model_location']):
- device = torch.device('cpu')
- model = nets.CascadedASPPNet(mp.param['bins'] * 2)
- model.load_state_dict(torch.load(c['model_location'],
- map_location=device))
- if torch.cuda.is_available() and data['gpu'] >= 0:
- device = torch.device('cuda:{}'.format(data['gpu']))
- model.to(device)
-
- text_widget.write('Done!\n')
-
- model_name = os.path.basename(c["model_name"])
-
- # -Go through the different steps of seperation-
- # Wave source
- text_widget.write(base_text + 'Loading wave source... ')
-
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
-
- bands_n = len(mp.param['band'])
-
- for d in range(bands_n, 0, -1):
- bp = mp.param['band'][d]
-
- if d == bands_n: # high-end band
- X_wave[d], _ = librosa.load(
- music_file, bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
-
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.resample(X_wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
-
- # Stft of wave source
-
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
- mp.param['mid_side_b2'], mp.param['reverse'])
-
- if d == bands_n and args.high_end_process != 'none':
- input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
- input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
-
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.1)
-
- text_widget.write(base_text + 'Stft of wave source... ')
- text_widget.write('Done!\n')
- text_widget.write(base_text + "Please Wait...\n")
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, mp)
-
- del X_wave, X_spec_s
-
- def inference(X_spec, device, model, aggressiveness):
-
- def _execute(X_mag_pad, roi_size, n_window, device, model, aggressiveness):
- model.eval()
-
- with torch.no_grad():
- preds = []
-
- iterations = [n_window]
-
- total_iterations = sum(iterations)
-
- text_widget.write(base_text + "Processing "f"{total_iterations} Slices... ")
-
- for i in tqdm(range(n_window)):
- update_progress(**progress_kwargs,
- step=(0.1 + (0.8/n_window * i)))
- start = i * roi_size
- X_mag_window = X_mag_pad[None, :, :, start:start + data['window_size']]
- X_mag_window = torch.from_numpy(X_mag_window).to(device)
-
- pred = model.predict(X_mag_window, aggressiveness)
-
- pred = pred.detach().cpu().numpy()
- preds.append(pred[0])
-
- pred = np.concatenate(preds, axis=2)
-
- text_widget.write('Done!\n')
- return pred
-
- def preprocess(X_spec):
- X_mag = np.abs(X_spec)
- X_phase = np.angle(X_spec)
-
- return X_mag, X_phase
-
- X_mag, X_phase = preprocess(X_spec)
-
- coef = X_mag.max()
- X_mag_pre = X_mag / coef
-
- n_frame = X_mag_pre.shape[2]
- pad_l, pad_r, roi_size = dataset.make_padding(n_frame,
- data['window_size'], model.offset)
- n_window = int(np.ceil(n_frame / roi_size))
-
- X_mag_pad = np.pad(
- X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
-
- pred = _execute(X_mag_pad, roi_size, n_window,
- device, model, aggressiveness)
- pred = pred[:, :, :n_frame]
-
- if data['tta']:
- pad_l += roi_size // 2
- pad_r += roi_size // 2
- n_window += 1
-
- X_mag_pad = np.pad(
- X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
-
- pred_tta = _execute(X_mag_pad, roi_size, n_window,
- device, model, aggressiveness)
- pred_tta = pred_tta[:, :, roi_size // 2:]
- pred_tta = pred_tta[:, :, :n_frame]
-
- return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.j * X_phase)
- else:
- return pred * coef, X_mag, np.exp(1.j * X_phase)
-
- aggressiveness = {'value': args.aggressiveness, 'split_bin': mp.param['band'][1]['crop_stop']}
-
- if data['tta']:
- text_widget.write(base_text + "Running Inferences (TTA)... \n")
- else:
- text_widget.write(base_text + "Running Inference... \n")
-
- pred, X_mag, X_phase = inference(X_spec_m,
- device,
- model, aggressiveness)
-
- update_progress(**progress_kwargs,
- step=0.85)
-
- # Postprocess
- if data['postprocess']:
- text_widget.write(base_text + 'Post processing... ')
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.85)
-
- # Inverse stft
- text_widget.write(base_text + 'Inverse stft of instruments and vocals... ') # nopep8
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, y_spec_m, input_high_end, mp)
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
-
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, v_spec_m, input_high_end, mp)
-
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
-
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.9)
-
- # Save output music files
- text_widget.write(base_text + 'Saving Files... ')
- save_files(wav_instrument, wav_vocals)
- text_widget.write('Done!\n')
-
- # Save output image
- if data['output_image']:
- with open('{}_Instruments.jpg'.format(base_name), mode='wb') as f:
- image = spec_utils.spectrogram_to_image(y_spec_m)
- _, bin_image = cv2.imencode('.jpg', image)
- bin_image.tofile(f)
- with open('{}_Vocals.jpg'.format(base_name), mode='wb') as f:
- image = spec_utils.spectrogram_to_image(v_spec_m)
- _, bin_image = cv2.imencode('.jpg', image)
- bin_image.tofile(f)
-
- text_widget.write(base_text + 'Clearing CUDA Cache... ')
-
- torch.cuda.empty_cache()
- time.sleep(3)
-
- text_widget.write('Done!\n')
-
- text_widget.write(base_text + 'Completed Seperation!\n\n')
-
- # Emsembling Outputs
- def get_files(folder="", prefix="", suffix=""):
- return [f"{folder}{i}" for i in os.listdir(folder) if i.startswith(prefix) if i.endswith(suffix)]
-
- ensambles = [
+ if not data['ensChoose'] == 'User Ensemble':
+ HP1_Models = [
{
- 'algorithm':'min_mag',
- 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
- 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
- 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
- 'type': 'Instrumentals'
+ 'model_name':'1_HP-UVR',
+ 'model_name_c':'1st HP Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/1_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
},
{
- 'algorithm':'max_mag',
- 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
- 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
- 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
- 'type': 'Vocals'
+ 'model_name':'2_HP-UVR',
+ 'model_name_c':'2nd HP Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 2/2'
+ }
+ ]
+
+ HP2_Models = [
+ {
+ 'model_name':'7_HP2-UVR',
+ 'model_name_c':'1st HP2 Model',
+ 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
+ 'model_param_name':'3band_44100_msb2',
+ 'model_location':'models/Main_Models/7_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 1/3'
+ },
+ {
+ 'model_name':'8_HP2-UVR',
+ 'model_name_c':'2nd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/8_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 2/3'
+ },
+ {
+ 'model_name':'9_HP2-UVR',
+ 'model_name_c':'3rd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/9_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 3/3'
+ }
+ ]
+
+ All_HP_Models = [
+ {
+ 'model_name':'7_HP2-UVR',
+ 'model_name_c':'1st HP2 Model',
+ 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
+ 'model_param_name':'3band_44100_msb2',
+ 'model_location':'models/Main_Models/7_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 1/5'
+
+ },
+ {
+ 'model_name':'8_HP2-UVR',
+ 'model_name_c':'2nd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/8_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 2/5'
+
+ },
+ {
+ 'model_name':'9_HP2-UVR',
+ 'model_name_c':'3rd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/9_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 3/5'
+ },
+ {
+ 'model_name':'1_HP-UVR',
+ 'model_name_c':'1st HP Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/1_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 4/5'
+ },
+ {
+ 'model_name':'2_HP-UVR',
+ 'model_name_c':'2nd HP Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 5/5'
+ }
+ ]
+
+ Vocal_Models = [
+ {
+ 'model_name':'3_HP-Vocal-UVR',
+ 'model_name_c':'1st Vocal Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/3_HP-Vocal-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
+ },
+ {
+ 'model_name':'4_HP-Vocal-UVR',
+ 'model_name_c':'2nd Vocal Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/4_HP-Vocal-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 2/2'
}
]
- for i, e in tqdm(enumerate(ensambles), desc="Ensembling..."):
-
- text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
-
- wave, specs = {}, {}
-
- mp = ModelParameters(e['model_params'])
-
- for i in range(len(e['files'])):
- spec = {}
-
- for d in range(len(mp.param['band']), 0, -1):
- bp = mp.param['band'][d]
-
- if d == len(mp.param['band']): # high-end band
- wave[d], _ = librosa.load(
- e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
-
- if len(wave[d].shape) == 1: # mono to stereo
- wave[d] = np.array([wave[d], wave[d]])
- else: # lower bands
- wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
-
- spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
-
- specs[i] = spec_utils.combine_spectrograms(spec, mp)
-
- del wave
+ mdx_vr = [
+ {
+ 'model_name':'VR_Model',
+ 'mdx_model_name': 'UVR_MDXNET_9703',
+ 'model_name_c':'VR Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
+ }
+ ]
- sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
- spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
- specs), mp), mp.param['sr'])
+ if data['ensChoose'] == 'HP Models':
+ loops = HP1_Models
+ ensefolder = 'HP_Models_Ensemble_Outputs'
+ ensemode = 'HP_Models'
+ if data['ensChoose'] == 'HP2 Models':
+ loops = HP2_Models
+ ensefolder = 'HP2_Models_Ensemble_Outputs'
+ ensemode = 'HP2_Models'
+ if data['ensChoose'] == 'All HP/HP2 Models':
+ loops = All_HP_Models
+ ensefolder = 'All_HP_HP2_Models_Ensemble_Outputs'
+ ensemode = 'All_HP_HP2_Models'
+ if data['ensChoose'] == 'Vocal Models':
+ loops = Vocal_Models
+ ensefolder = 'Vocal_Models_Ensemble_Outputs'
+ ensemode = 'Vocal_Models'
+ if data['ensChoose'] == 'MDX-Net/VR Ensemble':
+ loops = mdx_vr
+ ensefolder = 'MDX_VR_Ensemble_Outputs'
+ ensemode = 'MDX-Net_VR'
+
+
+ #Prepare Audiofile(s)
+ for file_num, music_file in enumerate(data['input_paths'], start=1):
+ print(data['input_paths'])
+ # -Get text and update progress-
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=file_num)
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': file_num}
+ update_progress(**progress_kwargs,
+ step=0)
- if not data['save']: # Deletes all outputs if Save All Outputs: is checked
- files = e['files']
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+
+ #Prepare to loop models
+ for i, c in tqdm(enumerate(loops), disable=True, desc='Iterations..'):
+
+ if hp2_ens == 'off' and loops == HP2_Models:
+ text_widget.write(base_text + 'You must install the UVR expansion pack in order to use this ensemble.\n')
+ text_widget.write(base_text + 'Please install the expansion pack or choose another ensemble.\n')
+ text_widget.write(base_text + 'See the \"Updates\" tab in the Help Guide for installation instructions.\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL)
+ return
+ elif hp2_ens == 'off' and loops == All_HP_Models:
+ text_widget.write(base_text + 'You must install the UVR expansion pack in order to use this ensemble.\n')
+ text_widget.write(base_text + 'Please install the expansion pack or choose another ensemble.\n')
+ text_widget.write(base_text + 'See the \"Updates\" tab in the Help Guide for installation instructions.\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL)
+ return
+
+ presentmodel = Path(c['model_location'])
+
+ if presentmodel.is_file():
+ print(f'The file {presentmodel} exist')
+ else:
+ text_widget.write(base_text + 'Model "' + c['model_name'] + '.pth" is missing, moving to next... \n\n')
+ continue
+
+ text_widget.write(c['loop_name'] + '\n\n')
+
+ text_widget.write(base_text + 'Loading ' + c['model_name_c'] + '... ')
+
+ aggresive_set = float(data['agg']/100)
+
+ model_size = math.ceil(os.stat(c['model_location']).st_size / 1024)
+ nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+
+ nets = importlib.import_module('lib_v5.nets' + f'_{nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
+
+ text_widget.write('Done!\n')
+
+ ModelName=(c['model_location'])
+
+ #Package Models
+
+ model_hash = hashlib.md5(open(ModelName,'rb').read()).hexdigest()
+ print(model_hash)
+
+ #v5 Models
+
+ if model_hash == '47939caf0cfe52a0e81442b85b971dfd':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '4e4ecb9764c50a8c414fee6e10395bbe':
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if model_hash == 'e60a1e84803ce4efc0a6551206cc4b71':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'a82f14e75892e55e994376edbf0c8435':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '6dd9eaa6f0420af9f1d403aaafa4cc06':
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if model_hash == '5c7bbca45a187e81abbbd351606164e5':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'd6b2cb685a058a091e5e7098192d3233':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'c1b9f38170a7c90e96f027992eb7c62b':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'c3448ec923fa0edf3d03a19e633faa53':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+
+ #v4 Models
+
+ if model_hash == '6a00461c51c2920fd68937d4609ed6c8':
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if model_hash == '0ab504864d20f1bd378fe9c81ef37140':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '7dd21065bf91c10f7fccb57d7d83b07f':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '80ab74d65e515caa3622728d2de07d23':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == 'edc115e7fc523245062200c00caa847f':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == '28063e9f6ab5b341c5f6d3c67f2045b7':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == 'b58090534c52cbc3e9b5104bad666ef2':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == '0cdab9947f1b0928705f518f3c78ea8f':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == 'ae702fed0238afb5346db8356fe25f13':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ def determineenseFolderName():
+ """
+ Determine the name that is used for the folder and appended
+ to the back of the music files
+ """
+ enseFolderName = ''
+
+ if str(ensefolder):
+ enseFolderName += os.path.splitext(os.path.basename(ensefolder))[0]
+
+ if enseFolderName:
+ enseFolderName = '/' + enseFolderName
+
+ return enseFolderName
+
+ enseFolderName = determineenseFolderName()
+ if enseFolderName:
+ folder_path = f'{data["export_path"]}{enseFolderName}'
+ if not os.path.isdir(folder_path):
+ os.mkdir(folder_path)
+
+ # Determine File Name
+ base_name = f'{data["export_path"]}{enseFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+ enseExport = f'{data["export_path"]}{enseFolderName}/'
+ trackname = f'{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+
+ ModelName_1=(c['model_name'])
+
+ try:
+ ModelName_2=(c['mdx_model_name'])
+ except:
+ pass
+
+ print('Model Parameters:', model_params_d)
+ text_widget.write(base_text + 'Loading assigned model parameters ' + '\"' + param_name + '\"... ')
+
+ mp = ModelParameters(model_params_d)
+
+ text_widget.write('Done!\n')
+
+ #Load model
+ if os.path.isfile(c['model_location']):
+ device = torch.device('cpu')
+ model = nets.CascadedASPPNet(mp.param['bins'] * 2)
+ model.load_state_dict(torch.load(c['model_location'],
+ map_location=device))
+ if torch.cuda.is_available() and data['gpu'] >= 0:
+ device = torch.device('cuda:{}'.format(data['gpu']))
+ model.to(device)
+
+ model_name = os.path.basename(c["model_name"])
+
+ # -Go through the different steps of seperation-
+ # Wave source
+ text_widget.write(base_text + 'Loading audio source... ')
+
+ X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
+
+ bands_n = len(mp.param['band'])
+
+ for d in range(bands_n, 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == bands_n: # high-end band
+ X_wave[d], _ = librosa.load(
+ music_file, bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if X_wave[d].ndim == 1:
+ X_wave[d] = np.asarray([X_wave[d], X_wave[d]])
+ else: # lower bands
+ X_wave[d] = librosa.resample(X_wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ # Stft of wave source
+
+ X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
+ mp.param['mid_side_b2'], mp.param['reverse'])
+
+ if d == bands_n and data['high_end_process'] != 'none':
+ input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
+ input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
+
+ text_widget.write('Done!\n')
+
+ update_progress(**progress_kwargs,
+ step=0.1)
+
+ text_widget.write(base_text + 'Loading the stft of audio source... ')
+ text_widget.write('Done!\n')
+ text_widget.write(base_text + "Please Wait...\n")
+
+ X_spec_m = spec_utils.combine_spectrograms(X_spec_s, mp)
+
+ del X_wave, X_spec_s
+
+ def inference(X_spec, device, model, aggressiveness):
+
+ def _execute(X_mag_pad, roi_size, n_window, device, model, aggressiveness):
+ model.eval()
+
+ with torch.no_grad():
+ preds = []
+
+ iterations = [n_window]
+
+ total_iterations = sum(iterations)
+
+ text_widget.write(base_text + "Processing "f"{total_iterations} Slices... ")
+
+ for i in tqdm(range(n_window)):
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.8/n_window * i)))
+ start = i * roi_size
+ X_mag_window = X_mag_pad[None, :, :, start:start + data['window_size']]
+ X_mag_window = torch.from_numpy(X_mag_window).to(device)
+
+ pred = model.predict(X_mag_window, aggressiveness)
+
+ pred = pred.detach().cpu().numpy()
+ preds.append(pred[0])
+
+ pred = np.concatenate(preds, axis=2)
+
+ text_widget.write('Done!\n')
+ return pred
+
+ def preprocess(X_spec):
+ X_mag = np.abs(X_spec)
+ X_phase = np.angle(X_spec)
+
+ return X_mag, X_phase
+
+ X_mag, X_phase = preprocess(X_spec)
+
+ coef = X_mag.max()
+ X_mag_pre = X_mag / coef
+
+ n_frame = X_mag_pre.shape[2]
+ pad_l, pad_r, roi_size = dataset.make_padding(n_frame,
+ data['window_size'], model.offset)
+ n_window = int(np.ceil(n_frame / roi_size))
+
+ X_mag_pad = np.pad(
+ X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
+
+ pred = _execute(X_mag_pad, roi_size, n_window,
+ device, model, aggressiveness)
+ pred = pred[:, :, :n_frame]
+
+ if data['tta']:
+ pad_l += roi_size // 2
+ pad_r += roi_size // 2
+ n_window += 1
+
+ X_mag_pad = np.pad(
+ X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
+
+ pred_tta = _execute(X_mag_pad, roi_size, n_window,
+ device, model, aggressiveness)
+ pred_tta = pred_tta[:, :, roi_size // 2:]
+ pred_tta = pred_tta[:, :, :n_frame]
+
+ return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.j * X_phase)
+ else:
+ return pred * coef, X_mag, np.exp(1.j * X_phase)
+
+ aggressiveness = {'value': aggresive_set, 'split_bin': mp.param['band'][1]['crop_stop']}
+
+ if data['tta']:
+ text_widget.write(base_text + "Running Inferences (TTA)... \n")
+ else:
+ text_widget.write(base_text + "Running Inference... \n")
+
+ pred, X_mag, X_phase = inference(X_spec_m,
+ device,
+ model, aggressiveness)
+
+ update_progress(**progress_kwargs,
+ step=0.85)
+
+ # Postprocess
+ if data['postprocess']:
+ try:
+ text_widget.write(base_text + 'Post processing...')
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ text_widget.write(' Done!\n')
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Post process failed, check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run Post Processing on "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ # Inverse stft
+ # nopep8
+ y_spec_m = pred * X_phase
+ v_spec_m = X_spec_m - y_spec_m
+
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Instrumental... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], y_spec_m, input_high_end, mp)
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+ else:
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Vocals... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], v_spec_m, input_high_end, mp)
+
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+ else:
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+
+
+ update_progress(**progress_kwargs,
+ step=0.9)
+
+ # Save output music files
+ save_files(wav_instrument, wav_vocals)
+
+ # Save output image
+ if data['output_image']:
+ with open('{}_Instruments.jpg'.format(base_name), mode='wb') as f:
+ image = spec_utils.spectrogram_to_image(y_spec_m)
+ _, bin_image = cv2.imencode('.jpg', image)
+ bin_image.tofile(f)
+ with open('{}_Vocals.jpg'.format(base_name), mode='wb') as f:
+ image = spec_utils.spectrogram_to_image(v_spec_m)
+ _, bin_image = cv2.imencode('.jpg', image)
+ bin_image.tofile(f)
+
+ text_widget.write(base_text + 'Completed Seperation!\n\n')
+
+
+ if data['ensChoose'] == 'MDX-Net/VR Ensemble':
+ text_widget.write('Ensemble Mode - Model 2/2\n\n')
+
+ update_progress(**progress_kwargs,
+ step=0)
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ else:
+ if not os.path.isfile("lib_v5\sox\sox.exe"):
+ data['noisereduc_s'] = 'None'
+ data['non_red'] = False
+ widget_text.write(base_text + 'SoX is missing and required for noise reduction.\n')
+ widget_text.write(base_text + 'See the \"More Info\" tab in the Help Guide.\n')
+ widget_text.write(base_text + 'Noise Reduction will be disabled until SoX is available.\n\n')
+
+ e = os.path.join(data["export_path"])
+
+ demucsmodel = 'models/Demucs_Model/demucs_extra-3646af93_org.th'
+
+ pred = Predictor()
+ pred.prediction_setup(demucs_name=demucsmodel,
+ channels=channel_set)
+
+ # split
+ pred.prediction(
+ m=music_file,
+ )
+ else:
+ pass
+
+
+ # Emsembling Outputs
+ def get_files(folder="", prefix="", suffix=""):
+ return [f"{folder}{i}" for i in os.listdir(folder) if i.startswith(prefix) if i.endswith(suffix)]
+
+ voc_inst = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
+ 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
+ 'type': 'Instrumentals'
+ },
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
+ 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
+ 'type': 'Vocals'
+ }
+ ]
+
+ inst = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
+ 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
+ 'type': 'Instrumentals'
+ }
+ ]
+
+ vocal = [
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
+ 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
+ 'type': 'Vocals'
+ }
+ ]
+
+ if data['voc_only']:
+ ensembles = vocal
+ elif data['inst_only']:
+ ensembles = inst
+ else:
+ ensembles = voc_inst
+
+ try:
+ for i, e in tqdm(enumerate(ensembles), desc="Ensembling..."):
+
+ text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
+ specs), mp), mp.param['sr'])
+
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.mp3'.format(e['output']))), format="mp3", bitrate="320k")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}".\n\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.flac'.format(e['output']))), format="flac")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}".\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ text_widget.write("Done!\n")
+ except:
+ text_widget.write('\n' + base_text + 'Not enough files to ensemble.')
+ pass
+
+ update_progress(**progress_kwargs,
+ step=0.95)
+ text_widget.write("\n")
+
+ try:
+ if not data['save']: # Deletes all outputs if Save All Outputs isn't checked
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
for file in files:
os.remove(file)
+ if not data['save']:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ if data['save'] and data['saveFormat'] == 'Mp3':
+ try:
+ text_widget.write(base_text + 'Saving all ensemble outputs in Mp3... ')
+ path = enseExport
+ #Change working directory
+ os.chdir(path)
+ audio_files = os.listdir()
+ for file in audio_files:
+ #spliting the file into the name and the extension
+ name, ext = os.path.splitext(file)
+ if ext == ".wav":
+ if trackname in file:
+ musfile = pydub.AudioSegment.from_wav(file)
+ #rename them using the old name + ".wav"
+ musfile.export("{0}.mp3".format(name), format="mp3", bitrate="320k")
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ text_widget.write('Done!\n\n')
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ except Exception as e:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'\nError Received while attempting to save ensembled outputs as mp3s.\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['save'] and data['saveFormat'] == 'Flac':
+ try:
+ text_widget.write(base_text + 'Saving all ensemble outputs in Flac... ')
+ path = enseExport
+ #Change working directory
+ os.chdir(path)
+ audio_files = os.listdir()
+ for file in audio_files:
+ #spliting the file into the name and the extension
+ name, ext = os.path.splitext(file)
+ if ext == ".wav":
+ if trackname in file:
+ musfile = pydub.AudioSegment.from_wav(file)
+ #rename them using the old name + ".wav"
+ musfile.export("{0}.flac".format(name), format="flac")
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ text_widget.write('Done!\n\n')
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+
+ except Exception as e:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'\nError Received while attempting to ensembled outputs as Flacs.\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
+ try:
+ os.remove('temp.wav')
+ except:
+ pass
+
+ if len(os.listdir(enseExport)) == 0: #Check if the folder is empty
+ shutil.rmtree(folder_path) #Delete folder if empty
+
+ else:
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': len(data['input_paths'])}
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=len(data['input_paths']))
+
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+ music_file = data['input_paths']
+ if len(data['input_paths']) <= 1:
+ text_widget.write(base_text + "Not enough files to process.\n")
+ pass
+ else:
+ update_progress(**progress_kwargs,
+ step=0.2)
+
+ savefilename = (data['input_paths'][0])
+ trackname1 = f'{os.path.splitext(os.path.basename(savefilename))[0]}'
+
+ insts = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output':'{}_User_Ensembled_(Min Spec)'.format(trackname1),
+ 'type': 'Instrumentals'
+ }
+ ]
+
+ vocals = [
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_User_Ensembled_(Max Spec)'.format(trackname1),
+ 'type': 'Vocals'
+ }
+ ]
+
+ invert_spec = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_diff_si'.format(trackname1),
+ 'type': 'Spectral Inversion'
+ }
+ ]
+
+ invert_nor = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_diff_ni'.format(trackname1),
+ 'type': 'Normal Inversion'
+ }
+ ]
+
+ if data['algo'] == 'Instrumentals (Min Spec)':
+ ensem = insts
+ if data['algo'] == 'Vocals (Max Spec)':
+ ensem = vocals
+ if data['algo'] == 'Invert (Spectral)':
+ ensem = invert_spec
+ if data['algo'] == 'Invert (Normal)':
+ ensem = invert_nor
+
+ #Prepare to loop models
+ if data['algo'] == 'Instrumentals (Min Spec)' or data['algo'] == 'Vocals (Max Spec)':
+ for i, e in tqdm(enumerate(ensem), desc="Ensembling..."):
+ text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(data['input_paths'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ data['input_paths'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
+ specs), mp), mp.param['sr'])
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.mp3'.format(e['output']))), format="mp3", bitrate="320k")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3.')
+ text_widget.write('\n' + base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ text_widget.write(base_text + f'Complete!\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run user ensemble:\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL)
+
+ return
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.flac'.format(e['output']))), format="flac")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Failed to save output as Flac.\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ text_widget.write(base_text + f'Complete!\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run user ensemble:\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL)
+ return
+
text_widget.write("Done!\n")
+ if data['algo'] == 'Invert (Spectral)' and data['algo'] == 'Invert (Normal)':
+ if len(data['input_paths']) != 2:
+ text_widget.write(base_text + "Invalid file count.\n")
+ pass
+ else:
+ for i, e in tqdm(enumerate(ensem), desc="Inverting..."):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(data['input_paths'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ data['input_paths'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ if data['algo'] == 'Invert (Spectral)':
+ text_widget.write(base_text + "Performing " + e['type'] + "... ")
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+ if data['algo'] == 'Invert (Normal)':
+ v_spec = specs[0] - specs[1]
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(v_spec, mp), mp.param['sr'])
+ text_widget.write("Done!\n")
+
+
- update_progress(**progress_kwargs,
- step=0.95)
- text_widget.write("\n")
-
except Exception as e:
traceback_text = ''.join(traceback.format_tb(e.__traceback__))
- message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\nFile: {music_file}\nPlease contact the creator and attach a screenshot of this error with the file and settings that caused it!'
- tk.messagebox.showerror(master=window,
- title='Untracked Error',
- message=message)
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmissing in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application could not detect this MDX-Net model on your system.\n')
+ text_widget.write(f'Please make sure all the models are present in the correct directory.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application could not detect this MDX-Net model on your system.\n' +
+ f'Please make sure all the models are present in the correct directory.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmemerror in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
print(traceback_text)
print(type(e).__name__, e)
print(message)
- progress_var.set(0)
- button_widget.configure(state=tk.NORMAL) #Enable Button
- return
-
- if len(os.listdir(enseExport)) == 0: #Check if the folder is empty
- shutil.rmtree(folder_path) #Delete folder if empty
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
+ progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
update_progress(**progress_kwargs,
step=1)
-
- print('Done!')
-
- os.remove('temp.wav')
+
+ print('Done!')
+
progress_var.set(0)
- text_widget.write(f'Conversions Completed!\n')
+ if not data['ensChoose'] == 'User Ensemble':
+ text_widget.write(base_text + f'Conversions Completed!\n')
+ elif data['algo'] == 'Instrumentals (Min Spec)' and len(data['input_paths']) <= 1 or data['algo'] == 'Vocals (Max Spec)' and len(data['input_paths']) <= 1:
+ text_widget.write(base_text + f'Please select 2 or more files to use this feature and try again.\n')
+ elif data['algo'] == 'Instrumentals (Min Spec)' or data['algo'] == 'Vocals (Max Spec)':
+ text_widget.write(base_text + f'Ensemble Complete!\n')
+ elif len(data['input_paths']) != 2 and data['algo'] == 'Invert (Spectral)' or len(data['input_paths']) != 2 and data['algo'] == 'Invert (Normal)':
+ text_widget.write(base_text + f'Please select exactly 2 files to extract difference.\n')
+ elif data['algo'] == 'Invert (Spectral)' or data['algo'] == 'Invert (Normal)':
+ text_widget.write(base_text + f'Complete!\n')
+
text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) #Enable Button
diff --git a/lib_v5/fonts/centurygothic/GOTHIC.TTF b/lib_v5/fonts/centurygothic/GOTHIC.TTF
new file mode 100644
index 0000000..c60a324
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHIC.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICB.TTF b/lib_v5/fonts/centurygothic/GOTHICB.TTF
new file mode 100644
index 0000000..d3577b9
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICB.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICBI.TTF b/lib_v5/fonts/centurygothic/GOTHICBI.TTF
new file mode 100644
index 0000000..d01cefa
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICBI.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICI.TTF b/lib_v5/fonts/centurygothic/GOTHICI.TTF
new file mode 100644
index 0000000..777a6d8
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICI.TTF differ
diff --git a/lib_v5/fonts/unispace/unispace.ttf b/lib_v5/fonts/unispace/unispace.ttf
new file mode 100644
index 0000000..6151186
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_bd.ttf b/lib_v5/fonts/unispace/unispace_bd.ttf
new file mode 100644
index 0000000..5312426
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_bd.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_bd_it.ttf b/lib_v5/fonts/unispace/unispace_bd_it.ttf
new file mode 100644
index 0000000..8f14509
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_bd_it.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_it.ttf b/lib_v5/fonts/unispace/unispace_it.ttf
new file mode 100644
index 0000000..be4b6e8
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_it.ttf differ
diff --git a/lib_v5/layers.py b/lib_v5/layers.py
new file mode 100644
index 0000000..e48d70b
--- /dev/null
+++ b/lib_v5/layers.py
@@ -0,0 +1,116 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/layers_33966KB.py b/lib_v5/layers_33966KB.py
new file mode 100644
index 0000000..d410a21
--- /dev/null
+++ b/lib_v5/layers_33966KB.py
@@ -0,0 +1,122 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/layers_537227KB.py b/lib_v5/layers_537227KB.py
new file mode 100644
index 0000000..d410a21
--- /dev/null
+++ b/lib_v5/layers_537227KB.py
@@ -0,0 +1,122 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/nets.py b/lib_v5/nets.py
new file mode 100644
index 0000000..b5a8417
--- /dev/null
+++ b/lib_v5/nets.py
@@ -0,0 +1,113 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers
+from lib_v5 import spec_utils
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/nets_33966KB.py b/lib_v5/nets_33966KB.py
new file mode 100644
index 0000000..07e2b8c
--- /dev/null
+++ b/lib_v5/nets_33966KB.py
@@ -0,0 +1,112 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers_33966KB as layers
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16, 32)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/nets_537227KB.py b/lib_v5/nets_537227KB.py
new file mode 100644
index 0000000..566e3f9
--- /dev/null
+++ b/lib_v5/nets_537227KB.py
@@ -0,0 +1,113 @@
+import torch
+import numpy as np
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers_537238KB as layers
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 64)
+ self.stg1_high_band_net = BaseASPPNet(2, 64)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(32, 64)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(130, 64, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(64, 128)
+
+ self.out = nn.Conv2d(128, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(64, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/sox/Sox goes here.txt b/lib_v5/sox/Sox goes here.txt
new file mode 100644
index 0000000..2d03d25
--- /dev/null
+++ b/lib_v5/sox/Sox goes here.txt
@@ -0,0 +1 @@
+Sox goes here
\ No newline at end of file
diff --git a/lib_v5/sox/mdxnetnoisereduc.prof b/lib_v5/sox/mdxnetnoisereduc.prof
new file mode 100644
index 0000000..e84270d
--- /dev/null
+++ b/lib_v5/sox/mdxnetnoisereduc.prof
@@ -0,0 +1,2 @@
+Channel 0: -7.009383, -9.291822, -8.961462, -8.988426, -8.133916, -7.550877, -6.823206, -8.324312, -7.926179, -8.284890, -7.006778, -7.520769, -6.676938, -7.599460, -7.296249, -7.862341, -7.603068, -7.957884, -6.943116, -7.064777, -6.617763, -6.976608, -6.474446, -6.976694, -6.775996, -7.173531, -6.239498, -7.433953, -7.435424, -7.556505, -6.661156, -7.537329, -6.869858, -7.345681, -6.348115, -7.624833, -7.356656, -7.397345, -7.268706, -8.009533, -7.879307, -7.206394, -7.595149, -8.183835, -7.877466, -7.849053, -6.575886, -7.970041, -7.973623, -8.654870, -8.238590, -8.322275, -7.080089, -8.381072, -8.166994, -8.211880, -6.978457, -8.440431, -8.660172, -8.568000, -7.374925, -7.825880, -7.727026, -8.436455, -8.058270, -7.776336, -7.163500, -8.324635, -7.496432, -8.231029, -8.168671, -8.803044, -8.365684, -8.284722, -7.717031, -7.899992, -6.716974, -7.789536, -8.123308, -8.718283, -8.127323, -8.608119, -7.955237, -8.195423, -8.562821, -8.923180, -8.620318, -8.362193, -7.892359, -9.106509, -8.866467, -8.334931, -8.432192, -7.981750, -8.118553, -8.357300, -8.303634, -8.951071, -8.357619, -8.628114, -8.194091, -8.329184, -8.479573, -9.059311, -8.928500, -8.971485, -8.930757, -7.888778, -8.512952, -8.701514, -8.509488, -7.927048, -8.980245, -9.453869, -8.502084, -9.179351, -9.352121, -8.612514, -8.515877, -8.990332, -8.064332, -9.353903, -9.226296, -8.582130, -8.062571, -8.975781, -8.985588, -9.084478, -9.475922, -9.627264, -8.866921, -9.788176, -9.405965, -9.690348, -9.697125, -9.834449, -9.723495, -9.551198, -9.067146, -8.391362, -8.062964, -8.664368, -8.834053, -9.365320, -8.774260, -8.826809, -8.938656, -8.571966, -9.301930, -8.476783, -9.083561, -9.606360, -9.013194, -9.633930, -9.361920, -8.814354, -8.210675, -8.741395, -8.973019, -9.735017, -9.445080, -9.970575, -9.387616, -8.885903, -8.364945, -8.181610, -9.367054, -9.632653, -9.174005, -9.669417, -9.632316, -8.792030, -8.639747, -8.757731, -8.189369, -8.609264, -9.203773, -9.027173, -9.267983, -9.038571, -8.480053, -8.989291, -9.334651, -8.989846, -8.505489, -9.093593, -8.603022, -8.935084, -8.995838, -9.807545, -9.936930, -9.858782, -9.525642, -9.342257, -9.687481, -10.109383, -9.415607, -9.960437, -9.511531, -9.512959, -9.410252, -9.463380, -8.009910, -9.010445, -7.930557, -8.907247, -8.696819, -7.628914, -8.656908, -9.540818, -9.834308, -10.149171, -9.603844, -9.368526, -9.262289, -9.177496, -7.941667, -8.894559, -9.577237, -9.213502, -8.329892, -8.875650, -8.551803, -7.293085, -7.970225, -8.689839, -9.213015, -8.729056, -8.370025, -9.476679, -9.801536, -8.779216, -7.794588, -8.743565, -8.677839, -8.659505, -8.530433, -9.471109, -8.952149, -9.026676, -8.581315, -8.305970, -7.698102, -9.075556, -8.994505, -9.525378, -9.427664, -8.896355, -7.806924, -8.713507, -8.001523, -8.820920, -8.825943, -9.033789, -8.943538, -8.305934, -7.843387, -8.222633, -9.394885, -9.639977, -9.382100, -9.858908, -9.861235, -9.617870, -9.572075, -8.937280, -7.900751, -8.817468, -8.367288, -8.198920, -8.835616, -9.120554, -9.430250, -9.599668, -8.890237, -9.182921, -9.068647, -9.198983, -9.219759, -8.444858, -8.306649, -9.081246, -9.658321, -9.175613, -9.559673, -9.202353, -8.468946, -8.959963, -8.611696, -9.287626, -9.178090, -9.829329, -9.418147, -8.433018, -6.759007, -7.992561, -8.209750, -8.367482, -8.160244, -8.659845, -8.142351, -8.449805, -9.052549, -8.108782, -9.131697, -8.656035, -8.754751, -8.799905, -9.252805, -9.666502, -8.742819, -8.779405, -9.290927, -9.100673, -8.813067, -7.968793, -8.372980, -8.334048, -8.766193, -8.525885, -8.295012, -9.267423, -8.512022, -8.716763, -7.543527, -8.133463, -8.899957, -8.884852, -8.879415, -8.921800, -8.989868, -8.456031, -8.742332, -8.387804, -9.199132, -9.269713, -8.533924, -9.031591, -9.510307, -9.003630, -8.032389, -8.199724, -9.178456, -9.109508, -8.830519, -8.833589, -9.138852, -8.359014, -9.055459, -9.124282, -8.931469, -8.293803, -8.784939, -8.829195, -8.204985, -8.832497, -9.291157, -9.229586, -8.902256, -7.836384, -8.558482, -9.045199, -8.784686, -8.640361, -8.122143, -8.856282, -9.933563, -10.433572, -10.053477, -9.901992, -9.234422, -8.272216, -7.767568, -8.634153, -9.037672, -7.966586, -7.879588, -8.073919, -7.618028, -8.733914, -9.367538, -9.360283, -8.472114, -8.424832, -8.244030, -8.266778, -8.279402, -8.488133, -8.574222, -8.015083, -7.603164, -7.773276, -7.969313, -8.463429, -8.327254, -8.908369, -8.842388, -8.697819, -9.069319, -8.471298, -8.487786, -7.722121, -7.005715, -6.071240, -4.913710, -5.252938, -6.890169, -8.112794, -8.627293, -8.763681, -8.730070, -8.663003, -8.490945, -8.165999, -7.835065, -7.929111, -8.760281, -9.092809, -8.427891, -8.396054, -7.063385, -8.432428, -8.356983, -8.770448, -8.572601, -8.279242, -8.050529, -9.172235, -9.494339, -9.115856, -8.913443, -9.234514, -8.266346, -8.655711, -7.904694, -8.750291, -8.669807, -8.733426, -8.195509, -8.445010, -8.608845, -9.364661, -8.545942, -9.320732, -8.908144, -8.906418, -8.977945, -8.351475, -8.425015, -8.580469, -8.635973, -8.587179, -8.825187, -8.613693, -8.572787, -9.008575, -9.139839, -8.730886, -8.378273, -8.104312, -7.693113, -8.144767, -7.909862, -8.660356, -8.560781, -8.402486, -8.329734, -8.549006, -8.467747, -7.797524, -8.701290, -8.745170, -9.123959, -8.828640, -8.034152, -8.244606, -7.922297, -8.304344, -8.390489, -8.384267, -8.804485, -8.274789, -7.641120, -7.419797, -6.875395, -7.779922, -8.285890, -8.435658, -8.243375, -8.234133, -8.147679, -7.876873, -7.560720, -8.453065, -7.912884, -8.321675, -8.351012, -8.551875, -8.245539, -8.157014, -8.045531, -8.802874, -7.939998, -8.531658, -8.286127, -8.426950, -7.872053, -7.950769, -8.103668, -7.361780, -7.233630, -8.588113, -8.391391, -8.025829, -7.778002, -6.812353, -6.892645, -8.379886, -8.968739, -9.232736, -7.678606, -8.519589, -7.233673, -7.732607, -7.712150, -8.588383, -7.141524, -8.350538, -7.687734, -8.350335, -7.299619, -7.251563, -7.551582, -7.601188, -8.913805, -8.327199, -8.351825, -9.285121, -8.206786, -7.760271, -5.924285, -7.253280, -7.920683, -8.456389, -8.348553, -8.304132, -7.914664, -7.378574, -6.740644, -8.366895, -7.828516, -8.495502, -8.358516, -8.638541, -8.803589, -7.815868, -6.526936, -8.311996, -8.795187, -8.682474, -7.771255, -8.021541, -7.061438, -8.140287, -8.479327, -8.769970, -9.137885, -8.767818, -8.507115, -7.818171, -7.023338, -6.684543, -7.590823, -7.973853, -7.125487, -6.444645, -5.015516, -5.527578, -4.825749, -6.076069, -6.067105, -6.832324, -6.415292, -7.687704, -7.876131, -8.185242, -7.719656, -8.129504, -7.591390, -7.471135, -8.264959, -7.372910, -6.003157, -7.699708, -8.063796, -6.937130, -6.498588, -6.515582, -6.480911, -6.705885, -7.971720, -8.244526, -7.773425, -8.179802, -7.852663, -7.736978, -7.450927, -7.798478, -7.171562, -7.725062, -7.005856, -6.939411, -7.545801, -7.298831, -7.866823, -7.788211, -6.324419, -6.972910, -6.354499, -6.692432, -7.116762, -8.336053, -8.031844, -7.638197, -6.962282, -7.762571, -7.219688, -7.684484, -6.576585, -6.971768, -6.049053, -5.645847, -5.826155, -5.018756, -6.294459, -7.700381, -8.087517, -7.940284, -8.351140, -7.342774, -5.678021, -7.577646, -8.088142, -7.801032, -6.492934, -7.910668, -7.328195, -7.128594, -6.916883, -5.799251, -6.564095, -6.370745, -5.558840, -7.342127, -7.275418, -6.746891, -7.759083, -6.735355, -6.476465, -6.283120, -7.176216, -7.664367, -6.443789, -5.538641, -5.694131, -7.232028, -7.065130, -7.523064, -6.623515, -5.389147, -3.544363, -5.611296, -6.213579, -6.530970, -6.581829, -6.395981, -7.651325, -7.012158, -8.015069, -7.575516, -7.032994, -5.677541, -3.718229, -6.020396, -7.988893, -9.343635, -9.945617, -10.323884, -10.642690, -10.876016, -11.078479, -11.255501, -11.395584, -11.483764, -11.557805, -11.698310, -11.737680, -11.840640, -11.912717, -11.909139, -11.977159, -11.978605, -12.038353, -12.093234, -12.111259, -12.121384, -12.176933, -12.171291, -12.176199, -12.198986, -12.233503, -12.275017, -12.265485, -12.274396, -12.241486, -12.261465, -12.282915, -12.275353, -12.276109, -12.255538, -12.296432, -12.243854, -12.250940, -12.222560, -12.250113, -12.183066, -12.247768, -12.242023, -12.285899, -12.235859, -12.219860, -12.231251, -12.265896, -12.266792, -12.217250, -12.292002, -12.251619, -12.283025, -12.208677, -12.143500, -12.194249, -12.168472, -12.159037, -12.136466, -12.175126, -12.182810, -12.148365, -12.157288, -12.111798, -12.070856, -12.088792, -12.088619, -12.050185, -12.073867, -12.053141, -12.079345, -12.013352, -11.999766, -12.055408, -11.965831, -11.985056, -11.968968, -11.961904, -11.959881, -12.045696, -11.965464, -11.966563, -11.887108, -11.874594, -11.889680, -11.904971, -11.870472, -11.882454, -11.926828, -11.848092, -11.827531, -11.810616, -11.798046, -11.860422, -11.843547, -11.817146, -11.766209, -11.751227, -11.771116, -11.767917, -11.759330, -11.740242, -11.770084, -11.770973, -11.770555, -11.702766, -11.672210, -11.656888, -11.644030, -11.633999, -11.688310, -11.612173, -11.615041, -11.608862, -11.675717, -11.672152, -11.619037, -11.607554, -11.621890, -11.539628, -11.582389, -11.505353, -11.506137, -11.516038, -11.488252, -11.464626, -11.555939, -11.470755, -11.477320, -11.503404, -11.444288, -11.514609, -11.442399, -11.395453, -11.417263, -11.507715, -11.409320, -11.432245, -11.437587, -11.405253, -11.347139, -11.368037, -11.442106, -11.416598, -11.311483, -11.318091, -11.345511, -11.311282, -11.263789, -11.369459, -11.318594, -11.253346, -11.275534, -11.303650, -11.246404, -11.238109, -11.330812, -11.262724, -11.256104, -11.304247, -11.222750, -11.260267, -11.268924, -11.264678, -11.178239, -11.215854, -11.183023, -11.236221, -11.190973, -11.213630, -11.148606, -11.194403, -11.171699, -11.036693, -11.178444, -11.212547, -11.126407, -11.096385, -11.113798, -11.100501, -11.117359, -11.137890, -11.133387, -11.173369, -11.087261, -11.093644, -11.072756, -11.086142, -11.111346, -11.077774, -11.041398, -11.115988, -11.051571, -11.023808, -11.007654, -10.986833, -11.045266, -11.028788, -10.972257, -11.024872, -11.023347, -10.963393, -10.999147, -10.988231, -11.024704, -10.955430, -10.948047, -10.976632, -10.963916, -10.944159, -10.941738, -10.988978, -10.986086, -10.893852, -10.970823, -10.930062, -10.907232, -10.985453, -10.946364, -10.870025, -10.952854, -10.817455, -10.883003, -10.932498, -10.827333, -10.860927, -10.907078, -10.876232, -10.887182, -10.870004, -10.914099, -10.877161, -10.936840, -10.929503, -10.838376, -10.858479, -10.841352, -10.896008, -10.929105, -10.945358, -11.049899, -11.024334, -11.083250, -11.577282, -11.331383, -11.528310, -11.884033, -12.191691, -12.494642, -12.393940, -11.879013, -11.514395, -11.288580, -11.240140, -11.185865, -11.183484, -11.195589, -11.173580, -11.232604, -11.226796, -11.173893, -11.171396, -11.198562, -11.178386, -11.154948, -11.233259, -11.218584, -11.263170, -11.226203, -11.212432, -11.234622, -11.203861, -11.141663, -11.252211, -11.182387, -11.184281, -11.251010, -11.153616, -11.200994, -11.251609, -11.229125, -11.234426, -11.188760, -11.167431, -11.214060, -11.189217, -11.169435, -11.176277, -11.215827, -11.224740, -11.252942, -11.188585, -11.259495, -11.175788, -11.209007, -11.186180, -11.269020, -11.167184, -11.239420, -11.246427, -11.212875, -11.274052, -11.248956, -11.138576, -11.200762, -11.196568, -11.234824, -11.189839, -11.256922, -11.243899, -11.181837, -11.172835, -11.249906, -11.216124, -11.218074, -11.203452, -11.190719, -11.235559, -11.208005, -11.241541, -11.222897, -11.245105, -11.218976, -11.238669, -11.186864, -11.235706, -11.251585, -11.194207, -11.206015, -11.248406, -11.130074, -11.267996, -11.164400, -11.230077, -11.253899, -11.256946, -11.265360, -11.526430, -12.161562, -12.806432
+Channel 1: -4.259930, -6.665874, -8.134066, -8.840438, -8.619794, -7.955403, -8.262574, -8.998555, -9.045693, -8.528444, -7.130245, -7.262262, -6.663597, -7.233217, -6.972096, -6.821386, -6.677742, -7.806568, -7.335373, -7.410591, -6.870041, -7.541009, -7.960963, -8.444545, -8.221375, -7.770029, -7.763016, -8.179813, -7.863228, -8.234585, -8.139375, -8.447256, -7.722274, -7.880364, -6.586095, -7.770856, -7.927386, -8.511121, -8.588671, -8.453915, -8.236507, -8.271281, -8.939804, -7.892449, -8.888687, -8.282051, -8.188881, -8.348185, -7.744533, -8.006490, -7.487299, -8.713056, -9.093363, -8.952080, -8.845392, -9.472238, -8.873316, -8.721225, -8.098806, -8.701453, -8.930824, -8.396164, -8.278354, -9.088575, -8.290803, -8.495568, -8.264076, -8.434325, -8.595228, -8.251158, -7.845592, -8.516354, -7.873776, -8.346703, -8.880695, -8.575607, -8.760291, -8.786157, -8.844520, -8.617285, -8.004654, -8.407488, -8.017504, -8.364023, -8.809873, -8.760958, -7.909836, -8.728406, -8.382615, -9.363587, -9.165038, -9.414248, -9.130792, -9.224532, -8.767155, -8.954391, -9.178588, -9.399056, -8.776269, -9.172440, -8.084314, -8.842681, -9.525107, -10.051264, -9.343119, -9.600515, -8.690162, -8.984976, -9.492682, -9.637033, -9.019089, -9.689909, -9.886874, -9.555185, -8.698978, -9.482370, -9.512797, -9.796427, -9.084339, -9.067111, -8.096872, -9.394472, -9.210224, -9.591035, -8.734660, -9.219631, -9.474369, -9.584915, -9.621107, -8.822695, -8.890237, -9.707699, -8.917385, -9.366862, -9.725400, -9.663552, -9.681070, -9.314154, -9.079782, -8.314726, -7.821788, -9.292004, -9.918605, -9.974658, -8.805674, -9.051614, -8.993109, -8.707320, -9.610121, -9.380853, -9.539219, -9.583693, -8.444094, -9.370004, -9.774833, -9.178371, -8.069433, -8.741679, -9.057518, -9.273414, -9.224139, -9.633160, -8.476246, -9.280371, -7.927913, -9.082052, -9.332532, -9.351880, -8.692086, -9.607157, -8.883523, -8.950102, -7.722098, -8.834408, -8.517441, -9.079045, -9.703975, -9.093547, -9.000713, -8.605949, -8.179986, -9.252756, -9.447043, -8.756150, -8.281525, -8.750285, -8.695918, -9.297653, -8.472452, -9.554568, -9.649224, -9.381518, -9.197469, -7.805096, -7.631302, -8.775340, -8.234345, -9.489371, -9.777892, -9.381069, -8.678194, -8.850762, -7.287530, -8.545574, -7.447676, -8.876554, -9.582433, -9.590407, -9.882222, -9.883838, -9.288763, -9.118943, -7.675229, -8.229518, -7.170421, -7.817407, -7.205565, -8.695884, -9.216897, -9.148524, -7.428808, -8.720323, -8.317363, -8.370560, -7.106984, -8.726242, -9.387314, -8.698427, -8.072460, -8.357757, -7.377579, -8.342648, -7.289837, -8.238201, -8.384848, -8.944333, -8.949400, -9.203900, -9.035657, -9.163540, -8.073293, -7.974755, -7.929166, -8.947936, -9.142023, -9.270968, -9.305846, -8.361058, -8.018343, -8.932560, -8.223735, -8.836396, -7.915270, -8.753596, -8.604981, -8.492489, -8.559630, -9.541150, -9.361395, -9.288562, -8.349491, -9.096639, -9.020768, -9.538647, -9.318568, -8.856726, -8.520123, -9.246026, -8.430225, -8.377248, -8.167982, -8.518759, -9.347731, -9.710631, -9.302118, -8.489496, -7.592235, -7.705674, -7.287686, -8.487080, -8.087019, -8.961322, -9.055279, -9.079551, -8.932386, -8.889071, -7.805691, -8.656663, -7.920151, -8.411662, -8.936442, -9.642854, -8.826767, -8.716343, -7.467595, -8.323562, -8.461170, -8.868902, -8.692887, -8.625588, -8.171611, -9.140244, -9.517572, -9.013833, -8.891995, -8.924587, -7.552063, -8.659528, -9.011218, -9.835388, -9.553982, -8.811605, -8.372470, -9.111942, -8.329686, -8.317845, -8.564806, -7.922851, -7.458095, -7.964257, -7.765472, -8.852958, -8.004261, -8.580846, -7.945783, -8.703115, -8.308766, -8.203026, -7.815558, -8.566113, -8.240727, -8.818314, -8.148007, -8.323301, -8.430678, -8.997805, -7.646616, -8.818527, -8.304271, -8.703316, -7.301023, -8.111465, -9.022206, -9.175094, -8.195924, -9.038541, -8.702284, -7.924984, -7.833028, -8.954045, -8.984037, -8.906318, -8.771588, -8.077010, -7.400714, -8.603812, -9.210019, -9.064473, -8.652490, -8.205794, -7.619889, -8.567104, -8.550753, -8.550062, -7.631665, -8.534122, -9.733936, -9.977779, -9.118277, -9.742090, -9.107510, -8.430905, -8.022441, -8.587177, -9.021651, -7.880519, -7.746123, -7.836301, -6.868521, -8.423772, -8.782660, -9.423576, -8.260281, -8.590183, -7.321841, -8.259229, -7.961996, -8.479307, -7.360967, -7.342826, -7.451933, -7.621740, -6.663265, -8.063039, -7.318747, -8.346091, -7.880221, -8.537465, -7.400912, -7.799035, -7.097081, -7.607987, -6.399781, -5.818133, -4.206942, -4.873427, -5.870036, -7.291239, -7.132577, -8.057511, -7.916516, -8.310016, -7.182425, -8.365717, -8.209022, -8.168317, -7.596393, -8.103685, -6.841571, -7.362644, -7.668583, -8.431250, -7.828101, -7.703382, -6.534189, -7.691038, -6.858395, -8.142296, -8.667139, -8.501014, -7.613063, -8.795669, -7.589070, -8.072585, -7.145250, -8.226945, -7.153139, -8.173641, -7.536234, -8.041589, -7.015898, -7.913368, -7.038860, -8.217951, -7.877144, -8.356038, -8.270323, -7.800798, -8.486864, -7.774801, -8.109586, -9.023869, -8.373515, -8.463743, -8.083220, -8.798285, -8.303820, -8.513109, -8.073146, -8.009741, -7.220683, -7.716941, -6.996583, -7.472267, -7.212493, -7.494446, -7.912122, -8.258996, -7.328467, -7.363515, -7.818997, -7.495634, -6.799818, -7.531826, -6.498136, -7.636568, -6.885640, -7.639394, -6.917420, -7.549028, -6.717033, -7.402769, -6.375102, -6.889420, -6.735350, -7.222528, -6.668705, -7.202723, -6.608903, -7.570821, -7.501699, -7.425125, -7.080040, -8.427832, -7.533368, -7.938439, -7.413480, -8.108686, -6.766507, -7.338324, -7.053434, -8.005589, -7.035327, -7.516874, -7.424109, -8.089847, -7.000190, -7.458596, -7.081159, -6.558933, -5.088411, -7.060199, -6.769171, -7.562777, -6.649964, -6.674577, -6.462755, -6.777149, -6.819967, -8.117656, -7.640822, -7.916130, -6.262249, -7.592839, -6.132151, -7.613210, -6.293193, -7.393553, -6.353974, -7.469313, -6.163464, -6.751505, -6.172511, -7.133448, -6.491663, -7.821720, -6.676021, -7.639304, -6.155329, -7.014252, -5.443317, -6.704660, -5.916575, -6.898118, -6.195959, -7.433244, -6.455409, -7.007600, -6.128975, -7.460167, -6.123561, -7.651618, -7.164772, -7.629981, -6.835324, -6.716437, -5.183644, -6.868895, -6.805713, -7.968579, -7.487688, -7.114592, -5.821909, -7.316700, -6.855646, -7.720102, -6.446047, -7.697660, -6.339335, -7.687504, -6.834591, -6.683082, -6.942220, -6.909783, -5.074804, -6.165250, -6.153298, -5.678282, -4.613012, -5.964366, -5.786907, -6.916967, -6.850884, -7.534286, -8.144188, -7.996600, -6.341528, -7.122040, -5.758266, -7.088390, -5.968180, -6.704577, -6.537925, -7.251836, -6.228176, -6.687443, -6.398175, -6.690834, -5.928494, -6.550750, -6.842618, -7.406426, -5.854750, -7.262702, -6.566095, -7.092973, -6.727913, -7.309717, -6.720907, -6.788705, -5.831271, -6.358783, -6.244705, -6.687904, -7.170726, -7.503015, -6.122330, -6.378451, -5.728226, -6.376993, -6.353649, -7.462792, -7.881882, -7.554917, -7.625055, -7.638963, -6.011956, -6.946953, -6.791678, -6.385592, -5.502690, -4.915271, -3.416375, -4.899525, -4.581249, -6.402817, -5.971680, -7.012322, -6.136549, -6.824212, -5.319725, -6.310439, -4.835482, -6.512325, -5.837218, -7.188224, -6.723541, -6.708874, -6.554284, -5.596497, -5.616427, -6.737126, -6.436505, -7.376004, -6.440490, -6.446702, -6.007579, -6.601145, -6.317451, -6.036757, -6.105096, -7.011704, -5.711968, -5.987137, -6.980494, -7.624007, -6.877258, -7.194951, -6.188616, -5.987470, -4.655405, -6.499982, -6.489651, -6.532937, -6.708004, -6.527180, -6.724357, -6.717589, -6.022833, -6.931286, -6.336641, -5.685828, -4.039437, -6.219453, -8.130675, -9.464308, -10.022870, -10.420049, -10.703384, -10.945469, -11.123913, -11.233537, -11.379059, -11.494582, -11.570949, -11.675247, -11.761181, -11.768067, -11.876720, -11.893350, -11.947802, -11.989884, -12.004077, -12.054701, -12.056536, -12.044354, -12.132642, -12.120678, -12.167317, -12.158012, -12.181180, -12.234111, -12.213580, -12.198493, -12.204160, -12.181049, -12.212451, -12.228227, -12.194394, -12.214880, -12.222660, -12.221822, -12.209952, -12.211454, -12.231614, -12.189473, -12.269559, -12.235000, -12.216308, -12.242371, -12.219618, -12.193850, -12.249622, -12.135980, -12.168841, -12.146604, -12.162963, -12.133065, -12.176877, -12.193899, -12.186448, -12.118124, -12.070942, -12.128473, -12.127756, -12.127233, -12.084522, -12.087598, -12.059898, -12.036678, -12.050549, -12.025837, -12.031931, -12.072273, -12.063232, -11.981957, -12.024312, -12.010247, -12.003762, -11.971796, -11.992863, -11.976723, -12.006408, -11.907823, -11.917524, -11.936979, -11.914774, -11.909843, -11.857338, -11.827791, -11.818738, -11.888795, -11.909382, -11.865104, -11.827947, -11.788726, -11.810175, -11.717047, -11.772633, -11.790649, -11.793788, -11.773142, -11.705820, -11.728366, -11.702689, -11.730853, -11.739186, -11.704392, -11.706135, -11.697459, -11.680339, -11.669865, -11.703570, -11.697549, -11.661277, -11.529678, -11.662926, -11.676917, -11.647680, -11.607013, -11.658460, -11.595510, -11.508871, -11.550809, -11.548915, -11.564424, -11.606986, -11.650755, -11.522508, -11.488883, -11.567245, -11.519251, -11.487745, -11.415361, -11.505821, -11.463196, -11.427436, -11.428846, -11.495184, -11.484595, -11.447071, -11.356764, -11.387198, -11.433549, -11.385021, -11.381288, -11.412570, -11.381546, -11.437341, -11.441191, -11.381344, -11.277543, -11.320440, -11.275726, -11.365967, -11.311194, -11.317135, -11.320085, -11.225074, -11.287350, -11.278776, -11.293480, -11.309305, -11.255347, -11.285573, -11.194140, -11.244653, -11.189018, -11.185633, -11.218847, -11.213889, -11.249570, -11.167549, -11.208049, -11.164425, -11.189422, -11.162452, -11.137228, -11.119850, -11.170403, -11.115357, -11.167995, -11.095230, -11.144916, -11.131977, -11.218188, -11.122955, -11.087488, -11.094148, -11.117593, -11.072780, -11.149068, -11.072266, -11.064289, -10.957873, -11.110456, -11.084738, -10.982981, -11.059867, -10.989739, -11.026423, -11.046131, -11.043926, -11.035169, -10.988957, -10.986110, -11.049037, -11.020273, -11.016151, -10.952446, -10.977067, -11.005713, -10.958026, -10.960253, -10.967862, -10.907291, -10.987797, -10.980047, -10.960212, -10.902742, -10.904990, -10.905846, -10.908110, -10.894984, -10.916619, -10.872750, -10.865998, -10.830662, -10.915156, -10.869629, -10.846634, -10.835961, -10.850613, -10.783281, -10.834146, -10.895739, -10.908914, -10.848139, -10.796355, -10.818753, -10.812157, -10.800378, -10.834988, -10.916374, -10.953966, -11.065389, -11.065859, -11.090129, -11.459610, -11.276367, -11.578049, -11.910393, -12.216752, -12.428281, -12.393793, -11.969883, -11.537288, -11.248703, -11.168830, -11.168840, -11.218028, -11.186548, -11.135037, -11.196804, -11.194995, -11.116007, -11.144456, -11.200728, -11.253898, -11.172103, -11.147541, -11.185085, -11.161169, -11.215450, -11.158085, -11.167490, -11.224521, -11.135065, -11.193638, -11.183433, -11.186640, -11.244736, -11.189924, -11.253969, -11.204787, -11.206291, -11.244095, -11.138053, -11.176304, -11.150232, -11.206832, -11.192003, -11.193088, -11.192120, -11.187546, -11.204346, -11.198397, -11.147942, -11.162097, -11.121401, -11.136583, -11.160843, -11.152843, -11.169833, -11.183629, -11.196892, -11.168925, -11.188020, -11.209744, -11.185288, -11.200361, -11.213862, -11.218718, -11.186627, -11.170916, -11.157483, -11.213737, -11.200897, -11.240792, -11.182018, -11.195962, -11.130478, -11.133306, -11.196097, -11.207166, -11.203553, -11.204930, -11.240325, -11.132530, -11.123456, -11.159070, -11.205329, -11.170352, -11.195209, -11.192614, -11.211015, -11.148291, -11.120795, -11.191674, -11.138820, -11.281963, -11.270242, -11.489305, -12.294074, -12.989191
diff --git a/lib_v5/spec_utils.py b/lib_v5/spec_utils.py
index a889ef6..79bab8f 100644
--- a/lib_v5/spec_utils.py
+++ b/lib_v5/spec_utils.py
@@ -369,6 +369,23 @@ def ensembling(a, specs):
return spec
+def stft(wave, nfft, hl):
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+ spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
+ spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+def istft(spec, hl):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hl)
+ wave_right = librosa.istft(spec_right, hop_length=hl)
+ wave = np.asfortranarray([wave_left, wave_right])
+
if __name__ == "__main__":
import cv2
diff --git a/lib_v5/sv_ttk/__init__.py b/lib_v5/sv_ttk/__init__.py
new file mode 100644
index 0000000..b265472
--- /dev/null
+++ b/lib_v5/sv_ttk/__init__.py
@@ -0,0 +1,61 @@
+from pathlib import Path
+
+inited = False
+root = None
+
+
+def init(func):
+ def wrapper(*args, **kwargs):
+ global inited
+ global root
+
+ if not inited:
+ from tkinter import _default_root
+
+ path = (Path(__file__).parent / "sun-valley.tcl").resolve()
+
+ try:
+ _default_root.tk.call("source", str(path))
+ except AttributeError:
+ raise RuntimeError(
+ "can't set theme. "
+ "Tk is not initialized. "
+ "Please first create a tkinter.Tk instance, then set the theme."
+ ) from None
+ else:
+ inited = True
+ root = _default_root
+
+ return func(*args, **kwargs)
+
+ return wrapper
+
+
+@init
+def set_theme(theme):
+ if theme not in {"dark", "light"}:
+ raise RuntimeError(f"not a valid theme name: {theme}")
+
+ root.tk.call("set_theme", theme)
+
+
+@init
+def get_theme():
+ theme = root.tk.call("ttk::style", "theme", "use")
+
+ try:
+ return {"sun-valley-dark": "dark", "sun-valley-light": "light"}[theme]
+ except KeyError:
+ return theme
+
+
+@init
+def toggle_theme():
+ if get_theme() == "dark":
+ use_light_theme()
+ else:
+ use_dark_theme()
+
+
+use_dark_theme = lambda: set_theme("dark")
+use_light_theme = lambda: set_theme("light")
diff --git a/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc b/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..471fa89
Binary files /dev/null and b/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc differ
diff --git a/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc b/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000..477c027
Binary files /dev/null and b/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc differ
diff --git a/lib_v5/sv_ttk/sun-valley.tcl b/lib_v5/sv_ttk/sun-valley.tcl
new file mode 100644
index 0000000..7baac78
--- /dev/null
+++ b/lib_v5/sv_ttk/sun-valley.tcl
@@ -0,0 +1,46 @@
+source [file join [file dirname [info script]] theme dark.tcl]
+
+option add *tearOff 0
+
+proc set_theme {mode} {
+ if {$mode == "dark"} {
+ ttk::style theme use "sun-valley-dark"
+
+ array set colors {
+ -fg "#F6F6F7"
+ -bg "#0e0e0f"
+ -disabledfg "#F6F6F7"
+ -selectfg "#F6F6F7"
+ -selectbg "#003b50"
+ }
+
+ ttk::style configure . \
+ -background $colors(-bg) \
+ -foreground $colors(-fg) \
+ -troughcolor $colors(-bg) \
+ -focuscolor $colors(-selectbg) \
+ -selectbackground $colors(-selectbg) \
+ -selectforeground $colors(-selectfg) \
+ -insertwidth 0 \
+ -insertcolor $colors(-fg) \
+ -fieldbackground $colors(-selectbg) \
+ -font {"Century Gothic" 10} \
+ -borderwidth 0 \
+ -relief flat
+
+ tk_setPalette \
+ background [ttk::style lookup . -background] \
+ foreground [ttk::style lookup . -foreground] \
+ highlightColor [ttk::style lookup . -focuscolor] \
+ selectBackground [ttk::style lookup . -selectbackground] \
+ selectForeground [ttk::style lookup . -selectforeground] \
+ activeBackground [ttk::style lookup . -selectbackground] \
+ activeForeground [ttk::style lookup . -selectforeground]
+
+ ttk::style map . -foreground [list disabled $colors(-disabledfg)]
+
+ option add *font [ttk::style lookup . -font]
+ option add *Menu.selectcolor $colors(-fg)
+ option add *Menu.background #0e0e0f
+ }
+}
diff --git a/lib_v5/sv_ttk/theme/dark.tcl b/lib_v5/sv_ttk/theme/dark.tcl
new file mode 100644
index 0000000..33a815d
--- /dev/null
+++ b/lib_v5/sv_ttk/theme/dark.tcl
@@ -0,0 +1,534 @@
+# Copyright © 2021 rdbende
+
+# A stunning dark theme for ttk based on Microsoft's Sun Valley visual style
+
+package require Tk 8.6
+
+namespace eval ttk::theme::sun-valley-dark {
+ variable version 1.0
+ package provide ttk::theme::sun-valley-dark $version
+
+ ttk::style theme create sun-valley-dark -parent clam -settings {
+ proc load_images {imgdir} {
+ variable images
+ foreach file [glob -directory $imgdir *.png] {
+ set images([file tail [file rootname $file]]) \
+ [image create photo -file $file -format png]
+ }
+ }
+
+ load_images [file join [file dirname [info script]] dark]
+
+ array set colors {
+ -fg "#F6F6F7"
+ -bg "#0e0e0f"
+ -disabledfg "#F6F6F7"
+ -selectfg "#ffffff"
+ -selectbg "#2f60d8"
+ }
+
+ ttk::style layout TButton {
+ Button.button -children {
+ Button.padding -children {
+ Button.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Toolbutton {
+ Toolbutton.button -children {
+ Toolbutton.padding -children {
+ Toolbutton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TMenubutton {
+ Menubutton.button -children {
+ Menubutton.padding -children {
+ Menubutton.label -side left -expand 1
+ Menubutton.indicator -side right -sticky nsew
+ }
+ }
+ }
+
+ ttk::style layout TOptionMenu {
+ OptionMenu.button -children {
+ OptionMenu.padding -children {
+ OptionMenu.label -side left -expand 0
+ OptionMenu.indicator -side right -sticky nsew
+ }
+ }
+ }
+
+ ttk::style layout Accent.TButton {
+ AccentButton.button -children {
+ AccentButton.padding -children {
+ AccentButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Titlebar.TButton {
+ TitlebarButton.button -children {
+ TitlebarButton.padding -children {
+ TitlebarButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Close.Titlebar.TButton {
+ CloseButton.button -children {
+ CloseButton.padding -children {
+ CloseButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TCheckbutton {
+ Checkbutton.button -children {
+ Checkbutton.padding -children {
+ Checkbutton.indicator -side left
+ Checkbutton.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Switch.TCheckbutton {
+ Switch.button -children {
+ Switch.padding -children {
+ Switch.indicator -side left
+ Switch.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Toggle.TButton {
+ ToggleButton.button -children {
+ ToggleButton.padding -children {
+ ToggleButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TRadiobutton {
+ Radiobutton.button -children {
+ Radiobutton.padding -children {
+ Radiobutton.indicator -side left
+ Radiobutton.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Vertical.TScrollbar {
+ Vertical.Scrollbar.trough -sticky ns -children {
+ Vertical.Scrollbar.uparrow -side top
+ Vertical.Scrollbar.downarrow -side bottom
+ Vertical.Scrollbar.thumb -expand 1
+ }
+ }
+
+ ttk::style layout Horizontal.TScrollbar {
+ Horizontal.Scrollbar.trough -sticky ew -children {
+ Horizontal.Scrollbar.leftarrow -side left
+ Horizontal.Scrollbar.rightarrow -side right
+ Horizontal.Scrollbar.thumb -expand 1
+ }
+ }
+
+ ttk::style layout TSeparator {
+ TSeparator.separator -sticky nsew
+ }
+
+ ttk::style layout TCombobox {
+ Combobox.field -sticky nsew -children {
+ Combobox.padding -expand 1 -sticky nsew -children {
+ Combobox.textarea -sticky nsew
+ }
+ }
+ null -side right -sticky ns -children {
+ Combobox.arrow -sticky nsew
+ }
+ }
+
+ ttk::style layout TSpinbox {
+ Spinbox.field -sticky nsew -children {
+ Spinbox.padding -expand 1 -sticky nsew -children {
+ Spinbox.textarea -sticky nsew
+ }
+
+ }
+ null -side right -sticky nsew -children {
+ Spinbox.uparrow -side left -sticky nsew
+ Spinbox.downarrow -side right -sticky nsew
+ }
+ }
+
+ ttk::style layout Card.TFrame {
+ Card.field {
+ Card.padding -expand 1
+ }
+ }
+
+ ttk::style layout TLabelframe {
+ Labelframe.border {
+ Labelframe.padding -expand 1 -children {
+ Labelframe.label -side left
+ }
+ }
+ }
+
+ ttk::style layout TNotebook {
+ Notebook.border -children {
+ TNotebook.Tab -expand 1
+ Notebook.client -sticky nsew
+ }
+ }
+
+ ttk::style layout Treeview.Item {
+ Treeitem.padding -sticky nsew -children {
+ Treeitem.image -side left -sticky {}
+ Treeitem.indicator -side left -sticky {}
+ Treeitem.text -side left -sticky {}
+ }
+ }
+
+ # Button
+ ttk::style configure TButton -padding {8 4} -anchor center -foreground $colors(-fg)
+
+ ttk::style map TButton -foreground \
+ [list disabled #7a7a7a \
+ pressed #d0d0d0]
+
+ ttk::style element create Button.button image \
+ [list $images(button-rest) \
+ {selected disabled} $images(button-disabled) \
+ disabled $images(button-disabled) \
+ selected $images(button-rest) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Toolbutton
+ ttk::style configure Toolbutton -padding {8 4} -anchor center
+
+ ttk::style element create Toolbutton.button image \
+ [list $images(empty) \
+ {selected disabled} $images(button-disabled) \
+ selected $images(button-rest) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Menubutton
+ ttk::style configure TMenubutton -padding {8 4 0 4}
+
+ ttk::style element create Menubutton.button \
+ image [list $images(button-rest) \
+ disabled $images(button-disabled) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ ttk::style element create Menubutton.indicator image $images(arrow-down) -width 28 -sticky {}
+
+ # OptionMenu
+ ttk::style configure TOptionMenu -padding {8 4 0 4}
+
+ ttk::style element create OptionMenu.button \
+ image [list $images(button-rest) \
+ disabled $images(button-disabled) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 0 -sticky nsew
+
+ ttk::style element create OptionMenu.indicator image $images(arrow-down) -width 28 -sticky {}
+
+ # Accent.TButton
+ ttk::style configure Accent.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Accent.TButton -foreground \
+ [list pressed #25536a \
+ disabled #a5a5a5]
+
+ ttk::style element create AccentButton.button image \
+ [list $images(button-accent-rest) \
+ {selected disabled} $images(button-accent-disabled) \
+ disabled $images(button-accent-disabled) \
+ selected $images(button-accent-rest) \
+ pressed $images(button-accent-pressed) \
+ active $images(button-accent-hover) \
+ ] -border 4 -sticky nsew
+
+ # Titlebar.TButton
+ ttk::style configure Titlebar.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Titlebar.TButton -foreground \
+ [list disabled #6f6f6f \
+ pressed #d1d1d1 \
+ active #ffffff]
+
+ ttk::style element create TitlebarButton.button image \
+ [list $images(empty) \
+ disabled $images(empty) \
+ pressed $images(button-titlebar-pressed) \
+ active $images(button-titlebar-hover) \
+ ] -border 4 -sticky nsew
+
+ # Close.Titlebar.TButton
+ ttk::style configure Close.Titlebar.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Close.Titlebar.TButton -foreground \
+ [list disabled #6f6f6f \
+ pressed #e8bfbb \
+ active #ffffff]
+
+ ttk::style element create CloseButton.button image \
+ [list $images(empty) \
+ disabled $images(empty) \
+ pressed $images(button-close-pressed) \
+ active $images(button-close-hover) \
+ ] -border 4 -sticky nsew
+
+ # Checkbutton
+ ttk::style configure TCheckbutton -padding 4
+
+ ttk::style element create Checkbutton.indicator image \
+ [list $images(check-unsel-rest) \
+ {alternate disabled} $images(check-tri-disabled) \
+ {selected disabled} $images(check-disabled) \
+ disabled $images(check-unsel-disabled) \
+ {pressed alternate} $images(check-tri-hover) \
+ {active alternate} $images(check-tri-hover) \
+ alternate $images(check-tri-rest) \
+ {pressed selected} $images(check-hover) \
+ {active selected} $images(check-hover) \
+ selected $images(check-rest) \
+ {pressed !selected} $images(check-unsel-pressed) \
+ active $images(check-unsel-hover) \
+ ] -width 26 -sticky w
+
+ # Switch.TCheckbutton
+ ttk::style element create Switch.indicator image \
+ [list $images(switch-off-rest) \
+ {selected disabled} $images(switch-on-disabled) \
+ disabled $images(switch-off-disabled) \
+ {pressed selected} $images(switch-on-pressed) \
+ {active selected} $images(switch-on-hover) \
+ selected $images(switch-on-rest) \
+ {pressed !selected} $images(switch-off-pressed) \
+ active $images(switch-off-hover) \
+ ] -width 46 -sticky w
+
+ # Toggle.TButton
+ ttk::style configure Toggle.TButton -padding {8 4 8 4} -anchor center -foreground $colors(-fg)
+
+ ttk::style map Toggle.TButton -foreground \
+ [list {selected disabled} #a5a5a5 \
+ {selected pressed} #d0d0d0 \
+ selected #ffffff \
+ pressed #25536a \
+ disabled #7a7a7a
+ ]
+
+ ttk::style element create ToggleButton.button image \
+ [list $images(button-rest) \
+ {selected disabled} $images(button-accent-disabled) \
+ disabled $images(button-disabled) \
+ {pressed selected} $images(button-rest) \
+ {active selected} $images(button-accent-hover) \
+ selected $images(button-accent-rest) \
+ {pressed !selected} $images(button-accent-rest) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Radiobutton
+ ttk::style configure TRadiobutton -padding 0
+
+ ttk::style element create Radiobutton.indicator image \
+ [list $images(radio-unsel-rest) \
+ {selected disabled} $images(radio-disabled) \
+ disabled $images(radio-unsel-disabled) \
+ {pressed selected} $images(radio-pressed) \
+ {active selected} $images(radio-hover) \
+ selected $images(radio-rest) \
+ {pressed !selected} $images(radio-unsel-pressed) \
+ active $images(radio-unsel-hover) \
+ ] -width 20 -sticky w
+
+ ttk::style configure Menu.TRadiobutton -padding 0
+
+ ttk::style element create Menu.Radiobutton.indicator image \
+ [list $images(radio-unsel-rest) \
+ {selected disabled} $images(radio-disabled) \
+ disabled $images(radio-unsel-disabled) \
+ {pressed selected} $images(radio-pressed) \
+ {active selected} $images(radio-hover) \
+ selected $images(radio-rest) \
+ {pressed !selected} $images(radio-unsel-pressed) \
+ active $images(radio-unsel-hover) \
+ ] -width 20 -sticky w
+
+ # Scrollbar
+ ttk::style element create Horizontal.Scrollbar.trough image $images(scroll-hor-trough) -sticky ew -border 6
+ ttk::style element create Horizontal.Scrollbar.thumb image $images(scroll-hor-thumb) -sticky ew -border 3
+
+ ttk::style element create Horizontal.Scrollbar.rightarrow image $images(scroll-right) -sticky {} -width 12
+ ttk::style element create Horizontal.Scrollbar.leftarrow image $images(scroll-left) -sticky {} -width 12
+
+ ttk::style element create Vertical.Scrollbar.trough image $images(scroll-vert-trough) -sticky ns -border 6
+ ttk::style element create Vertical.Scrollbar.thumb image $images(scroll-vert-thumb) -sticky ns -border 3
+
+ ttk::style element create Vertical.Scrollbar.uparrow image $images(scroll-up) -sticky {} -height 12
+ ttk::style element create Vertical.Scrollbar.downarrow image $images(scroll-down) -sticky {} -height 12
+
+ # Scale
+ ttk::style element create Horizontal.Scale.trough image $images(scale-trough-hor) \
+ -border 5 -padding 0
+
+ ttk::style element create Vertical.Scale.trough image $images(scale-trough-vert) \
+ -border 5 -padding 0
+
+ ttk::style element create Scale.slider \
+ image [list $images(scale-thumb-rest) \
+ disabled $images(scale-thumb-disabled) \
+ pressed $images(scale-thumb-pressed) \
+ active $images(scale-thumb-hover) \
+ ] -sticky {}
+
+ # Progressbar
+ ttk::style element create Horizontal.Progressbar.trough image $images(progress-trough-hor) \
+ -border 1 -sticky ew
+
+ ttk::style element create Horizontal.Progressbar.pbar image $images(progress-pbar-hor) \
+ -border 2 -sticky ew
+
+ ttk::style element create Vertical.Progressbar.trough image $images(progress-trough-vert) \
+ -border 1 -sticky ns
+
+ ttk::style element create Vertical.Progressbar.pbar image $images(progress-pbar-vert) \
+ -border 2 -sticky ns
+
+ # Entry
+ ttk::style configure TEntry -foreground $colors(-fg)
+
+ ttk::style map TEntry -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style element create Entry.field \
+ image [list $images(entry-rest) \
+ {focus hover !invalid} $images(entry-focus) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ {focus !invalid} $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 5 -padding 8 -sticky nsew
+
+ # Combobox
+ ttk::style configure TCombobox -foreground $colors(-fg)
+
+ ttk::style map TCombobox -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style configure ComboboxPopdownFrame -borderwidth 0 -flat solid
+
+ ttk::style map TCombobox -selectbackground [list \
+ {readonly hover} $colors(-selectbg) \
+ {readonly focus} $colors(-selectbg) \
+ ] -selectforeground [list \
+ {readonly hover} $colors(-selectfg) \
+ {readonly focus} $colors(-selectfg) \
+ ]
+
+ ttk::style element create Combobox.field \
+ image [list $images(entry-rest) \
+ {readonly disabled} $images(button-disabled) \
+ {readonly pressed} $images(button-pressed) \
+ {readonly hover} $images(button-hover) \
+ readonly $images(button-rest) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ focus $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 0 -padding {8 8 28 8}
+
+ ttk::style element create Combobox.arrow image $images(arrow-down) -width 35 -sticky {}
+
+ # Spinbox
+ ttk::style configure TSpinbox -foreground $colors(-fg)
+
+ ttk::style map TSpinbox -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style element create Spinbox.field \
+ image [list $images(entry-rest) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ focus $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 5 -padding {8 8 54 8} -sticky nsew
+
+ ttk::style element create Spinbox.uparrow image $images(arrow-up) -width 35 -sticky {}
+ ttk::style element create Spinbox.downarrow image $images(arrow-down) -width 35 -sticky {}
+
+ # Sizegrip
+ ttk::style element create Sizegrip.sizegrip image $images(sizegrip) \
+ -sticky nsew
+
+ # Separator
+ ttk::style element create TSeparator.separator image $images(separator)
+
+ # Card
+ ttk::style element create Card.field image $images(card) \
+ -border 10 -padding 4 -sticky nsew
+
+ # Labelframe
+ ttk::style element create Labelframe.border image $images(card) \
+ -border 5 -padding 4 -sticky nsew
+
+ # Notebook
+ ttk::style configure TNotebook -padding 1
+
+ ttk::style element create Notebook.border \
+ image $images(notebook-border) -border 5 -padding 5
+
+ ttk::style element create Notebook.client image $images(notebook)
+
+ ttk::style element create Notebook.tab \
+ image [list $images(tab-rest) \
+ selected $images(tab-selected) \
+ active $images(tab-hover) \
+ ] -border 13 -padding {16 14 16 6} -height 32
+
+ # Treeview
+ ttk::style element create Treeview.field image $images(card) \
+ -border 5
+
+ ttk::style element create Treeheading.cell \
+ image [list $images(treeheading-rest) \
+ pressed $images(treeheading-pressed) \
+ active $images(treeheading-hover)
+ ] -border 5 -padding 15 -sticky nsew
+
+ ttk::style element create Treeitem.indicator \
+ image [list $images(arrow-right) \
+ user2 $images(empty) \
+ user1 $images(arrow-down) \
+ ] -width 26 -sticky {}
+
+ ttk::style configure Treeview -background $colors(-bg) -rowheight [expr {[font metrics font -linespace] + 2}]
+ ttk::style map Treeview \
+ -background [list selected #292929] \
+ -foreground [list selected $colors(-selectfg)]
+
+ # Panedwindow
+ # Insane hack to remove clam's ugly sash
+ ttk::style configure Sash -gripcount 0
+ }
+}
\ No newline at end of file
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-down.png b/lib_v5/sv_ttk/theme/dark/arrow-down.png
new file mode 100644
index 0000000..2b0a9d8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-down.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-right.png b/lib_v5/sv_ttk/theme/dark/arrow-right.png
new file mode 100644
index 0000000..2638d88
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-right.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-up.png b/lib_v5/sv_ttk/theme/dark/arrow-up.png
new file mode 100644
index 0000000..f935a0d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-up.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png b/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png
new file mode 100644
index 0000000..bf7bd9b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-hover.png b/lib_v5/sv_ttk/theme/dark/button-accent-hover.png
new file mode 100644
index 0000000..8aea9dd
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png b/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png
new file mode 100644
index 0000000..edc1114
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-rest.png b/lib_v5/sv_ttk/theme/dark/button-accent-rest.png
new file mode 100644
index 0000000..75e64f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-close-hover.png b/lib_v5/sv_ttk/theme/dark/button-close-hover.png
new file mode 100644
index 0000000..6fc0c00
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-close-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-close-pressed.png b/lib_v5/sv_ttk/theme/dark/button-close-pressed.png
new file mode 100644
index 0000000..6023dc1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-close-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-disabled.png b/lib_v5/sv_ttk/theme/dark/button-disabled.png
new file mode 100644
index 0000000..43add5f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-hover.png b/lib_v5/sv_ttk/theme/dark/button-hover.png
new file mode 100644
index 0000000..2041375
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-pressed.png b/lib_v5/sv_ttk/theme/dark/button-pressed.png
new file mode 100644
index 0000000..4270149
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-rest.png b/lib_v5/sv_ttk/theme/dark/button-rest.png
new file mode 100644
index 0000000..128f5f6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png b/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png
new file mode 100644
index 0000000..a2ac951
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png b/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png
new file mode 100644
index 0000000..fcb3751
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png b/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png
new file mode 100644
index 0000000..2ed0623
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/card.png b/lib_v5/sv_ttk/theme/dark/card.png
new file mode 100644
index 0000000..eaac11c
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/card.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-disabled.png b/lib_v5/sv_ttk/theme/dark/check-disabled.png
new file mode 100644
index 0000000..f766eba
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-hover.png b/lib_v5/sv_ttk/theme/dark/check-hover.png
new file mode 100644
index 0000000..59358d4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-pressed.png b/lib_v5/sv_ttk/theme/dark/check-pressed.png
new file mode 100644
index 0000000..02ee6af
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-rest.png b/lib_v5/sv_ttk/theme/dark/check-rest.png
new file mode 100644
index 0000000..aa8dc67
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png b/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png
new file mode 100644
index 0000000..a9d31c7
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-hover.png b/lib_v5/sv_ttk/theme/dark/check-tri-hover.png
new file mode 100644
index 0000000..ed218a0
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png b/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png
new file mode 100644
index 0000000..68d7a99
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-rest.png b/lib_v5/sv_ttk/theme/dark/check-tri-rest.png
new file mode 100644
index 0000000..26edcdb
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png b/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png
new file mode 100644
index 0000000..9f4be22
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png b/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png
new file mode 100644
index 0000000..0081141
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png b/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png
new file mode 100644
index 0000000..26767b8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png b/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png
new file mode 100644
index 0000000..55eabc6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/empty.png b/lib_v5/sv_ttk/theme/dark/empty.png
new file mode 100644
index 0000000..2218363
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/empty.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-disabled.png b/lib_v5/sv_ttk/theme/dark/entry-disabled.png
new file mode 100644
index 0000000..43add5f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-focus.png b/lib_v5/sv_ttk/theme/dark/entry-focus.png
new file mode 100644
index 0000000..58999e4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-focus.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-hover.png b/lib_v5/sv_ttk/theme/dark/entry-hover.png
new file mode 100644
index 0000000..6b93830
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-invalid.png b/lib_v5/sv_ttk/theme/dark/entry-invalid.png
new file mode 100644
index 0000000..7304b24
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-invalid.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-rest.png b/lib_v5/sv_ttk/theme/dark/entry-rest.png
new file mode 100644
index 0000000..e876752
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/notebook-border.png b/lib_v5/sv_ttk/theme/dark/notebook-border.png
new file mode 100644
index 0000000..0827a07
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/notebook-border.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/notebook.png b/lib_v5/sv_ttk/theme/dark/notebook.png
new file mode 100644
index 0000000..15c05f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/notebook.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png b/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png
new file mode 100644
index 0000000..f8035f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png b/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png
new file mode 100644
index 0000000..3d0cb29
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png b/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png
new file mode 100644
index 0000000..9fe4807
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png b/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png
new file mode 100644
index 0000000..22a8c1c
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-disabled.png b/lib_v5/sv_ttk/theme/dark/radio-disabled.png
new file mode 100644
index 0000000..965136d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-hover.png b/lib_v5/sv_ttk/theme/dark/radio-hover.png
new file mode 100644
index 0000000..9823345
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-pressed.png b/lib_v5/sv_ttk/theme/dark/radio-pressed.png
new file mode 100644
index 0000000..ed89533
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-rest.png b/lib_v5/sv_ttk/theme/dark/radio-rest.png
new file mode 100644
index 0000000..ef891d1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png
new file mode 100644
index 0000000..ec7dd91
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png
new file mode 100644
index 0000000..7feda0b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png
new file mode 100644
index 0000000..7a76749
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png
new file mode 100644
index 0000000..f311983
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png
new file mode 100644
index 0000000..ba77f1d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png
new file mode 100644
index 0000000..8398922
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png
new file mode 100644
index 0000000..70029b3
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png
new file mode 100644
index 0000000..f6571b9
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png b/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png
new file mode 100644
index 0000000..7fa2bf4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png b/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png
new file mode 100644
index 0000000..205fed8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-down.png b/lib_v5/sv_ttk/theme/dark/scroll-down.png
new file mode 100644
index 0000000..4c0e24f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-down.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png b/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png
new file mode 100644
index 0000000..795a88a
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png b/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png
new file mode 100644
index 0000000..89d0403
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-left.png b/lib_v5/sv_ttk/theme/dark/scroll-left.png
new file mode 100644
index 0000000..f43538b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-left.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-right.png b/lib_v5/sv_ttk/theme/dark/scroll-right.png
new file mode 100644
index 0000000..a56511f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-right.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-up.png b/lib_v5/sv_ttk/theme/dark/scroll-up.png
new file mode 100644
index 0000000..7ddba7f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-up.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png b/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png
new file mode 100644
index 0000000..572f33d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png b/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png
new file mode 100644
index 0000000..c947ed1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/separator.png b/lib_v5/sv_ttk/theme/dark/separator.png
new file mode 100644
index 0000000..6e01f55
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/separator.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/sizegrip.png b/lib_v5/sv_ttk/theme/dark/sizegrip.png
new file mode 100644
index 0000000..7080c04
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/sizegrip.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png b/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png
new file mode 100644
index 0000000..4032c61
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-hover.png b/lib_v5/sv_ttk/theme/dark/switch-off-hover.png
new file mode 100644
index 0000000..5a136bd
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png b/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png
new file mode 100644
index 0000000..040e2ea
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-rest.png b/lib_v5/sv_ttk/theme/dark/switch-off-rest.png
new file mode 100644
index 0000000..6c31bb2
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png b/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png
new file mode 100644
index 0000000..c0d67c5
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-hover.png b/lib_v5/sv_ttk/theme/dark/switch-on-hover.png
new file mode 100644
index 0000000..fd4de94
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png b/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png
new file mode 100644
index 0000000..00e87c6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-rest.png b/lib_v5/sv_ttk/theme/dark/switch-on-rest.png
new file mode 100644
index 0000000..52a19ea
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-hover.png b/lib_v5/sv_ttk/theme/dark/tab-hover.png
new file mode 100644
index 0000000..43a113b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-rest.png b/lib_v5/sv_ttk/theme/dark/tab-rest.png
new file mode 100644
index 0000000..d873b66
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-selected.png b/lib_v5/sv_ttk/theme/dark/tab-selected.png
new file mode 100644
index 0000000..eb7b211
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-selected.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-hover.png b/lib_v5/sv_ttk/theme/dark/treeheading-hover.png
new file mode 100644
index 0000000..beaaf13
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png b/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png
new file mode 100644
index 0000000..9cd311d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-rest.png b/lib_v5/sv_ttk/theme/dark/treeheading-rest.png
new file mode 100644
index 0000000..374ed49
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-rest.png differ
diff --git a/models.py b/models.py
new file mode 100644
index 0000000..15e5fb3
--- /dev/null
+++ b/models.py
@@ -0,0 +1,244 @@
+import torch
+from torch._C import has_mkl
+import torch.nn as nn
+import numpy as np
+import librosa
+
+dim_c = 4
+k = 3
+model_path = 'model'
+n_fft_scale = {'bass': 8, 'drums':2, 'other':4, 'vocals':3, '*':2}
+
+
+class Conv_TDF(nn.Module):
+ def __init__(self, c, l, f, k, bn, bias=True):
+
+ super(Conv_TDF, self).__init__()
+
+ self.use_tdf = bn is not None
+
+ self.H = nn.ModuleList()
+ for i in range(l):
+ self.H.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=c, kernel_size=k, stride=1, padding=k//2),
+ nn.BatchNorm2d(c),
+ nn.ReLU(),
+ )
+ )
+
+ if self.use_tdf:
+ if bn==0:
+ self.tdf = nn.Sequential(
+ nn.Linear(f,f, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU()
+ )
+ else:
+ self.tdf = nn.Sequential(
+ nn.Linear(f,f//bn, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU(),
+ nn.Linear(f//bn,f, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU()
+ )
+
+ def forward(self, x):
+ for h in self.H:
+ x = h(x)
+
+ return x + self.tdf(x) if self.use_tdf else x
+
+
+class Conv_TDF_net_trim(nn.Module):
+ def __init__(self, device, load, model_name, target_name, lr, epoch,
+ L, l, g, dim_f, dim_t, k=3, hop=1024, bn=None, bias=True):
+
+ super(Conv_TDF_net_trim, self).__init__()
+
+ self.dim_f, self.dim_t = 2**dim_f, 2**dim_t
+ self.n_fft = self.dim_f * n_fft_scale[target_name]
+ self.hop = hop
+ self.n_bins = self.n_fft//2+1
+ self.chunk_size = hop * (self.dim_t-1)
+ self.window = torch.hann_window(window_length=self.n_fft, periodic=True).to(device)
+ self.target_name = target_name
+ self.blender = 'blender' in model_name
+
+ out_c = dim_c*4 if target_name=='*' else dim_c
+ in_c = dim_c*2 if self.blender else dim_c
+ #out_c = dim_c*2 if self.blender else dim_c
+ self.freq_pad = torch.zeros([1, out_c, self.n_bins-self.dim_f, self.dim_t]).to(device)
+
+ self.n = L//2
+ if load:
+
+ self.first_conv = nn.Sequential(
+ nn.Conv2d(in_channels=in_c, out_channels=g, kernel_size=1, stride=1),
+ nn.BatchNorm2d(g),
+ nn.ReLU(),
+ )
+
+ f = self.dim_f
+ c = g
+ self.ds_dense = nn.ModuleList()
+ self.ds = nn.ModuleList()
+ for i in range(self.n):
+ self.ds_dense.append(Conv_TDF(c, l, f, k, bn, bias=bias))
+
+ scale = (2,2)
+ self.ds.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=c+g, kernel_size=scale, stride=scale),
+ nn.BatchNorm2d(c+g),
+ nn.ReLU()
+ )
+ )
+ f = f//2
+ c += g
+
+ self.mid_dense = Conv_TDF(c, l, f, k, bn, bias=bias)
+ #if bn is None and mid_tdf:
+ # self.mid_dense = Conv_TDF(c, l, f, k, bn=0, bias=False)
+
+ self.us_dense = nn.ModuleList()
+ self.us = nn.ModuleList()
+ for i in range(self.n):
+ scale = (2,2)
+ self.us.append(
+ nn.Sequential(
+ nn.ConvTranspose2d(in_channels=c, out_channels=c-g, kernel_size=scale, stride=scale),
+ nn.BatchNorm2d(c-g),
+ nn.ReLU()
+ )
+ )
+ f = f*2
+ c -= g
+
+ self.us_dense.append(Conv_TDF(c, l, f, k, bn, bias=bias))
+
+
+ self.final_conv = nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=out_c, kernel_size=1, stride=1),
+ )
+
+
+ model_cfg = f'L{L}l{l}g{g}'
+ model_cfg += ', ' if (bn is None or bn==0) else f'bn{bn}, '
+
+ stft_cfg = f'f{dim_f}t{dim_t}, '
+
+ model_name = model_name[:model_name.index('(')+1] + model_cfg + stft_cfg + model_name[model_name.index('(')+1:]
+ try:
+ self.load_state_dict(
+ torch.load('{0}/{1}/{2}_lr{3}_e{4:05}.ckpt'.format(model_path, model_name, target_name, lr, epoch), map_location=device)
+ )
+ print(f'Loading model ({target_name})')
+ except FileNotFoundError:
+ print(f'Random init ({target_name})')
+
+
+ def stft(self, x):
+ x = x.reshape([-1, self.chunk_size])
+ x = torch.stft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
+ x = x.permute([0,3,1,2])
+ x = x.reshape([-1,2,2,self.n_bins,self.dim_t]).reshape([-1,dim_c,self.n_bins,self.dim_t])
+ return x[:,:,:self.dim_f]
+
+ def istft(self, x, freq_pad=None):
+ freq_pad = self.freq_pad.repeat([x.shape[0],1,1,1]) if freq_pad is None else freq_pad
+ x = torch.cat([x, freq_pad], -2)
+ c = 4*2 if self.target_name=='*' else 2
+ x = x.reshape([-1,c,2,self.n_bins,self.dim_t]).reshape([-1,2,self.n_bins,self.dim_t])
+ x = x.permute([0,2,3,1])
+ x = torch.istft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
+ return x.reshape([-1,c,self.chunk_size])
+
+
+ def forward(self, x):
+
+ x = self.first_conv(x)
+
+ x = x.transpose(-1,-2)
+
+ ds_outputs = []
+ for i in range(self.n):
+ x = self.ds_dense[i](x)
+ ds_outputs.append(x)
+ x = self.ds[i](x)
+
+ x = self.mid_dense(x)
+
+ for i in range(self.n):
+ x = self.us[i](x)
+ x *= ds_outputs[-i-1]
+ x = self.us_dense[i](x)
+
+ x = x.transpose(-1,-2)
+
+ x = self.final_conv(x)
+
+ return x
+
+def stft(wave, nfft, hl):
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+ spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
+ spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+def istft(spec, hl):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hl)
+ wave_right = librosa.istft(spec_right, hop_length=hl)
+ wave = np.asfortranarray([wave_left, wave_right])
+
+ return wave
+
+def spec_effects(wave, algorithm='default', value=None):
+ spec = [stft(wave[0],2048,1024),stft(wave[1],2048,1024)]
+ if algorithm == 'min_mag':
+ v_spec_m = np.where(np.abs(spec[1]) <= np.abs(spec[0]), spec[1], spec[0])
+ wave = istft(v_spec_m,1024)
+ elif algorithm == 'max_mag':
+ v_spec_m = np.where(np.abs(spec[1]) >= np.abs(spec[0]), spec[1], spec[0])
+ wave = istft(v_spec_m,1024)
+ elif algorithm == 'default':
+ #wave = [istft(spec[0],1024),istft(spec[1],1024)]
+ wave = (wave[1] * value) + (wave[0] * (1-value))
+ elif algorithm == 'invert_p':
+ X_mag = np.abs(spec[0])
+ y_mag = np.abs(spec[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = spec[1] - max_mag * np.exp(1.j * np.angle(spec[0]))
+ wave = istft(v_spec,1024)
+ return wave
+
+
+def get_models(name, device, load=True, stems='vocals'):
+
+ if name=='tdf_extra':
+ models = []
+ if 'vocals' in stems:
+ models.append(
+ Conv_TDF_net_trim(
+ device=device, load=load,
+ model_name='Conv-TDF', target_name='vocals',
+ lr=0.0001, epoch=0,
+ L=11, l=3, g=32, bn=8, bias=False,
+ dim_f=11, dim_t=8
+ )
+ )
+ return models
+
+ else:
+ print('Model undefined')
+ return None
+
+
+
diff --git a/requirements.txt b/requirements.txt
index a0052ba..de17853 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,4 +1,5 @@
Pillow
+audioread
tqdm==4.45.0
librosa==0.8.0
resampy==0.2.2
@@ -8,3 +9,18 @@ numpy==1.21.0
samplerate
SoundFile
soundstretch
+loguru
+boto3
+openunmix
+musdb
+SoundFile
+scipy
+norbert
+asteroid>=0.5.0
+demucs
+pydub
+audiosegment
+pyglet
+pyperclip
+julius
+yaml
\ No newline at end of file
+
+### Other Application Notes
+
+- Nvidia GPUs with at least 8GBs of V-RAM are recommended.
+- This application is only compatible with 64-bit platforms.
+- This application relies on Sox - Sound Exchange for Noise Reduction.
+- This application relies on FFmpeg to process non-wav audio files.
+- The application will automatically remember your settings when closed.
+- Conversion times will significantly depend on your hardware.
+- These models are computationally intensive. Processing times might be slow on older or budget hardware. Please proceed with caution and pay attention to your PC to ensure it doesn't overheat. ***We are not responsible for any hardware damage.***
## Change Log
- **v4 vs. v5**
- The v5 models significantly outperform the v4 models.
- - The extraction's aggressiveness can be adjusted using the "Aggression Setting". The default value of 10 is optimal for most tracks.
+ - The extraction's aggressiveness can be adjusted using the "Aggression Setting." The default value of 10 is optimal for most tracks.
- All v2 and v4 models have been removed.
- - Ensemble Mode added - This allows the user to get the strongest result from each model.
+ - Ensemble Mode added - This allows the user to get the most robust result from each model.
- Stacked models have been entirely removed.
- - Stacked model feature has been replaced by the new aggression setting and model ensembling.
+ The new aggression setting and model ensembling have replaced the stacked model feature.
- The NFFT, HOP_SIZE, and SR values are now set internally.
+ - The MDX-NET AI engine and models have been added.
+ - This is a brand new feature added to the UVR GUI.
+ - 4 MDX-Net models trained by UVR developers are included in this package.
+ - The MDX-Net models provided were trained by the UVR core developers
+ - This network is less resource-intensive but incredibly powerful.
+ - MDX-Net is a Hybrid Waveform/Spectrogram network.
-- **Upcoming v5.2.0 Update**
- - MDX-NET AI engine and model support
+## Troubleshooting
-## Installation
+### Common Issues
-The application was made with Tkinter for cross-platform compatibility, so it should work with Windows, Mac, and Linux systems. However, this application has only been tested on Windows 10 & Linux Ubuntu.
+- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
-### Install Required Applications & Packages
+### Issue Reporting
-1. Download & install Python 3.9.8 [here](https://www.python.org/ftp/python/3.9.8/python-3.9.8-amd64.exe) (Windows link)
- - **Note:** Ensure the *"Add Python 3.9 to PATH"* box is checked
-2. Download the Source code zip here - https://github.com/Anjok07/ultimatevocalremovergui/archive/refs/heads/master.zip
-3. Download the models.zip here - https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.1.0/models.zip
+Please be as detailed as possible when posting a new issue.
+
+If possible, click the "Help Guide" button to the left of the "Start Processing" button and navigate to the "Error Log" tab for detailed error information that can be provided to us.
+
+## Manual Installation (For Developers)
+
+These instructions are for those installing UVR v5.2.0 **manually** only.
+
+1. Download & install Python 3.9 or lower (but no lower than 3.6) [here](https://www.python.org/downloads/)
+ - **Note:** Ensure the *"Add Python to PATH"* box is checked
+2. Download the Source code zip [here]()
+3. Download the models.zip [here]()
4. Extract the *ultimatevocalremovergui-master* folder within ultimatevocalremovergui-master.zip where ever you wish.
5. Extract the *models* folder within models.zip to the *ultimatevocalremovergui-master* directory.
- - **Note:** At this time, the GUI is hardcoded to run the models included in this package only.
6. Open the command prompt from the ultimatevocalremovergui-master directory and run the following commands, separately -
```
@@ -50,163 +116,36 @@ pip install --no-cache-dir -r requirements.txt
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
```
-### FFmpeg
+- FFmpeg
-FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg can be found on YouTube, WikiHow, Reddit, GitHub, and many other sources around the web.
+ - FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg is provided in the "More Info" tab within the Help Guide.
-- **Note:** If you are experiencing any errors when attempting to process any media files, not in the *.wav* format, please ensure FFmpeg is installed & configured correctly.
+- Running the GUI & Models
-### Running the GUI & Models
-
-- Open the file labeled *'VocalRemover.py'*.
- - It's recommended that you create a shortcut for the file labeled *'VocalRemover.py'* to your desktop for easy access.
- - **Note:** If you are unable to open the *'VocalRemover.py'* file, please go to the [**troubleshooting**](https://github.com/Anjok07/ultimatevocalremovergui/tree/beta#troubleshooting) section below.
-- **Note:** All output audio files will be in the *'.wav'* format.
-
-## Option Guide
-
-### Main Checkboxes
-- **GPU Conversion** - Selecting this option ensures the GPU is used to process conversions.
- - **Note:** This option will not work if you don't have a Cuda compatible GPU.
- - Nvidia GPUs are most compatible with Cuda.
- - **Note:** CPU conversions are much slower than those processed through the GPU.
-- **Post-process** - This option can potentially identify leftover instrumental artifacts within the vocal outputs. This option may improve the separation of *some* songs.
- - **Note:** Having this option selected can adversely affect the conversion process, depending on the track. Because of this, it's only recommended as a last resort.
-- **TTA** - This option performs Test-Time-Augmentation to improve the separation quality.
- - **Note:** Having this selected will increase the time it takes to complete a conversion.
-- **Output Image** - Selecting this option will include the spectrograms in *.jpg* format for the instrumental & vocal audio outputs.
-
-### Special Checkboxes
-- **Model Test Mode** - Only selectable when using the "*Single Model*" conversion method. This option makes it easier for users to test the results of different models and model combinations by eliminating the hassle of manually changing the filenames and creating new folders when processing the same track through multiple models. This option structures the model testing process.
- - When *' Model Test Mode'* is selected, the application will auto-generate a new folder in the *' Save to'* path you have chosen.
- - The new auto-generated folder will be named after the model(s) selected.
- - The output audio files will be saved to the auto-generated directory.
- - The filenames for the instrumental & vocal outputs will have the selected model(s) name(s) appended.
-- **Save All Outputs** - Only selectable when using the "*Ensemble Mode*" conversion method. This option will save all of the individual conversion outputs from each model within the ensemble.
- - When *'Save All Outputs'* is un-selected, the application will auto-delete all of the individual conversions generated by each model in the ensemble.
-
-### Additional Options
-
-- **Window Size** - The smaller your window size, the better your conversions will be. However, a smaller window means longer conversion times and heavier resource usage.
- - Here are the selectable window size values -
- - **1024** - Low conversion quality, shortest conversion time, low resource usage
- - **512** - Average conversion quality, average conversion time, normal resource usage
- - **320** - Better conversion quality, long conversion time, high resource usage
-- **Aggression Setting** - This option allows you to set how strong the vocal removal will be.
- - The range is 0-100.
- - Higher values perform deeper extractions.
- - The default is 10 for instrumental & vocal models.
- - Values over 10 can result in muddy-sounding instrumentals for the non-vocal models.
-- **Default Values:**
- - **Window Size** - 512
- - **Aggression Setting** - 10 (optimal setting for all conversions)
-
-### Other Buttons
-
-- **Open Export Directory** - This button will open your 'save to' directory. You will find it to the right of the *'Start Conversion'* button.
-
-## Models Included
-
-All of the models included in the release were trained on large datasets containing a diverse range of music genres and different training parameters.
-
-**Please Note:** Do not change the name of the models provided! The required parameters are specified and appended to the end of the filenames.
-
-- **Model Network Types**
- - **HP2** - The model layers are much larger. However, this makes them resource-heavy.
- - **HP** - The model layers are the standard size for UVR v5.
-
-### Main Models
-
-- **HP2_3BAND_44100_MSB2.pth** - This is a strong instrumental model trained using more data and new parameters.
-- **HP2_4BAND_44100_1.pth** - This is a strong instrumental model.
-- **HP2_4BAND_44100_2.pth** - This is a fine tuned version of the HP2_4BAND_44100_1.pth model.
-- **HP_4BAND_44100_A.pth** - This is a strong instrumental model.
-- **HP_4BAND_44100_B.pth** - This is a fine tuned version of the HP_4BAND_44100_A.pth model.
-- **HP_KAROKEE_4BAND_44100_SN.pth** - This is a model that removes main vocals while leaving background vocals intact.
-- **HP_Vocal_4BAND_44100.pth** - This model emphasizes vocal extraction. The vocal stem will be clean, but the instrumental might sound muddy.
-- **HP_Vocal_AGG_4BAND_44100.pth** - This model also emphasizes vocal extraction and is a bit more aggressive than the previous model.
-
-## Choose Conversion Method
-
-### Single Model
-
-Run your tracks through a single model only. This is the default conversion method.
-
-- **Choose Main Model** - Here is where you choose the main model to perform a deep vocal removal.
- - The *'Model Test Mode'* option makes it easier for users to test different models on given tracks.
-
-### Ensemble Mode
-
-Ensemble Mode will run your track(s) through multiple models and combine the resulting outputs for a more robust separation. Higher level ensembles will have stronger separations, as they use more models.
-
-- **Choose Ensemble** - Here, choose the ensemble you wish to run your track through.
- - **There are 4 ensembles you can choose from:**
- - **HP1 Models** - Level 1 Ensemble
- - **HP2 Models** - Level 2 Ensemble
- - **All HP Models** - Level 3 Ensemble
- - **Vocal Models** - Level 1 Vocal Ensemble
- - A directory is auto-generated with the name of the ensemble. This directory will contain all of the individual outputs generated by the ensemble and auto-delete once the conversions are complete if the *'Save All Outputs'* option is unchecked.
- - When checked, the *'Save All Outputs'* option saves all of the outputs generated by each model in the ensemble.
-
-- **List of models included in each ensemble:**
- - **HP1 Models**
- - HP_4BAND_44100_A
- - HP_4BAND_44100_B
- - **HP2 Models**
- - HP2_4BAND_44100_1
- - HP2_4BAND_44100_2
- - HP2_3BAND_44100_MSB2
- - **All HP Models**
- - HP_4BAND_44100_A
- - HP_4BAND_44100_B
- - HP2_4BAND_44100_1
- - HP2_4BAND_44100_2
- - HP2_3BAND_44100_MSB2
- - **Vocal Models**
- - HP_Vocal_4BAND_44100
- - HP_Vocal_AGG_4BAND_44100
-
-- **Please Note:** Ensemble mode is very resource heavy!
-
-## Other GUI Notes
-
-- The application will automatically remember your *'save to'* path upon closing and reopening until it's changed.
- - **Note:** The last directory accessed within the application will also be remembered.
-- Multiple conversions are supported.
-- The ability to drag & drop audio files to convert has also been added.
-- Conversion times will significantly depend on your hardware.
- - **Note:** This application will *not* be friendly to older or budget hardware. Please proceed with caution! Please pay attention to your PC and make sure it doesn't overheat. ***We are not responsible for any hardware damage.***
-
-## Troubleshooting
-
-### Common Issues
-
-- This application is not compatible with 32-bit versions of Python. Please make sure your version of Python is 64-bit.
-- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
-
-### Issue Reporting
-
-Please be as detailed as possible when posting a new issue. Make sure to provide any error outputs and/or screenshots/gif's to give us a clearer understanding of the issue you are experiencing.
-
-If the *'VocalRemover.py'* file won't open *under any circumstances* and all other resources have been exhausted, please do the following -
-
-1. Open the cmd prompt from the ultimatevocalremovergui-master directory
-2. Run the following command -
-```
-python VocalRemover.py
-```
-3. Copy and paste the error output shown in the cmd prompt to the issues center on the GitHub repository.
+ - Open the file labeled *'UVR.py'*.
+ - It's recommended that you create a shortcut for the file labeled *'UVR.py'* to your desktop for easy access.
+ - **Note:** If you are unable to open the *'UVR.py'* file, please go to the **troubleshooting** section below.
+ - **Note:** All output audio files will be in the *'.wav'* format.
## License
The **Ultimate Vocal Remover GUI** code is [MIT-licensed](LICENSE).
-- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers Anjok07, aufr33, & tsurumeso.
+- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers.
+
+## Credits
+
+- [DilanBoskan](https://github.com/DilanBoskan) - Your contributions at the start of this project were essential to the success of UVR. Thank you!
+- [Bas Curtiz](https://www.youtube.com/user/bascurtiz) - Designed the official UVR logo, icon, banner, splash screen, and interface.
+- [tsurumeso](https://github.com/tsurumeso) - Developed the original VR Architecture code.
+- [Kuielab & Woosung Choi](https://github.com/kuielab) - Developed the original MDX-Net AI code.
+- [Adefossez & Demucs](https://github.com/facebookresearch/demucs) - Developed the original MDX-Net AI code.
+- [Hv](https://github.com/NaJeongMo/Colab-for-MDX_B) - Helped implement chunks into the MDX-Net AI code. Thank you!
## Contributing
-- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and/or modify as they wish.
-- Please note that we do not maintain or directly support any of tsurumesos AI application code. We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
+- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and modify as they wish.
+- We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
## References
- [1] Takahashi et al., "Multi-scale Multi-band DenseNets for Audio Source Separation", https://arxiv.org/pdf/1706.09588.pdf
diff --git a/UVR.py b/UVR.py
new file mode 100644
index 0000000..6227261
--- /dev/null
+++ b/UVR.py
@@ -0,0 +1,1729 @@
+# GUI modules
+import os
+try:
+ with open(os.path.join(os.getcwd(), 'tmp', 'splash.txt'), 'w') as f:
+ f.write('1')
+except:
+ pass
+import pyperclip
+from gc import freeze
+import tkinter as tk
+from tkinter import *
+from tkinter.tix import *
+import webbrowser
+from tracemalloc import stop
+import lib_v5.sv_ttk
+import tkinter.ttk as ttk
+import tkinter.messagebox
+import tkinter.filedialog
+import tkinter.font
+from tkinterdnd2 import TkinterDnD, DND_FILES # Enable Drag & Drop
+import pyglet,tkinter
+from datetime import datetime
+# Images
+from PIL import Image
+from PIL import ImageTk
+import pickle # Save Data
+# Other Modules
+
+# Pathfinding
+import pathlib
+import sys
+import subprocess
+from collections import defaultdict
+# Used for live text displaying
+import queue
+import threading # Run the algorithm inside a thread
+from subprocess import call
+from pathlib import Path
+import ctypes as ct
+import subprocess # Run python file
+import inference_MDX
+import inference_v5
+import inference_v5_ensemble
+
+try:
+ with open(os.path.join(os.getcwd(), 'tmp', 'splash.txt'), 'w') as f:
+ f.write('1')
+except:
+ pass
+
+# Change the current working directory to the directory
+# this file sits in
+if getattr(sys, 'frozen', False):
+ # If the application is run as a bundle, the PyInstaller bootloader
+ # extends the sys module by a flag frozen=True and sets the app
+ # path into variable _MEIPASS'.
+ base_path = sys._MEIPASS
+else:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+
+os.chdir(base_path) # Change the current working directory to the base path
+
+#Images
+instrumentalModels_dir = os.path.join(base_path, 'models')
+banner_path = os.path.join(base_path, 'img', 'UVR-banner.png')
+efile_path = os.path.join(base_path, 'img', 'file.png')
+stop_path = os.path.join(base_path, 'img', 'stop.png')
+help_path = os.path.join(base_path, 'img', 'help.png')
+gen_opt_path = os.path.join(base_path, 'img', 'gen_opt.png')
+mdx_opt_path = os.path.join(base_path, 'img', 'mdx_opt.png')
+vr_opt_path = os.path.join(base_path, 'img', 'vr_opt.png')
+ense_opt_path = os.path.join(base_path, 'img', 'ense_opt.png')
+user_ens_opt_path = os.path.join(base_path, 'img', 'user_ens_opt.png')
+credits_path = os.path.join(base_path, 'img', 'credits.png')
+
+DEFAULT_DATA = {
+ 'exportPath': '',
+ 'inputPaths': [],
+ 'saveFormat': 'Wav',
+ 'gpu': False,
+ 'postprocess': False,
+ 'tta': False,
+ 'save': True,
+ 'output_image': False,
+ 'window_size': '512',
+ 'agg': 10,
+ 'modelFolder': False,
+ 'modelInstrumentalLabel': '',
+ 'aiModel': 'MDX-Net',
+ 'algo': 'Instrumentals (Min Spec)',
+ 'ensChoose': 'MDX-Net/VR Ensemble',
+ 'useModel': 'instrumental',
+ 'lastDir': None,
+ 'break': False,
+ #MDX-Net
+ 'demucsmodel': True,
+ 'non_red': False,
+ 'noise_reduc': True,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'chunks': 'Auto',
+ 'noisereduc_s': '3',
+ 'mixing': 'default',
+ 'mdxnetModel': 'UVR-MDX-NET 1',
+}
+
+def open_image(path: str, size: tuple = None, keep_aspect: bool = True, rotate: int = 0) -> ImageTk.PhotoImage:
+ """
+ Open the image on the path and apply given settings\n
+ Paramaters:
+ path(str):
+ Absolute path of the image
+ size(tuple):
+ first value - width
+ second value - height
+ keep_aspect(bool):
+ keep aspect ratio of image and resize
+ to maximum possible width and height
+ (maxima are given by size)
+ rotate(int):
+ clockwise rotation of image
+ Returns(ImageTk.PhotoImage):
+ Image of path
+ """
+ img = Image.open(path).convert(mode='RGBA')
+ ratio = img.height/img.width
+ img = img.rotate(angle=-rotate)
+ if size is not None:
+ size = (int(size[0]), int(size[1]))
+ if keep_aspect:
+ img = img.resize((size[0], int(size[0] * ratio)), Image.ANTIALIAS)
+ else:
+ img = img.resize(size, Image.ANTIALIAS)
+ return ImageTk.PhotoImage(img)
+
+def save_data(data):
+ """
+ Saves given data as a .pkl (pickle) file
+
+ Paramters:
+ data(dict):
+ Dictionary containing all the necessary data to save
+ """
+ # Open data file, create it if it does not exist
+ with open('data.pkl', 'wb') as data_file:
+ pickle.dump(data, data_file)
+
+def load_data() -> dict:
+ """
+ Loads saved pkl file and returns the stored data
+
+ Returns(dict):
+ Dictionary containing all the saved data
+ """
+ try:
+ with open('data.pkl', 'rb') as data_file: # Open data file
+ data = pickle.load(data_file)
+
+ return data
+ except (ValueError, FileNotFoundError):
+ # Data File is corrupted or not found so recreate it
+ save_data(data=DEFAULT_DATA)
+
+ return load_data()
+
+def drop(event, accept_mode: str = 'files'):
+ """
+ Drag & Drop verification process
+ """
+ global dnd
+ global dnddir
+
+ path = event.data
+
+ if accept_mode == 'folder':
+ path = path.replace('{', '').replace('}', '')
+ if not os.path.isdir(path):
+ tk.messagebox.showerror(title='Invalid Folder',
+ message='Your given export path is not a valid folder!')
+ return
+ # Set Variables
+ root.exportPath_var.set(path)
+ elif accept_mode == 'files':
+ # Clean path text and set path to the list of paths
+ path = path.replace('{', '')
+ path = path.split('} ')
+ path[-1] = path[-1].replace('}', '')
+ # Set Variables
+ dnd = 'yes'
+ root.inputPaths = path
+ root.update_inputPaths()
+ dnddir = os.path.dirname(path[0])
+ print('dnddir ', str(dnddir))
+ else:
+ # Invalid accept mode
+ return
+
+class ThreadSafeConsole(tk.Text):
+ """
+ Text Widget which is thread safe for tkinter
+ """
+ def __init__(self, master, **options):
+ tk.Text.__init__(self, master, **options)
+ self.queue = queue.Queue()
+ self.update_me()
+
+ def write(self, line):
+ self.queue.put(line)
+
+ def clear(self):
+ self.queue.put(None)
+
+ def update_me(self):
+ self.configure(state=tk.NORMAL)
+ try:
+ while 1:
+ line = self.queue.get_nowait()
+ if line is None:
+ self.delete(1.0, tk.END)
+ else:
+ self.insert(tk.END, str(line))
+ self.see(tk.END)
+ self.update_idletasks()
+ except queue.Empty:
+ pass
+ self.configure(state=tk.DISABLED)
+ self.after(100, self.update_me)
+
+class MainWindow(TkinterDnD.Tk):
+ # --Constants--
+ # Layout
+ IMAGE_HEIGHT = 140
+ FILEPATHS_HEIGHT = 85
+ OPTIONS_HEIGHT = 275
+ CONVERSIONBUTTON_HEIGHT = 35
+ COMMAND_HEIGHT = 200
+ PROGRESS_HEIGHT = 30
+ PADDING = 10
+
+ COL1_ROWS = 11
+ COL2_ROWS = 11
+
+ def __init__(self):
+ # Run the __init__ method on the tk.Tk class
+ super().__init__()
+
+ # Calculate window height
+ height = self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT
+ height += self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PROGRESS_HEIGHT
+ height += self.PADDING * 5 # Padding
+
+ # --Window Settings--
+ self.title('Ultimate Vocal Remover')
+ # Set Geometry and Center Window
+ self.geometry('{width}x{height}+{xpad}+{ypad}'.format(
+ width=620,
+ height=height,
+ xpad=int(self.winfo_screenwidth()/2 - 635/2),
+ ypad=int(self.winfo_screenheight()/2 - height/2 - 30)))
+ self.configure(bg='#0e0e0f') # Set background color to #0c0c0d
+ self.protocol("WM_DELETE_WINDOW", self.save_values)
+ self.resizable(False, False)
+ self.update()
+
+ # --Variables--
+ self.logo_img = open_image(path=banner_path,
+ size=(self.winfo_width(), 9999))
+ self.efile_img = open_image(path=efile_path,
+ size=(20, 20))
+ self.stop_img = open_image(path=stop_path,
+ size=(20, 20))
+ self.help_img = open_image(path=help_path,
+ size=(20, 20))
+ self.gen_opt_img = open_image(path=gen_opt_path,
+ size=(1016, 826))
+ self.mdx_opt_img = open_image(path=mdx_opt_path,
+ size=(1016, 826))
+ self.vr_opt_img = open_image(path=vr_opt_path,
+ size=(1016, 826))
+ self.ense_opt_img = open_image(path=ense_opt_path,
+ size=(1016, 826))
+ self.user_ens_opt_img = open_image(path=user_ens_opt_path,
+ size=(1016, 826))
+ self.credits_img = open_image(path=credits_path,
+ size=(100, 100))
+
+ self.instrumentalLabel_to_path = defaultdict(lambda: '')
+ self.lastInstrumentalModels = []
+
+ # -Tkinter Value Holders-
+ data = load_data()
+ # Paths
+ self.inputPaths = data['inputPaths']
+ self.inputPathop_var = tk.StringVar(value=data['inputPaths'])
+ self.exportPath_var = tk.StringVar(value=data['exportPath'])
+ self.saveFormat_var = tk.StringVar(value=data['saveFormat'])
+
+ # Processing Options
+ self.gpuConversion_var = tk.BooleanVar(value=data['gpu'])
+ self.postprocessing_var = tk.BooleanVar(value=data['postprocess'])
+ self.tta_var = tk.BooleanVar(value=data['tta'])
+ self.save_var = tk.BooleanVar(value=data['save'])
+ self.outputImage_var = tk.BooleanVar(value=data['output_image'])
+ # MDX-NET Specific Processing Options
+ self.demucsmodel_var = tk.BooleanVar(value=data['demucsmodel'])
+ self.non_red_var = tk.BooleanVar(value=data['non_red'])
+ self.noisereduc_var = tk.BooleanVar(value=data['noise_reduc'])
+ self.chunks_var = tk.StringVar(value=data['chunks'])
+ self.noisereduc_s_var = tk.StringVar(value=data['noisereduc_s'])
+ self.mixing_var = tk.StringVar(value=data['mixing']) #dropdown
+ # Models
+ self.instrumentalModel_var = tk.StringVar(value=data['modelInstrumentalLabel'])
+ # Model Test Mode
+ self.modelFolder_var = tk.BooleanVar(value=data['modelFolder'])
+ # Constants
+ self.winSize_var = tk.StringVar(value=data['window_size'])
+ self.agg_var = tk.StringVar(value=data['agg'])
+ # Instrumental or Vocal Only
+ self.voc_only_var = tk.BooleanVar(value=data['voc_only'])
+ self.inst_only_var = tk.BooleanVar(value=data['inst_only'])
+ # Choose Conversion Method
+ self.aiModel_var = tk.StringVar(value=data['aiModel'])
+ self.last_aiModel = self.aiModel_var.get()
+ # Choose Conversion Method
+ self.algo_var = tk.StringVar(value=data['algo'])
+ self.last_algo = self.aiModel_var.get()
+ # Choose Ensemble
+ self.ensChoose_var = tk.StringVar(value=data['ensChoose'])
+ self.last_ensChoose = self.ensChoose_var.get()
+ # Choose MDX-NET Model
+ self.mdxnetModel_var = tk.StringVar(value=data['mdxnetModel'])
+ self.last_mdxnetModel = self.mdxnetModel_var.get()
+ # Other
+ self.inputPathsEntry_var = tk.StringVar(value='')
+ self.lastDir = data['lastDir'] # nopep8
+ self.progress_var = tk.IntVar(value=0)
+ # Font
+ pyglet.font.add_file('lib_v5/fonts/centurygothic/GOTHIC.TTF')
+ self.font = tk.font.Font(family='Century Gothic', size=10)
+ self.fontRadio = tk.font.Font(family='Century Gothic', size=8)
+ # --Widgets--
+ self.create_widgets()
+ self.configure_widgets()
+ self.bind_widgets()
+ self.place_widgets()
+
+ self.update_available_models()
+ self.update_states()
+ self.update_loop()
+
+
+
+
+ # -Widget Methods-
+ def create_widgets(self):
+ """Create window widgets"""
+ self.title_Label = tk.Label(master=self, bg='#0e0e0f',
+ image=self.logo_img, compound=tk.TOP)
+ self.filePaths_Frame = ttk.Frame(master=self)
+ self.fill_filePaths_Frame()
+
+ self.options_Frame = ttk.Frame(master=self)
+ self.fill_options_Frame()
+
+ self.conversion_Button = ttk.Button(master=self,
+ text='Start Processing',
+ command=self.start_conversion)
+ self.stop_Button = ttk.Button(master=self,
+ image=self.stop_img,
+ command=self.restart)
+ self.help_Button = ttk.Button(master=self,
+ image=self.help_img,
+ command=self.help)
+
+ #ttk.Button(win, text= "Open", command= open_popup).pack()
+
+ self.efile_e_Button = ttk.Button(master=self,
+ image=self.efile_img,
+ command=self.open_exportPath_filedialog)
+
+ self.efile_i_Button = ttk.Button(master=self,
+ image=self.efile_img,
+ command=self.open_inputPath_filedialog)
+
+ self.progressbar = ttk.Progressbar(master=self, variable=self.progress_var)
+
+ self.command_Text = ThreadSafeConsole(master=self,
+ background='#0e0e0f',fg='#898b8e', font=('Century Gothic', 11),
+ borderwidth=0,)
+
+ self.command_Text.write(f'Ultimate Vocal Remover [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+
+
+ def configure_widgets(self):
+ """Change widget styling and appearance"""
+
+ #ttk.Style().configure('TCheckbutton', background='#0e0e0f',
+ # font=self.font, foreground='#d4d4d4')
+ #ttk.Style().configure('TRadiobutton', background='#0e0e0f',
+ # font=("Century Gothic", "8", "bold"), foreground='#d4d4d4')
+ #ttk.Style().configure('T', font=self.font, foreground='#d4d4d4')
+
+ #s = ttk.Style()
+ #s.configure('TButton', background='blue', foreground='black', font=('Century Gothic', '9', 'bold'), relief="groove")
+
+
+ def bind_widgets(self):
+ """Bind widgets to the drag & drop mechanic"""
+ self.filePaths_musicFile_Button.drop_target_register(DND_FILES)
+ self.filePaths_musicFile_Entry.drop_target_register(DND_FILES)
+ self.filePaths_saveTo_Button.drop_target_register(DND_FILES)
+ self.filePaths_saveTo_Entry.drop_target_register(DND_FILES)
+ self.filePaths_musicFile_Button.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='files'))
+ self.filePaths_musicFile_Entry.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='files'))
+ self.filePaths_saveTo_Button.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='folder'))
+ self.filePaths_saveTo_Entry.dnd_bind('<>',
+ lambda e: drop(e, accept_mode='folder'))
+
+ def place_widgets(self):
+ """Place main widgets"""
+ self.title_Label.place(x=-2, y=-2)
+ self.filePaths_Frame.place(x=10, y=155, width=-20, height=self.FILEPATHS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.options_Frame.place(x=10, y=250, width=-50, height=self.OPTIONS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.conversion_Button.place(x=50, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=-60 - 40, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.efile_e_Button.place(x=-45, y=200, width=35, height=30,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.efile_i_Button.place(x=-45, y=160, width=35, height=30,
+ relx=1, rely=0, relwidth=0, relheight=0)
+
+ self.stop_Button.place(x=-10 - 35, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.help_Button.place(x=-10 - 600, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
+ relx=1, rely=0, relwidth=0, relheight=0)
+ self.command_Text.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.PADDING*3, width=-30, height=self.COMMAND_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+ self.progressbar.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PADDING*4, width=-50, height=self.PROGRESS_HEIGHT,
+ relx=0, rely=0, relwidth=1, relheight=0)
+
+ def fill_filePaths_Frame(self):
+ """Fill Frame with neccessary widgets"""
+ # -Create Widgets-
+ # Save To Option
+ # Select Music Files Option
+
+ # Save To Option
+ self.filePaths_saveTo_Button = ttk.Button(master=self.filePaths_Frame,
+ text='Select output',
+ command=self.open_export_filedialog)
+ self.filePaths_saveTo_Entry = ttk.Entry(master=self.filePaths_Frame,
+
+ textvariable=self.exportPath_var,
+ state=tk.DISABLED
+ )
+ # Select Music Files Option
+ self.filePaths_musicFile_Button = ttk.Button(master=self.filePaths_Frame,
+ text='Select input',
+ command=self.open_file_filedialog)
+ self.filePaths_musicFile_Entry = ttk.Entry(master=self.filePaths_Frame,
+ textvariable=self.inputPathsEntry_var,
+ state=tk.DISABLED
+ )
+
+
+ # -Place Widgets-
+
+ # Select Music Files Option
+ self.filePaths_musicFile_Button.place(x=0, y=5, width=0, height=-10,
+ relx=0, rely=0, relwidth=0.3, relheight=0.5)
+ self.filePaths_musicFile_Entry.place(x=10, y=2.5, width=-50, height=-5,
+ relx=0.3, rely=0, relwidth=0.7, relheight=0.5)
+
+ # Save To Option
+ self.filePaths_saveTo_Button.place(x=0, y=5, width=0, height=-10,
+ relx=0, rely=0.5, relwidth=0.3, relheight=0.5)
+ self.filePaths_saveTo_Entry.place(x=10, y=2.5, width=-50, height=-5,
+ relx=0.3, rely=0.5, relwidth=0.7, relheight=0.5)
+
+
+ def fill_options_Frame(self):
+ """Fill Frame with neccessary widgets"""
+ # -Create Widgets-
+
+
+ # Save as wav
+ self.options_wav_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='WAV',
+ variable=self.saveFormat_var,
+ value='Wav'
+ )
+
+ # Save as flac
+ self.options_flac_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='FLAC',
+ variable=self.saveFormat_var,
+ value='Flac'
+ )
+
+ # Save as mp3
+ self.options_mpThree_Radiobutton = ttk.Radiobutton(master=self.options_Frame,
+ text='MP3',
+ variable=self.saveFormat_var,
+ value='Mp3',
+ )
+
+ # -Column 1-
+
+ # Choose Conversion Method
+ self.options_aiModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose Process Method', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_aiModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.aiModel_var,
+ None, 'VR Architecture', 'MDX-Net', 'Ensemble Mode')
+ # Choose Instrumental Model
+ self.options_instrumentalModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose Main Model',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_instrumentalModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.instrumentalModel_var)
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label = tk.Label(master=self.options_Frame,
+ text='Choose MDX-Net Model', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+
+ self.options_mdxnetModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.mdxnetModel_var,
+ None, 'UVR-MDX-NET 1', 'UVR-MDX-NET 2', 'UVR-MDX-NET 3', 'UVR-MDX-NET Karaoke')
+ # Ensemble Mode
+ self.options_ensChoose_Label = tk.Label(master=self.options_Frame,
+ text='Choose Ensemble', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_ensChoose_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.ensChoose_var,
+ None, 'MDX-Net/VR Ensemble', 'HP Models', 'Vocal Models', 'HP2 Models', 'All HP/HP2 Models', 'User Ensemble')
+
+ # Choose Agorithim
+ self.options_algo_Label = tk.Label(master=self.options_Frame,
+ text='Choose Algorithm', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_algo_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.algo_var,
+ None, 'Vocals (Max Spec)', 'Instrumentals (Min Spec)')#, 'Invert (Normal)', 'Invert (Spectral)')
+
+
+ # -Column 2-
+
+ # WINDOW SIZE
+ self.options_winSize_Label = tk.Label(master=self.options_Frame,
+ text='Window Size', anchor=tk.CENTER,
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_winSize_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.winSize_var,
+ None, '320', '512','1024')
+ # MDX-chunks
+ self.options_chunks_Label = tk.Label(master=self.options_Frame,
+ text='Chunks',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_chunks_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.chunks_var,
+ None, 'Auto', '1', '5', '10', '15', '20',
+ '25', '30', '35', '40', '45', '50',
+ '55', '60', '65', '70', '75', '80',
+ '85', '90', '95', 'Full')
+
+ #Checkboxes
+ # GPU Selection
+ self.options_gpu_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='GPU Conversion',
+ variable=self.gpuConversion_var,
+ )
+
+ # Vocal Only
+ self.options_voc_only_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Vocals Only',
+ variable=self.voc_only_var,
+ )
+ # Instrumental Only
+ self.options_inst_only_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Instrumental Only',
+ variable=self.inst_only_var,
+ )
+ # TTA
+ self.options_tta_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='TTA',
+ variable=self.tta_var,
+ )
+
+ # MDX-Auto-Chunk
+ self.options_non_red_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save Noisey Vocal',
+ variable=self.non_red_var,
+ )
+
+ # Postprocessing
+ self.options_post_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Post-Process',
+ variable=self.postprocessing_var,
+ )
+
+ # -Column 3-
+
+ # AGG
+ self.options_agg_Label = tk.Label(master=self.options_Frame,
+ text='Aggression Setting',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_agg_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.agg_var,
+ None, '1', '2', '3', '4', '5',
+ '6', '7', '8', '9', '10', '11',
+ '12', '13', '14', '15', '16', '17',
+ '18', '19', '20')
+
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label = tk.Label(master=self.options_Frame,
+ text='Noise Reduction',
+ background='#0e0e0f', font=self.font, foreground='#13a4c9')
+ self.options_noisereduc_s_Optionmenu = ttk.OptionMenu(self.options_Frame,
+ self.noisereduc_s_var,
+ None, 'None', '0', '1', '2', '3', '4', '5',
+ '6', '7', '8', '9', '10', '11',
+ '12', '13', '14', '15', '16', '17',
+ '18', '19', '20')
+
+
+ # Save Image
+ self.options_image_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Output Image',
+ variable=self.outputImage_var,
+ )
+
+ # MDX-Enable Demucs Model
+ self.options_demucsmodel_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Demucs Model',
+ variable=self.demucsmodel_var,
+ )
+
+ # MDX-Noise Reduction
+ self.options_noisereduc_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Noise Reduction',
+ variable=self.noisereduc_var,
+ )
+
+ # Ensemble Save Ensemble Outputs
+ self.options_save_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Save All Outputs',
+ variable=self.save_var,
+ )
+
+ # Model Test Mode
+ self.options_modelFolder_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
+ text='Model Test Mode',
+ variable=self.modelFolder_var,
+ )
+
+ # -Place Widgets-
+
+ # -Column 0-
+
+ # Save as
+ self.options_wav_Radiobutton.place(x=400, y=-5, width=0, height=6,
+ relx=0, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_flac_Radiobutton.place(x=271, y=-5, width=0, height=6,
+ relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_mpThree_Radiobutton.place(x=143, y=-5, width=0, height=6,
+ relx=2/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # -Column 1-
+
+ # Choose Conversion Method
+ self.options_aiModel_Label.place(x=0, y=0, width=0, height=-10,
+ relx=0, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_aiModel_Optionmenu.place(x=0, y=-2, width=0, height=7,
+ relx=0, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Main Model
+ self.options_instrumentalModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_instrumentalModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_mdxnetModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+
+ # Choose Algorithm
+ self.options_algo_Label.place(x=20, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_algo_Optionmenu.place(x=12, y=-2, width=0, height=7,
+ relx=1/3, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+
+ # -Column 2-
+
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---MDX-Net Specific---
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Checkboxes
+
+ #GPU Conversion
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # TTA
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-Keep Non_Reduced Vocal
+ self.options_non_red_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # -Column 3-
+
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Checkboxes
+ #---MDX-Net Specific---
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ #---VR Architecture Specific---
+ #Post-Process
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---Ensemble Specific---
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #---MDX-Net & VR Architecture Specific---
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # Change States
+ self.aiModel_var.trace_add('write',
+ lambda *args: self.deselect_models())
+ self.ensChoose_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ self.inst_only_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ self.voc_only_var.trace_add('write',
+ lambda *args: self.update_states())
+ self.noisereduc_s_var.trace_add('write',
+ lambda *args: self.update_states())
+ self.non_red_var.trace_add('write',
+ lambda *args: self.update_states())
+
+ # Opening filedialogs
+ def open_file_filedialog(self):
+ """Make user select music files"""
+ global dnd
+ global nondnd
+
+ if self.lastDir is not None:
+ if not os.path.isdir(self.lastDir):
+ self.lastDir = None
+
+ paths = tk.filedialog.askopenfilenames(
+ parent=self,
+ title=f'Select Music Files',
+ initialfile='',
+ initialdir=self.lastDir,
+ )
+ if paths: # Path selected
+ self.inputPaths = paths
+ dnd = 'no'
+ self.update_inputPaths()
+ nondnd = os.path.dirname(paths[0])
+ print('last dir', self.lastDir)
+
+ def open_export_filedialog(self):
+ """Make user select a folder to export the converted files in"""
+ path = tk.filedialog.askdirectory(
+ parent=self,
+ title=f'Select Folder',)
+ if path: # Path selected
+ self.exportPath_var.set(path)
+
+ def open_exportPath_filedialog(self):
+ filename = self.exportPath_var.get()
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def open_inputPath_filedialog(self):
+ """Open Input Directory"""
+
+ try:
+ if dnd == 'yes':
+ self.lastDir = str(dnddir)
+ filename = str(self.lastDir)
+ if sys.platform == "win32":
+ os.startfile(filename)
+ if dnd == 'no':
+ self.lastDir = str(nondnd)
+ filename = str(self.lastDir)
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ except:
+ filename = str(self.lastDir)
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+
+ def start_conversion(self):
+ """
+ Start the conversion for all the given mp3 and wav files
+ """
+
+ # -Get all variables-
+ export_path = self.exportPath_var.get()
+ input_paths = self.inputPaths
+ instrumentalModel_path = self.instrumentalLabel_to_path[self.instrumentalModel_var.get()] # nopep8
+ # mdxnetModel_path = self.mdxnetLabel_to_path[self.mdxnetModel_var.get()]
+ # Get constants
+ instrumental = self.instrumentalModel_var.get()
+ try:
+ if [bool(instrumental)].count(True) == 2: #CHECKTHIS
+ window_size = DEFAULT_DATA['window_size']
+ agg = DEFAULT_DATA['agg']
+ chunks = DEFAULT_DATA['chunks']
+ noisereduc_s = DEFAULT_DATA['noisereduc_s']
+ mixing = DEFAULT_DATA['mixing']
+ else:
+ window_size = int(self.winSize_var.get())
+ agg = int(self.agg_var.get())
+ chunks = str(self.chunks_var.get())
+ noisereduc_s = str(self.noisereduc_s_var.get())
+ mixing = str(self.mixing_var.get())
+ ensChoose = str(self.ensChoose_var.get())
+ mdxnetModel = str(self.mdxnetModel_var.get())
+
+ except SyntaxError: # Non integer was put in entry box
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Music File',
+ message='You have selected an invalid music file!\nPlease make sure that your files still exist and ends with either ".mp3", ".mp4", ".m4a", ".flac", ".wav"')
+ return
+
+ # -Check for invalid inputs-
+
+ for path in input_paths:
+ if not os.path.isfile(path):
+ tk.messagebox.showwarning(master=self,
+ title='Drag and Drop Feature Failed or Invalid Input',
+ message='The input is invalid, or the drag and drop feature failed to select your files properly.\n\nPlease try the following:\n\n1. Select your inputs using the \"Select Input\" button\n2. Verify the input is valid.\n3. Then try again.')
+ return
+
+
+ if self.aiModel_var.get() == 'VR Architecture':
+ if not os.path.isfile(instrumentalModel_path):
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Main Model File',
+ message='You have selected an invalid main model file!\nPlease make sure that your model file still exists!')
+ return
+
+ if not os.path.isdir(export_path):
+ tk.messagebox.showwarning(master=self,
+ title='Invalid Export Directory',
+ message='You have selected an invalid export directory!\nPlease make sure that your directory still exists!')
+ return
+
+ if self.aiModel_var.get() == 'VR Architecture':
+ inference = inference_v5
+ elif self.aiModel_var.get() == 'Ensemble Mode':
+ inference = inference_v5_ensemble
+ elif self.aiModel_var.get() == 'MDX-Net':
+ inference = inference_MDX
+ else:
+ raise TypeError('This error should not occur.')
+
+ # -Run the algorithm-
+ threading.Thread(target=inference.main,
+ kwargs={
+ # Paths
+ 'input_paths': input_paths,
+ 'export_path': export_path,
+ 'saveFormat': self.saveFormat_var.get(),
+ # Processing Options
+ 'gpu': 0 if self.gpuConversion_var.get() else -1,
+ 'postprocess': self.postprocessing_var.get(),
+ 'tta': self.tta_var.get(),
+ 'save': self.save_var.get(),
+ 'output_image': self.outputImage_var.get(),
+ 'algo': self.algo_var.get(),
+ # Models
+ 'instrumentalModel': instrumentalModel_path,
+ 'vocalModel': '', # Always not needed
+ 'useModel': 'instrumental', # Always instrumental
+ # Model Folder
+ 'modelFolder': self.modelFolder_var.get(),
+ # Constants
+ 'window_size': window_size,
+ 'agg': agg,
+ 'break': False,
+ 'ensChoose': ensChoose,
+ 'mdxnetModel': mdxnetModel,
+ # Other Variables (Tkinter)
+ 'window': self,
+ 'text_widget': self.command_Text,
+ 'button_widget': self.conversion_Button,
+ 'inst_menu': self.options_instrumentalModel_Optionmenu,
+ 'progress_var': self.progress_var,
+ # MDX-Net Specific
+ 'demucsmodel': self.demucsmodel_var.get(),
+ 'non_red': self.non_red_var.get(),
+ 'noise_reduc': self.noisereduc_var.get(),
+ 'voc_only': self.voc_only_var.get(),
+ 'inst_only': self.inst_only_var.get(),
+ 'chunks': chunks,
+ 'noisereduc_s': noisereduc_s,
+ 'mixing': mixing,
+ },
+ daemon=True
+ ).start()
+
+ # Models
+ def update_inputPaths(self):
+ """Update the music file entry"""
+ if self.inputPaths:
+ # Non-empty Selection
+ text = '; '.join(self.inputPaths)
+ else:
+ # Empty Selection
+ text = ''
+ self.inputPathsEntry_var.set(text)
+
+
+
+ def update_loop(self):
+ """Update the dropdown menu"""
+ self.update_available_models()
+
+ self.after(3000, self.update_loop)
+
+ def update_available_models(self):
+ """
+ Loop through every model (.pth) in the models directory
+ and add to the select your model list
+ """
+ temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, 'Main_Models') # nopep8
+
+ # Main models
+ new_InstrumentalModels = os.listdir(temp_instrumentalModels_dir)
+ if new_InstrumentalModels != self.lastInstrumentalModels:
+ self.instrumentalLabel_to_path.clear()
+ self.options_instrumentalModel_Optionmenu['menu'].delete(0, 'end')
+ for file_name in new_InstrumentalModels:
+ if file_name.endswith('.pth'):
+ # Add Radiobutton to the Options Menu
+ self.options_instrumentalModel_Optionmenu['menu'].add_radiobutton(label=file_name,
+ command=tk._setit(self.instrumentalModel_var, file_name))
+ # Link the files name to its absolute path
+ self.instrumentalLabel_to_path[file_name] = os.path.join(temp_instrumentalModels_dir, file_name) # nopep8
+ self.lastInstrumentalModels = new_InstrumentalModels
+
+ def update_states(self):
+ """
+ Vary the states for all widgets based
+ on certain selections
+ """
+
+ if self.aiModel_var.get() == 'MDX-Net':
+ # Place Widgets
+
+ # Choose MDX-Net Model
+ self.options_mdxnetModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_mdxnetModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.configure(state=tk.NORMAL)
+ self.options_demucsmodel_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # MDX-Keep Non_Reduced Vocal
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+ self.options_non_red_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+
+ # Forget widgets
+ self.options_ensChoose_Label.place_forget()
+ self.options_ensChoose_Optionmenu.place_forget()
+ self.options_instrumentalModel_Label.place_forget()
+ self.options_instrumentalModel_Optionmenu.place_forget()
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_tta_Checkbutton.configure(state=tk.DISABLED)
+ self.options_tta_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_winSize_Label.place_forget()
+ self.options_winSize_Optionmenu.place_forget()
+ self.options_agg_Label.place_forget()
+ self.options_agg_Optionmenu.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+
+
+ elif self.aiModel_var.get() == 'VR Architecture':
+ #Keep for Ensemble & VR Architecture Mode
+ # Choose Main Model
+ self.options_instrumentalModel_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_instrumentalModel_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Post-Process
+ self.options_post_Checkbutton.configure(state=tk.NORMAL)
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.configure(state=tk.NORMAL)
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Model Test Mode
+ self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
+ self.options_modelFolder_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Forget Widgets
+ self.options_ensChoose_Label.place_forget()
+ self.options_ensChoose_Optionmenu.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+
+ elif self.aiModel_var.get() == 'Ensemble Mode':
+ if self.ensChoose_var.get() == 'User Ensemble':
+ # Choose Algorithm
+ self.options_algo_Label.place(x=20, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_algo_Optionmenu.place(x=12, y=-2, width=0, height=7,
+ relx=1/3, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # Forget Widgets
+ self.options_save_Checkbutton.configure(state=tk.DISABLED)
+ self.options_save_Checkbutton.place_forget()
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_tta_Checkbutton.configure(state=tk.DISABLED)
+ self.options_tta_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_modelFolder_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_gpu_Checkbutton.configure(state=tk.DISABLED)
+ self.options_gpu_Checkbutton.place_forget()
+ self.options_voc_only_Checkbutton.configure(state=tk.DISABLED)
+ self.options_voc_only_Checkbutton.place_forget()
+ self.options_inst_only_Checkbutton.configure(state=tk.DISABLED)
+ self.options_inst_only_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_winSize_Label.place_forget()
+ self.options_winSize_Optionmenu.place_forget()
+ self.options_agg_Label.place_forget()
+ self.options_agg_Optionmenu.place_forget()
+
+ elif self.ensChoose_var.get() == 'MDX-Net/VR Ensemble':
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # MDX-chunks
+ self.options_chunks_Label.place(x=12, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_chunks_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-noisereduc_s
+ self.options_noisereduc_s_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_noisereduc_s_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=-7, width=0, height=-10,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-5, width=-118, height=7,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=-7, width=0, height=-10,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-5, width=-118, height=7,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=8/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=1/3, rely=9/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # MDX-demucs Model
+ self.options_demucsmodel_Checkbutton.configure(state=tk.NORMAL)
+ self.options_demucsmodel_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=8/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.configure(state=tk.NORMAL)
+ self.options_save_Checkbutton.place(x=35, y=3, width=0, height=5,
+ relx=2/3, rely=9/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # Forget Widgets
+ self.options_post_Checkbutton.configure(state=tk.DISABLED)
+ self.options_post_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_modelFolder_Checkbutton.place_forget()
+ # self.options_image_Checkbutton.configure(state=tk.DISABLED)
+ # self.options_image_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ else:
+ # Choose Ensemble
+ self.options_ensChoose_Label.place(x=0, y=19, width=0, height=-10,
+ relx=0, rely=6/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ self.options_ensChoose_Optionmenu.place(x=0, y=19, width=0, height=7,
+ relx=0, rely=7/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
+ # WINDOW
+ self.options_winSize_Label.place(x=13, y=0, width=0, height=-10,
+ relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_winSize_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # AGG
+ self.options_agg_Label.place(x=15, y=0, width=0, height=-10,
+ relx=2/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ self.options_agg_Optionmenu.place(x=71, y=-2, width=-118, height=7,
+ relx=2/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #GPU Conversion
+ self.options_gpu_Checkbutton.configure(state=tk.NORMAL)
+ self.options_gpu_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Vocals Only
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Instrumental Only
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+ self.options_inst_only_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=1/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ # TTA
+ self.options_tta_Checkbutton.configure(state=tk.NORMAL)
+ self.options_tta_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Post-Process
+ self.options_post_Checkbutton.configure(state=tk.NORMAL)
+ self.options_post_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=6/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Save Image
+ # self.options_image_Checkbutton.configure(state=tk.NORMAL)
+ # self.options_image_Checkbutton.place(x=35, y=21, width=0, height=5,
+ # relx=2/3, rely=5/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Ensemble Save Outputs
+ self.options_save_Checkbutton.configure(state=tk.NORMAL)
+ self.options_save_Checkbutton.place(x=35, y=21, width=0, height=5,
+ relx=2/3, rely=7/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
+ #Forget Widgets
+ self.options_algo_Label.place_forget()
+ self.options_algo_Optionmenu.place_forget()
+ self.options_instrumentalModel_Label.place_forget()
+ self.options_instrumentalModel_Optionmenu.place_forget()
+ self.options_chunks_Label.place_forget()
+ self.options_chunks_Optionmenu.place_forget()
+ self.options_noisereduc_s_Label.place_forget()
+ self.options_noisereduc_s_Optionmenu.place_forget()
+ self.options_mdxnetModel_Label.place_forget()
+ self.options_mdxnetModel_Optionmenu.place_forget()
+ self.options_modelFolder_Checkbutton.place_forget()
+ self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
+ self.options_noisereduc_Checkbutton.place_forget()
+ self.options_noisereduc_Checkbutton.configure(state=tk.DISABLED)
+ self.options_demucsmodel_Checkbutton.place_forget()
+ self.options_demucsmodel_Checkbutton.configure(state=tk.DISABLED)
+ self.options_non_red_Checkbutton.place_forget()
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+
+
+ if self.inst_only_var.get() == True:
+ self.options_voc_only_Checkbutton.configure(state=tk.DISABLED)
+ self.voc_only_var.set(False)
+ self.non_red_var.set(False)
+ elif self.inst_only_var.get() == False:
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+ self.options_voc_only_Checkbutton.configure(state=tk.NORMAL)
+
+ if self.voc_only_var.get() == True:
+ self.options_inst_only_Checkbutton.configure(state=tk.DISABLED)
+ self.inst_only_var.set(False)
+ elif self.voc_only_var.get() == False:
+ self.options_inst_only_Checkbutton.configure(state=tk.NORMAL)
+
+ if self.noisereduc_s_var.get() == 'None':
+ self.options_non_red_Checkbutton.configure(state=tk.DISABLED)
+ self.non_red_var.set(False)
+ if not self.noisereduc_s_var.get() == 'None':
+ self.options_non_red_Checkbutton.configure(state=tk.NORMAL)
+
+
+ self.update_inputPaths()
+
+ def deselect_models(self):
+ """
+ Run this method on version change
+ """
+ if self.aiModel_var.get() == self.last_aiModel:
+ return
+ else:
+ self.last_aiModel = self.aiModel_var.get()
+
+ self.instrumentalModel_var.set('')
+ self.ensChoose_var.set('MDX-Net/VR Ensemble')
+ self.mdxnetModel_var.set('UVR-MDX-NET 1')
+
+ self.winSize_var.set(DEFAULT_DATA['window_size'])
+ self.agg_var.set(DEFAULT_DATA['agg'])
+ self.modelFolder_var.set(DEFAULT_DATA['modelFolder'])
+
+
+ self.update_available_models()
+ self.update_states()
+
+ def restart(self):
+ """
+ Restart the application after asking for confirmation
+ """
+ confirm = tk.messagebox.askyesno(title='Restart Confirmation',
+ message='This will restart the application and halt any running processes. Your current settings will be saved. \n\n Are you sure you wish to continue?')
+
+ if confirm:
+ self.save_values()
+
+ subprocess.Popen(f'UVR_Launcher.exe')
+ exit()
+ else:
+ pass
+
+ def help(self):
+ """
+ Open Help Guide
+ """
+ top= Toplevel(self)
+ top.geometry("1080x920")
+ top.title("UVR Help Guide")
+
+ top.resizable(False, False) # This code helps to disable windows from resizing
+
+ window_height = 920
+ window_width = 1080
+
+ screen_width = top.winfo_screenwidth()
+ screen_height = top.winfo_screenheight()
+
+ x_cordinate = int((screen_width/2) - (window_width/2))
+ y_cordinate = int((screen_height/2) - (window_height/2))
+
+ top.geometry("{}x{}+{}+{}".format(window_width, window_height, x_cordinate, y_cordinate))
+
+ # change title bar icon
+ top.iconbitmap('img\\UVR-Icon-v2.ico')
+
+ tabControl = ttk.Notebook(top)
+
+ tab1 = ttk.Frame(tabControl)
+ tab2 = ttk.Frame(tabControl)
+ tab3 = ttk.Frame(tabControl)
+ tab4 = ttk.Frame(tabControl)
+ tab5 = ttk.Frame(tabControl)
+ tab6 = ttk.Frame(tabControl)
+ tab7 = ttk.Frame(tabControl)
+ tab8 = ttk.Frame(tabControl)
+ tab9 = ttk.Frame(tabControl)
+
+ tabControl.add(tab1, text ='General Options')
+ tabControl.add(tab2, text ='VR Architecture Options')
+ tabControl.add(tab3, text ='MDX-Net Options')
+ tabControl.add(tab4, text ='Ensemble Mode')
+ tabControl.add(tab5, text ='User Ensemble')
+ tabControl.add(tab6, text ='More Info')
+ tabControl.add(tab7, text ='Credits')
+ tabControl.add(tab8, text ='Updates')
+ tabControl.add(tab9, text ='Error Log')
+
+ tabControl.pack(expand = 1, fill ="both")
+
+ #Configure the row/col of our frame and root window to be resizable and fill all available space
+ tab6.grid_rowconfigure(0, weight=1)
+ tab6.grid_columnconfigure(0, weight=1)
+
+ tab7.grid_rowconfigure(0, weight=1)
+ tab7.grid_columnconfigure(0, weight=1)
+
+ tab8.grid_rowconfigure(0, weight=1)
+ tab8.grid_columnconfigure(0, weight=1)
+
+ tab9.grid_rowconfigure(0, weight=1)
+ tab9.grid_columnconfigure(0, weight=1)
+
+ ttk.Label(tab1, image=self.gen_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab2, image=self.vr_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab3, image=self.mdx_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab4, image=self.ense_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ ttk.Label(tab5, image=self.user_ens_opt_img).grid(column = 0,
+ row = 0,
+ padx = 30,
+ pady = 30)
+
+ #frame0
+ frame0=Frame(tab6,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Notes",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=15)
+
+ l0=Label(frame0,text="UVR is 100% free and open-source but MIT licensed.\nAll the models provided as part of UVR were trained by its core developers.\nPlease credit the core UVR developers if you choose to use any of our models or code for projects unrelated to UVR.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=2,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Resources",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=3,column=0,padx=20,pady=15, sticky=N)
+
+ link = Label(frame0, text="Ultimate Vocal Remover (Official GitHub)",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=4,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui"))
+
+ l0=Label(frame0,text="You can find updates, report issues, and give us a shout via our official GitHub.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=5,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="SoX - Sound eXchange",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=6,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://sourceforge.net/projects/sox/files/sox/14.4.2/sox-14.4.2-win32.zip/download"))
+
+ l0=Label(frame0,text="UVR relies on SoX for Noise Reduction. It's automatically included via the UVR installer but not the developer build.\nIf you are missing SoX, please download it via the link and extract the SoX archive to the following directory - lib_v5/sox",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=7,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="FFmpeg",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=8,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://www.wikihow.com/Install-FFmpeg-on-Windows"))
+
+ l0=Label(frame0,text="UVR relies on FFmpeg for processing non-wav audio files.\nIt's automatically included via the UVR installer but not the developer build.\nIf you are missing FFmpeg, please see the installation guide via the link provided.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=9,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="X-Minus AI",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=10,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://x-minus.pro/ai"))
+
+ l0=Label(frame0,text="Many of the models provided are also on X-Minus.\nThis resource primarily benefits users without the computing resources to run the GUI or models locally.",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=11,column=0,padx=10,pady=10)
+
+ link = Label(frame0, text="Official UVR Patreon",font=("Century Gothic", "14", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=12,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://www.patreon.com/uvr"))
+
+ l0=Label(frame0,text="If you wish to support and donate to this project, click the link above and become a Patreon!",font=("Century Gothic", "13"), justify="center", fg="#F6F6F7")
+ l0.grid(row=13,column=0,padx=10,pady=10)
+
+ frame0=Frame(tab7,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ #inside frame0
+
+ l0=Label(frame0,text="Core UVR Developers",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=0,column=0,padx=20,pady=10, sticky=N)
+
+ l0=Label(frame0,image=self.credits_img,font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=1,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Anjok07\nAufr33",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=2,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Special Thanks",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=4,column=0,padx=20,pady=15)
+
+ l0=Label(frame0,text="DilanBoskan",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=5,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Your contributions at the start of this project were essential to the success of UVR. Thank you!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=6,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Tsurumeso",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=7,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/tsurumeso/vocal-remover"))
+
+ l0=Label(frame0,text="Developed the original VR Architecture AI code.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=8,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Kuielab & Woosung Choi",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=9,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/kuielab"))
+
+ l0=Label(frame0,text="Developed the original MDX-Net AI code.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=10,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="Bas Curtiz",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=11,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Designed the official UVR logo, icon, banner, splash screen, and interface.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=12,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Adefossez & Demucs",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=13,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/facebookresearch/demucs"))
+
+ l0=Label(frame0,text="Core developer of Facebook's Demucs Music Source Separation.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=14,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="Audio Separation Discord Community",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=15,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Thank you for the support!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=16,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="CC Karokee & Friends Discord Community",font=("Century Gothic", "13", "bold"), justify="center", fg="#13a4c9")
+ l0.grid(row=17,column=0,padx=10,pady=10)
+
+ l0=Label(frame0,text="Thank you for the support!",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=18,column=0,padx=0,pady=0)
+
+ frame0=Frame(tab8,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Update Details",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=10)
+
+ l0=Label(frame0,text="Installing Model Expansion Pack",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=2,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="1. Download the model expansion pack via the provided link below.\n2. Once the download has completed, click the \"Open Models Directory\" button below.\n3. Extract the \'Main Models\' folder within the downloaded archive to the opened \"models\" directory.\n4. Without restarting the application, you will now see the new models appear under the VR Architecture model selection list.",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=3,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="Model Expansion Pack",font=("Century Gothic", "11", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=4,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui/releases/tag/v5.2.0"))
+
+ l0=Button(frame0,text='Open Models Directory',font=("Century Gothic", "11"), command=self.open_Modelfolder_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=5,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="\n\n\nBackward Compatibility",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=6,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="The v4 Models are fully compatible with this GUI. \n1. If you already have them on your system, click the \"Open Models Directory\" button below. \n2. Place the files with extension \".pth\" into the \"Main Models\" directory. \n3. Now they will automatically appear in the VR Architecture model selection list.\n Note: The v2 models are not compatible with this GUI.\n",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=7,column=0,padx=0,pady=0)
+
+ l0=Button(frame0,text='Open Models Directory',font=("Century Gothic", "11"), command=self.open_Modelfolder_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=8,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="\n\n\nInstalling Future Updates",font=("Century Gothic", "13", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=9,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="New updates and patches for this application can be found on the official UVR Releases GitHub page (link below).\nAny new update instructions will likely require the use of the \"Open Application Directory\" button below.",font=("Century Gothic", "11"), justify="center", fg="#f4f4f4")
+ l0.grid(row=10,column=0,padx=0,pady=0)
+
+ link = Label(frame0, text="UVR Releases GitHub Page",font=("Century Gothic", "11", "underline"), justify="center", fg="#13a4c9", cursor="hand2")
+ link.grid(row=11,column=0,padx=10,pady=10)
+ link.bind("", lambda e:
+ callback("https://github.com/Anjok07/ultimatevocalremovergui/releases"))
+
+ l0=Button(frame0,text='Open Application Directory',font=("Century Gothic", "11"), command=self.open_appdir_filedialog, justify="left", wraplength=1000, bg="black", relief="ridge")
+ l0.grid(row=12,column=0,padx=0,pady=0)
+
+ frame0=Frame(tab9,highlightbackground='red',highlightthicknes=0)
+ frame0.grid(row=0,column=0,padx=0,pady=30)
+
+ l0=Label(frame0,text="Error Details",font=("Century Gothic", "16", "bold"), justify="center", fg="#f4f4f4")
+ l0.grid(row=1,column=0,padx=20,pady=10)
+
+ l0=Label(frame0,text="This tab will show the raw details of the last error received.",font=("Century Gothic", "12"), justify="center", fg="#F6F6F7")
+ l0.grid(row=2,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="(Click the error console below to copy the error)\n",font=("Century Gothic", "10"), justify="center", fg="#F6F6F7")
+ l0.grid(row=3,column=0,padx=0,pady=0)
+
+ with open("errorlog.txt", "r") as f:
+ l0=Button(frame0,text=f.read(),font=("Century Gothic", "11"), command=self.copy_clip, justify="left", wraplength=1000, fg="#FF0000", bg="black", relief="sunken")
+ l0.grid(row=4,column=0,padx=0,pady=0)
+
+ l0=Label(frame0,text="",font=("Century Gothic", "10"), justify="center", fg="#F6F6F7")
+ l0.grid(row=5,column=0,padx=0,pady=0)
+
+ def copy_clip(self):
+ copy_t = open("errorlog.txt", "r").read()
+ pyperclip.copy(copy_t)
+
+ def open_Modelfolder_filedialog(self):
+ """Let user paste a ".pth" model to use for the vocal seperation"""
+ filename = 'models'
+
+ if sys.platform == "win32":
+ os.startfile(filename)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def open_appdir_filedialog(self):
+
+ pathname = '.'
+
+ print(pathname)
+
+ if sys.platform == "win32":
+ os.startfile(pathname)
+ else:
+ opener = "open" if sys.platform == "darwin" else "xdg-open"
+ subprocess.call([opener, filename])
+
+ def save_values(self):
+ """
+ Save the data of the application
+ """
+ # Get constants
+ instrumental = self.instrumentalModel_var.get()
+ if [bool(instrumental)].count(True) == 2: #Checkthis
+ window_size = DEFAULT_DATA['window_size']
+ agg = DEFAULT_DATA['agg']
+ chunks = DEFAULT_DATA['chunks']
+ noisereduc_s = DEFAULT_DATA['noisereduc_s']
+ mixing = DEFAULT_DATA['mixing']
+ else:
+ window_size = self.winSize_var.get()
+ agg = self.agg_var.get()
+ chunks = self.chunks_var.get()
+ noisereduc_s = self.noisereduc_s_var.get()
+ mixing = self.mixing_var.get()
+
+ # -Save Data-
+ save_data(data={
+ 'exportPath': self.exportPath_var.get(),
+ 'inputPaths': self.inputPaths,
+ 'saveFormat': self.saveFormat_var.get(),
+ 'gpu': self.gpuConversion_var.get(),
+ 'postprocess': self.postprocessing_var.get(),
+ 'tta': self.tta_var.get(),
+ 'save': self.save_var.get(),
+ 'output_image': self.outputImage_var.get(),
+ 'window_size': window_size,
+ 'agg': agg,
+ 'useModel': 'instrumental',
+ 'lastDir': self.lastDir,
+ 'modelFolder': self.modelFolder_var.get(),
+ 'modelInstrumentalLabel': self.instrumentalModel_var.get(),
+ 'aiModel': self.aiModel_var.get(),
+ 'algo': self.algo_var.get(),
+ 'ensChoose': self.ensChoose_var.get(),
+ 'mdxnetModel': self.mdxnetModel_var.get(),
+ #MDX-Net
+ 'demucsmodel': self.demucsmodel_var.get(),
+ 'non_red': self.non_red_var.get(),
+ 'noise_reduc': self.noisereduc_var.get(),
+ 'voc_only': self.voc_only_var.get(),
+ 'inst_only': self.inst_only_var.get(),
+ 'chunks': chunks,
+ 'noisereduc_s': noisereduc_s,
+ 'mixing': mixing,
+ })
+
+ self.destroy()
+
+if __name__ == "__main__":
+
+ root = MainWindow()
+
+ root.tk.call(
+ 'wm',
+ 'iconphoto',
+ root._w,
+ tk.PhotoImage(file='img\\GUI-icon.png')
+ )
+
+ lib_v5.sv_ttk.set_theme("dark")
+ lib_v5.sv_ttk.use_dark_theme() # Set dark theme
+
+ #Define a callback function
+ def callback(url):
+ webbrowser.open_new_tab(url)
+
+ root.mainloop()
diff --git a/VocalRemover.py b/VocalRemover.py
deleted file mode 100644
index 9fd172b..0000000
--- a/VocalRemover.py
+++ /dev/null
@@ -1,786 +0,0 @@
-# GUI modules
-import tkinter as tk
-import tkinter.ttk as ttk
-import tkinter.messagebox
-import tkinter.filedialog
-import tkinter.font
-from tkinterdnd2 import TkinterDnD, DND_FILES # Enable Drag & Drop
-from datetime import datetime
-# Images
-from PIL import Image
-from PIL import ImageTk
-import pickle # Save Data
-# Other Modules
-import subprocess # Run python file
-# Pathfinding
-import pathlib
-import sys
-import os
-import subprocess
-from collections import defaultdict
-# Used for live text displaying
-import queue
-import threading # Run the algorithm inside a thread
-
-
-from pathlib import Path
-
-import inference_v5
-import inference_v5_ensemble
-# import win32gui, win32con
-
-# the_program_to_hide = win32gui.GetForegroundWindow()
-# win32gui.ShowWindow(the_program_to_hide , win32con.SW_HIDE)
-
-# Change the current working directory to the directory
-# this file sits in
-if getattr(sys, 'frozen', False):
- # If the application is run as a bundle, the PyInstaller bootloader
- # extends the sys module by a flag frozen=True and sets the app
- # path into variable _MEIPASS'.
- base_path = sys._MEIPASS
-else:
- base_path = os.path.dirname(os.path.abspath(__file__))
-
-os.chdir(base_path) # Change the current working directory to the base path
-
-instrumentalModels_dir = os.path.join(base_path, 'models')
-banner_path = os.path.join(base_path, 'img', 'UVR-banner.png')
-efile_path = os.path.join(base_path, 'img', 'file.png')
-DEFAULT_DATA = {
- 'exportPath': '',
- 'inputPaths': [],
- 'gpu': False,
- 'postprocess': False,
- 'tta': False,
- 'save': True,
- 'output_image': False,
- 'window_size': '512',
- 'agg': 10,
- 'modelFolder': False,
- 'modelInstrumentalLabel': '',
- 'aiModel': 'Single Model',
- 'ensChoose': 'HP1 Models',
- 'useModel': 'instrumental',
- 'lastDir': None,
-}
-
-def open_image(path: str, size: tuple = None, keep_aspect: bool = True, rotate: int = 0) -> ImageTk.PhotoImage:
- """
- Open the image on the path and apply given settings\n
- Paramaters:
- path(str):
- Absolute path of the image
- size(tuple):
- first value - width
- second value - height
- keep_aspect(bool):
- keep aspect ratio of image and resize
- to maximum possible width and height
- (maxima are given by size)
- rotate(int):
- clockwise rotation of image
- Returns(ImageTk.PhotoImage):
- Image of path
- """
- img = Image.open(path).convert(mode='RGBA')
- ratio = img.height/img.width
- img = img.rotate(angle=-rotate)
- if size is not None:
- size = (int(size[0]), int(size[1]))
- if keep_aspect:
- img = img.resize((size[0], int(size[0] * ratio)), Image.ANTIALIAS)
- else:
- img = img.resize(size, Image.ANTIALIAS)
- return ImageTk.PhotoImage(img)
-
-def save_data(data):
- """
- Saves given data as a .pkl (pickle) file
-
- Paramters:
- data(dict):
- Dictionary containing all the necessary data to save
- """
- # Open data file, create it if it does not exist
- with open('data.pkl', 'wb') as data_file:
- pickle.dump(data, data_file)
-
-def load_data() -> dict:
- """
- Loads saved pkl file and returns the stored data
-
- Returns(dict):
- Dictionary containing all the saved data
- """
- try:
- with open('data.pkl', 'rb') as data_file: # Open data file
- data = pickle.load(data_file)
-
- return data
- except (ValueError, FileNotFoundError):
- # Data File is corrupted or not found so recreate it
- save_data(data=DEFAULT_DATA)
-
- return load_data()
-
-def drop(event, accept_mode: str = 'files'):
- """
- Drag & Drop verification process
- """
- path = event.data
-
- if accept_mode == 'folder':
- path = path.replace('{', '').replace('}', '')
- if not os.path.isdir(path):
- tk.messagebox.showerror(title='Invalid Folder',
- message='Your given export path is not a valid folder!')
- return
- # Set Variables
- root.exportPath_var.set(path)
- elif accept_mode == 'files':
- # Clean path text and set path to the list of paths
- path = path.replace('{', '')
- path = path.split('} ')
- path[-1] = path[-1].replace('}', '')
- # Set Variables
- root.inputPaths = path
- root.update_inputPaths()
- else:
- # Invalid accept mode
- return
-
-class ThreadSafeConsole(tk.Text):
- """
- Text Widget which is thread safe for tkinter
- """
- def __init__(self, master, **options):
- tk.Text.__init__(self, master, **options)
- self.queue = queue.Queue()
- self.update_me()
-
- def write(self, line):
- self.queue.put(line)
-
- def clear(self):
- self.queue.put(None)
-
- def update_me(self):
- self.configure(state=tk.NORMAL)
- try:
- while 1:
- line = self.queue.get_nowait()
- if line is None:
- self.delete(1.0, tk.END)
- else:
- self.insert(tk.END, str(line))
- self.see(tk.END)
- self.update_idletasks()
- except queue.Empty:
- pass
- self.configure(state=tk.DISABLED)
- self.after(100, self.update_me)
-
-class MainWindow(TkinterDnD.Tk):
- # --Constants--
- # Layout
- IMAGE_HEIGHT = 140
- FILEPATHS_HEIGHT = 80
- OPTIONS_HEIGHT = 190
- CONVERSIONBUTTON_HEIGHT = 35
- COMMAND_HEIGHT = 200
- PROGRESS_HEIGHT = 26
- PADDING = 10
-
- COL1_ROWS = 6
- COL2_ROWS = 6
- COL3_ROWS = 6
-
- def __init__(self):
- # Run the __init__ method on the tk.Tk class
- super().__init__()
- # Calculate window height
- height = self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT
- height += self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PROGRESS_HEIGHT
- height += self.PADDING * 5 # Padding
-
- # --Window Settings--
- self.title('Vocal Remover')
- # Set Geometry and Center Window
- self.geometry('{width}x{height}+{xpad}+{ypad}'.format(
- width=620,
- height=height,
- xpad=int(self.winfo_screenwidth()/2 - 550/2),
- ypad=int(self.winfo_screenheight()/2 - height/2 - 30)))
- self.configure(bg='#000000') # Set background color to black
- self.protocol("WM_DELETE_WINDOW", self.save_values)
- self.resizable(False, False)
- self.update()
-
- # --Variables--
- self.logo_img = open_image(path=banner_path,
- size=(self.winfo_width(), 9999))
- self.efile_img = open_image(path=efile_path,
- size=(20, 20))
- self.instrumentalLabel_to_path = defaultdict(lambda: '')
- self.lastInstrumentalModels = []
- # -Tkinter Value Holders-
- data = load_data()
- # Paths
- self.exportPath_var = tk.StringVar(value=data['exportPath'])
- self.inputPaths = data['inputPaths']
- # Processing Options
- self.gpuConversion_var = tk.BooleanVar(value=data['gpu'])
- self.postprocessing_var = tk.BooleanVar(value=data['postprocess'])
- self.tta_var = tk.BooleanVar(value=data['tta'])
- self.save_var = tk.BooleanVar(value=data['save'])
- self.outputImage_var = tk.BooleanVar(value=data['output_image'])
- # Models
- self.instrumentalModel_var = tk.StringVar(value=data['modelInstrumentalLabel'])
- # Model Test Mode
- self.modelFolder_var = tk.BooleanVar(value=data['modelFolder'])
- # Constants
- self.winSize_var = tk.StringVar(value=data['window_size'])
- self.agg_var = tk.StringVar(value=data['agg'])
- # Choose Conversion Method
- self.aiModel_var = tk.StringVar(value=data['aiModel'])
- self.last_aiModel = self.aiModel_var.get()
- # Choose Ensemble
- self.ensChoose_var = tk.StringVar(value=data['ensChoose'])
- self.last_ensChoose = self.ensChoose_var.get()
- # Other
- self.inputPathsEntry_var = tk.StringVar(value='')
- self.lastDir = data['lastDir'] # nopep8
- self.progress_var = tk.IntVar(value=0)
- # Font
- self.font = tk.font.Font(family='Microsoft JhengHei', size=9, weight='bold')
- # --Widgets--
- self.create_widgets()
- self.configure_widgets()
- self.bind_widgets()
- self.place_widgets()
- self.update_available_models()
- self.update_states()
- self.update_loop()
-
- # -Widget Methods-
- def create_widgets(self):
- """Create window widgets"""
- self.title_Label = tk.Label(master=self, bg='black',
- image=self.logo_img, compound=tk.TOP)
- self.filePaths_Frame = tk.Frame(master=self, bg='black')
- self.fill_filePaths_Frame()
-
- self.options_Frame = tk.Frame(master=self, bg='black')
- self.fill_options_Frame()
-
- self.conversion_Button = ttk.Button(master=self,
- text='Start Conversion',
- command=self.start_conversion)
- self.efile_Button = ttk.Button(master=self,
- image=self.efile_img,
- command=self.open_newModel_filedialog)
-
- self.progressbar = ttk.Progressbar(master=self,
- variable=self.progress_var)
-
- self.command_Text = ThreadSafeConsole(master=self,
- background='#a0a0a0',
- borderwidth=0,)
- self.command_Text.write(f'COMMAND LINE [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]') # nopep8
-
- def configure_widgets(self):
- """Change widget styling and appearance"""
-
- ttk.Style().configure('TCheckbutton', background='black',
- font=self.font, foreground='white')
- ttk.Style().configure('TRadiobutton', background='black',
- font=self.font, foreground='white')
- ttk.Style().configure('T', font=self.font, foreground='white')
-
- def bind_widgets(self):
- """Bind widgets to the drag & drop mechanic"""
- self.filePaths_saveTo_Button.drop_target_register(DND_FILES)
- self.filePaths_saveTo_Entry.drop_target_register(DND_FILES)
- self.filePaths_musicFile_Button.drop_target_register(DND_FILES)
- self.filePaths_musicFile_Entry.drop_target_register(DND_FILES)
- self.filePaths_saveTo_Button.dnd_bind('<>',
- lambda e: drop(e, accept_mode='folder'))
- self.filePaths_saveTo_Entry.dnd_bind('<>',
- lambda e: drop(e, accept_mode='folder'))
- self.filePaths_musicFile_Button.dnd_bind('<>',
- lambda e: drop(e, accept_mode='files'))
- self.filePaths_musicFile_Entry.dnd_bind('<>',
- lambda e: drop(e, accept_mode='files'))
-
- def place_widgets(self):
- """Place main widgets"""
- self.title_Label.place(x=-2, y=-2)
- self.filePaths_Frame.place(x=10, y=155, width=-20, height=self.FILEPATHS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.options_Frame.place(x=25, y=250, width=-50, height=self.OPTIONS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.conversion_Button.place(x=10, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=-20 - 40, height=self.CONVERSIONBUTTON_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.efile_Button.place(x=-10 - 35, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.PADDING*2, width=35, height=self.CONVERSIONBUTTON_HEIGHT,
- relx=1, rely=0, relwidth=0, relheight=0)
- self.command_Text.place(x=15, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.PADDING*3, width=-30, height=self.COMMAND_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
- self.progressbar.place(x=25, y=self.IMAGE_HEIGHT + self.FILEPATHS_HEIGHT + self.OPTIONS_HEIGHT + self.CONVERSIONBUTTON_HEIGHT + self.COMMAND_HEIGHT + self.PADDING*4, width=-50, height=self.PROGRESS_HEIGHT,
- relx=0, rely=0, relwidth=1, relheight=0)
-
- def fill_filePaths_Frame(self):
- """Fill Frame with neccessary widgets"""
- # -Create Widgets-
- # Save To Option
- self.filePaths_saveTo_Button = ttk.Button(master=self.filePaths_Frame,
- text='Save to',
- command=self.open_export_filedialog)
- self.filePaths_saveTo_Entry = ttk.Entry(master=self.filePaths_Frame,
-
- textvariable=self.exportPath_var,
- state=tk.DISABLED
- )
- # Select Music Files Option
- self.filePaths_musicFile_Button = ttk.Button(master=self.filePaths_Frame,
- text='Select Your Audio File(s)',
- command=self.open_file_filedialog)
- self.filePaths_musicFile_Entry = ttk.Entry(master=self.filePaths_Frame,
- textvariable=self.inputPathsEntry_var,
- state=tk.DISABLED
- )
- # -Place Widgets-
- # Save To Option
- self.filePaths_saveTo_Button.place(x=0, y=5, width=0, height=-10,
- relx=0, rely=0, relwidth=0.3, relheight=0.5)
- self.filePaths_saveTo_Entry.place(x=10, y=7, width=-20, height=-14,
- relx=0.3, rely=0, relwidth=0.7, relheight=0.5)
- # Select Music Files Option
- self.filePaths_musicFile_Button.place(x=0, y=5, width=0, height=-10,
- relx=0, rely=0.5, relwidth=0.4, relheight=0.5)
- self.filePaths_musicFile_Entry.place(x=10, y=7, width=-20, height=-14,
- relx=0.4, rely=0.5, relwidth=0.6, relheight=0.5)
-
- def fill_options_Frame(self):
- """Fill Frame with neccessary widgets"""
- # -Create Widgets-
- # -Column 1-
- # GPU Selection
- self.options_gpu_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='GPU Conversion',
- variable=self.gpuConversion_var,
- )
- # Postprocessing
- self.options_post_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Post-Process',
- variable=self.postprocessing_var,
- )
- # TTA
- self.options_tta_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='TTA',
- variable=self.tta_var,
- )
- # Save Ensemble Outputs
- self.options_save_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Save All Outputs',
- variable=self.save_var,
- )
- # Save Image
- self.options_image_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Output Image',
- variable=self.outputImage_var,
- )
-
- # Model Test Mode
- self.options_modelFolder_Checkbutton = ttk.Checkbutton(master=self.options_Frame,
- text='Model Test Mode',
- variable=self.modelFolder_var,
- )
- # -Column 2-
-
- # Choose Conversion Method
- self.options_aiModel_Label = tk.Label(master=self.options_Frame,
- text='Choose Conversion Method', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_aiModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.aiModel_var,
- None, 'Single Model', 'Ensemble Mode')
- # Ensemble Mode
- self.options_ensChoose_Label = tk.Label(master=self.options_Frame,
- text='Choose Ensemble', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_ensChoose_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.ensChoose_var,
- None, 'HP1 Models', 'HP2 Models', 'All HP Models', 'Vocal Models')
- # -Column 3-
-
- # WINDOW SIZE
- self.options_winSize_Label = tk.Label(master=self.options_Frame,
- text='Window Size', anchor=tk.CENTER,
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_winSize_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.winSize_var,
- None, '320', '512','1024')
-
- # AGG
- self.options_agg_Entry = ttk.Entry(master=self.options_Frame,
- textvariable=self.agg_var, justify='center')
- self.options_agg_Label = tk.Label(master=self.options_Frame,
- text='Aggression Setting',
- background='#404040', font=self.font, foreground='white', relief="groove")
-
- # "Save to", "Select Your Audio File(s)"", and "Start Conversion" Button Style
- s = ttk.Style()
- s.configure('TButton', background='blue', foreground='black', font=('Microsoft JhengHei', '9', 'bold'), relief="groove")
-
- # -Column 3-
- # Choose Instrumental Model
- self.options_instrumentalModel_Label = tk.Label(master=self.options_Frame,
- text='Choose Main Model',
- background='#404040', font=self.font, foreground='white', relief="groove")
- self.options_instrumentalModel_Optionmenu = ttk.OptionMenu(self.options_Frame,
- self.instrumentalModel_var)
-
- # -Place Widgets-
-
- # -Column 1-
- self.options_gpu_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=0, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_post_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=1/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_tta_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=2/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_image_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=3/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
-
- # -Column 2-
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=2/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
-
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=1/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- # Conversion Method
- self.options_aiModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=0/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_aiModel_Optionmenu.place(x=-15, y=4, width=0, height=-10,
- relx=1/3, rely=1/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- # -Column 3-
-
- # WINDOW
- self.options_winSize_Label.place(x=35, y=6, width=-40, height=-10,
- relx=2/3, rely=0, relwidth=1/3, relheight=1/self.COL3_ROWS)
- self.options_winSize_Optionmenu.place(x=80, y=6, width=-133, height=-10,
- relx=2/3, rely=1/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
-
- # AGG
- self.options_agg_Label.place(x=35, y=6, width=-40, height=-10,
- relx=2/3, rely=2/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
- self.options_agg_Entry.place(x=80, y=6, width=-133, height=-10,
- relx=2/3, rely=3/self.COL3_ROWS, relwidth=1/3, relheight=1/self.COL3_ROWS)
-
- # Model deselect
- self.aiModel_var.trace_add('write',
- lambda *args: self.deselect_models())
-
- # Opening filedialogs
- def open_file_filedialog(self):
- """Make user select music files"""
- if self.lastDir is not None:
- if not os.path.isdir(self.lastDir):
- self.lastDir = None
-
- paths = tk.filedialog.askopenfilenames(
- parent=self,
- title=f'Select Music Files',
- initialfile='',
- initialdir=self.lastDir,
- )
- if paths: # Path selected
- self.inputPaths = paths
- self.update_inputPaths()
- self.lastDir = os.path.dirname(paths[0])
-
- def open_export_filedialog(self):
- """Make user select a folder to export the converted files in"""
- path = tk.filedialog.askdirectory(
- parent=self,
- title=f'Select Folder',)
- if path: # Path selected
- self.exportPath_var.set(path)
-
- def open_newModel_filedialog(self):
- """Let user paste a ".pth" model to use for the vocal seperation"""
- filename = self.exportPath_var.get()
-
- if sys.platform == "win32":
- os.startfile(filename)
- else:
- opener = "open" if sys.platform == "darwin" else "xdg-open"
- subprocess.call([opener, filename])
-
- def start_conversion(self):
- """
- Start the conversion for all the given mp3 and wav files
- """
- # -Get all variables-
- export_path = self.exportPath_var.get()
- input_paths = self.inputPaths
- instrumentalModel_path = self.instrumentalLabel_to_path[self.instrumentalModel_var.get()] # nopep8
- # Get constants
- instrumental = self.instrumentalModel_var.get()
- try:
- if [bool(instrumental)].count(True) == 2: #CHECKTHIS
- window_size = DEFAULT_DATA['window_size']
- agg = DEFAULT_DATA['agg']
- else:
- window_size = int(self.winSize_var.get())
- agg = int(self.agg_var.get())
- ensChoose = str(self.ensChoose_var.get())
- except ValueError: # Non integer was put in entry box
- tk.messagebox.showwarning(master=self,
- title='Invalid Input',
- message='Please make sure you only input integer numbers!')
- return
- except SyntaxError: # Non integer was put in entry box
- tk.messagebox.showwarning(master=self,
- title='Invalid Music File',
- message='You have selected an invalid music file!\nPlease make sure that your files still exist and ends with either ".mp3", ".mp4", ".m4a", ".flac", ".wav"')
- return
-
- # -Check for invalid inputs-
- for path in input_paths:
- if not os.path.isfile(path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Music File',
- message='You have selected an invalid music file! Please make sure that the file still exists!',
- detail=f'File path: {path}')
- return
- if self.aiModel_var.get() == 'Single Model':
- if not os.path.isfile(instrumentalModel_path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Main Model File',
- message='You have selected an invalid main model file!\nPlease make sure that your model file still exists!')
- return
-
- if not os.path.isdir(export_path):
- tk.messagebox.showwarning(master=self,
- title='Invalid Export Directory',
- message='You have selected an invalid export directory!\nPlease make sure that your directory still exists!')
- return
-
- if self.aiModel_var.get() == 'Single Model':
- inference = inference_v5
- elif self.aiModel_var.get() == 'Ensemble Mode':
- inference = inference_v5_ensemble
- else:
- raise TypeError('This error should not occur.')
-
- # -Run the algorithm-
- threading.Thread(target=inference.main,
- kwargs={
- # Paths
- 'input_paths': input_paths,
- 'export_path': export_path,
- # Processing Options
- 'gpu': 0 if self.gpuConversion_var.get() else -1,
- 'postprocess': self.postprocessing_var.get(),
- 'tta': self.tta_var.get(),
- 'save': self.save_var.get(),
- 'output_image': self.outputImage_var.get(),
- # Models
- 'instrumentalModel': instrumentalModel_path,
- 'vocalModel': '', # Always not needed
- 'useModel': 'instrumental', # Always instrumental
- # Model Folder
- 'modelFolder': self.modelFolder_var.get(),
- # Constants
- 'window_size': window_size,
- 'agg': agg,
- 'ensChoose': ensChoose,
- # Other Variables (Tkinter)
- 'window': self,
- 'text_widget': self.command_Text,
- 'button_widget': self.conversion_Button,
- 'inst_menu': self.options_instrumentalModel_Optionmenu,
- 'progress_var': self.progress_var,
- },
- daemon=True
- ).start()
-
- # Models
- def update_inputPaths(self):
- """Update the music file entry"""
- if self.inputPaths:
- # Non-empty Selection
- text = '; '.join(self.inputPaths)
- else:
- # Empty Selection
- text = ''
- self.inputPathsEntry_var.set(text)
-
- def update_loop(self):
- """Update the dropdown menu"""
- self.update_available_models()
-
- self.after(3000, self.update_loop)
-
- def update_available_models(self):
- """
- Loop through every model (.pth) in the models directory
- and add to the select your model list
- """
- #temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, self.aiModel_var.get(), 'Main Models') # nopep8
- temp_instrumentalModels_dir = os.path.join(instrumentalModels_dir, 'Main Models') # nopep8
-
- # Main models
- new_InstrumentalModels = os.listdir(temp_instrumentalModels_dir)
- if new_InstrumentalModels != self.lastInstrumentalModels:
- self.instrumentalLabel_to_path.clear()
- self.options_instrumentalModel_Optionmenu['menu'].delete(0, 'end')
- for file_name in new_InstrumentalModels:
- if file_name.endswith('.pth'):
- # Add Radiobutton to the Options Menu
- self.options_instrumentalModel_Optionmenu['menu'].add_radiobutton(label=file_name,
- command=tk._setit(self.instrumentalModel_var, file_name))
- # Link the files name to its absolute path
- self.instrumentalLabel_to_path[file_name] = os.path.join(temp_instrumentalModels_dir, file_name) # nopep8
- self.lastInstrumentalModels = new_InstrumentalModels
-
- def update_states(self):
- """
- Vary the states for all widgets based
- on certain selections
- """
- if self.aiModel_var.get() == 'Single Model':
- self.options_ensChoose_Label.place_forget()
- self.options_ensChoose_Optionmenu.place_forget()
- self.options_save_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- else:
- self.options_instrumentalModel_Label.place_forget()
- self.options_instrumentalModel_Optionmenu.place_forget()
- self.options_modelFolder_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.configure(state=tk.NORMAL)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
- if self.aiModel_var.get() == 'Ensemble Mode':
- self.options_instrumentalModel_Label.place_forget()
- self.options_instrumentalModel_Optionmenu.place_forget()
- self.options_modelFolder_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.configure(state=tk.NORMAL)
- self.options_save_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_ensChoose_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_ensChoose_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- else:
- self.options_ensChoose_Label.place_forget()
- self.options_ensChoose_Optionmenu.place_forget()
- self.options_save_Checkbutton.configure(state=tk.DISABLED)
- self.options_save_Checkbutton.place_forget()
- self.options_modelFolder_Checkbutton.configure(state=tk.NORMAL)
- self.options_modelFolder_Checkbutton.place(x=0, y=0, width=0, height=0,
- relx=0, rely=4/self.COL1_ROWS, relwidth=1/3, relheight=1/self.COL1_ROWS)
- self.options_instrumentalModel_Label.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=3/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
- self.options_instrumentalModel_Optionmenu.place(x=-15, y=6, width=0, height=-10,
- relx=1/3, rely=4/self.COL2_ROWS, relwidth=1/3, relheight=1/self.COL2_ROWS)
-
-
- self.update_inputPaths()
-
- def deselect_models(self):
- """
- Run this method on version change
- """
- if self.aiModel_var.get() == self.last_aiModel:
- return
- else:
- self.last_aiModel = self.aiModel_var.get()
-
- self.instrumentalModel_var.set('')
- self.ensChoose_var.set('HP1 Models')
-
- self.winSize_var.set(DEFAULT_DATA['window_size'])
- self.agg_var.set(DEFAULT_DATA['agg'])
- self.modelFolder_var.set(DEFAULT_DATA['modelFolder'])
-
-
- self.update_available_models()
- self.update_states()
-
- # def restart(self):
- # """
- # Restart the application after asking for confirmation
- # """
- # save = tk.messagebox.askyesno(title='Confirmation',
- # message='The application will restart. Do you want to save the data?')
- # if save:
- # self.save_values()
- # subprocess.Popen(f'..App\Python\python.exe "{__file__}"')
- # exit()
-
- def save_values(self):
- """
- Save the data of the application
- """
- # Get constants
- instrumental = self.instrumentalModel_var.get()
- if [bool(instrumental)].count(True) == 2: #Checkthis
- window_size = DEFAULT_DATA['window_size']
- agg = DEFAULT_DATA['agg']
- else:
- window_size = self.winSize_var.get()
- agg = self.agg_var.get()
-
- # -Save Data-
- save_data(data={
- 'exportPath': self.exportPath_var.get(),
- 'inputPaths': self.inputPaths,
- 'gpu': self.gpuConversion_var.get(),
- 'postprocess': self.postprocessing_var.get(),
- 'tta': self.tta_var.get(),
- 'save': self.save_var.get(),
- 'output_image': self.outputImage_var.get(),
- 'window_size': window_size,
- 'agg': agg,
- 'useModel': 'instrumental',
- 'lastDir': self.lastDir,
- 'modelFolder': self.modelFolder_var.get(),
- 'modelInstrumentalLabel': self.instrumentalModel_var.get(),
- 'aiModel': self.aiModel_var.get(),
- 'ensChoose': self.ensChoose_var.get(),
- })
-
- self.destroy()
-
-if __name__ == "__main__":
- root = MainWindow()
-
- root.mainloop()
diff --git a/demucs/__init__.py b/demucs/__init__.py
new file mode 100644
index 0000000..d4182e3
--- /dev/null
+++ b/demucs/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+__version__ = "2.0.3"
diff --git a/demucs/__main__.py b/demucs/__main__.py
new file mode 100644
index 0000000..5148f20
--- /dev/null
+++ b/demucs/__main__.py
@@ -0,0 +1,317 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import json
+import math
+import os
+import sys
+import time
+from dataclasses import dataclass, field
+
+import torch as th
+from torch import distributed, nn
+from torch.nn.parallel.distributed import DistributedDataParallel
+
+from .augment import FlipChannels, FlipSign, Remix, Scale, Shift
+from .compressed import get_compressed_datasets
+from .model import Demucs
+from .parser import get_name, get_parser
+from .raw import Rawset
+from .repitch import RepitchedWrapper
+from .pretrained import load_pretrained, SOURCES
+from .tasnet import ConvTasNet
+from .test import evaluate
+from .train import train_model, validate_model
+from .utils import (human_seconds, load_model, save_model, get_state,
+ save_state, sizeof_fmt, get_quantizer)
+from .wav import get_wav_datasets, get_musdb_wav_datasets
+
+
+@dataclass
+class SavedState:
+ metrics: list = field(default_factory=list)
+ last_state: dict = None
+ best_state: dict = None
+ optimizer: dict = None
+
+
+def main():
+ parser = get_parser()
+ args = parser.parse_args()
+ name = get_name(parser, args)
+ print(f"Experiment {name}")
+
+ if args.musdb is None and args.rank == 0:
+ print(
+ "You must provide the path to the MusDB dataset with the --musdb flag. "
+ "To download the MusDB dataset, see https://sigsep.github.io/datasets/musdb.html.",
+ file=sys.stderr)
+ sys.exit(1)
+
+ eval_folder = args.evals / name
+ eval_folder.mkdir(exist_ok=True, parents=True)
+ args.logs.mkdir(exist_ok=True)
+ metrics_path = args.logs / f"{name}.json"
+ eval_folder.mkdir(exist_ok=True, parents=True)
+ args.checkpoints.mkdir(exist_ok=True, parents=True)
+ args.models.mkdir(exist_ok=True, parents=True)
+
+ if args.device is None:
+ device = "cpu"
+ if th.cuda.is_available():
+ device = "cuda"
+ else:
+ device = args.device
+
+ th.manual_seed(args.seed)
+ # Prevents too many threads to be started when running `museval` as it can be quite
+ # inefficient on NUMA architectures.
+ os.environ["OMP_NUM_THREADS"] = "1"
+ os.environ["MKL_NUM_THREADS"] = "1"
+
+ if args.world_size > 1:
+ if device != "cuda" and args.rank == 0:
+ print("Error: distributed training is only available with cuda device", file=sys.stderr)
+ sys.exit(1)
+ th.cuda.set_device(args.rank % th.cuda.device_count())
+ distributed.init_process_group(backend="nccl",
+ init_method="tcp://" + args.master,
+ rank=args.rank,
+ world_size=args.world_size)
+
+ checkpoint = args.checkpoints / f"{name}.th"
+ checkpoint_tmp = args.checkpoints / f"{name}.th.tmp"
+ if args.restart and checkpoint.exists() and args.rank == 0:
+ checkpoint.unlink()
+
+ if args.test or args.test_pretrained:
+ args.epochs = 1
+ args.repeat = 0
+ if args.test:
+ model = load_model(args.models / args.test)
+ else:
+ model = load_pretrained(args.test_pretrained)
+ elif args.tasnet:
+ model = ConvTasNet(audio_channels=args.audio_channels,
+ samplerate=args.samplerate, X=args.X,
+ segment_length=4 * args.samples,
+ sources=SOURCES)
+ else:
+ model = Demucs(
+ audio_channels=args.audio_channels,
+ channels=args.channels,
+ context=args.context,
+ depth=args.depth,
+ glu=args.glu,
+ growth=args.growth,
+ kernel_size=args.kernel_size,
+ lstm_layers=args.lstm_layers,
+ rescale=args.rescale,
+ rewrite=args.rewrite,
+ stride=args.conv_stride,
+ resample=args.resample,
+ normalize=args.normalize,
+ samplerate=args.samplerate,
+ segment_length=4 * args.samples,
+ sources=SOURCES,
+ )
+ model.to(device)
+ if args.init:
+ model.load_state_dict(load_pretrained(args.init).state_dict())
+
+ if args.show:
+ print(model)
+ size = sizeof_fmt(4 * sum(p.numel() for p in model.parameters()))
+ print(f"Model size {size}")
+ return
+
+ try:
+ saved = th.load(checkpoint, map_location='cpu')
+ except IOError:
+ saved = SavedState()
+
+ optimizer = th.optim.Adam(model.parameters(), lr=args.lr)
+
+ quantizer = None
+ quantizer = get_quantizer(model, args, optimizer)
+
+ if saved.last_state is not None:
+ model.load_state_dict(saved.last_state, strict=False)
+ if saved.optimizer is not None:
+ optimizer.load_state_dict(saved.optimizer)
+
+ model_name = f"{name}.th"
+ if args.save_model:
+ if args.rank == 0:
+ model.to("cpu")
+ model.load_state_dict(saved.best_state)
+ save_model(model, quantizer, args, args.models / model_name)
+ return
+ elif args.save_state:
+ model_name = f"{args.save_state}.th"
+ if args.rank == 0:
+ model.to("cpu")
+ model.load_state_dict(saved.best_state)
+ state = get_state(model, quantizer)
+ save_state(state, args.models / model_name)
+ return
+
+ if args.rank == 0:
+ done = args.logs / f"{name}.done"
+ if done.exists():
+ done.unlink()
+
+ augment = [Shift(args.data_stride)]
+ if args.augment:
+ augment += [FlipSign(), FlipChannels(), Scale(),
+ Remix(group_size=args.remix_group_size)]
+ augment = nn.Sequential(*augment).to(device)
+ print("Agumentation pipeline:", augment)
+
+ if args.mse:
+ criterion = nn.MSELoss()
+ else:
+ criterion = nn.L1Loss()
+
+ # Setting number of samples so that all convolution windows are full.
+ # Prevents hard to debug mistake with the prediction being shifted compared
+ # to the input mixture.
+ samples = model.valid_length(args.samples)
+ print(f"Number of training samples adjusted to {samples}")
+ samples = samples + args.data_stride
+ if args.repitch:
+ # We need a bit more audio samples, to account for potential
+ # tempo change.
+ samples = math.ceil(samples / (1 - 0.01 * args.max_tempo))
+
+ args.metadata.mkdir(exist_ok=True, parents=True)
+ if args.raw:
+ train_set = Rawset(args.raw / "train",
+ samples=samples,
+ channels=args.audio_channels,
+ streams=range(1, len(model.sources) + 1),
+ stride=args.data_stride)
+
+ valid_set = Rawset(args.raw / "valid", channels=args.audio_channels)
+ elif args.wav:
+ train_set, valid_set = get_wav_datasets(args, samples, model.sources)
+ elif args.is_wav:
+ train_set, valid_set = get_musdb_wav_datasets(args, samples, model.sources)
+ else:
+ train_set, valid_set = get_compressed_datasets(args, samples)
+
+ if args.repitch:
+ train_set = RepitchedWrapper(
+ train_set,
+ proba=args.repitch,
+ max_tempo=args.max_tempo)
+
+ best_loss = float("inf")
+ for epoch, metrics in enumerate(saved.metrics):
+ print(f"Epoch {epoch:03d}: "
+ f"train={metrics['train']:.8f} "
+ f"valid={metrics['valid']:.8f} "
+ f"best={metrics['best']:.4f} "
+ f"ms={metrics.get('true_model_size', 0):.2f}MB "
+ f"cms={metrics.get('compressed_model_size', 0):.2f}MB "
+ f"duration={human_seconds(metrics['duration'])}")
+ best_loss = metrics['best']
+
+ if args.world_size > 1:
+ dmodel = DistributedDataParallel(model,
+ device_ids=[th.cuda.current_device()],
+ output_device=th.cuda.current_device())
+ else:
+ dmodel = model
+
+ for epoch in range(len(saved.metrics), args.epochs):
+ begin = time.time()
+ model.train()
+ train_loss, model_size = train_model(
+ epoch, train_set, dmodel, criterion, optimizer, augment,
+ quantizer=quantizer,
+ batch_size=args.batch_size,
+ device=device,
+ repeat=args.repeat,
+ seed=args.seed,
+ diffq=args.diffq,
+ workers=args.workers,
+ world_size=args.world_size)
+ model.eval()
+ valid_loss = validate_model(
+ epoch, valid_set, model, criterion,
+ device=device,
+ rank=args.rank,
+ split=args.split_valid,
+ overlap=args.overlap,
+ world_size=args.world_size)
+
+ ms = 0
+ cms = 0
+ if quantizer and args.rank == 0:
+ ms = quantizer.true_model_size()
+ cms = quantizer.compressed_model_size(num_workers=min(40, args.world_size * 10))
+
+ duration = time.time() - begin
+ if valid_loss < best_loss and ms <= args.ms_target:
+ best_loss = valid_loss
+ saved.best_state = {
+ key: value.to("cpu").clone()
+ for key, value in model.state_dict().items()
+ }
+
+ saved.metrics.append({
+ "train": train_loss,
+ "valid": valid_loss,
+ "best": best_loss,
+ "duration": duration,
+ "model_size": model_size,
+ "true_model_size": ms,
+ "compressed_model_size": cms,
+ })
+ if args.rank == 0:
+ json.dump(saved.metrics, open(metrics_path, "w"))
+
+ saved.last_state = model.state_dict()
+ saved.optimizer = optimizer.state_dict()
+ if args.rank == 0 and not args.test:
+ th.save(saved, checkpoint_tmp)
+ checkpoint_tmp.rename(checkpoint)
+
+ print(f"Epoch {epoch:03d}: "
+ f"train={train_loss:.8f} valid={valid_loss:.8f} best={best_loss:.4f} ms={ms:.2f}MB "
+ f"cms={cms:.2f}MB "
+ f"duration={human_seconds(duration)}")
+
+ if args.world_size > 1:
+ distributed.barrier()
+
+ del dmodel
+ model.load_state_dict(saved.best_state)
+ if args.eval_cpu:
+ device = "cpu"
+ model.to(device)
+ model.eval()
+ evaluate(model, args.musdb, eval_folder,
+ is_wav=args.is_wav,
+ rank=args.rank,
+ world_size=args.world_size,
+ device=device,
+ save=args.save,
+ split=args.split_valid,
+ shifts=args.shifts,
+ overlap=args.overlap,
+ workers=args.eval_workers)
+ model.to("cpu")
+ if args.rank == 0:
+ if not (args.test or args.test_pretrained):
+ save_model(model, quantizer, args, args.models / model_name)
+ print("done")
+ done.write_text("done")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/audio.py b/demucs/audio.py
new file mode 100644
index 0000000..b29f156
--- /dev/null
+++ b/demucs/audio.py
@@ -0,0 +1,172 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+import json
+import subprocess as sp
+from pathlib import Path
+
+import julius
+import numpy as np
+import torch
+
+from .utils import temp_filenames
+
+
+def _read_info(path):
+ stdout_data = sp.check_output([
+ 'ffprobe', "-loglevel", "panic",
+ str(path), '-print_format', 'json', '-show_format', '-show_streams'
+ ])
+ return json.loads(stdout_data.decode('utf-8'))
+
+
+class AudioFile:
+ """
+ Allows to read audio from any format supported by ffmpeg, as well as resampling or
+ converting to mono on the fly. See :method:`read` for more details.
+ """
+ def __init__(self, path: Path):
+ self.path = Path(path)
+ self._info = None
+
+ def __repr__(self):
+ features = [("path", self.path)]
+ features.append(("samplerate", self.samplerate()))
+ features.append(("channels", self.channels()))
+ features.append(("streams", len(self)))
+ features_str = ", ".join(f"{name}={value}" for name, value in features)
+ return f"AudioFile({features_str})"
+
+ @property
+ def info(self):
+ if self._info is None:
+ self._info = _read_info(self.path)
+ return self._info
+
+ @property
+ def duration(self):
+ return float(self.info['format']['duration'])
+
+ @property
+ def _audio_streams(self):
+ return [
+ index for index, stream in enumerate(self.info["streams"])
+ if stream["codec_type"] == "audio"
+ ]
+
+ def __len__(self):
+ return len(self._audio_streams)
+
+ def channels(self, stream=0):
+ return int(self.info['streams'][self._audio_streams[stream]]['channels'])
+
+ def samplerate(self, stream=0):
+ return int(self.info['streams'][self._audio_streams[stream]]['sample_rate'])
+
+ def read(self,
+ seek_time=None,
+ duration=None,
+ streams=slice(None),
+ samplerate=None,
+ channels=None,
+ temp_folder=None):
+ """
+ Slightly more efficient implementation than stempeg,
+ in particular, this will extract all stems at once
+ rather than having to loop over one file multiple times
+ for each stream.
+
+ Args:
+ seek_time (float): seek time in seconds or None if no seeking is needed.
+ duration (float): duration in seconds to extract or None to extract until the end.
+ streams (slice, int or list): streams to extract, can be a single int, a list or
+ a slice. If it is a slice or list, the output will be of size [S, C, T]
+ with S the number of streams, C the number of channels and T the number of samples.
+ If it is an int, the output will be [C, T].
+ samplerate (int): if provided, will resample on the fly. If None, no resampling will
+ be done. Original sampling rate can be obtained with :method:`samplerate`.
+ channels (int): if 1, will convert to mono. We do not rely on ffmpeg for that
+ as ffmpeg automatically scale by +3dB to conserve volume when playing on speakers.
+ See https://sound.stackexchange.com/a/42710.
+ Our definition of mono is simply the average of the two channels. Any other
+ value will be ignored.
+ temp_folder (str or Path or None): temporary folder to use for decoding.
+
+
+ """
+ streams = np.array(range(len(self)))[streams]
+ single = not isinstance(streams, np.ndarray)
+ if single:
+ streams = [streams]
+
+ if duration is None:
+ target_size = None
+ query_duration = None
+ else:
+ target_size = int((samplerate or self.samplerate()) * duration)
+ query_duration = float((target_size + 1) / (samplerate or self.samplerate()))
+
+ with temp_filenames(len(streams)) as filenames:
+ command = ['ffmpeg', '-y']
+ command += ['-loglevel', 'panic']
+ if seek_time:
+ command += ['-ss', str(seek_time)]
+ command += ['-i', str(self.path)]
+ for stream, filename in zip(streams, filenames):
+ command += ['-map', f'0:{self._audio_streams[stream]}']
+ if query_duration is not None:
+ command += ['-t', str(query_duration)]
+ command += ['-threads', '1']
+ command += ['-f', 'f32le']
+ if samplerate is not None:
+ command += ['-ar', str(samplerate)]
+ command += [filename]
+
+ sp.run(command, check=True)
+ wavs = []
+ for filename in filenames:
+ wav = np.fromfile(filename, dtype=np.float32)
+ wav = torch.from_numpy(wav)
+ wav = wav.view(-1, self.channels()).t()
+ if channels is not None:
+ wav = convert_audio_channels(wav, channels)
+ if target_size is not None:
+ wav = wav[..., :target_size]
+ wavs.append(wav)
+ wav = torch.stack(wavs, dim=0)
+ if single:
+ wav = wav[0]
+ return wav
+
+
+def convert_audio_channels(wav, channels=2):
+ """Convert audio to the given number of channels."""
+ *shape, src_channels, length = wav.shape
+ if src_channels == channels:
+ pass
+ elif channels == 1:
+ # Case 1:
+ # The caller asked 1-channel audio, but the stream have multiple
+ # channels, downmix all channels.
+ wav = wav.mean(dim=-2, keepdim=True)
+ elif src_channels == 1:
+ # Case 2:
+ # The caller asked for multiple channels, but the input file have
+ # one single channel, replicate the audio over all channels.
+ wav = wav.expand(*shape, channels, length)
+ elif src_channels >= channels:
+ # Case 3:
+ # The caller asked for multiple channels, and the input file have
+ # more channels than requested. In that case return the first channels.
+ wav = wav[..., :channels, :]
+ else:
+ # Case 4: What is a reasonable choice here?
+ raise ValueError('The audio file has less channels than requested but is not mono.')
+ return wav
+
+
+def convert_audio(wav, from_samplerate, to_samplerate, channels):
+ wav = convert_audio_channels(wav, channels)
+ return julius.resample_frac(wav, from_samplerate, to_samplerate)
diff --git a/demucs/compressed.py b/demucs/compressed.py
new file mode 100644
index 0000000..eb8fbb7
--- /dev/null
+++ b/demucs/compressed.py
@@ -0,0 +1,115 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import json
+from fractions import Fraction
+from concurrent import futures
+
+import musdb
+from torch import distributed
+
+from .audio import AudioFile
+
+
+def get_musdb_tracks(root, *args, **kwargs):
+ mus = musdb.DB(root, *args, **kwargs)
+ return {track.name: track.path for track in mus}
+
+
+class StemsSet:
+ def __init__(self, tracks, metadata, duration=None, stride=1,
+ samplerate=44100, channels=2, streams=slice(None)):
+
+ self.metadata = []
+ for name, path in tracks.items():
+ meta = dict(metadata[name])
+ meta["path"] = path
+ meta["name"] = name
+ self.metadata.append(meta)
+ if duration is not None and meta["duration"] < duration:
+ raise ValueError(f"Track {name} duration is too small {meta['duration']}")
+ self.metadata.sort(key=lambda x: x["name"])
+ self.duration = duration
+ self.stride = stride
+ self.channels = channels
+ self.samplerate = samplerate
+ self.streams = streams
+
+ def __len__(self):
+ return sum(self._examples_count(m) for m in self.metadata)
+
+ def _examples_count(self, meta):
+ if self.duration is None:
+ return 1
+ else:
+ return int((meta["duration"] - self.duration) // self.stride + 1)
+
+ def track_metadata(self, index):
+ for meta in self.metadata:
+ examples = self._examples_count(meta)
+ if index >= examples:
+ index -= examples
+ continue
+ return meta
+
+ def __getitem__(self, index):
+ for meta in self.metadata:
+ examples = self._examples_count(meta)
+ if index >= examples:
+ index -= examples
+ continue
+ streams = AudioFile(meta["path"]).read(seek_time=index * self.stride,
+ duration=self.duration,
+ channels=self.channels,
+ samplerate=self.samplerate,
+ streams=self.streams)
+ return (streams - meta["mean"]) / meta["std"]
+
+
+def _get_track_metadata(path):
+ # use mono at 44kHz as reference. For any other settings data won't be perfectly
+ # normalized but it should be good enough.
+ audio = AudioFile(path)
+ mix = audio.read(streams=0, channels=1, samplerate=44100)
+ return {"duration": audio.duration, "std": mix.std().item(), "mean": mix.mean().item()}
+
+
+def _build_metadata(tracks, workers=10):
+ pendings = []
+ with futures.ProcessPoolExecutor(workers) as pool:
+ for name, path in tracks.items():
+ pendings.append((name, pool.submit(_get_track_metadata, path)))
+ return {name: p.result() for name, p in pendings}
+
+
+def _build_musdb_metadata(path, musdb, workers):
+ tracks = get_musdb_tracks(musdb)
+ metadata = _build_metadata(tracks, workers)
+ path.parent.mkdir(exist_ok=True, parents=True)
+ json.dump(metadata, open(path, "w"))
+
+
+def get_compressed_datasets(args, samples):
+ metadata_file = args.metadata / "musdb.json"
+ if not metadata_file.is_file() and args.rank == 0:
+ _build_musdb_metadata(metadata_file, args.musdb, args.workers)
+ if args.world_size > 1:
+ distributed.barrier()
+ metadata = json.load(open(metadata_file))
+ duration = Fraction(samples, args.samplerate)
+ stride = Fraction(args.data_stride, args.samplerate)
+ train_set = StemsSet(get_musdb_tracks(args.musdb, subsets=["train"], split="train"),
+ metadata,
+ duration=duration,
+ stride=stride,
+ streams=slice(1, None),
+ samplerate=args.samplerate,
+ channels=args.audio_channels)
+ valid_set = StemsSet(get_musdb_tracks(args.musdb, subsets=["train"], split="valid"),
+ metadata,
+ samplerate=args.samplerate,
+ channels=args.audio_channels)
+ return train_set, valid_set
diff --git a/demucs/model.py b/demucs/model.py
new file mode 100644
index 0000000..e9d932f
--- /dev/null
+++ b/demucs/model.py
@@ -0,0 +1,202 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import math
+
+import julius
+from torch import nn
+
+from .utils import capture_init, center_trim
+
+
+class BLSTM(nn.Module):
+ def __init__(self, dim, layers=1):
+ super().__init__()
+ self.lstm = nn.LSTM(bidirectional=True, num_layers=layers, hidden_size=dim, input_size=dim)
+ self.linear = nn.Linear(2 * dim, dim)
+
+ def forward(self, x):
+ x = x.permute(2, 0, 1)
+ x = self.lstm(x)[0]
+ x = self.linear(x)
+ x = x.permute(1, 2, 0)
+ return x
+
+
+def rescale_conv(conv, reference):
+ std = conv.weight.std().detach()
+ scale = (std / reference)**0.5
+ conv.weight.data /= scale
+ if conv.bias is not None:
+ conv.bias.data /= scale
+
+
+def rescale_module(module, reference):
+ for sub in module.modules():
+ if isinstance(sub, (nn.Conv1d, nn.ConvTranspose1d)):
+ rescale_conv(sub, reference)
+
+
+class Demucs(nn.Module):
+ @capture_init
+ def __init__(self,
+ sources,
+ audio_channels=2,
+ channels=64,
+ depth=6,
+ rewrite=True,
+ glu=True,
+ rescale=0.1,
+ resample=True,
+ kernel_size=8,
+ stride=4,
+ growth=2.,
+ lstm_layers=2,
+ context=3,
+ normalize=False,
+ samplerate=44100,
+ segment_length=4 * 10 * 44100):
+ """
+ Args:
+ sources (list[str]): list of source names
+ audio_channels (int): stereo or mono
+ channels (int): first convolution channels
+ depth (int): number of encoder/decoder layers
+ rewrite (bool): add 1x1 convolution to each encoder layer
+ and a convolution to each decoder layer.
+ For the decoder layer, `context` gives the kernel size.
+ glu (bool): use glu instead of ReLU
+ resample_input (bool): upsample x2 the input and downsample /2 the output.
+ rescale (int): rescale initial weights of convolutions
+ to get their standard deviation closer to `rescale`
+ kernel_size (int): kernel size for convolutions
+ stride (int): stride for convolutions
+ growth (float): multiply (resp divide) number of channels by that
+ for each layer of the encoder (resp decoder)
+ lstm_layers (int): number of lstm layers, 0 = no lstm
+ context (int): kernel size of the convolution in the
+ decoder before the transposed convolution. If > 1,
+ will provide some context from neighboring time
+ steps.
+ samplerate (int): stored as meta information for easing
+ future evaluations of the model.
+ segment_length (int): stored as meta information for easing
+ future evaluations of the model. Length of the segments on which
+ the model was trained.
+ """
+
+ super().__init__()
+ self.audio_channels = audio_channels
+ self.sources = sources
+ self.kernel_size = kernel_size
+ self.context = context
+ self.stride = stride
+ self.depth = depth
+ self.resample = resample
+ self.channels = channels
+ self.normalize = normalize
+ self.samplerate = samplerate
+ self.segment_length = segment_length
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ if glu:
+ activation = nn.GLU(dim=1)
+ ch_scale = 2
+ else:
+ activation = nn.ReLU()
+ ch_scale = 1
+ in_channels = audio_channels
+ for index in range(depth):
+ encode = []
+ encode += [nn.Conv1d(in_channels, channels, kernel_size, stride), nn.ReLU()]
+ if rewrite:
+ encode += [nn.Conv1d(channels, ch_scale * channels, 1), activation]
+ self.encoder.append(nn.Sequential(*encode))
+
+ decode = []
+ if index > 0:
+ out_channels = in_channels
+ else:
+ out_channels = len(self.sources) * audio_channels
+ if rewrite:
+ decode += [nn.Conv1d(channels, ch_scale * channels, context), activation]
+ decode += [nn.ConvTranspose1d(channels, out_channels, kernel_size, stride)]
+ if index > 0:
+ decode.append(nn.ReLU())
+ self.decoder.insert(0, nn.Sequential(*decode))
+ in_channels = channels
+ channels = int(growth * channels)
+
+ channels = in_channels
+
+ if lstm_layers:
+ self.lstm = BLSTM(channels, lstm_layers)
+ else:
+ self.lstm = None
+
+ if rescale:
+ rescale_module(self, reference=rescale)
+
+ def valid_length(self, length):
+ """
+ Return the nearest valid length to use with the model so that
+ there is no time steps left over in a convolutions, e.g. for all
+ layers, size of the input - kernel_size % stride = 0.
+
+ If the mixture has a valid length, the estimated sources
+ will have exactly the same length when context = 1. If context > 1,
+ the two signals can be center trimmed to match.
+
+ For training, extracts should have a valid length.For evaluation
+ on full tracks we recommend passing `pad = True` to :method:`forward`.
+ """
+ if self.resample:
+ length *= 2
+ for _ in range(self.depth):
+ length = math.ceil((length - self.kernel_size) / self.stride) + 1
+ length = max(1, length)
+ length += self.context - 1
+ for _ in range(self.depth):
+ length = (length - 1) * self.stride + self.kernel_size
+
+ if self.resample:
+ length = math.ceil(length / 2)
+ return int(length)
+
+ def forward(self, mix):
+ x = mix
+
+ if self.normalize:
+ mono = mix.mean(dim=1, keepdim=True)
+ mean = mono.mean(dim=-1, keepdim=True)
+ std = mono.std(dim=-1, keepdim=True)
+ else:
+ mean = 0
+ std = 1
+
+ x = (x - mean) / (1e-5 + std)
+
+ if self.resample:
+ x = julius.resample_frac(x, 1, 2)
+
+ saved = []
+ for encode in self.encoder:
+ x = encode(x)
+ saved.append(x)
+ if self.lstm:
+ x = self.lstm(x)
+ for decode in self.decoder:
+ skip = center_trim(saved.pop(-1), x)
+ x = x + skip
+ x = decode(x)
+
+ if self.resample:
+ x = julius.resample_frac(x, 2, 1)
+ x = x * std + mean
+ x = x.view(x.size(0), len(self.sources), self.audio_channels, x.size(-1))
+ return x
diff --git a/demucs/parser.py b/demucs/parser.py
new file mode 100644
index 0000000..4e8a19c
--- /dev/null
+++ b/demucs/parser.py
@@ -0,0 +1,244 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import os
+from pathlib import Path
+
+
+def get_parser():
+ parser = argparse.ArgumentParser("demucs", description="Train and evaluate Demucs.")
+ default_raw = None
+ default_musdb = None
+ if 'DEMUCS_RAW' in os.environ:
+ default_raw = Path(os.environ['DEMUCS_RAW'])
+ if 'DEMUCS_MUSDB' in os.environ:
+ default_musdb = Path(os.environ['DEMUCS_MUSDB'])
+ parser.add_argument(
+ "--raw",
+ type=Path,
+ default=default_raw,
+ help="Path to raw audio, can be faster, see python3 -m demucs.raw to extract.")
+ parser.add_argument("--no_raw", action="store_const", const=None, dest="raw")
+ parser.add_argument("-m",
+ "--musdb",
+ type=Path,
+ default=default_musdb,
+ help="Path to musdb root")
+ parser.add_argument("--is_wav", action="store_true",
+ help="Indicate that the MusDB dataset is in wav format (i.e. MusDB-HQ).")
+ parser.add_argument("--metadata", type=Path, default=Path("metadata/"),
+ help="Folder where metadata information is stored.")
+ parser.add_argument("--wav", type=Path,
+ help="Path to a wav dataset. This should contain a 'train' and a 'valid' "
+ "subfolder.")
+ parser.add_argument("--samplerate", type=int, default=44100)
+ parser.add_argument("--audio_channels", type=int, default=2)
+ parser.add_argument("--samples",
+ default=44100 * 10,
+ type=int,
+ help="number of samples to feed in")
+ parser.add_argument("--data_stride",
+ default=44100,
+ type=int,
+ help="Stride for chunks, shorter = longer epochs")
+ parser.add_argument("-w", "--workers", default=10, type=int, help="Loader workers")
+ parser.add_argument("--eval_workers", default=2, type=int, help="Final evaluation workers")
+ parser.add_argument("-d",
+ "--device",
+ help="Device to train on, default is cuda if available else cpu")
+ parser.add_argument("--eval_cpu", action="store_true", help="Eval on test will be run on cpu.")
+ parser.add_argument("--dummy", help="Dummy parameter, useful to create a new checkpoint file")
+ parser.add_argument("--test", help="Just run the test pipeline + one validation. "
+ "This should be a filename relative to the models/ folder.")
+ parser.add_argument("--test_pretrained", help="Just run the test pipeline + one validation, "
+ "on a pretrained model. ")
+
+ parser.add_argument("--rank", default=0, type=int)
+ parser.add_argument("--world_size", default=1, type=int)
+ parser.add_argument("--master")
+
+ parser.add_argument("--checkpoints",
+ type=Path,
+ default=Path("checkpoints"),
+ help="Folder where to store checkpoints etc")
+ parser.add_argument("--evals",
+ type=Path,
+ default=Path("evals"),
+ help="Folder where to store evals and waveforms")
+ parser.add_argument("--save",
+ action="store_true",
+ help="Save estimated for the test set waveforms")
+ parser.add_argument("--logs",
+ type=Path,
+ default=Path("logs"),
+ help="Folder where to store logs")
+ parser.add_argument("--models",
+ type=Path,
+ default=Path("models"),
+ help="Folder where to store trained models")
+ parser.add_argument("-R",
+ "--restart",
+ action='store_true',
+ help='Restart training, ignoring previous run')
+
+ parser.add_argument("--seed", type=int, default=42)
+ parser.add_argument("-e", "--epochs", type=int, default=180, help="Number of epochs")
+ parser.add_argument("-r",
+ "--repeat",
+ type=int,
+ default=2,
+ help="Repeat the train set, longer epochs")
+ parser.add_argument("-b", "--batch_size", type=int, default=64)
+ parser.add_argument("--lr", type=float, default=3e-4)
+ parser.add_argument("--mse", action="store_true", help="Use MSE instead of L1")
+ parser.add_argument("--init", help="Initialize from a pre-trained model.")
+
+ # Augmentation options
+ parser.add_argument("--no_augment",
+ action="store_false",
+ dest="augment",
+ default=True,
+ help="No basic data augmentation.")
+ parser.add_argument("--repitch", type=float, default=0.2,
+ help="Probability to do tempo/pitch change")
+ parser.add_argument("--max_tempo", type=float, default=12,
+ help="Maximum relative tempo change in %% when using repitch.")
+
+ parser.add_argument("--remix_group_size",
+ type=int,
+ default=4,
+ help="Shuffle sources using group of this size. Useful to somewhat "
+ "replicate multi-gpu training "
+ "on less GPUs.")
+ parser.add_argument("--shifts",
+ type=int,
+ default=10,
+ help="Number of random shifts used for the shift trick.")
+ parser.add_argument("--overlap",
+ type=float,
+ default=0.25,
+ help="Overlap when --split_valid is passed.")
+
+ # See model.py for doc
+ parser.add_argument("--growth",
+ type=float,
+ default=2.,
+ help="Number of channels between two layers will increase by this factor")
+ parser.add_argument("--depth",
+ type=int,
+ default=6,
+ help="Number of layers for the encoder and decoder")
+ parser.add_argument("--lstm_layers", type=int, default=2, help="Number of layers for the LSTM")
+ parser.add_argument("--channels",
+ type=int,
+ default=64,
+ help="Number of channels for the first encoder layer")
+ parser.add_argument("--kernel_size",
+ type=int,
+ default=8,
+ help="Kernel size for the (transposed) convolutions")
+ parser.add_argument("--conv_stride",
+ type=int,
+ default=4,
+ help="Stride for the (transposed) convolutions")
+ parser.add_argument("--context",
+ type=int,
+ default=3,
+ help="Context size for the decoder convolutions "
+ "before the transposed convolutions")
+ parser.add_argument("--rescale",
+ type=float,
+ default=0.1,
+ help="Initial weight rescale reference")
+ parser.add_argument("--no_resample", action="store_false",
+ default=True, dest="resample",
+ help="No Resampling of the input/output x2")
+ parser.add_argument("--no_glu",
+ action="store_false",
+ default=True,
+ dest="glu",
+ help="Replace all GLUs by ReLUs")
+ parser.add_argument("--no_rewrite",
+ action="store_false",
+ default=True,
+ dest="rewrite",
+ help="No 1x1 rewrite convolutions")
+ parser.add_argument("--normalize", action="store_true")
+ parser.add_argument("--no_norm_wav", action="store_false", dest='norm_wav', default=True)
+
+ # Tasnet options
+ parser.add_argument("--tasnet", action="store_true")
+ parser.add_argument("--split_valid",
+ action="store_true",
+ help="Predict chunks by chunks for valid and test. Required for tasnet")
+ parser.add_argument("--X", type=int, default=8)
+
+ # Other options
+ parser.add_argument("--show",
+ action="store_true",
+ help="Show model architecture, size and exit")
+ parser.add_argument("--save_model", action="store_true",
+ help="Skip traning, just save final model "
+ "for the current checkpoint value.")
+ parser.add_argument("--save_state",
+ help="Skip training, just save state "
+ "for the current checkpoint value. You should "
+ "provide a model name as argument.")
+
+ # Quantization options
+ parser.add_argument("--q-min-size", type=float, default=1,
+ help="Only quantize layers over this size (in MB)")
+ parser.add_argument(
+ "--qat", type=int, help="If provided, use QAT training with that many bits.")
+
+ parser.add_argument("--diffq", type=float, default=0)
+ parser.add_argument(
+ "--ms-target", type=float, default=162,
+ help="Model size target in MB, when using DiffQ. Best model will be kept "
+ "only if it is smaller than this target.")
+
+ return parser
+
+
+def get_name(parser, args):
+ """
+ Return the name of an experiment given the args. Some parameters are ignored,
+ for instance --workers, as they do not impact the final result.
+ """
+ ignore_args = set([
+ "checkpoints",
+ "deterministic",
+ "eval",
+ "evals",
+ "eval_cpu",
+ "eval_workers",
+ "logs",
+ "master",
+ "rank",
+ "restart",
+ "save",
+ "save_model",
+ "save_state",
+ "show",
+ "workers",
+ "world_size",
+ ])
+ parts = []
+ name_args = dict(args.__dict__)
+ for name, value in name_args.items():
+ if name in ignore_args:
+ continue
+ if value != parser.get_default(name):
+ if isinstance(value, Path):
+ parts.append(f"{name}={value.name}")
+ else:
+ parts.append(f"{name}={value}")
+ if parts:
+ name = " ".join(parts)
+ else:
+ name = "default"
+ return name
diff --git a/demucs/pretrained.py b/demucs/pretrained.py
new file mode 100644
index 0000000..6aac5db
--- /dev/null
+++ b/demucs/pretrained.py
@@ -0,0 +1,107 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+# author: adefossez
+
+import logging
+
+from diffq import DiffQuantizer
+import torch.hub
+
+from .model import Demucs
+from .tasnet import ConvTasNet
+from .utils import set_state
+
+logger = logging.getLogger(__name__)
+ROOT = "https://dl.fbaipublicfiles.com/demucs/v3.0/"
+
+PRETRAINED_MODELS = {
+ 'demucs': 'e07c671f',
+ 'demucs48_hq': '28a1282c',
+ 'demucs_extra': '3646af93',
+ 'demucs_quantized': '07afea75',
+ 'tasnet': 'beb46fac',
+ 'tasnet_extra': 'df3777b2',
+ 'demucs_unittest': '09ebc15f',
+}
+
+SOURCES = ["drums", "bass", "other", "vocals"]
+
+
+def get_url(name):
+ sig = PRETRAINED_MODELS[name]
+ return ROOT + name + "-" + sig[:8] + ".th"
+
+
+def is_pretrained(name):
+ return name in PRETRAINED_MODELS
+
+
+def load_pretrained(name):
+ if name == "demucs":
+ return demucs(pretrained=True)
+ elif name == "demucs48_hq":
+ return demucs(pretrained=True, hq=True, channels=48)
+ elif name == "demucs_extra":
+ return demucs(pretrained=True, extra=True)
+ elif name == "demucs_quantized":
+ return demucs(pretrained=True, quantized=True)
+ elif name == "demucs_unittest":
+ return demucs_unittest(pretrained=True)
+ elif name == "tasnet":
+ return tasnet(pretrained=True)
+ elif name == "tasnet_extra":
+ return tasnet(pretrained=True, extra=True)
+ else:
+ raise ValueError(f"Invalid pretrained name {name}")
+
+
+def _load_state(name, model, quantizer=None):
+ url = get_url(name)
+ state = torch.hub.load_state_dict_from_url(url, map_location='cpu', check_hash=True)
+ set_state(model, quantizer, state)
+ if quantizer:
+ quantizer.detach()
+
+
+def demucs_unittest(pretrained=True):
+ model = Demucs(channels=4, sources=SOURCES)
+ if pretrained:
+ _load_state('demucs_unittest', model)
+ return model
+
+
+def demucs(pretrained=True, extra=False, quantized=False, hq=False, channels=64):
+ if not pretrained and (extra or quantized or hq):
+ raise ValueError("if extra or quantized is True, pretrained must be True.")
+ model = Demucs(sources=SOURCES, channels=channels)
+ if pretrained:
+ name = 'demucs'
+ if channels != 64:
+ name += str(channels)
+ quantizer = None
+ if sum([extra, quantized, hq]) > 1:
+ raise ValueError("Only one of extra, quantized, hq, can be True.")
+ if quantized:
+ quantizer = DiffQuantizer(model, group_size=8, min_size=1)
+ name += '_quantized'
+ if extra:
+ name += '_extra'
+ if hq:
+ name += '_hq'
+ _load_state(name, model, quantizer)
+ return model
+
+
+def tasnet(pretrained=True, extra=False):
+ if not pretrained and extra:
+ raise ValueError("if extra is True, pretrained must be True.")
+ model = ConvTasNet(X=10, sources=SOURCES)
+ if pretrained:
+ name = 'tasnet'
+ if extra:
+ name = 'tasnet_extra'
+ _load_state(name, model)
+ return model
diff --git a/demucs/raw.py b/demucs/raw.py
new file mode 100644
index 0000000..d4941ad
--- /dev/null
+++ b/demucs/raw.py
@@ -0,0 +1,173 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import os
+from collections import defaultdict, namedtuple
+from pathlib import Path
+
+import musdb
+import numpy as np
+import torch as th
+import tqdm
+from torch.utils.data import DataLoader
+
+from .audio import AudioFile
+
+ChunkInfo = namedtuple("ChunkInfo", ["file_index", "offset", "local_index"])
+
+
+class Rawset:
+ """
+ Dataset of raw, normalized, float32 audio files
+ """
+ def __init__(self, path, samples=None, stride=None, channels=2, streams=None):
+ self.path = Path(path)
+ self.channels = channels
+ self.samples = samples
+ if stride is None:
+ stride = samples if samples is not None else 0
+ self.stride = stride
+ entries = defaultdict(list)
+ for root, folders, files in os.walk(self.path, followlinks=True):
+ folders.sort()
+ files.sort()
+ for file in files:
+ if file.endswith(".raw"):
+ path = Path(root) / file
+ name, stream = path.stem.rsplit('.', 1)
+ entries[(path.parent.relative_to(self.path), name)].append(int(stream))
+
+ self._entries = list(entries.keys())
+
+ sizes = []
+ self._lengths = []
+ ref_streams = sorted(entries[self._entries[0]])
+ assert ref_streams == list(range(len(ref_streams)))
+ if streams is None:
+ self.streams = ref_streams
+ else:
+ self.streams = streams
+ for entry in sorted(entries.keys()):
+ streams = entries[entry]
+ assert sorted(streams) == ref_streams
+ file = self._path(*entry)
+ length = file.stat().st_size // (4 * channels)
+ if samples is None:
+ sizes.append(1)
+ else:
+ if length < samples:
+ self._entries.remove(entry)
+ continue
+ sizes.append((length - samples) // stride + 1)
+ self._lengths.append(length)
+ if not sizes:
+ raise ValueError(f"Empty dataset {self.path}")
+ self._cumulative_sizes = np.cumsum(sizes)
+ self._sizes = sizes
+
+ def __len__(self):
+ return self._cumulative_sizes[-1]
+
+ @property
+ def total_length(self):
+ return sum(self._lengths)
+
+ def chunk_info(self, index):
+ file_index = np.searchsorted(self._cumulative_sizes, index, side='right')
+ if file_index == 0:
+ local_index = index
+ else:
+ local_index = index - self._cumulative_sizes[file_index - 1]
+ return ChunkInfo(offset=local_index * self.stride,
+ file_index=file_index,
+ local_index=local_index)
+
+ def _path(self, folder, name, stream=0):
+ return self.path / folder / (name + f'.{stream}.raw')
+
+ def __getitem__(self, index):
+ chunk = self.chunk_info(index)
+ entry = self._entries[chunk.file_index]
+
+ length = self.samples or self._lengths[chunk.file_index]
+ streams = []
+ to_read = length * self.channels * 4
+ for stream_index, stream in enumerate(self.streams):
+ offset = chunk.offset * 4 * self.channels
+ file = open(self._path(*entry, stream=stream), 'rb')
+ file.seek(offset)
+ content = file.read(to_read)
+ assert len(content) == to_read
+ content = np.frombuffer(content, dtype=np.float32)
+ content = content.copy() # make writable
+ streams.append(th.from_numpy(content).view(length, self.channels).t())
+ return th.stack(streams, dim=0)
+
+ def name(self, index):
+ chunk = self.chunk_info(index)
+ folder, name = self._entries[chunk.file_index]
+ return folder / name
+
+
+class MusDBSet:
+ def __init__(self, mus, streams=slice(None), samplerate=44100, channels=2):
+ self.mus = mus
+ self.streams = streams
+ self.samplerate = samplerate
+ self.channels = channels
+
+ def __len__(self):
+ return len(self.mus.tracks)
+
+ def __getitem__(self, index):
+ track = self.mus.tracks[index]
+ return (track.name, AudioFile(track.path).read(channels=self.channels,
+ seek_time=0,
+ streams=self.streams,
+ samplerate=self.samplerate))
+
+
+def build_raw(mus, destination, normalize, workers, samplerate, channels):
+ destination.mkdir(parents=True, exist_ok=True)
+ loader = DataLoader(MusDBSet(mus, channels=channels, samplerate=samplerate),
+ batch_size=1,
+ num_workers=workers,
+ collate_fn=lambda x: x[0])
+ for name, streams in tqdm.tqdm(loader):
+ if normalize:
+ ref = streams[0].mean(dim=0) # use mono mixture as reference
+ streams = (streams - ref.mean()) / ref.std()
+ for index, stream in enumerate(streams):
+ open(destination / (name + f'.{index}.raw'), "wb").write(stream.t().numpy().tobytes())
+
+
+def main():
+ parser = argparse.ArgumentParser('rawset')
+ parser.add_argument('--workers', type=int, default=10)
+ parser.add_argument('--samplerate', type=int, default=44100)
+ parser.add_argument('--channels', type=int, default=2)
+ parser.add_argument('musdb', type=Path)
+ parser.add_argument('destination', type=Path)
+
+ args = parser.parse_args()
+
+ build_raw(musdb.DB(root=args.musdb, subsets=["train"], split="train"),
+ args.destination / "train",
+ normalize=True,
+ channels=args.channels,
+ samplerate=args.samplerate,
+ workers=args.workers)
+ build_raw(musdb.DB(root=args.musdb, subsets=["train"], split="valid"),
+ args.destination / "valid",
+ normalize=True,
+ samplerate=args.samplerate,
+ channels=args.channels,
+ workers=args.workers)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/separate.py b/demucs/separate.py
new file mode 100644
index 0000000..3fc7af9
--- /dev/null
+++ b/demucs/separate.py
@@ -0,0 +1,185 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import argparse
+import sys
+from pathlib import Path
+import subprocess
+
+import julius
+import torch as th
+import torchaudio as ta
+
+from .audio import AudioFile, convert_audio_channels
+from .pretrained import is_pretrained, load_pretrained
+from .utils import apply_model, load_model
+
+
+def load_track(track, device, audio_channels, samplerate):
+ errors = {}
+ wav = None
+
+ try:
+ wav = AudioFile(track).read(
+ streams=0,
+ samplerate=samplerate,
+ channels=audio_channels).to(device)
+ except FileNotFoundError:
+ errors['ffmpeg'] = 'Ffmpeg is not installed.'
+ except subprocess.CalledProcessError:
+ errors['ffmpeg'] = 'FFmpeg could not read the file.'
+
+ if wav is None:
+ try:
+ wav, sr = ta.load(str(track))
+ except RuntimeError as err:
+ errors['torchaudio'] = err.args[0]
+ else:
+ wav = convert_audio_channels(wav, audio_channels)
+ wav = wav.to(device)
+ wav = julius.resample_frac(wav, sr, samplerate)
+
+ if wav is None:
+ print(f"Could not load file {track}. "
+ "Maybe it is not a supported file format? ")
+ for backend, error in errors.items():
+ print(f"When trying to load using {backend}, got the following error: {error}")
+ sys.exit(1)
+ return wav
+
+
+def encode_mp3(wav, path, bitrate=320, samplerate=44100, channels=2, verbose=False):
+ try:
+ import lameenc
+ except ImportError:
+ print("Failed to call lame encoder. Maybe it is not installed? "
+ "On windows, run `python.exe -m pip install -U lameenc`, "
+ "on OSX/Linux, run `python3 -m pip install -U lameenc`, "
+ "then try again.", file=sys.stderr)
+ sys.exit(1)
+ encoder = lameenc.Encoder()
+ encoder.set_bit_rate(bitrate)
+ encoder.set_in_sample_rate(samplerate)
+ encoder.set_channels(channels)
+ encoder.set_quality(2) # 2-highest, 7-fastest
+ if not verbose:
+ encoder.silence()
+ wav = wav.transpose(0, 1).numpy()
+ mp3_data = encoder.encode(wav.tobytes())
+ mp3_data += encoder.flush()
+ with open(path, "wb") as f:
+ f.write(mp3_data)
+
+
+def main():
+ parser = argparse.ArgumentParser("demucs.separate",
+ description="Separate the sources for the given tracks")
+ parser.add_argument("tracks", nargs='+', type=Path, default=[], help='Path to tracks')
+ parser.add_argument("-n",
+ "--name",
+ default="demucs_quantized",
+ help="Model name. See README.md for the list of pretrained models. "
+ "Default is demucs_quantized.")
+ parser.add_argument("-v", "--verbose", action="store_true")
+ parser.add_argument("-o",
+ "--out",
+ type=Path,
+ default=Path("separated"),
+ help="Folder where to put extracted tracks. A subfolder "
+ "with the model name will be created.")
+ parser.add_argument("--models",
+ type=Path,
+ default=Path("models"),
+ help="Path to trained models. "
+ "Also used to store downloaded pretrained models")
+ parser.add_argument("-d",
+ "--device",
+ default="cuda" if th.cuda.is_available() else "cpu",
+ help="Device to use, default is cuda if available else cpu")
+ parser.add_argument("--shifts",
+ default=0,
+ type=int,
+ help="Number of random shifts for equivariant stabilization."
+ "Increase separation time but improves quality for Demucs. 10 was used "
+ "in the original paper.")
+ parser.add_argument("--overlap",
+ default=0.25,
+ type=float,
+ help="Overlap between the splits.")
+ parser.add_argument("--no-split",
+ action="store_false",
+ dest="split",
+ default=True,
+ help="Doesn't split audio in chunks. This can use large amounts of memory.")
+ parser.add_argument("--float32",
+ action="store_true",
+ help="Convert the output wavefile to use pcm f32 format instead of s16. "
+ "This should not make a difference if you just plan on listening to the "
+ "audio but might be needed to compute exactly metrics like SDR etc.")
+ parser.add_argument("--int16",
+ action="store_false",
+ dest="float32",
+ help="Opposite of --float32, here for compatibility.")
+ parser.add_argument("--mp3", action="store_true",
+ help="Convert the output wavs to mp3.")
+ parser.add_argument("--mp3-bitrate",
+ default=320,
+ type=int,
+ help="Bitrate of converted mp3.")
+
+ args = parser.parse_args()
+ name = args.name + ".th"
+ model_path = args.models / name
+ if model_path.is_file():
+ model = load_model(model_path)
+ else:
+ if is_pretrained(args.name):
+ model = load_pretrained(args.name)
+ else:
+ print(f"No pre-trained model {args.name}", file=sys.stderr)
+ sys.exit(1)
+ model.to(args.device)
+
+ out = args.out / args.name
+ out.mkdir(parents=True, exist_ok=True)
+ print(f"Separated tracks will be stored in {out.resolve()}")
+ for track in args.tracks:
+ if not track.exists():
+ print(
+ f"File {track} does not exist. If the path contains spaces, "
+ "please try again after surrounding the entire path with quotes \"\".",
+ file=sys.stderr)
+ continue
+ print(f"Separating track {track}")
+ wav = load_track(track, args.device, model.audio_channels, model.samplerate)
+
+ ref = wav.mean(0)
+ wav = (wav - ref.mean()) / ref.std()
+ sources = apply_model(model, wav, shifts=args.shifts, split=args.split,
+ overlap=args.overlap, progress=True)
+ sources = sources * ref.std() + ref.mean()
+
+ track_folder = out / track.name.rsplit(".", 1)[0]
+ track_folder.mkdir(exist_ok=True)
+ for source, name in zip(sources, model.sources):
+ source = source / max(1.01 * source.abs().max(), 1)
+ if args.mp3 or not args.float32:
+ source = (source * 2**15).clamp_(-2**15, 2**15 - 1).short()
+ source = source.cpu()
+ stem = str(track_folder / name)
+ if args.mp3:
+ encode_mp3(source, stem + ".mp3",
+ bitrate=args.mp3_bitrate,
+ samplerate=model.samplerate,
+ channels=model.audio_channels,
+ verbose=args.verbose)
+ else:
+ wavname = str(track_folder / f"{name}.wav")
+ ta.save(wavname, source, sample_rate=model.samplerate)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/demucs/tasnet.py b/demucs/tasnet.py
new file mode 100644
index 0000000..ecc1257
--- /dev/null
+++ b/demucs/tasnet.py
@@ -0,0 +1,452 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+# Created on 2018/12
+# Author: Kaituo XU
+# Modified on 2019/11 by Alexandre Defossez, added support for multiple output channels
+# Here is the original license:
+# The MIT License (MIT)
+#
+# Copyright (c) 2018 Kaituo XU
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .utils import capture_init
+
+EPS = 1e-8
+
+
+def overlap_and_add(signal, frame_step):
+ outer_dimensions = signal.size()[:-2]
+ frames, frame_length = signal.size()[-2:]
+
+ subframe_length = math.gcd(frame_length, frame_step) # gcd=Greatest Common Divisor
+ subframe_step = frame_step // subframe_length
+ subframes_per_frame = frame_length // subframe_length
+ output_size = frame_step * (frames - 1) + frame_length
+ output_subframes = output_size // subframe_length
+
+ subframe_signal = signal.view(*outer_dimensions, -1, subframe_length)
+
+ frame = torch.arange(0, output_subframes,
+ device=signal.device).unfold(0, subframes_per_frame, subframe_step)
+ frame = frame.long() # signal may in GPU or CPU
+ frame = frame.contiguous().view(-1)
+
+ result = signal.new_zeros(*outer_dimensions, output_subframes, subframe_length)
+ result.index_add_(-2, frame, subframe_signal)
+ result = result.view(*outer_dimensions, -1)
+ return result
+
+
+class ConvTasNet(nn.Module):
+ @capture_init
+ def __init__(self,
+ sources,
+ N=256,
+ L=20,
+ B=256,
+ H=512,
+ P=3,
+ X=8,
+ R=4,
+ audio_channels=2,
+ norm_type="gLN",
+ causal=False,
+ mask_nonlinear='relu',
+ samplerate=44100,
+ segment_length=44100 * 2 * 4):
+ """
+ Args:
+ sources: list of sources
+ N: Number of filters in autoencoder
+ L: Length of the filters (in samples)
+ B: Number of channels in bottleneck 1 × 1-conv block
+ H: Number of channels in convolutional blocks
+ P: Kernel size in convolutional blocks
+ X: Number of convolutional blocks in each repeat
+ R: Number of repeats
+ norm_type: BN, gLN, cLN
+ causal: causal or non-causal
+ mask_nonlinear: use which non-linear function to generate mask
+ """
+ super(ConvTasNet, self).__init__()
+ # Hyper-parameter
+ self.sources = sources
+ self.C = len(sources)
+ self.N, self.L, self.B, self.H, self.P, self.X, self.R = N, L, B, H, P, X, R
+ self.norm_type = norm_type
+ self.causal = causal
+ self.mask_nonlinear = mask_nonlinear
+ self.audio_channels = audio_channels
+ self.samplerate = samplerate
+ self.segment_length = segment_length
+ # Components
+ self.encoder = Encoder(L, N, audio_channels)
+ self.separator = TemporalConvNet(
+ N, B, H, P, X, R, self.C, norm_type, causal, mask_nonlinear)
+ self.decoder = Decoder(N, L, audio_channels)
+ # init
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_normal_(p)
+
+ def valid_length(self, length):
+ return length
+
+ def forward(self, mixture):
+ """
+ Args:
+ mixture: [M, T], M is batch size, T is #samples
+ Returns:
+ est_source: [M, C, T]
+ """
+ mixture_w = self.encoder(mixture)
+ est_mask = self.separator(mixture_w)
+ est_source = self.decoder(mixture_w, est_mask)
+
+ # T changed after conv1d in encoder, fix it here
+ T_origin = mixture.size(-1)
+ T_conv = est_source.size(-1)
+ est_source = F.pad(est_source, (0, T_origin - T_conv))
+ return est_source
+
+
+class Encoder(nn.Module):
+ """Estimation of the nonnegative mixture weight by a 1-D conv layer.
+ """
+ def __init__(self, L, N, audio_channels):
+ super(Encoder, self).__init__()
+ # Hyper-parameter
+ self.L, self.N = L, N
+ # Components
+ # 50% overlap
+ self.conv1d_U = nn.Conv1d(audio_channels, N, kernel_size=L, stride=L // 2, bias=False)
+
+ def forward(self, mixture):
+ """
+ Args:
+ mixture: [M, T], M is batch size, T is #samples
+ Returns:
+ mixture_w: [M, N, K], where K = (T-L)/(L/2)+1 = 2T/L-1
+ """
+ mixture_w = F.relu(self.conv1d_U(mixture)) # [M, N, K]
+ return mixture_w
+
+
+class Decoder(nn.Module):
+ def __init__(self, N, L, audio_channels):
+ super(Decoder, self).__init__()
+ # Hyper-parameter
+ self.N, self.L = N, L
+ self.audio_channels = audio_channels
+ # Components
+ self.basis_signals = nn.Linear(N, audio_channels * L, bias=False)
+
+ def forward(self, mixture_w, est_mask):
+ """
+ Args:
+ mixture_w: [M, N, K]
+ est_mask: [M, C, N, K]
+ Returns:
+ est_source: [M, C, T]
+ """
+ # D = W * M
+ source_w = torch.unsqueeze(mixture_w, 1) * est_mask # [M, C, N, K]
+ source_w = torch.transpose(source_w, 2, 3) # [M, C, K, N]
+ # S = DV
+ est_source = self.basis_signals(source_w) # [M, C, K, ac * L]
+ m, c, k, _ = est_source.size()
+ est_source = est_source.view(m, c, k, self.audio_channels, -1).transpose(2, 3).contiguous()
+ est_source = overlap_and_add(est_source, self.L // 2) # M x C x ac x T
+ return est_source
+
+
+class TemporalConvNet(nn.Module):
+ def __init__(self, N, B, H, P, X, R, C, norm_type="gLN", causal=False, mask_nonlinear='relu'):
+ """
+ Args:
+ N: Number of filters in autoencoder
+ B: Number of channels in bottleneck 1 × 1-conv block
+ H: Number of channels in convolutional blocks
+ P: Kernel size in convolutional blocks
+ X: Number of convolutional blocks in each repeat
+ R: Number of repeats
+ C: Number of speakers
+ norm_type: BN, gLN, cLN
+ causal: causal or non-causal
+ mask_nonlinear: use which non-linear function to generate mask
+ """
+ super(TemporalConvNet, self).__init__()
+ # Hyper-parameter
+ self.C = C
+ self.mask_nonlinear = mask_nonlinear
+ # Components
+ # [M, N, K] -> [M, N, K]
+ layer_norm = ChannelwiseLayerNorm(N)
+ # [M, N, K] -> [M, B, K]
+ bottleneck_conv1x1 = nn.Conv1d(N, B, 1, bias=False)
+ # [M, B, K] -> [M, B, K]
+ repeats = []
+ for r in range(R):
+ blocks = []
+ for x in range(X):
+ dilation = 2**x
+ padding = (P - 1) * dilation if causal else (P - 1) * dilation // 2
+ blocks += [
+ TemporalBlock(B,
+ H,
+ P,
+ stride=1,
+ padding=padding,
+ dilation=dilation,
+ norm_type=norm_type,
+ causal=causal)
+ ]
+ repeats += [nn.Sequential(*blocks)]
+ temporal_conv_net = nn.Sequential(*repeats)
+ # [M, B, K] -> [M, C*N, K]
+ mask_conv1x1 = nn.Conv1d(B, C * N, 1, bias=False)
+ # Put together
+ self.network = nn.Sequential(layer_norm, bottleneck_conv1x1, temporal_conv_net,
+ mask_conv1x1)
+
+ def forward(self, mixture_w):
+ """
+ Keep this API same with TasNet
+ Args:
+ mixture_w: [M, N, K], M is batch size
+ returns:
+ est_mask: [M, C, N, K]
+ """
+ M, N, K = mixture_w.size()
+ score = self.network(mixture_w) # [M, N, K] -> [M, C*N, K]
+ score = score.view(M, self.C, N, K) # [M, C*N, K] -> [M, C, N, K]
+ if self.mask_nonlinear == 'softmax':
+ est_mask = F.softmax(score, dim=1)
+ elif self.mask_nonlinear == 'relu':
+ est_mask = F.relu(score)
+ else:
+ raise ValueError("Unsupported mask non-linear function")
+ return est_mask
+
+
+class TemporalBlock(nn.Module):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ norm_type="gLN",
+ causal=False):
+ super(TemporalBlock, self).__init__()
+ # [M, B, K] -> [M, H, K]
+ conv1x1 = nn.Conv1d(in_channels, out_channels, 1, bias=False)
+ prelu = nn.PReLU()
+ norm = chose_norm(norm_type, out_channels)
+ # [M, H, K] -> [M, B, K]
+ dsconv = DepthwiseSeparableConv(out_channels, in_channels, kernel_size, stride, padding,
+ dilation, norm_type, causal)
+ # Put together
+ self.net = nn.Sequential(conv1x1, prelu, norm, dsconv)
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, B, K]
+ Returns:
+ [M, B, K]
+ """
+ residual = x
+ out = self.net(x)
+ # TODO: when P = 3 here works fine, but when P = 2 maybe need to pad?
+ return out + residual # look like w/o F.relu is better than w/ F.relu
+ # return F.relu(out + residual)
+
+
+class DepthwiseSeparableConv(nn.Module):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ norm_type="gLN",
+ causal=False):
+ super(DepthwiseSeparableConv, self).__init__()
+ # Use `groups` option to implement depthwise convolution
+ # [M, H, K] -> [M, H, K]
+ depthwise_conv = nn.Conv1d(in_channels,
+ in_channels,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=in_channels,
+ bias=False)
+ if causal:
+ chomp = Chomp1d(padding)
+ prelu = nn.PReLU()
+ norm = chose_norm(norm_type, in_channels)
+ # [M, H, K] -> [M, B, K]
+ pointwise_conv = nn.Conv1d(in_channels, out_channels, 1, bias=False)
+ # Put together
+ if causal:
+ self.net = nn.Sequential(depthwise_conv, chomp, prelu, norm, pointwise_conv)
+ else:
+ self.net = nn.Sequential(depthwise_conv, prelu, norm, pointwise_conv)
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, H, K]
+ Returns:
+ result: [M, B, K]
+ """
+ return self.net(x)
+
+
+class Chomp1d(nn.Module):
+ """To ensure the output length is the same as the input.
+ """
+ def __init__(self, chomp_size):
+ super(Chomp1d, self).__init__()
+ self.chomp_size = chomp_size
+
+ def forward(self, x):
+ """
+ Args:
+ x: [M, H, Kpad]
+ Returns:
+ [M, H, K]
+ """
+ return x[:, :, :-self.chomp_size].contiguous()
+
+
+def chose_norm(norm_type, channel_size):
+ """The input of normlization will be (M, C, K), where M is batch size,
+ C is channel size and K is sequence length.
+ """
+ if norm_type == "gLN":
+ return GlobalLayerNorm(channel_size)
+ elif norm_type == "cLN":
+ return ChannelwiseLayerNorm(channel_size)
+ elif norm_type == "id":
+ return nn.Identity()
+ else: # norm_type == "BN":
+ # Given input (M, C, K), nn.BatchNorm1d(C) will accumulate statics
+ # along M and K, so this BN usage is right.
+ return nn.BatchNorm1d(channel_size)
+
+
+# TODO: Use nn.LayerNorm to impl cLN to speed up
+class ChannelwiseLayerNorm(nn.Module):
+ """Channel-wise Layer Normalization (cLN)"""
+ def __init__(self, channel_size):
+ super(ChannelwiseLayerNorm, self).__init__()
+ self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.beta = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ self.gamma.data.fill_(1)
+ self.beta.data.zero_()
+
+ def forward(self, y):
+ """
+ Args:
+ y: [M, N, K], M is batch size, N is channel size, K is length
+ Returns:
+ cLN_y: [M, N, K]
+ """
+ mean = torch.mean(y, dim=1, keepdim=True) # [M, 1, K]
+ var = torch.var(y, dim=1, keepdim=True, unbiased=False) # [M, 1, K]
+ cLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
+ return cLN_y
+
+
+class GlobalLayerNorm(nn.Module):
+ """Global Layer Normalization (gLN)"""
+ def __init__(self, channel_size):
+ super(GlobalLayerNorm, self).__init__()
+ self.gamma = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.beta = nn.Parameter(torch.Tensor(1, channel_size, 1)) # [1, N, 1]
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ self.gamma.data.fill_(1)
+ self.beta.data.zero_()
+
+ def forward(self, y):
+ """
+ Args:
+ y: [M, N, K], M is batch size, N is channel size, K is length
+ Returns:
+ gLN_y: [M, N, K]
+ """
+ # TODO: in torch 1.0, torch.mean() support dim list
+ mean = y.mean(dim=1, keepdim=True).mean(dim=2, keepdim=True) # [M, 1, 1]
+ var = (torch.pow(y - mean, 2)).mean(dim=1, keepdim=True).mean(dim=2, keepdim=True)
+ gLN_y = self.gamma * (y - mean) / torch.pow(var + EPS, 0.5) + self.beta
+ return gLN_y
+
+
+if __name__ == "__main__":
+ torch.manual_seed(123)
+ M, N, L, T = 2, 3, 4, 12
+ K = 2 * T // L - 1
+ B, H, P, X, R, C, norm_type, causal = 2, 3, 3, 3, 2, 2, "gLN", False
+ mixture = torch.randint(3, (M, T))
+ # test Encoder
+ encoder = Encoder(L, N)
+ encoder.conv1d_U.weight.data = torch.randint(2, encoder.conv1d_U.weight.size())
+ mixture_w = encoder(mixture)
+ print('mixture', mixture)
+ print('U', encoder.conv1d_U.weight)
+ print('mixture_w', mixture_w)
+ print('mixture_w size', mixture_w.size())
+
+ # test TemporalConvNet
+ separator = TemporalConvNet(N, B, H, P, X, R, C, norm_type=norm_type, causal=causal)
+ est_mask = separator(mixture_w)
+ print('est_mask', est_mask)
+
+ # test Decoder
+ decoder = Decoder(N, L)
+ est_mask = torch.randint(2, (B, K, C, N))
+ est_source = decoder(mixture_w, est_mask)
+ print('est_source', est_source)
+
+ # test Conv-TasNet
+ conv_tasnet = ConvTasNet(N, L, B, H, P, X, R, C, norm_type=norm_type)
+ est_source = conv_tasnet(mixture)
+ print('est_source', est_source)
+ print('est_source size', est_source.size())
diff --git a/demucs/test.py b/demucs/test.py
new file mode 100644
index 0000000..4140914
--- /dev/null
+++ b/demucs/test.py
@@ -0,0 +1,109 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import gzip
+import sys
+from concurrent import futures
+
+import musdb
+import museval
+import torch as th
+import tqdm
+from scipy.io import wavfile
+from torch import distributed
+
+from .audio import convert_audio
+from .utils import apply_model
+
+
+def evaluate(model,
+ musdb_path,
+ eval_folder,
+ workers=2,
+ device="cpu",
+ rank=0,
+ save=False,
+ shifts=0,
+ split=False,
+ overlap=0.25,
+ is_wav=False,
+ world_size=1):
+ """
+ Evaluate model using museval. Run the model
+ on a single GPU, the bottleneck being the call to museval.
+ """
+
+ output_dir = eval_folder / "results"
+ output_dir.mkdir(exist_ok=True, parents=True)
+ json_folder = eval_folder / "results/test"
+ json_folder.mkdir(exist_ok=True, parents=True)
+
+ # we load tracks from the original musdb set
+ test_set = musdb.DB(musdb_path, subsets=["test"], is_wav=is_wav)
+ src_rate = 44100 # hardcoded for now...
+
+ for p in model.parameters():
+ p.requires_grad = False
+ p.grad = None
+
+ pendings = []
+ with futures.ProcessPoolExecutor(workers or 1) as pool:
+ for index in tqdm.tqdm(range(rank, len(test_set), world_size), file=sys.stdout):
+ track = test_set.tracks[index]
+
+ out = json_folder / f"{track.name}.json.gz"
+ if out.exists():
+ continue
+
+ mix = th.from_numpy(track.audio).t().float()
+ ref = mix.mean(dim=0) # mono mixture
+ mix = (mix - ref.mean()) / ref.std()
+ mix = convert_audio(mix, src_rate, model.samplerate, model.audio_channels)
+ estimates = apply_model(model, mix.to(device),
+ shifts=shifts, split=split, overlap=overlap)
+ estimates = estimates * ref.std() + ref.mean()
+
+ estimates = estimates.transpose(1, 2)
+ references = th.stack(
+ [th.from_numpy(track.targets[name].audio).t() for name in model.sources])
+ references = convert_audio(references, src_rate,
+ model.samplerate, model.audio_channels)
+ references = references.transpose(1, 2).numpy()
+ estimates = estimates.cpu().numpy()
+ win = int(1. * model.samplerate)
+ hop = int(1. * model.samplerate)
+ if save:
+ folder = eval_folder / "wav/test" / track.name
+ folder.mkdir(exist_ok=True, parents=True)
+ for name, estimate in zip(model.sources, estimates):
+ wavfile.write(str(folder / (name + ".wav")), 44100, estimate)
+
+ if workers:
+ pendings.append((track.name, pool.submit(
+ museval.evaluate, references, estimates, win=win, hop=hop)))
+ else:
+ pendings.append((track.name, museval.evaluate(
+ references, estimates, win=win, hop=hop)))
+ del references, mix, estimates, track
+
+ for track_name, pending in tqdm.tqdm(pendings, file=sys.stdout):
+ if workers:
+ pending = pending.result()
+ sdr, isr, sir, sar = pending
+ track_store = museval.TrackStore(win=44100, hop=44100, track_name=track_name)
+ for idx, target in enumerate(model.sources):
+ values = {
+ "SDR": sdr[idx].tolist(),
+ "SIR": sir[idx].tolist(),
+ "ISR": isr[idx].tolist(),
+ "SAR": sar[idx].tolist()
+ }
+
+ track_store.add_target(target_name=target, values=values)
+ json_path = json_folder / f"{track_name}.json.gz"
+ gzip.open(json_path, "w").write(track_store.json.encode('utf-8'))
+ if world_size > 1:
+ distributed.barrier()
diff --git a/demucs/utils.py b/demucs/utils.py
new file mode 100644
index 0000000..4364184
--- /dev/null
+++ b/demucs/utils.py
@@ -0,0 +1,323 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import errno
+import functools
+import hashlib
+import inspect
+import io
+import os
+import random
+import socket
+import tempfile
+import warnings
+import zlib
+from contextlib import contextmanager
+
+from diffq import UniformQuantizer, DiffQuantizer
+import torch as th
+import tqdm
+from torch import distributed
+from torch.nn import functional as F
+
+
+def center_trim(tensor, reference):
+ """
+ Center trim `tensor` with respect to `reference`, along the last dimension.
+ `reference` can also be a number, representing the length to trim to.
+ If the size difference != 0 mod 2, the extra sample is removed on the right side.
+ """
+ if hasattr(reference, "size"):
+ reference = reference.size(-1)
+ delta = tensor.size(-1) - reference
+ if delta < 0:
+ raise ValueError("tensor must be larger than reference. " f"Delta is {delta}.")
+ if delta:
+ tensor = tensor[..., delta // 2:-(delta - delta // 2)]
+ return tensor
+
+
+def average_metric(metric, count=1.):
+ """
+ Average `metric` which should be a float across all hosts. `count` should be
+ the weight for this particular host (i.e. number of examples).
+ """
+ metric = th.tensor([count, count * metric], dtype=th.float32, device='cuda')
+ distributed.all_reduce(metric, op=distributed.ReduceOp.SUM)
+ return metric[1].item() / metric[0].item()
+
+
+def free_port(host='', low=20000, high=40000):
+ """
+ Return a port number that is most likely free.
+ This could suffer from a race condition although
+ it should be quite rare.
+ """
+ sock = socket.socket()
+ while True:
+ port = random.randint(low, high)
+ try:
+ sock.bind((host, port))
+ except OSError as error:
+ if error.errno == errno.EADDRINUSE:
+ continue
+ raise
+ return port
+
+
+def sizeof_fmt(num, suffix='B'):
+ """
+ Given `num` bytes, return human readable size.
+ Taken from https://stackoverflow.com/a/1094933
+ """
+ for unit in ['', 'Ki', 'Mi', 'Gi', 'Ti', 'Pi', 'Ei', 'Zi']:
+ if abs(num) < 1024.0:
+ return "%3.1f%s%s" % (num, unit, suffix)
+ num /= 1024.0
+ return "%.1f%s%s" % (num, 'Yi', suffix)
+
+
+def human_seconds(seconds, display='.2f'):
+ """
+ Given `seconds` seconds, return human readable duration.
+ """
+ value = seconds * 1e6
+ ratios = [1e3, 1e3, 60, 60, 24]
+ names = ['us', 'ms', 's', 'min', 'hrs', 'days']
+ last = names.pop(0)
+ for name, ratio in zip(names, ratios):
+ if value / ratio < 0.3:
+ break
+ value /= ratio
+ last = name
+ return f"{format(value, display)} {last}"
+
+
+class TensorChunk:
+ def __init__(self, tensor, offset=0, length=None):
+ total_length = tensor.shape[-1]
+ assert offset >= 0
+ assert offset < total_length
+
+ if length is None:
+ length = total_length - offset
+ else:
+ length = min(total_length - offset, length)
+
+ self.tensor = tensor
+ self.offset = offset
+ self.length = length
+ self.device = tensor.device
+
+ @property
+ def shape(self):
+ shape = list(self.tensor.shape)
+ shape[-1] = self.length
+ return shape
+
+ def padded(self, target_length):
+ delta = target_length - self.length
+ total_length = self.tensor.shape[-1]
+ assert delta >= 0
+
+ start = self.offset - delta // 2
+ end = start + target_length
+
+ correct_start = max(0, start)
+ correct_end = min(total_length, end)
+
+ pad_left = correct_start - start
+ pad_right = end - correct_end
+
+ out = F.pad(self.tensor[..., correct_start:correct_end], (pad_left, pad_right))
+ assert out.shape[-1] == target_length
+ return out
+
+
+def tensor_chunk(tensor_or_chunk):
+ if isinstance(tensor_or_chunk, TensorChunk):
+ return tensor_or_chunk
+ else:
+ assert isinstance(tensor_or_chunk, th.Tensor)
+ return TensorChunk(tensor_or_chunk)
+
+
+def apply_model(model, mix, shifts=None, split=False,
+ overlap=0.25, transition_power=1., progress=False):
+ """
+ Apply model to a given mixture.
+
+ Args:
+ shifts (int): if > 0, will shift in time `mix` by a random amount between 0 and 0.5 sec
+ and apply the oppositve shift to the output. This is repeated `shifts` time and
+ all predictions are averaged. This effectively makes the model time equivariant
+ and improves SDR by up to 0.2 points.
+ split (bool): if True, the input will be broken down in 8 seconds extracts
+ and predictions will be performed individually on each and concatenated.
+ Useful for model with large memory footprint like Tasnet.
+ progress (bool): if True, show a progress bar (requires split=True)
+ """
+ assert transition_power >= 1, "transition_power < 1 leads to weird behavior."
+ device = mix.device
+ channels, length = mix.shape
+ if split:
+ out = th.zeros(len(model.sources), channels, length, device=device)
+ sum_weight = th.zeros(length, device=device)
+ segment = model.segment_length
+ stride = int((1 - overlap) * segment)
+ offsets = range(0, length, stride)
+ scale = stride / model.samplerate
+ if progress:
+ offsets = tqdm.tqdm(offsets, unit_scale=scale, ncols=120, unit='seconds')
+ # We start from a triangle shaped weight, with maximal weight in the middle
+ # of the segment. Then we normalize and take to the power `transition_power`.
+ # Large values of transition power will lead to sharper transitions.
+ weight = th.cat([th.arange(1, segment // 2 + 1),
+ th.arange(segment - segment // 2, 0, -1)]).to(device)
+ assert len(weight) == segment
+ # If the overlap < 50%, this will translate to linear transition when
+ # transition_power is 1.
+ weight = (weight / weight.max())**transition_power
+ for offset in offsets:
+ chunk = TensorChunk(mix, offset, segment)
+ chunk_out = apply_model(model, chunk, shifts=shifts)
+ chunk_length = chunk_out.shape[-1]
+ out[..., offset:offset + segment] += weight[:chunk_length] * chunk_out
+ sum_weight[offset:offset + segment] += weight[:chunk_length]
+ offset += segment
+ assert sum_weight.min() > 0
+ out /= sum_weight
+ return out
+ elif shifts:
+ max_shift = int(0.5 * model.samplerate)
+ mix = tensor_chunk(mix)
+ padded_mix = mix.padded(length + 2 * max_shift)
+ out = 0
+ for _ in range(shifts):
+ offset = random.randint(0, max_shift)
+ shifted = TensorChunk(padded_mix, offset, length + max_shift - offset)
+ shifted_out = apply_model(model, shifted)
+ out += shifted_out[..., max_shift - offset:]
+ out /= shifts
+ return out
+ else:
+ valid_length = model.valid_length(length)
+ mix = tensor_chunk(mix)
+ padded_mix = mix.padded(valid_length)
+ with th.no_grad():
+ out = model(padded_mix.unsqueeze(0))[0]
+ return center_trim(out, length)
+
+
+@contextmanager
+def temp_filenames(count, delete=True):
+ names = []
+ try:
+ for _ in range(count):
+ names.append(tempfile.NamedTemporaryFile(delete=False).name)
+ yield names
+ finally:
+ if delete:
+ for name in names:
+ os.unlink(name)
+
+
+def get_quantizer(model, args, optimizer=None):
+ quantizer = None
+ if args.diffq:
+ quantizer = DiffQuantizer(
+ model, min_size=args.q_min_size, group_size=8)
+ if optimizer is not None:
+ quantizer.setup_optimizer(optimizer)
+ elif args.qat:
+ quantizer = UniformQuantizer(
+ model, bits=args.qat, min_size=args.q_min_size)
+ return quantizer
+
+
+def load_model(path, strict=False):
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ load_from = path
+ package = th.load(load_from, 'cpu')
+
+ klass = package["klass"]
+ args = package["args"]
+ kwargs = package["kwargs"]
+
+ if strict:
+ model = klass(*args, **kwargs)
+ else:
+ sig = inspect.signature(klass)
+ for key in list(kwargs):
+ if key not in sig.parameters:
+ warnings.warn("Dropping inexistant parameter " + key)
+ del kwargs[key]
+ model = klass(*args, **kwargs)
+
+ state = package["state"]
+ training_args = package["training_args"]
+ quantizer = get_quantizer(model, training_args)
+
+ set_state(model, quantizer, state)
+ return model
+
+
+def get_state(model, quantizer):
+ if quantizer is None:
+ state = {k: p.data.to('cpu') for k, p in model.state_dict().items()}
+ else:
+ state = quantizer.get_quantized_state()
+ buf = io.BytesIO()
+ th.save(state, buf)
+ state = {'compressed': zlib.compress(buf.getvalue())}
+ return state
+
+
+def set_state(model, quantizer, state):
+ if quantizer is None:
+ model.load_state_dict(state)
+ else:
+ buf = io.BytesIO(zlib.decompress(state["compressed"]))
+ state = th.load(buf, "cpu")
+ quantizer.restore_quantized_state(state)
+
+ return state
+
+
+def save_state(state, path):
+ buf = io.BytesIO()
+ th.save(state, buf)
+ sig = hashlib.sha256(buf.getvalue()).hexdigest()[:8]
+
+ path = path.parent / (path.stem + "-" + sig + path.suffix)
+ path.write_bytes(buf.getvalue())
+
+
+def save_model(model, quantizer, training_args, path):
+ args, kwargs = model._init_args_kwargs
+ klass = model.__class__
+
+ state = get_state(model, quantizer)
+
+ save_to = path
+ package = {
+ 'klass': klass,
+ 'args': args,
+ 'kwargs': kwargs,
+ 'state': state,
+ 'training_args': training_args,
+ }
+ th.save(package, save_to)
+
+
+def capture_init(init):
+ @functools.wraps(init)
+ def __init__(self, *args, **kwargs):
+ self._init_args_kwargs = (args, kwargs)
+ init(self, *args, **kwargs)
+
+ return __init__
diff --git a/demucs/wav.py b/demucs/wav.py
new file mode 100644
index 0000000..a65c3b2
--- /dev/null
+++ b/demucs/wav.py
@@ -0,0 +1,174 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from collections import OrderedDict
+import hashlib
+import math
+import json
+from pathlib import Path
+
+import julius
+import torch as th
+from torch import distributed
+import torchaudio as ta
+from torch.nn import functional as F
+
+from .audio import convert_audio_channels
+from .compressed import get_musdb_tracks
+
+MIXTURE = "mixture"
+EXT = ".wav"
+
+
+def _track_metadata(track, sources):
+ track_length = None
+ track_samplerate = None
+ for source in sources + [MIXTURE]:
+ file = track / f"{source}{EXT}"
+ info = ta.info(str(file))
+ length = info.num_frames
+ if track_length is None:
+ track_length = length
+ track_samplerate = info.sample_rate
+ elif track_length != length:
+ raise ValueError(
+ f"Invalid length for file {file}: "
+ f"expecting {track_length} but got {length}.")
+ elif info.sample_rate != track_samplerate:
+ raise ValueError(
+ f"Invalid sample rate for file {file}: "
+ f"expecting {track_samplerate} but got {info.sample_rate}.")
+ if source == MIXTURE:
+ wav, _ = ta.load(str(file))
+ wav = wav.mean(0)
+ mean = wav.mean().item()
+ std = wav.std().item()
+
+ return {"length": length, "mean": mean, "std": std, "samplerate": track_samplerate}
+
+
+def _build_metadata(path, sources):
+ meta = {}
+ path = Path(path)
+ for file in path.iterdir():
+ meta[file.name] = _track_metadata(file, sources)
+ return meta
+
+
+class Wavset:
+ def __init__(
+ self,
+ root, metadata, sources,
+ length=None, stride=None, normalize=True,
+ samplerate=44100, channels=2):
+ """
+ Waveset (or mp3 set for that matter). Can be used to train
+ with arbitrary sources. Each track should be one folder inside of `path`.
+ The folder should contain files named `{source}.{ext}`.
+ Files will be grouped according to `sources` (each source is a list of
+ filenames).
+
+ Sample rate and channels will be converted on the fly.
+
+ `length` is the sample size to extract (in samples, not duration).
+ `stride` is how many samples to move by between each example.
+ """
+ self.root = Path(root)
+ self.metadata = OrderedDict(metadata)
+ self.length = length
+ self.stride = stride or length
+ self.normalize = normalize
+ self.sources = sources
+ self.channels = channels
+ self.samplerate = samplerate
+ self.num_examples = []
+ for name, meta in self.metadata.items():
+ track_length = int(self.samplerate * meta['length'] / meta['samplerate'])
+ if length is None or track_length < length:
+ examples = 1
+ else:
+ examples = int(math.ceil((track_length - self.length) / self.stride) + 1)
+ self.num_examples.append(examples)
+
+ def __len__(self):
+ return sum(self.num_examples)
+
+ def get_file(self, name, source):
+ return self.root / name / f"{source}{EXT}"
+
+ def __getitem__(self, index):
+ for name, examples in zip(self.metadata, self.num_examples):
+ if index >= examples:
+ index -= examples
+ continue
+ meta = self.metadata[name]
+ num_frames = -1
+ offset = 0
+ if self.length is not None:
+ offset = int(math.ceil(
+ meta['samplerate'] * self.stride * index / self.samplerate))
+ num_frames = int(math.ceil(
+ meta['samplerate'] * self.length / self.samplerate))
+ wavs = []
+ for source in self.sources:
+ file = self.get_file(name, source)
+ wav, _ = ta.load(str(file), frame_offset=offset, num_frames=num_frames)
+ wav = convert_audio_channels(wav, self.channels)
+ wavs.append(wav)
+
+ example = th.stack(wavs)
+ example = julius.resample_frac(example, meta['samplerate'], self.samplerate)
+ if self.normalize:
+ example = (example - meta['mean']) / meta['std']
+ if self.length:
+ example = example[..., :self.length]
+ example = F.pad(example, (0, self.length - example.shape[-1]))
+ return example
+
+
+def get_wav_datasets(args, samples, sources):
+ sig = hashlib.sha1(str(args.wav).encode()).hexdigest()[:8]
+ metadata_file = args.metadata / (sig + ".json")
+ train_path = args.wav / "train"
+ valid_path = args.wav / "valid"
+ if not metadata_file.is_file() and args.rank == 0:
+ train = _build_metadata(train_path, sources)
+ valid = _build_metadata(valid_path, sources)
+ json.dump([train, valid], open(metadata_file, "w"))
+ if args.world_size > 1:
+ distributed.barrier()
+ train, valid = json.load(open(metadata_file))
+ train_set = Wavset(train_path, train, sources,
+ length=samples, stride=args.data_stride,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ valid_set = Wavset(valid_path, valid, [MIXTURE] + sources,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ return train_set, valid_set
+
+
+def get_musdb_wav_datasets(args, samples, sources):
+ metadata_file = args.metadata / "musdb_wav.json"
+ root = args.musdb / "train"
+ if not metadata_file.is_file() and args.rank == 0:
+ metadata = _build_metadata(root, sources)
+ json.dump(metadata, open(metadata_file, "w"))
+ if args.world_size > 1:
+ distributed.barrier()
+ metadata = json.load(open(metadata_file))
+
+ train_tracks = get_musdb_tracks(args.musdb, is_wav=True, subsets=["train"], split="train")
+ metadata_train = {name: meta for name, meta in metadata.items() if name in train_tracks}
+ metadata_valid = {name: meta for name, meta in metadata.items() if name not in train_tracks}
+ train_set = Wavset(root, metadata_train, sources,
+ length=samples, stride=args.data_stride,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ valid_set = Wavset(root, metadata_valid, [MIXTURE] + sources,
+ samplerate=args.samplerate, channels=args.audio_channels,
+ normalize=args.norm_wav)
+ return train_set, valid_set
diff --git a/diffq/__init__.py b/diffq/__init__.py
new file mode 100644
index 0000000..2b997ee
--- /dev/null
+++ b/diffq/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+# flake8: noqa
+"""
+This package implements different quantization strategies:
+
+- `diffq.uniform.UniformQuantizer`: classic uniform quantization over n bits.
+- `diffq.diffq.DiffQuantizer`: differentiable quantizer based on scaled noise injection.
+
+Also, do check `diffq.base.BaseQuantizer` for the common methods of all Quantizers.
+"""
+
+from .uniform import UniformQuantizer
+from .diffq import DiffQuantizer
diff --git a/diffq/base.py b/diffq/base.py
new file mode 100644
index 0000000..9bd5276
--- /dev/null
+++ b/diffq/base.py
@@ -0,0 +1,262 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from dataclasses import dataclass
+from concurrent import futures
+from fnmatch import fnmatch
+from functools import partial
+import io
+import math
+from multiprocessing import cpu_count
+import typing as tp
+import zlib
+
+import torch
+
+
+class BaseQuantizer:
+ @dataclass
+ class _QuantizedParam:
+ name: str
+ param: torch.nn.Parameter
+ module: torch.nn.Module
+ # If a Parameter is used multiple times, `other` can be used
+ # to share state between the different Quantizers
+ other: tp.Optional[tp.Any]
+
+ def __init__(self, model: torch.nn.Module, min_size: float = 0.01, float16: bool = False,
+ exclude: tp.Optional[tp.List[str]] = [], detect_bound: bool = True):
+ self.model = model
+ self.min_size = min_size
+ self.float16 = float16
+ self.exclude = exclude
+ self.detect_bound = detect_bound
+ self._quantized = False
+ self._pre_handle = self.model.register_forward_pre_hook(self._forward_pre_hook)
+ self._post_handle = self.model.register_forward_hook(self._forward_hook)
+
+ self._quantized_state = None
+ self._qparams = []
+ self._float16 = []
+ self._others = []
+ self._rnns = []
+
+ self._saved = []
+
+ self._find_params()
+
+ def _find_params(self):
+ min_params = self.min_size * 2**20 // 4
+ previous = {}
+ for module_name, module in self.model.named_modules():
+ if isinstance(module, torch.nn.RNNBase):
+ self._rnns.append(module)
+ for name, param in list(module.named_parameters(recurse=False)):
+ full_name = f"{module_name}.{name}"
+ matched = False
+ for pattern in self.exclude:
+ if fnmatch(full_name, pattern) or fnmatch(name, pattern):
+ matched = True
+ break
+
+ if param.numel() <= min_params or matched:
+ if id(param) in previous:
+ continue
+ if self.detect_bound:
+ previous[id(param)] = None
+ if self.float16:
+ self._float16.append(param)
+ else:
+ self._others.append(param)
+ else:
+ qparam = self._register_param(name, param, module, previous.get(id(param)))
+ if self.detect_bound:
+ previous[id(param)] = qparam
+ self._qparams.append(qparam)
+
+ def _register_param(self, name, param, module, other):
+ return self.__class__._QuantizedParam(name, param, module, other)
+
+ def _forward_pre_hook(self, module, input):
+ if self.model.training:
+ self._quantized_state = None
+ if self._quantized:
+ self.unquantize()
+ if self._pre_forward_train():
+ self._fix_rnns()
+ else:
+ self.quantize()
+
+ def _forward_hook(self, module, input, output):
+ if self.model.training:
+ if self._post_forward_train():
+ self._fix_rnns(flatten=False) # Hacky, next forward will flatten
+
+ def quantize(self, save=True):
+ """
+ Immediately apply quantization to the model parameters.
+ If `save` is True, save a copy of the unquantized parameters, that can be
+ restored with `unquantize()`.
+ """
+ if self._quantized:
+ return
+ if save:
+ self._saved = [qp.param.data.to('cpu', copy=True)
+ for qp in self._qparams if qp.other is None]
+ self.restore_quantized_state(self.get_quantized_state())
+ self._quantized = True
+ self._fix_rnns()
+
+ def unquantize(self):
+ """
+ Revert a previous call to `quantize()`.
+ """
+ if not self._quantized:
+ raise RuntimeError("Can only be called on a quantized model.")
+ if not self._saved:
+ raise RuntimeError("Nothing to restore.")
+ for qparam in self._qparams:
+ if qparam.other is None:
+ qparam.param.data[:] = self._saved.pop(0)
+ assert len(self._saved) == 0
+ self._quantized = False
+ self._fix_rnns()
+
+ def _pre_forward_train(self) -> bool:
+ """
+ Called once before each forward for continuous quantization.
+ Should return True if parameters were changed.
+ """
+ return False
+
+ def _post_forward_train(self) -> bool:
+ """
+ Called once after each forward (to restore state for instance).
+ Should return True if parameters were changed.
+ """
+ return False
+
+ def _fix_rnns(self, flatten=True):
+ """
+ To be called after quantization happened to fix RNNs.
+ """
+ for rnn in self._rnns:
+ rnn._flat_weights = [
+ (lambda wn: getattr(rnn, wn) if hasattr(rnn, wn) else None)(wn)
+ for wn in rnn._flat_weights_names]
+ if flatten:
+ rnn.flatten_parameters()
+
+ def get_quantized_state(self):
+ """
+ Returns sufficient quantized information to rebuild the model state.
+
+ ..Note::
+ To achieve maximum compression, you should compress this with
+ gzip or other, as quantized weights are not optimally coded!
+ """
+ if self._quantized_state is None:
+ self._quantized_state = self._get_quantized_state()
+ return self._quantized_state
+
+ def _get_quantized_state(self):
+ """
+ Actual implementation for `get_quantized_state`.
+ """
+ float16_params = []
+ for p in self._float16:
+ q = p.data.half()
+ float16_params.append(q)
+
+ return {
+ "quantized": [self._quantize_param(qparam) for qparam in self._qparams
+ if qparam.other is None],
+ "float16": float16_params,
+ "others": [p.data.clone() for p in self._others],
+ }
+
+ def _quantize_param(self, qparam: _QuantizedParam) -> tp.Any:
+ """
+ To be overriden.
+ """
+ raise NotImplementedError()
+
+ def _unquantize_param(self, qparam: _QuantizedParam, quantized: tp.Any) -> torch.Tensor:
+ """
+ To be overriden.
+ """
+ raise NotImplementedError()
+
+ def restore_quantized_state(self, state) -> None:
+ """
+ Restore the state of the model from the quantized state.
+ """
+ for p, q in zip(self._float16, state["float16"]):
+ p.data[:] = q.to(p)
+
+ for p, q in zip(self._others, state["others"]):
+ p.data[:] = q
+
+ remaining = list(state["quantized"])
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ # Only unquantize first appearance of nn.Parameter.
+ continue
+ quantized = remaining.pop(0)
+ qparam.param.data[:] = self._unquantize_param(qparam, quantized)
+ self._fix_rnns()
+
+ def detach(self) -> None:
+ """
+ Detach from the model, removes hooks and anything else.
+ """
+ self._pre_handle.remove()
+ self._post_handle.remove()
+
+ def model_size(self) -> torch.Tensor:
+ """
+ Returns an estimate of the quantized model size.
+ """
+ total = torch.tensor(0.)
+ for p in self._float16:
+ total += 16 * p.numel()
+ for p in self._others:
+ total += 32 * p.numel()
+ return total / 2**20 / 8 # bits to MegaBytes
+
+ def true_model_size(self) -> float:
+ """
+ Return the true quantized model size, in MB, without extra
+ compression.
+ """
+ return self.model_size().item()
+
+ def compressed_model_size(self, compress_level=-1, num_workers=8) -> float:
+ """
+ Return the compressed quantized model size, in MB.
+
+ Args:
+ compress_level (int): compression level used with zlib,
+ see `zlib.compress` for details.
+ num_workers (int): will split the final big byte representation in that
+ many chunks processed in parallels.
+ """
+ out = io.BytesIO()
+ torch.save(self.get_quantized_state(), out)
+ ms = _parallel_compress_len(out.getvalue(), compress_level, num_workers)
+ return ms / 2 ** 20
+
+
+def _compress_len(data, compress_level):
+ return len(zlib.compress(data, level=compress_level))
+
+
+def _parallel_compress_len(data, compress_level, num_workers):
+ num_workers = min(cpu_count(), num_workers)
+ chunk_size = int(math.ceil(len(data) / num_workers))
+ chunks = [data[offset:offset + chunk_size] for offset in range(0, len(data), chunk_size)]
+ with futures.ProcessPoolExecutor(num_workers) as pool:
+ return sum(pool.map(partial(_compress_len, compress_level=compress_level), chunks))
diff --git a/diffq/diffq.py b/diffq/diffq.py
new file mode 100644
index 0000000..b475ec7
--- /dev/null
+++ b/diffq/diffq.py
@@ -0,0 +1,286 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+"""
+Differentiable quantizer based on scaled noise injection.
+"""
+from dataclasses import dataclass
+import math
+import typing as tp
+
+import torch
+
+from .base import BaseQuantizer
+from .uniform import uniform_quantize, uniform_unquantize
+from .utils import simple_repr
+
+
+class DiffQuantizer(BaseQuantizer):
+ @dataclass
+ class _QuantizedParam(BaseQuantizer._QuantizedParam):
+ logit: torch.nn.Parameter
+
+ def __init__(self, model: torch.nn.Module, min_size: float = 0.01, float16: bool = False,
+ group_size: int = 1, min_bits: float = 2, max_bits: float = 15,
+ param="bits", noise="gaussian",
+ init_bits: float = 8, extra_bits: float = 0, suffix: str = "_diffq",
+ exclude: tp.List[str] = [], detect_bound: bool = True):
+ """
+ Differentiable quantizer based on scaled noise injection.
+ For every parameter `p` in the model, this introduces a number of bits parameter
+ `b` with the same dimensions (when group_size = 1).
+ Before each forward, `p` is replaced by `p + U`
+ with U uniform iid noise with range [-d/2, d/2], with `d` the uniform quantization
+ step for `b` bits.
+ This noise approximates the quantization noise in a differentiable manner, both
+ with respect to the unquantized parameter `p` and the number of bits `b`.
+
+ At eveluation (as detected with `model.eval()`), the model is replaced
+ by its true quantized version, and restored when going back to training.
+
+ When doing actual quantization (for serialization, or evaluation),
+ the number of bits is rounded to the nearest integer, and needs to be stored along.
+ This will cost a few bits per dimension. To reduce this cost, one can use `group_size`,
+ which will use a single noise level for multiple weight entries.
+
+ You can use the `DiffQuantizer.model_size` method to get a differentiable estimate of the
+ model size in MB. You can then use this estimate as a penalty in your training loss.
+
+ Args:
+ model (torch.nn.Module): model to quantize
+ min_size (float): minimum size in MB of a parameter to be quantized.
+ float16 (bool): if a layer is smaller than min_size, should we still do float16?
+ group_size (int): weight entries are groupped together to reduce the number
+ of noise scales to store. This should divide the size of all parameters
+ bigger than min_size.
+ min_bits (float): minimal number of bits.
+ max_bits (float): maximal number of bits.
+ init_bits (float): initial number of bits.
+ extra_bits (float): extra bits to add for actual quantization (before roundoff).
+ suffix (str): suffix used for the name of the extra noise scale parameters.
+ exclude (list[str]): list of patterns used to match parameters to exclude.
+ For instance `['bias']` to exclude all bias terms.
+ detect_bound (bool): if True, will detect bound parameters and reuse
+ the same quantized tensor for both, as well as the same number of bits.
+
+ ..Warning::
+ You must call `model.training()` and `model.eval()` for `DiffQuantizer` work properly.
+
+ """
+ self.group_size = group_size
+ self.min_bits = min_bits
+ self.max_bits = max_bits
+ self.init_bits = init_bits
+ self.extra_bits = extra_bits
+ self.suffix = suffix
+ self.param = param
+ self.noise = noise
+ assert noise in ["gaussian", "uniform"]
+ self._optimizer_setup = False
+
+ self._min_noise = 1 / (2 ** self.max_bits - 1)
+ self._max_noise = 1 / (2 ** self.min_bits - 1)
+
+ assert group_size >= 0
+ assert min_bits < init_bits < max_bits, \
+ "init_bits must be between min_bits and max_bits excluded3"
+
+ for name, _ in model.named_parameters():
+ if name.endswith(suffix):
+ raise RuntimeError("The model already has some noise scales parameters, "
+ "maybe you used twice a DiffQuantizer on the same model?.")
+
+ super().__init__(model, min_size, float16, exclude, detect_bound)
+
+ def _get_bits(self, logit: torch.Tensor):
+ if self.param == "noise":
+ return torch.log2(1 + 1 / self._get_noise_scale(logit))
+ else:
+ t = torch.sigmoid(logit)
+ return self.max_bits * t + (1 - t) * self.min_bits
+
+ def _get_noise_scale(self, logit: torch.Tensor):
+ if self.param == "noise":
+ t = torch.sigmoid(logit)
+ return torch.exp(t * math.log(self._min_noise) + (1 - t) * math.log(self._max_noise))
+ else:
+ return 1 / (2 ** self._get_bits(logit) - 1)
+
+ def _register_param(self, name, param, module, other):
+ if other is not None:
+ return self.__class__._QuantizedParam(
+ name=name, param=param, module=module, logit=other.logit, other=other)
+ assert self.group_size == 0 or param.numel() % self.group_size == 0
+ # we want the initial number of bits to be init_bits.
+ if self.param == "noise":
+ noise_scale = 1 / (2 ** self.init_bits - 1)
+ t = (math.log(noise_scale) - math.log(self._max_noise)) / (
+ math.log(self._min_noise) - math.log(self._max_noise))
+ else:
+ t = (self.init_bits - self.min_bits) / (self.max_bits - self.min_bits)
+ assert 0 < t < 1
+ logit = torch.logit(torch.tensor(float(t)))
+ assert abs(self._get_bits(logit) - self.init_bits) < 1e-5
+ if self.group_size > 0:
+ nparam = param.numel() // self.group_size
+ else:
+ nparam = 1
+ logit = torch.nn.Parameter(
+ torch.full(
+ (nparam,),
+ logit,
+ device=param.device))
+ module.register_parameter(name + self.suffix, logit)
+ return self.__class__._QuantizedParam(
+ name=name, param=param, module=module, logit=logit, other=None)
+
+ def clear_optimizer(self, optimizer: torch.optim.Optimizer):
+ params = [qp.logit for qp in self._qparams]
+
+ for group in optimizer.param_groups:
+ new_params = []
+ for q in list(group["params"]):
+ matched = False
+ for p in params:
+ if p is q:
+ matched = True
+ if not matched:
+ new_params.append(q)
+ group["params"][:] = new_params
+
+ def setup_optimizer(self, optimizer: torch.optim.Optimizer,
+ lr: float = 1e-3, **kwargs):
+ """
+ Setup the optimizer to tune the number of bits. In particular, this will deactivate
+ weight decay for the bits parameters.
+
+ Args:
+ optimizer (torch.Optimizer): optimizer to use.
+ lr (float): specific learning rate for the bits parameters. 1e-3
+ is perfect for Adam.,w
+ kwargs (dict): overrides for other optimization parameters for the bits.
+ """
+ assert not self._optimizer_setup
+ self._optimizer_setup = True
+
+ params = [qp.logit for qp in self._qparams]
+
+ for group in optimizer.param_groups:
+ for q in list(group["params"]):
+ for p in params:
+ if p is q:
+ raise RuntimeError("You should create the optimizer "
+ "before the quantizer!")
+
+ group = {"params": params, "lr": lr, "weight_decay": 0}
+ group.update(kwargs)
+ optimizer.add_param_group(group)
+
+ def no_optimizer(self):
+ """
+ Call this if you do not want to use an optimizer.
+ """
+ self._optimizer_setup = True
+
+ def check_unused(self):
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ continue
+ grad = qparam.param.grad
+ if grad is None or (grad == 0).all():
+ if qparam.logit.grad is not None:
+ qparam.logit.grad.data.zero_()
+
+ def model_size(self, exact=False):
+ """
+ Differentiable estimate of the model size.
+ The size is returned in MB.
+
+ If `exact` is True, then the output is no longer differentiable but
+ reflect exactly an achievable size, even without compression,
+ i.e.same as returned by `naive_model_size()`.
+ """
+ total = super().model_size()
+ subtotal = 0
+ for qparam in self._qparams:
+ # only count the first appearance of a Parameter
+ if qparam.other is not None:
+ continue
+ bits = self.extra_bits + self._get_bits(qparam.logit)
+ if exact:
+ bits = bits.round().clamp(1, 15)
+ if self.group_size == 0:
+ group_size = qparam.param.numel()
+ else:
+ group_size = self.group_size
+ subtotal += group_size * bits.sum()
+ subtotal += 2 * 32 # param scale
+
+ # Number of bits to represent each number of bits
+ bits_bits = math.ceil(math.log2(1 + (bits.max().round().item() - self.min_bits)))
+ subtotal += 8 # 8 bits for bits_bits
+ subtotal += bits_bits * bits.numel()
+
+ subtotal /= 2 ** 20 * 8 # bits -> MegaBytes
+ return total + subtotal
+
+ def true_model_size(self):
+ """
+ Naive model size without zlib compression.
+ """
+ return self.model_size(exact=True).item()
+
+ def _pre_forward_train(self):
+ if not self._optimizer_setup:
+ raise RuntimeError("You must call `setup_optimizer()` on your optimizer "
+ "before starting training.")
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ noisy = qparam.other.module._parameters[qparam.other.name]
+ else:
+ bits = self._get_bits(qparam.logit)[:, None]
+ if self.group_size == 0:
+ p_flat = qparam.param.view(-1)
+ else:
+ p_flat = qparam.param.view(-1, self.group_size)
+ scale = p_flat.max() - p_flat.min()
+ unit = 1 / (2**bits - 1)
+ if self.noise == "uniform":
+ noise_source = (torch.rand_like(p_flat) - 0.5)
+ elif self.noise == "gaussian":
+ noise_source = torch.randn_like(p_flat) / 2
+ noise = scale * unit * noise_source
+ noisy = p_flat + noise
+ # We bypass the checks by PyTorch on parameters being leafs
+ qparam.module._parameters[qparam.name] = noisy.view_as(qparam.param)
+ return True
+
+ def _post_forward_train(self):
+ for qparam in self._qparams:
+ qparam.module._parameters[qparam.name] = qparam.param
+ return True
+
+ def _quantize_param(self, qparam: _QuantizedParam) -> tp.Any:
+ bits = self.extra_bits + self._get_bits(qparam.logit)
+ bits = bits.round().clamp(1, 15)[:, None].byte()
+ if self.group_size == 0:
+ p = qparam.param.data.view(-1)
+ else:
+ p = qparam.param.data.view(-1, self.group_size)
+ levels, scales = uniform_quantize(p, bits)
+ return levels, scales, bits
+
+ def _unquantize_param(self, qparam: _QuantizedParam, quantized: tp.Any) -> torch.Tensor:
+ levels, param_scale, bits = quantized
+ return uniform_unquantize(levels, param_scale, bits).view_as(qparam.param.data)
+
+ def detach(self):
+ super().detach()
+ for qparam in self._qparams:
+ delattr(qparam.module, qparam.name + self.suffix)
+
+ def __repr__(self):
+ return simple_repr(self)
diff --git a/diffq/uniform.py b/diffq/uniform.py
new file mode 100644
index 0000000..f61e912
--- /dev/null
+++ b/diffq/uniform.py
@@ -0,0 +1,121 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+"""
+Classic uniform quantization over n bits.
+"""
+from typing import Tuple
+import torch
+
+from .base import BaseQuantizer
+from .utils import simple_repr
+
+
+def uniform_quantize(p: torch.Tensor, bits: torch.Tensor = torch.tensor(8.)):
+ """
+ Quantize the given weights over `bits` bits.
+
+ Returns:
+ - quantized levels
+ - (min, max) range.
+
+ """
+ assert (bits >= 1).all() and (bits <= 15).all()
+ num_levels = (2 ** bits.float()).long()
+ mn = p.min().item()
+ mx = p.max().item()
+ p = (p - mn) / (mx - mn) # put p in [0, 1]
+ unit = 1 / (num_levels - 1) # quantization unit
+ levels = (p / unit).round()
+ if (bits <= 8).all():
+ levels = levels.byte()
+ else:
+ levels = levels.short()
+ return levels, (mn, mx)
+
+
+def uniform_unquantize(levels: torch.Tensor, scales: Tuple[float, float],
+ bits: torch.Tensor = torch.tensor(8.)):
+ """
+ Unquantize the weights from the levels and scale. Return a float32 tensor.
+ """
+ mn, mx = scales
+ num_levels = 2 ** bits.float()
+ unit = 1 / (num_levels - 1)
+ levels = levels.float()
+ p = levels * unit # in [0, 1]
+ return p * (mx - mn) + mn
+
+
+class UniformQuantizer(BaseQuantizer):
+ def __init__(self, model: torch.nn.Module, bits: float = 8., min_size: float = 0.01,
+ float16: bool = False, qat: bool = False, exclude=[], detect_bound=True):
+ """
+ Args:
+ model (torch.nn.Module): model to quantize
+ bits (float): number of bits to quantize over.
+ min_size (float): minimum size in MB of a parameter to be quantized.
+ float16 (bool): if a layer is smaller than min_size, should we still do float16?
+ qat (bool): perform quantized aware training.
+ exclude (list[str]): list of patterns used to match parameters to exclude.
+ For instance `['bias']` to exclude all bias terms.
+ detect_bound (bool): if True, will detect bound parameters and reuse
+ the same quantized tensor for both.
+ """
+ self.bits = float(bits)
+ self.qat = qat
+
+ super().__init__(model, min_size, float16, exclude, detect_bound)
+
+ def __repr__(self):
+ return simple_repr(self, )
+
+ def _pre_forward_train(self):
+ if self.qat:
+ for qparam in self._qparams:
+ if qparam.other is not None:
+ new_param = qparam.other.module._parameters[qparam.other.name]
+ else:
+ quantized = self._quantize_param(qparam)
+ qvalue = self._unquantize_param(qparam, quantized)
+ new_param = qparam.param + (qvalue - qparam.param).detach()
+ qparam.module._parameters[qparam.name] = new_param
+ return True
+ return False
+
+ def _post_forward_train(self):
+ if self.qat:
+ for qparam in self._qparams:
+ qparam.module._parameters[qparam.name] = qparam.param
+ return True
+ return False
+
+ def _quantize_param(self, qparam):
+ levels, scales = uniform_quantize(qparam.param.data, torch.tensor(self.bits))
+ return (levels, scales)
+
+ def _unquantize_param(self, qparam, quantized):
+ levels, scales = quantized
+ return uniform_unquantize(levels, scales, torch.tensor(self.bits))
+
+ def model_size(self):
+ """
+ Non differentiable model size in MB.
+ """
+ total = super().model_size()
+ subtotal = 0
+ for qparam in self._qparams:
+ if qparam.other is None: # if parameter is bound, count only one copy.
+ subtotal += self.bits * qparam.param.numel() + 64 # 2 float for the overall scales
+ subtotal /= 2**20 * 8 # bits to MegaBytes
+ return total + subtotal
+
+ def true_model_size(self):
+ """
+ Return the true quantized model size, in MB, without extra
+ compression.
+ """
+ return self.model_size().item()
diff --git a/diffq/utils.py b/diffq/utils.py
new file mode 100644
index 0000000..be6ab52
--- /dev/null
+++ b/diffq/utils.py
@@ -0,0 +1,37 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import inspect
+from typing import Optional, List
+
+
+def simple_repr(obj, attrs: Optional[List[str]] = None, overrides={}):
+ """
+ Return a simple representation string for `obj`.
+ If `attrs` is not None, it should be a list of attributes to include.
+ """
+ params = inspect.signature(obj.__class__).parameters
+ attrs_repr = []
+ if attrs is None:
+ attrs = params.keys()
+ for attr in attrs:
+ display = False
+ if attr in overrides:
+ value = overrides[attr]
+ elif hasattr(obj, attr):
+ value = getattr(obj, attr)
+ else:
+ continue
+ if attr in params:
+ param = params[attr]
+ if param.default is inspect._empty or value != param.default:
+ display = True
+ else:
+ display = True
+
+ if display:
+ attrs_repr.append(f"{attr}={value}")
+ return f"{obj.__class__.__name__}({','.join(attrs_repr)})"
diff --git a/img/File.png b/img/File.png
new file mode 100644
index 0000000..f0efc7d
Binary files /dev/null and b/img/File.png differ
diff --git a/img/GUI-Icon.png b/img/GUI-Icon.png
new file mode 100644
index 0000000..302bee1
Binary files /dev/null and b/img/GUI-Icon.png differ
diff --git a/img/UVR-Icon-v2.ico b/img/UVR-Icon-v2.ico
new file mode 100644
index 0000000..1c9d5d0
Binary files /dev/null and b/img/UVR-Icon-v2.ico differ
diff --git a/img/UVR-Icon.ico b/img/UVR-Icon.ico
index 944b30e..c3169b9 100644
Binary files a/img/UVR-Icon.ico and b/img/UVR-Icon.ico differ
diff --git a/img/UVR-banner-2.png b/img/UVR-banner-2.png
deleted file mode 100644
index 4819e91..0000000
Binary files a/img/UVR-banner-2.png and /dev/null differ
diff --git a/img/UVR-banner.png b/img/UVR-banner.png
index 768498a..8d96dfd 100644
Binary files a/img/UVR-banner.png and b/img/UVR-banner.png differ
diff --git a/img/UVRV52.png b/img/UVRV52.png
deleted file mode 100644
index 24038bd..0000000
Binary files a/img/UVRV52.png and /dev/null differ
diff --git a/img/UVRv5.png b/img/UVRv5.png
new file mode 100644
index 0000000..09f7486
Binary files /dev/null and b/img/UVRv5.png differ
diff --git a/img/credits.png b/img/credits.png
new file mode 100644
index 0000000..f32a494
Binary files /dev/null and b/img/credits.png differ
diff --git a/img/ense_opt.png b/img/ense_opt.png
new file mode 100644
index 0000000..7e3889d
Binary files /dev/null and b/img/ense_opt.png differ
diff --git a/img/file.png b/img/file.png
deleted file mode 100644
index e6c2a78..0000000
Binary files a/img/file.png and /dev/null differ
diff --git a/img/gen_opt.png b/img/gen_opt.png
new file mode 100644
index 0000000..decafa5
Binary files /dev/null and b/img/gen_opt.png differ
diff --git a/img/help.png b/img/help.png
new file mode 100644
index 0000000..411803a
Binary files /dev/null and b/img/help.png differ
diff --git a/img/icon.png b/img/icon.png
new file mode 100644
index 0000000..c43f125
Binary files /dev/null and b/img/icon.png differ
diff --git a/img/mdx_opt.png b/img/mdx_opt.png
new file mode 100644
index 0000000..3ed1e51
Binary files /dev/null and b/img/mdx_opt.png differ
diff --git a/img/splash.bmp b/img/splash.bmp
new file mode 100644
index 0000000..e96677e
Binary files /dev/null and b/img/splash.bmp differ
diff --git a/img/stop.png b/img/stop.png
new file mode 100644
index 0000000..e094d1b
Binary files /dev/null and b/img/stop.png differ
diff --git a/img/user_ens_opt.png b/img/user_ens_opt.png
new file mode 100644
index 0000000..b32c0e3
Binary files /dev/null and b/img/user_ens_opt.png differ
diff --git a/img/vr_opt.png b/img/vr_opt.png
new file mode 100644
index 0000000..c11ff56
Binary files /dev/null and b/img/vr_opt.png differ
diff --git a/inference_MDX.py b/inference_MDX.py
new file mode 100644
index 0000000..ba1b40a
--- /dev/null
+++ b/inference_MDX.py
@@ -0,0 +1,1051 @@
+import os
+from pickle import STOP
+from tracemalloc import stop
+from turtle import update
+import subprocess
+from unittest import skip
+from pathlib import Path
+import os.path
+from datetime import datetime
+import pydub
+import shutil
+#MDX-Net
+#----------------------------------------
+import soundfile as sf
+import torch
+import numpy as np
+from demucs.model import Demucs
+from demucs.utils import apply_model
+from models import get_models, spec_effects
+import onnxruntime as ort
+import time
+import os
+from tqdm import tqdm
+import warnings
+import sys
+import librosa
+import psutil
+#----------------------------------------
+from lib_v5 import spec_utils
+from lib_v5.model_param_init import ModelParameters
+import torch
+
+# Command line text parsing and widget manipulation
+import tkinter as tk
+import traceback # Error Message Recent Calls
+import time # Timer
+
+class Predictor():
+ def __init__(self):
+ pass
+
+ def prediction_setup(self, demucs_name,
+ channels=64):
+ if data['demucsmodel']:
+ self.demucs = Demucs(sources=["drums", "bass", "other", "vocals"], channels=channels)
+ widget_text.write(base_text + 'Loading Demucs model... ')
+ update_progress(**progress_kwargs,
+ step=0.05)
+ self.demucs.to(device)
+ self.demucs.load_state_dict(torch.load(demucs_name))
+ widget_text.write('Done!\n')
+ self.demucs.eval()
+ self.onnx_models = {}
+ c = 0
+
+ self.models = get_models('tdf_extra', load=False, device=cpu, stems='vocals')
+ widget_text.write(base_text + 'Loading ONNX model... ')
+ update_progress(**progress_kwargs,
+ step=0.1)
+ c+=1
+
+ if data['gpu'] >= 0:
+ if torch.cuda.is_available():
+ run_type = ['CUDAExecutionProvider']
+ else:
+ data['gpu'] = -1
+ widget_text.write("\n" + base_text + "No NVIDIA GPU detected. Switching to CPU... ")
+ run_type = ['CPUExecutionProvider']
+ else:
+ run_type = ['CPUExecutionProvider']
+
+ self.onnx_models[c] = ort.InferenceSession(os.path.join('models/MDX_Net_Models', model_set), providers=run_type)
+ widget_text.write('Done!\n')
+
+ def prediction(self, m):
+ #mix, rate = sf.read(m)
+ mix, rate = librosa.load(m, mono=False, sr=44100)
+ if mix.ndim == 1:
+ mix = np.asfortranarray([mix,mix])
+ mix = mix.T
+ sources = self.demix(mix.T)
+ widget_text.write(base_text + 'Inferences complete!\n')
+ c = -1
+
+ #Main Save Path
+ save_path = os.path.dirname(_basename)
+
+ #Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}',)
+
+ #Instrumental Path
+ Instrumental_name = '(Instrumental)'
+ if data['modelFolder']:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ Instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ Instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}_{model_set_name}',)
+ else:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+ Instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+ Instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{Instrumental_name}',)
+
+ #Non-Reduced Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ non_reduced_vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ non_reduced_vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_{model_set_name}_No_Reduction',)
+ else:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+ non_reduced_vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+ non_reduced_vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(_basename)}_{vocal_name}_No_Reduction',)
+
+
+ if os.path.isfile(non_reduced_vocal_path):
+ file_exists_n = 'there'
+ else:
+ file_exists_n = 'not_there'
+
+ if os.path.isfile(vocal_path):
+ file_exists_v = 'there'
+ else:
+ file_exists_v = 'not_there'
+
+ if os.path.isfile(Instrumental_path):
+ file_exists_i = 'there'
+ else:
+ file_exists_i = 'not_there'
+
+ print('Is there already a voc file there? ', file_exists_v)
+
+ if not data['noisereduc_s'] == 'None':
+ c += 1
+
+ if not data['demucsmodel']:
+
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing to save Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving vocals... ')
+
+ sf.write(non_reduced_vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ widget_text.write('Done!\n')
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ else:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+
+ sf.write(non_reduced_vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ widget_text.write('Done!\n')
+ else:
+ c += 1
+
+ if not data['demucsmodel']:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ else:
+ if data['inst_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+
+ if data['voc_only'] and not data['inst_only']:
+ pass
+
+ else:
+ finalfiles = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':[str(music_file), vocal_path],
+ }
+ ]
+ widget_text.write(base_text + 'Saving Instrumental... ')
+ for i, e in tqdm(enumerate(finalfiles)):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ update_progress(**progress_kwargs,
+ step=(1))
+ sf.write(Instrumental_path, spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+
+
+ if data['inst_only']:
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+
+ widget_text.write('Done!\n')
+
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(Instrumental_path)
+ musfile.export(Instrumental_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(Instrumental_path)
+ except:
+ pass
+ if data['non_red'] == True:
+ musfile = pydub.AudioSegment.from_wav(non_reduced_vocal_path)
+ musfile.export(non_reduced_vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ widget_text.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ widget_text.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ else:
+ widget_text.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ widget_text.write(base_text + 'Please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}":\n\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(Instrumental_path)
+ musfile.export(Instrumental_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(Instrumental_path)
+ except:
+ pass
+ if data['non_red'] == True:
+ musfile = pydub.AudioSegment.from_wav(non_reduced_vocal_path)
+ musfile.export(non_reduced_vocal_path_flac, format="flac")
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ widget_text.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ widget_text.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ else:
+ widget_text.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ widget_text.write(base_text + 'Please check error log.\n')
+ widget_text.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}":\n\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
+ try:
+ print('Is there already a voc file there? ', file_exists_v)
+ print('Is there already a non_voc file there? ', file_exists_n)
+ except:
+ pass
+
+
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ elif data['non_red'] == True:
+ pass
+ elif data['inst_only']:
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ widget_text.write(base_text + 'Completed Seperation!\n')
+
+ def demix(self, mix):
+ # 1 = demucs only
+ # 0 = onnx only
+ if data['chunks'] == 'Full':
+ chunk_set = 0
+ else:
+ chunk_set = data['chunks']
+
+ if data['chunks'] == 'Auto':
+ if data['gpu'] == 0:
+ try:
+ gpu_mem = round(torch.cuda.get_device_properties(0).total_memory/1.074e+9)
+ except:
+ widget_text.write(base_text + 'NVIDIA GPU Required for conversion!\n')
+ if int(gpu_mem) <= int(5):
+ chunk_set = int(5)
+ widget_text.write(base_text + 'Chunk size auto-set to 5... \n')
+ if gpu_mem in [6, 7]:
+ chunk_set = int(30)
+ widget_text.write(base_text + 'Chunk size auto-set to 30... \n')
+ if gpu_mem in [8, 9, 10, 11, 12, 13, 14, 15]:
+ chunk_set = int(40)
+ widget_text.write(base_text + 'Chunk size auto-set to 40... \n')
+ if int(gpu_mem) >= int(16):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ if data['gpu'] == -1:
+ sys_mem = psutil.virtual_memory().total >> 30
+ if int(sys_mem) <= int(4):
+ chunk_set = int(1)
+ widget_text.write(base_text + 'Chunk size auto-set to 1... \n')
+ if sys_mem in [5, 6, 7, 8]:
+ chunk_set = int(10)
+ widget_text.write(base_text + 'Chunk size auto-set to 10... \n')
+ if sys_mem in [9, 10, 11, 12, 13, 14, 15, 16]:
+ chunk_set = int(25)
+ widget_text.write(base_text + 'Chunk size auto-set to 25... \n')
+ if int(sys_mem) >= int(17):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ elif data['chunks'] == 'Full':
+ chunk_set = 0
+ widget_text.write(base_text + "Chunk size set to full... \n")
+ else:
+ chunk_set = int(data['chunks'])
+ widget_text.write(base_text + "Chunk size user-set to "f"{chunk_set}... \n")
+
+ samples = mix.shape[-1]
+ margin = margin_set
+ chunk_size = chunk_set*44100
+ assert not margin == 0, 'margin cannot be zero!'
+ if margin > chunk_size:
+ margin = chunk_size
+
+ b = np.array([[[0.5]], [[0.5]], [[0.7]], [[0.9]]])
+ segmented_mix = {}
+
+ if chunk_set == 0 or samples < chunk_size:
+ chunk_size = samples
+
+ counter = -1
+ for skip in range(0, samples, chunk_size):
+ counter+=1
+
+ s_margin = 0 if counter == 0 else margin
+ end = min(skip+chunk_size+margin, samples)
+
+ start = skip-s_margin
+
+ segmented_mix[skip] = mix[:,start:end].copy()
+ if end == samples:
+ break
+
+ if not data['demucsmodel']:
+ sources = self.demix_base(segmented_mix, margin_size=margin)
+
+ else: # both, apply spec effects
+ base_out = self.demix_base(segmented_mix, margin_size=margin)
+ demucs_out = self.demix_demucs(segmented_mix, margin_size=margin)
+ nan_count = np.count_nonzero(np.isnan(demucs_out)) + np.count_nonzero(np.isnan(base_out))
+ if nan_count > 0:
+ print('Warning: there are {} nan values in the array(s).'.format(nan_count))
+ demucs_out, base_out = np.nan_to_num(demucs_out), np.nan_to_num(base_out)
+ sources = {}
+
+ sources[3] = (spec_effects(wave=[demucs_out[3],base_out[0]],
+ algorithm='default',
+ value=b[3])*1.03597672895) # compensation
+ return sources
+
+ def demix_base(self, mixes, margin_size):
+ chunked_sources = []
+ onnxitera = len(mixes)
+ onnxitera_calc = onnxitera * 2
+ gui_progress_bar_onnx = 0
+ widget_text.write(base_text + "Running ONNX Inference...\n")
+ widget_text.write(base_text + "Processing "f"{onnxitera} slices... ")
+ print(' Running ONNX Inference...')
+ for mix in mixes:
+ gui_progress_bar_onnx += 1
+ if data['demucsmodel']:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.5/onnxitera_calc * gui_progress_bar_onnx)))
+ else:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.9/onnxitera * gui_progress_bar_onnx)))
+ cmix = mixes[mix]
+ sources = []
+ n_sample = cmix.shape[1]
+
+ mod = 0
+ for model in self.models:
+ mod += 1
+ trim = model.n_fft//2
+ gen_size = model.chunk_size-2*trim
+ pad = gen_size - n_sample%gen_size
+ mix_p = np.concatenate((np.zeros((2,trim)), cmix, np.zeros((2,pad)), np.zeros((2,trim))), 1)
+ mix_waves = []
+ i = 0
+ while i < n_sample + pad:
+ waves = np.array(mix_p[:, i:i+model.chunk_size])
+ mix_waves.append(waves)
+ i += gen_size
+ mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(cpu)
+ with torch.no_grad():
+ _ort = self.onnx_models[mod]
+ spek = model.stft(mix_waves)
+
+ tar_waves = model.istft(torch.tensor(_ort.run(None, {'input': spek.cpu().numpy()})[0]))#.cpu()
+
+ tar_signal = tar_waves[:,:,trim:-trim].transpose(0,1).reshape(2, -1).numpy()[:, :-pad]
+
+ start = 0 if mix == 0 else margin_size
+ end = None if mix == list(mixes.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ sources.append(tar_signal[:,start:end])
+
+
+ chunked_sources.append(sources)
+ _sources = np.concatenate(chunked_sources, axis=-1)
+ del self.onnx_models
+ widget_text.write('Done!\n')
+ return _sources
+
+ def demix_demucs(self, mix, margin_size):
+ processed = {}
+ demucsitera = len(mix)
+ demucsitera_calc = demucsitera * 2
+ gui_progress_bar_demucs = 0
+ widget_text.write(base_text + "Running Demucs Inference...\n")
+ widget_text.write(base_text + "Processing "f"{len(mix)} slices... ")
+ print(' Running Demucs Inference...')
+ for nmix in mix:
+ gui_progress_bar_demucs += 1
+ update_progress(**progress_kwargs,
+ step=(0.35 + (1.05/demucsitera_calc * gui_progress_bar_demucs)))
+ cmix = mix[nmix]
+ cmix = torch.tensor(cmix, dtype=torch.float32)
+ ref = cmix.mean(0)
+ cmix = (cmix - ref.mean()) / ref.std()
+ shift_set = 0
+ with torch.no_grad():
+ sources = apply_model(self.demucs, cmix.to(device), split=True, overlap=overlap_set, shifts=shift_set)
+ sources = (sources * ref.std() + ref.mean()).cpu().numpy()
+ sources[[0,1]] = sources[[1,0]]
+
+ start = 0 if nmix == 0 else margin_size
+ end = None if nmix == list(mix.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ processed[nmix] = sources[:,:,start:end].copy()
+
+ sources = list(processed.values())
+ sources = np.concatenate(sources, axis=-1)
+ widget_text.write('Done!\n')
+ return sources
+
+data = {
+ # Paths
+ 'input_paths': None,
+ 'export_path': None,
+ 'saveFormat': 'Wav',
+ # Processing Options
+ 'demucsmodel': True,
+ 'gpu': -1,
+ 'chunks': 10,
+ 'non_red': False,
+ 'noisereduc_s': 3,
+ 'mixing': 'default',
+ 'modelFolder': False,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'break': False,
+ # Choose Model
+ 'mdxnetModel': 'UVR-MDX-NET 1',
+ 'high_end_process': 'mirroring',
+}
+default_chunks = data['chunks']
+default_noisereduc_s = data['noisereduc_s']
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+warnings.filterwarnings("ignore")
+cpu = torch.device('cpu')
+device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+
+def hide_opt():
+ with open(os.devnull, "w") as devnull:
+ old_stdout = sys.stdout
+ sys.stdout = devnull
+ try:
+ yield
+ finally:
+ sys.stdout = old_stdout
+
+def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
+ **kwargs: dict):
+
+ global widget_text
+ global gui_progress_bar
+ global music_file
+ global channel_set
+ global margin_set
+ global overlap_set
+ global default_chunks
+ global default_noisereduc_s
+ global _basename
+ global _mixture
+ global progress_kwargs
+ global base_text
+ global model_set
+ global model_set_name
+
+ # Update default settings
+ default_chunks = data['chunks']
+ default_noisereduc_s = data['noisereduc_s']
+
+ channel_set = int(64)
+ margin_set = int(44100)
+ overlap_set = float(0.5)
+
+ widget_text = text_widget
+ gui_progress_bar = progress_var
+
+ #Error Handling
+
+ onnxmissing = "[ONNXRuntimeError] : 3 : NO_SUCHFILE"
+ onnxmemerror = "onnxruntime::CudaCall CUDA failure 2: out of memory"
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: MDX-Net' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ data.update(kwargs)
+
+ if data['mdxnetModel'] == 'UVR-MDX-NET 1':
+ model_set = 'UVR_MDXNET_9703.onnx'
+ model_set_name = 'UVR_MDXNET_9703'
+ if data['mdxnetModel'] == 'UVR-MDX-NET 2':
+ model_set = 'UVR_MDXNET_9682.onnx'
+ model_set_name = 'UVR_MDXNET_9682'
+ if data['mdxnetModel'] == 'UVR-MDX-NET 3':
+ model_set = 'UVR_MDXNET_9662.onnx'
+ model_set_name = 'UVR_MDXNET_9662'
+ if data['mdxnetModel'] == 'UVR-MDX-NET Karaoke':
+ model_set = 'UVR_MDXNET_KARA.onnx'
+ model_set_name = 'UVR_MDXNET_Karaoke'
+
+ stime = time.perf_counter()
+ progress_var.set(0)
+ text_widget.clear()
+ button_widget.configure(state=tk.DISABLED) # Disable Button
+
+ try: #Load File(s)
+ for file_num, music_file in tqdm(enumerate(data['input_paths'], start=1)):
+
+ _mixture = f'{data["input_paths"]}'
+ _basename = f'{data["export_path"]}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+
+ # -Get text and update progress-
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=file_num)
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': file_num}
+
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ else:
+ if not os.path.isfile("lib_v5\sox\sox.exe"):
+ data['noisereduc_s'] = 'None'
+ data['non_red'] = False
+ widget_text.write(base_text + 'SoX is missing and required for noise reduction.\n')
+ widget_text.write(base_text + 'See the \"More Info\" tab in the Help Guide.\n')
+ widget_text.write(base_text + 'Noise Reduction will be disabled until SoX is available.\n\n')
+
+ update_progress(**progress_kwargs,
+ step=0)
+
+ e = os.path.join(data["export_path"])
+
+ demucsmodel = 'models/Demucs_Model/demucs_extra-3646af93_org.th'
+
+ pred = Predictor()
+ pred.prediction_setup(demucs_name=demucsmodel,
+ channels=channel_set)
+
+ # split
+ pred.prediction(
+ m=music_file,
+ )
+
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmissing in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application could not detect this MDX-Net model on your system.\n')
+ text_widget.write(f'Please make sure all the models are present in the correct directory.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application could not detect this MDX-Net model on your system.\n' +
+ f'Please make sure all the models are present in the correct directory.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmemerror in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'\nPlease do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'\nPlease do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ print(traceback_text)
+ print(type(e).__name__, e)
+ print(message)
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: MDX-Net\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
+ progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ progress_var.set(0)
+
+ text_widget.write(f'\nConversion(s) Completed!\n')
+
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+
+if __name__ == '__main__':
+ start_time = time.time()
+ main()
+ print("Successfully completed music demixing.");print('Total time: {0:.{1}f}s'.format(time.time() - start_time, 1))
+
diff --git a/inference_v5.py b/inference_v5.py
index 4ca9b4a..e1ee13c 100644
--- a/inference_v5.py
+++ b/inference_v5.py
@@ -1,9 +1,10 @@
from functools import total_ordering
-import pprint
-import argparse
import os
import importlib
from statistics import mode
+import pydub
+import shutil
+import hashlib
import cv2
import librosa
@@ -16,6 +17,7 @@ from lib_v5 import dataset
from lib_v5 import spec_utils
from lib_v5.model_param_init import ModelParameters
import torch
+from datetime import datetime
# Command line text parsing and widget manipulation
from collections import defaultdict
@@ -36,17 +38,21 @@ data = {
# Paths
'input_paths': None,
'export_path': None,
+ 'saveFormat': 'wav',
# Processing Options
'gpu': -1,
'postprocess': True,
'tta': True,
'output_image': True,
+ 'voc_only': False,
+ 'inst_only': False,
# Models
'instrumentalModel': None,
'useModel': None,
# Constants
'window_size': 512,
- 'agg': 10
+ 'agg': 10,
+ 'high_end_process': 'mirroring'
}
default_window_size = data['window_size']
@@ -88,25 +94,34 @@ def determineModelFolderName():
def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
**kwargs: dict):
- global args
global model_params_d
global nn_arch_sizes
-
+ global nn_architecture
+
+ #Error Handling
+
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: VR Architecture' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
nn_arch_sizes = [
31191, # default
33966, 123821, 123812, 537238 # custom
]
- p = argparse.ArgumentParser()
- p.add_argument('--paramone', type=str, default='lib_v5/modelparams/4band_44100.json')
- p.add_argument('--paramtwo', type=str, default='lib_v5/modelparams/4band_v2.json')
- p.add_argument('--paramthree', type=str, default='lib_v5/modelparams/3band_44100_msb2.json')
- p.add_argument('--paramfour', type=str, default='lib_v5/modelparams/4band_v2_sn.json')
- p.add_argument('--aggressiveness',type=float, default=data['agg']/100)
- p.add_argument('--nn_architecture', type=str, choices= ['auto'] + list('{}KB'.format(s) for s in nn_arch_sizes), default='auto')
- p.add_argument('--high_end_process', type=str, default='mirroring')
- args = p.parse_args()
-
+ nn_architecture = list('{}KB'.format(s) for s in nn_arch_sizes)
+
+
def save_files(wav_instrument, wav_vocals):
"""Save output music files"""
vocal_name = '(Vocals)'
@@ -133,22 +148,207 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# -Save files-
# Instrumental
if instrumental_name is not None:
- instrumental_path = '{save_path}/{file_name}.wav'.format(
- save_path=save_path,
- file_name=f'{os.path.basename(base_name)}_{instrumental_name}{appendModelFolderName}',
- )
-
- sf.write(instrumental_path,
- wav_instrument, mp.param['sr'])
+ if data['modelFolder']:
+ instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{instrumental_name}',)
+ else:
+ instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+ instrumental_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+ instrumental_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{instrumental_name}',)
+
+ if os.path.isfile(instrumental_path):
+ file_exists_i = 'there'
+ else:
+ file_exists_i = 'not_there'
+
+ if VModel in model_name and data['voc_only']:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+ elif VModel in model_name and data['inst_only']:
+ pass
+ elif data['voc_only']:
+ pass
+ else:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+
# Vocal
if vocal_name is not None:
- vocal_path = '{save_path}/{file_name}.wav'.format(
- save_path=save_path,
- file_name=f'{os.path.basename(base_name)}_{vocal_name}{appendModelFolderName}',
- )
- sf.write(vocal_path,
- wav_vocals, mp.param['sr'])
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}{appendModelFolderName}_{vocal_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+ vocal_path_mp3 = '{save_path}/{file_name}.mp3'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+ vocal_path_flac = '{save_path}/{file_name}.flac'.format(
+ save_path=save_path,
+ file_name=f'{os.path.basename(base_name)}_{vocal_name}',)
+
+ if os.path.isfile(vocal_path):
+ file_exists_v = 'there'
+ else:
+ file_exists_v = 'not_there'
+ if VModel in model_name and data['inst_only']:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+ elif VModel in model_name and data['voc_only']:
+ pass
+ elif data['inst_only']:
+ pass
+ else:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_mp3, format="mp3", bitrate="320k")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ if VModel in model_name:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ else:
+ if data['inst_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(vocal_path)
+ musfile.export(vocal_path_flac, format="flac")
+ if file_exists_v == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+ if data['voc_only'] == True:
+ pass
+ else:
+ musfile = pydub.AudioSegment.from_wav(instrumental_path)
+ musfile.export(instrumental_path_flac, format="flac")
+ if file_exists_i == 'there':
+ pass
+ else:
+ try:
+ os.remove(instrumental_path)
+ except:
+ pass
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
data.update(kwargs)
# Update default settings
@@ -164,16 +364,12 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
vocal_remover = VocalRemover(data, text_widget)
modelFolderName = determineModelFolderName()
- if modelFolderName:
- folder_path = f'{data["export_path"]}{modelFolderName}'
- if not os.path.isdir(folder_path):
- os.mkdir(folder_path)
# Separation Preperation
try: #Load File(s)
for file_num, music_file in enumerate(data['input_paths'], start=1):
# Determine File Name
- base_name = f'{data["export_path"]}{modelFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+ base_name = f'{data["export_path"]}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
model_name = os.path.basename(data[f'{data["useModel"]}Model'])
model = vocal_remover.models[data['useModel']]
@@ -187,36 +383,220 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
update_progress(**progress_kwargs,
step=0)
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
#Load Model
text_widget.write(base_text + 'Loading models...')
-
- if 'auto' == args.nn_architecture:
- model_size = math.ceil(os.stat(data['instrumentalModel']).st_size / 1024)
- args.nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+ model_size = math.ceil(os.stat(data['instrumentalModel']).st_size / 1024)
+ nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+
+ nets = importlib.import_module('lib_v5.nets' + f'_{nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
+
+ aggresive_set = float(data['agg']/100)
- nets = importlib.import_module('lib_v5.nets' + f'_{args.nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
-
ModelName=(data['instrumentalModel'])
- ModelParam1="4BAND_44100"
- ModelParam2="4BAND_44100_B"
- ModelParam3="MSB2"
- ModelParam4="4BAND_44100_SN"
-
- if ModelParam1 in ModelName:
- model_params_d=args.paramone
- if ModelParam2 in ModelName:
- model_params_d=args.paramtwo
- if ModelParam3 in ModelName:
- model_params_d=args.paramthree
- if ModelParam4 in ModelName:
- model_params_d=args.paramfour
+ #Package Models
+
+ model_hash = hashlib.md5(open(ModelName,'rb').read()).hexdigest()
+ print(model_hash)
+
+ #v5 Models
+
+ if model_hash == '47939caf0cfe52a0e81442b85b971dfd':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '4e4ecb9764c50a8c414fee6e10395bbe':
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if model_hash == 'e60a1e84803ce4efc0a6551206cc4b71':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'a82f14e75892e55e994376edbf0c8435':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '6dd9eaa6f0420af9f1d403aaafa4cc06':
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if model_hash == '5c7bbca45a187e81abbbd351606164e5':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'd6b2cb685a058a091e5e7098192d3233':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'c1b9f38170a7c90e96f027992eb7c62b':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'c3448ec923fa0edf3d03a19e633faa53':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
- print('Model Parameters:', model_params_d)
+ #v4 Models
+
+ if model_hash == '6a00461c51c2920fd68937d4609ed6c8':
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if model_hash == '0ab504864d20f1bd378fe9c81ef37140':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '7dd21065bf91c10f7fccb57d7d83b07f':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '80ab74d65e515caa3622728d2de07d23':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == 'edc115e7fc523245062200c00caa847f':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == '28063e9f6ab5b341c5f6d3c67f2045b7':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == 'b58090534c52cbc3e9b5104bad666ef2':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == '0cdab9947f1b0928705f518f3c78ea8f':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == 'ae702fed0238afb5346db8356fe25f13':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ #User Models
+
+ #1 Band
+ if '1band_sr16000_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if '1band_sr32000_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if '1band_sr33075_hl384' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if '1band_sr44100_hl256' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl256.json')
+ param_name=str('1band_sr44100_hl256')
+ if '1band_sr44100_hl512' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if '1band_sr44100_hl1024' in ModelName:
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ #2 Band
+ if '2band_44100_lofi' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_44100_lofi.json')
+ param_name=str('2band_44100_lofi')
+ if '2band_32000' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_32000.json')
+ param_name=str('2band_32000')
+ if '2band_48000' in ModelName:
+ model_params_d=str('lib_v5/modelparams/2band_48000.json')
+ param_name=str('2band_48000')
+
+ #3 Band
+ if '3band_44100' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100.json')
+ param_name=str('3band_44100')
+ if '3band_44100_mid' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100_mid.json')
+ param_name=str('3band_44100_mid')
+ if '3band_44100_msb2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+
+ #4 Band
+ if '4band_44100' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if '4band_44100_mid' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_mid.json')
+ param_name=str('4band_44100_mid')
+ if '4band_44100_msb' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_msb.json')
+ param_name=str('4band_44100_msb')
+ if '4band_44100_msb2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_msb2.json')
+ param_name=str('4band_44100_msb2')
+ if '4band_44100_reverse' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_reverse.json')
+ param_name=str('4band_44100_reverse')
+ if '4band_44100_sw' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_44100_sw.json')
+ param_name=str('4band_44100_sw')
+ if '4band_v2' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if '4band_v2_sn' in ModelName:
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if 'tmodelparam' in ModelName:
+ model_params_d=str('lib_v5/modelparams/tmodelparam.json')
+ param_name=str('User Model Param Set')
+
+ text_widget.write(' Done!\n')
+
+ try:
+ print('Model Parameters:', model_params_d)
+ text_widget.write(base_text + 'Loading assigned model parameters ' + '\"' + param_name + '\"... ')
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Model parameters are missing.\n\n')
+ text_widget.write(f'Please check the following:\n')
+ text_widget.write(f'1. Make sure the model is still present.\n')
+ text_widget.write(f'2. If you are running a model that was not originally included in this package, \nplease append the modelparam name to the model name.\n')
+ text_widget.write(f' - Example if using \"4band_v2.json\" modelparam: \"model_4band_v2.pth\"\n\n')
+ text_widget.write(f'Please address this and try again.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Model parameters are missing.\n\n' +
+ f'Please check the following:\n' +
+ f'1. Make sure the model is still present.\n' +
+ f'2. If you are running a model that was not originally included in this package, please append the modelparam name to the model name.\n' +
+ f' - Example if using \"4band_v2.json\" modelparam: \"model_4band_v2.pth\"\n\n' +
+ f'Please address this and try again.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
mp = ModelParameters(model_params_d)
-
+ text_widget.write('Done!\n')
# -Instrumental-
if os.path.isfile(data['instrumentalModel']):
device = torch.device('cpu')
@@ -230,7 +610,6 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
vocal_remover.models['instrumental'] = model
vocal_remover.devices['instrumental'] = device
- text_widget.write(' Done!\n')
model_name = os.path.basename(data[f'{data["useModel"]}Model'])
@@ -238,7 +617,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# -Go through the different steps of seperation-
# Wave source
- text_widget.write(base_text + 'Loading wave source...')
+ text_widget.write(base_text + 'Loading audio source...')
X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
@@ -261,7 +640,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
mp.param['mid_side_b2'], mp.param['reverse'])
- if d == bands_n and args.high_end_process != 'none':
+ if d == bands_n and data['high_end_process'] != 'none':
input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
@@ -270,7 +649,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
update_progress(**progress_kwargs,
step=0.1)
- text_widget.write(base_text + 'Stft of wave source...')
+ text_widget.write(base_text + 'Loading the stft of audio source...')
text_widget.write(' Done!\n')
@@ -350,7 +729,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
else:
return pred * coef, X_mag, np.exp(1.j * X_phase)
- aggressiveness = {'value': args.aggressiveness, 'split_bin': mp.param['band'][1]['crop_stop']}
+ aggressiveness = {'value': aggresive_set, 'split_bin': mp.param['band'][1]['crop_stop']}
if data['tta']:
text_widget.write(base_text + "Running Inferences (TTA)...\n")
@@ -365,42 +744,78 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
step=0.9)
# Postprocess
if data['postprocess']:
- text_widget.write(base_text + 'Post processing...')
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- text_widget.write(' Done!\n')
+ try:
+ text_widget.write(base_text + 'Post processing...')
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ text_widget.write(' Done!\n')
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Post process failed, check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run Post Processing on "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
update_progress(**progress_kwargs,
step=0.95)
# Inverse stft
- text_widget.write(base_text + 'Inverse stft of instruments and vocals...') # nopep8
y_spec_m = pred * X_phase
v_spec_m = X_spec_m - y_spec_m
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, y_spec_m, input_high_end, mp)
-
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Instrumental... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], y_spec_m, input_high_end, mp)
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
else:
wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, v_spec_m, input_high_end, mp)
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Vocals... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], v_spec_m, input_high_end, mp)
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
else:
wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
-
- text_widget.write('Done!\n')
+ if data['inst_only'] and not data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
update_progress(**progress_kwargs,
step=1)
# Save output music files
- text_widget.write(base_text + 'Saving Files...')
save_files(wav_instrument, wav_vocals)
- text_widget.write(' Done!\n')
update_progress(**progress_kwargs,
step=1)
@@ -415,25 +830,196 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
image = spec_utils.spectrogram_to_image(v_spec_m)
_, bin_image = cv2.imencode('.jpg', image)
bin_image.tofile(f)
+
text_widget.write(base_text + 'Completed Seperation!\n\n')
except Exception as e:
traceback_text = ''.join(traceback.format_tb(e.__traceback__))
- message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\nFile: {music_file}\nPlease contact the creator and attach a screenshot of this error with the file and settings that caused it!'
- tk.messagebox.showerror(master=window,
- title='Untracked Error',
- message=message)
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
print(traceback_text)
print(type(e).__name__, e)
print(message)
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: VR Architecture\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) # Enable Button
return
-
- os.remove('temp.wav')
+
+ try:
+ os.remove('temp.wav')
+ except:
+ pass
progress_var.set(0)
- text_widget.write(f'\nConversion(s) Completed!\n')
+ text_widget.write(f'Conversion(s) Completed!\n')
text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) # Enable Button
\ No newline at end of file
diff --git a/inference_v5_ensemble.py b/inference_v5_ensemble.py
index 43acdd5..ede48d9 100644
--- a/inference_v5_ensemble.py
+++ b/inference_v5_ensemble.py
@@ -1,15 +1,35 @@
from functools import total_ordering
-import pprint
-import argparse
+import importlib
import os
from statistics import mode
+from pathlib import Path
+import pydub
+import hashlib
+
+import subprocess
+import soundfile as sf
+import torch
+import numpy as np
+from demucs.model import Demucs
+from demucs.utils import apply_model
+from models import get_models, spec_effects
+import onnxruntime as ort
+import time
+import os
+from tqdm import tqdm
+import warnings
+import sys
+import librosa
+import psutil
import cv2
+import math
import librosa
import numpy as np
import soundfile as sf
import shutil
from tqdm import tqdm
+from datetime import datetime
from lib_v5 import dataset
from lib_v5 import spec_utils
@@ -22,6 +42,480 @@ import tkinter as tk
import traceback # Error Message Recent Calls
import time # Timer
+class Predictor():
+ def __init__(self):
+ pass
+
+ def prediction_setup(self, demucs_name,
+ channels=64):
+ if data['demucsmodel']:
+ self.demucs = Demucs(sources=["drums", "bass", "other", "vocals"], channels=channels)
+ widget_text.write(base_text + 'Loading Demucs model... ')
+ update_progress(**progress_kwargs,
+ step=0.05)
+ self.demucs.to(device)
+ self.demucs.load_state_dict(torch.load(demucs_name))
+ widget_text.write('Done!\n')
+ self.demucs.eval()
+ self.onnx_models = {}
+ c = 0
+
+ self.models = get_models('tdf_extra', load=False, device=cpu, stems='vocals')
+ widget_text.write(base_text + 'Loading ONNX model... ')
+ update_progress(**progress_kwargs,
+ step=0.1)
+ c+=1
+
+ if data['gpu'] >= 0:
+ if torch.cuda.is_available():
+ run_type = ['CUDAExecutionProvider']
+ else:
+ data['gpu'] = -1
+ widget_text.write("\n" + base_text + "No NVIDIA GPU detected. Switching to CPU... ")
+ run_type = ['CPUExecutionProvider']
+ else:
+ run_type = ['CPUExecutionProvider']
+
+ self.onnx_models[c] = ort.InferenceSession(os.path.join('models/MDX_Net_Models', model_set), providers=run_type)
+ widget_text.write('Done!\n')
+
+ def prediction(self, m):
+ #mix, rate = sf.read(m)
+ mix, rate = librosa.load(m, mono=False, sr=44100)
+ if mix.ndim == 1:
+ mix = np.asfortranarray([mix,mix])
+ mix = mix.T
+ sources = self.demix(mix.T)
+ widget_text.write(base_text + 'Inferences complete!\n')
+ c = -1
+
+ #Main Save Path
+ save_path = os.path.dirname(base_name)
+
+ #Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}',)
+ else:
+ vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}',)
+
+ #Instrumental Path
+ Instrumental_name = '(Instrumental)'
+ if data['modelFolder']:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{Instrumental_name}',)
+ else:
+ Instrumental_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{Instrumental_name}',)
+
+ #Non-Reduced Vocal Path
+ vocal_name = '(Vocals)'
+ if data['modelFolder']:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}_No_Reduction',)
+ else:
+ non_reduced_vocal_path = '{save_path}/{file_name}.wav'.format(
+ save_path=save_path,
+ file_name = f'{os.path.basename(base_name)}_{ModelName_2}_{vocal_name}_No_Reduction',)
+
+ if os.path.isfile(non_reduced_vocal_path):
+ file_exists_n = 'there'
+ else:
+ file_exists_n = 'not_there'
+
+ if os.path.isfile(vocal_path):
+ file_exists = 'there'
+ else:
+ file_exists = 'not_there'
+
+ if not data['noisereduc_s'] == 'None':
+ c += 1
+ if not data['demucsmodel']:
+ if data['inst_only'] and not data['voc_only']:
+ widget_text.write(base_text + 'Preparing to save Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving vocals... ')
+ sf.write(non_reduced_vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ widget_text.write('Done!\n')
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ else:
+ if data['inst_only'] and not data['voc_only']:
+ widget_text.write(base_text + 'Preparing Instrumental...')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(non_reduced_vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ widget_text.write(base_text + 'Performing Noise Reduction... ')
+ reduction_sen = float(int(data['noisereduc_s'])/10)
+ subprocess.call("lib_v5\\sox\\sox.exe" + ' "' +
+ f"{str(non_reduced_vocal_path)}" + '" "' + f"{str(vocal_path)}" + '" ' +
+ "noisered lib_v5\\sox\\mdxnetnoisereduc.prof " + f"{reduction_sen}",
+ shell=True, stdout=subprocess.PIPE,
+ stdin=subprocess.PIPE, stderr=subprocess.PIPE)
+ update_progress(**progress_kwargs,
+ step=(0.95))
+ widget_text.write('Done!\n')
+ else:
+ c += 1
+ if not data['demucsmodel']:
+ widget_text.write(base_text + 'Saving Vocals..')
+ sf.write(vocal_path, sources[c].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+ else:
+ widget_text.write(base_text + 'Saving Vocals... ')
+ sf.write(vocal_path, sources[3].T, rate)
+ update_progress(**progress_kwargs,
+ step=(0.9))
+ widget_text.write('Done!\n')
+
+ if data['voc_only'] and not data['inst_only']:
+ pass
+ else:
+ finalfiles = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':[str(music_file), vocal_path],
+ }
+ ]
+ widget_text.write(base_text + 'Saving Instrumental... ')
+ for i, e in tqdm(enumerate(finalfiles)):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ update_progress(**progress_kwargs,
+ step=(1))
+ sf.write(Instrumental_path, spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+ if data['inst_only']:
+ if file_exists == 'there':
+ pass
+ else:
+ try:
+ os.remove(vocal_path)
+ except:
+ pass
+
+ widget_text.write('Done!\n')
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ elif data['inst_only']:
+ if file_exists_n == 'there':
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+ else:
+ try:
+ os.remove(non_reduced_vocal_path)
+ except:
+ pass
+
+ widget_text.write(base_text + 'Completed Seperation!\n\n')
+
+ def demix(self, mix):
+ # 1 = demucs only
+ # 0 = onnx only
+ if data['chunks'] == 'Full':
+ chunk_set = 0
+ else:
+ chunk_set = data['chunks']
+
+ if data['chunks'] == 'Auto':
+ if data['gpu'] == 0:
+ try:
+ gpu_mem = round(torch.cuda.get_device_properties(0).total_memory/1.074e+9)
+ except:
+ widget_text.write(base_text + 'NVIDIA GPU Required for conversion!\n')
+ if int(gpu_mem) <= int(5):
+ chunk_set = int(5)
+ widget_text.write(base_text + 'Chunk size auto-set to 5... \n')
+ if gpu_mem in [6, 7]:
+ chunk_set = int(30)
+ widget_text.write(base_text + 'Chunk size auto-set to 30... \n')
+ if gpu_mem in [8, 9, 10, 11, 12, 13, 14, 15]:
+ chunk_set = int(40)
+ widget_text.write(base_text + 'Chunk size auto-set to 40... \n')
+ if int(gpu_mem) >= int(16):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ if data['gpu'] == -1:
+ sys_mem = psutil.virtual_memory().total >> 30
+ if int(sys_mem) <= int(4):
+ chunk_set = int(1)
+ widget_text.write(base_text + 'Chunk size auto-set to 1... \n')
+ if sys_mem in [5, 6, 7, 8]:
+ chunk_set = int(10)
+ widget_text.write(base_text + 'Chunk size auto-set to 10... \n')
+ if sys_mem in [9, 10, 11, 12, 13, 14, 15, 16]:
+ chunk_set = int(25)
+ widget_text.write(base_text + 'Chunk size auto-set to 25... \n')
+ if int(sys_mem) >= int(17):
+ chunk_set = int(60)
+ widget_text.write(base_text + 'Chunk size auto-set to 60... \n')
+ elif data['chunks'] == 'Full':
+ chunk_set = 0
+ widget_text.write(base_text + "Chunk size set to full... \n")
+ else:
+ chunk_set = int(data['chunks'])
+ widget_text.write(base_text + "Chunk size user-set to "f"{chunk_set}... \n")
+
+ samples = mix.shape[-1]
+ margin = margin_set
+ chunk_size = chunk_set*44100
+ assert not margin == 0, 'margin cannot be zero!'
+ if margin > chunk_size:
+ margin = chunk_size
+
+ b = np.array([[[0.5]], [[0.5]], [[0.7]], [[0.9]]])
+ segmented_mix = {}
+
+ if chunk_set == 0 or samples < chunk_size:
+ chunk_size = samples
+
+ counter = -1
+ for skip in range(0, samples, chunk_size):
+ counter+=1
+
+ s_margin = 0 if counter == 0 else margin
+ end = min(skip+chunk_size+margin, samples)
+
+ start = skip-s_margin
+
+ segmented_mix[skip] = mix[:,start:end].copy()
+ if end == samples:
+ break
+
+ if not data['demucsmodel']:
+ sources = self.demix_base(segmented_mix, margin_size=margin)
+
+ else: # both, apply spec effects
+ base_out = self.demix_base(segmented_mix, margin_size=margin)
+ demucs_out = self.demix_demucs(segmented_mix, margin_size=margin)
+ nan_count = np.count_nonzero(np.isnan(demucs_out)) + np.count_nonzero(np.isnan(base_out))
+ if nan_count > 0:
+ print('Warning: there are {} nan values in the array(s).'.format(nan_count))
+ demucs_out, base_out = np.nan_to_num(demucs_out), np.nan_to_num(base_out)
+ sources = {}
+
+ sources[3] = (spec_effects(wave=[demucs_out[3],base_out[0]],
+ algorithm='default',
+ value=b[3])*1.03597672895) # compensation
+ return sources
+
+ def demix_base(self, mixes, margin_size):
+ chunked_sources = []
+ onnxitera = len(mixes)
+ onnxitera_calc = onnxitera * 2
+ gui_progress_bar_onnx = 0
+ widget_text.write(base_text + "Running ONNX Inference...\n")
+ widget_text.write(base_text + "Processing "f"{onnxitera} slices... ")
+ print(' Running ONNX Inference...')
+ for mix in mixes:
+ gui_progress_bar_onnx += 1
+ if data['demucsmodel']:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.5/onnxitera_calc * gui_progress_bar_onnx)))
+ else:
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.9/onnxitera * gui_progress_bar_onnx)))
+ cmix = mixes[mix]
+ sources = []
+ n_sample = cmix.shape[1]
+
+ mod = 0
+ for model in self.models:
+ mod += 1
+ trim = model.n_fft//2
+ gen_size = model.chunk_size-2*trim
+ pad = gen_size - n_sample%gen_size
+ mix_p = np.concatenate((np.zeros((2,trim)), cmix, np.zeros((2,pad)), np.zeros((2,trim))), 1)
+ mix_waves = []
+ i = 0
+ while i < n_sample + pad:
+ waves = np.array(mix_p[:, i:i+model.chunk_size])
+ mix_waves.append(waves)
+ i += gen_size
+ mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(cpu)
+ with torch.no_grad():
+ _ort = self.onnx_models[mod]
+ spek = model.stft(mix_waves)
+
+ tar_waves = model.istft(torch.tensor(_ort.run(None, {'input': spek.cpu().numpy()})[0]))#.cpu()
+
+ tar_signal = tar_waves[:,:,trim:-trim].transpose(0,1).reshape(2, -1).numpy()[:, :-pad]
+
+ start = 0 if mix == 0 else margin_size
+ end = None if mix == list(mixes.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ sources.append(tar_signal[:,start:end])
+
+
+ chunked_sources.append(sources)
+ _sources = np.concatenate(chunked_sources, axis=-1)
+ del self.onnx_models
+ widget_text.write('Done!\n')
+ return _sources
+
+ def demix_demucs(self, mix, margin_size):
+ processed = {}
+ demucsitera = len(mix)
+ demucsitera_calc = demucsitera * 2
+ gui_progress_bar_demucs = 0
+ widget_text.write(base_text + "Running Demucs Inference...\n")
+ widget_text.write(base_text + "Processing "f"{len(mix)} slices... ")
+ print(' Running Demucs Inference...')
+ for nmix in mix:
+ gui_progress_bar_demucs += 1
+ update_progress(**progress_kwargs,
+ step=(0.35 + (1.05/demucsitera_calc * gui_progress_bar_demucs)))
+ cmix = mix[nmix]
+ cmix = torch.tensor(cmix, dtype=torch.float32)
+ ref = cmix.mean(0)
+ cmix = (cmix - ref.mean()) / ref.std()
+ shift_set = 0
+ with torch.no_grad():
+ sources = apply_model(self.demucs, cmix.to(device), split=True, overlap=overlap_set, shifts=shift_set)
+ sources = (sources * ref.std() + ref.mean()).cpu().numpy()
+ sources[[0,1]] = sources[[1,0]]
+
+ start = 0 if nmix == 0 else margin_size
+ end = None if nmix == list(mix.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ processed[nmix] = sources[:,:,start:end].copy()
+
+ sources = list(processed.values())
+ sources = np.concatenate(sources, axis=-1)
+ widget_text.write('Done!\n')
+ return sources
+
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+warnings.filterwarnings("ignore")
+cpu = torch.device('cpu')
+device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
+
+def hide_opt():
+ with open(os.devnull, "w") as devnull:
+ old_stdout = sys.stdout
+ sys.stdout = devnull
+ try:
+ yield
+ finally:
+ sys.stdout = old_stdout
+
+class VocalRemover(object):
+
+ def __init__(self, data, text_widget: tk.Text):
+ self.data = data
+ self.text_widget = text_widget
+ self.models = defaultdict(lambda: None)
+ self.devices = defaultdict(lambda: None)
+ # self.offset = model.offset
+
+
+
+def update_progress(progress_var, total_files, file_num, step: float = 1):
+ """Calculate the progress for the progress widget in the GUI"""
+ base = (100 / total_files)
+ progress = base * (file_num - 1)
+ progress += base * step
+
+ progress_var.set(progress)
+
+def get_baseText(total_files, file_num):
+ """Create the base text for the command widget"""
+ text = 'File {file_num}/{total_files} '.format(file_num=file_num,
+ total_files=total_files)
+ return text
+
+def determineModelFolderName():
+ """
+ Determine the name that is used for the folder and appended
+ to the back of the music files
+ """
+ modelFolderName = ''
+ if not data['modelFolder']:
+ # Model Test Mode not selected
+ return modelFolderName
+
+ # -Instrumental-
+ if os.path.isfile(data['instrumentalModel']):
+ modelFolderName += os.path.splitext(os.path.basename(data['instrumentalModel']))[0]
+
+ if modelFolderName:
+ modelFolderName = '/' + modelFolderName
+
+ return modelFolderName
+
class VocalRemover(object):
def __init__(self, data, text_widget: tk.Text):
@@ -33,23 +527,36 @@ data = {
# Paths
'input_paths': None,
'export_path': None,
+ 'saveFormat': 'wav',
# Processing Options
'gpu': -1,
'postprocess': True,
'tta': True,
- 'save': True,
'output_image': True,
+ 'voc_only': False,
+ 'inst_only': False,
+ 'demucsmodel': True,
+ 'gpu': -1,
+ 'chunks': 'auto',
+ 'non_red': False,
+ 'noisereduc_s': 3,
+ 'mixing': 'default',
+ 'ensChoose': 'HP1 Models',
+ 'algo': 'Instrumentals (Min Spec)',
# Models
'instrumentalModel': None,
'useModel': None,
# Constants
'window_size': 512,
'agg': 10,
- 'ensChoose': 'HP1 Models'
+ 'high_end_process': 'mirroring'
}
default_window_size = data['window_size']
default_agg = data['agg']
+default_chunks = data['chunks']
+default_noisereduc_s = data['noisereduc_s']
+
def update_progress(progress_var, total_files, file_num, step: float = 1):
"""Calculate the progress for the progress widget in the GUI"""
@@ -68,20 +575,61 @@ def get_baseText(total_files, file_num):
def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress_var: tk.Variable,
**kwargs: dict):
- global args
- global nn_arch_sizes
+ global widget_text
+ global gui_progress_bar
+ global music_file
+ global channel_set
+ global margin_set
+ global overlap_set
+ global default_chunks
+ global default_noisereduc_s
+ global base_name
+ global progress_kwargs
+ global base_text
+ global model_set
+ global model_set_name
+ global ModelName_2
+ model_set = 'UVR_MDXNET_9703.onnx'
+ model_set_name = 'UVR_MDXNET_9703'
+
+ # Update default settings
+ default_chunks = data['chunks']
+ default_noisereduc_s = data['noisereduc_s']
+
+ channel_set = int(64)
+ margin_set = int(44100)
+ overlap_set = float(0.5)
+
+ widget_text = text_widget
+ gui_progress_bar = progress_var
+
+ #Error Handling
+
+ onnxmissing = "[ONNXRuntimeError] : 3 : NO_SUCHFILE"
+ onnxmemerror = "onnxruntime::CudaCall CUDA failure 2: out of memory"
+ runtimeerr = "CUDNN error executing cudnnSetTensorNdDescriptor"
+ cuda_err = "CUDA out of memory"
+ mod_err = "ModuleNotFoundError"
+ file_err = "FileNotFoundError"
+ ffmp_err = """audioread\__init__.py", line 116, in audio_open"""
+ sf_write_err = "sf.write"
+
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'No errors to report at this time.' + f'\n\nLast Process Method Used: Ensemble Mode' +
+ f'\nLast Conversion Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ global nn_arch_sizes
+ global nn_architecture
+
nn_arch_sizes = [
31191, # default
- 33966, 123821, 123812, 537238 # custom
+ 33966, 123821, 123812, 537238, 537227 # custom
]
-
- p = argparse.ArgumentParser()
- p.add_argument('--aggressiveness',type=float, default=data['agg']/100)
- p.add_argument('--high_end_process', type=str, default='mirroring')
- args = p.parse_args()
-
-
+
def save_files(wav_instrument, wav_vocals):
"""Save output music files"""
vocal_name = '(Vocals)'
@@ -100,6 +648,7 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
# For instrumental the instrumental is the temp file
# and for vocal the instrumental is the temp file due
# to reversement
+
sf.write(f'temp.wav',
wav_instrument, mp.param['sr'])
@@ -110,17 +659,35 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
save_path=save_path,
file_name = f'{os.path.basename(base_name)}_{ModelName_1}_{instrumental_name}',
)
-
- sf.write(instrumental_path,
- wav_instrument, mp.param['sr'])
+
+ if VModel in ModelName_1 and data['voc_only']:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+ elif VModel in ModelName_1 and data['inst_only']:
+ pass
+ elif data['voc_only']:
+ pass
+ else:
+ sf.write(instrumental_path,
+ wav_instrument, mp.param['sr'])
+
# Vocal
if vocal_name is not None:
vocal_path = '{save_path}/{file_name}.wav'.format(
save_path=save_path,
file_name=f'{os.path.basename(base_name)}_{ModelName_1}_{vocal_name}',
)
- sf.write(vocal_path,
- wav_vocals, mp.param['sr'])
+
+ if VModel in ModelName_1 and data['inst_only']:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
+ elif VModel in ModelName_1 and data['voc_only']:
+ pass
+ elif data['inst_only']:
+ pass
+ else:
+ sf.write(vocal_path,
+ wav_vocals, mp.param['sr'])
data.update(kwargs)
@@ -135,471 +702,1376 @@ def main(window: tk.Wm, text_widget: tk.Text, button_widget: tk.Button, progress
text_widget.clear()
button_widget.configure(state=tk.DISABLED) # Disable Button
+ if os.path.exists('models/Main_Models/7_HP2-UVR.pth') \
+ or os.path.exists('models/Main_Models/8_HP2-UVR.pth') \
+ or os.path.exists('models/Main_Models/9_HP2-UVR.pth'):
+ hp2_ens = 'on'
+ else:
+ hp2_ens = 'off'
+
+ print('Do all of the HP models exist? ' + hp2_ens)
+
# Separation Preperation
try: #Ensemble Dictionary
- HP1_Models = [
- {
- 'model_name':'HP_4BAND_44100_A',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_A.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/2'
- },
- {
- 'model_name':'HP_4BAND_44100_B',
- 'model_params':'lib_v5/modelparams/4band_v2.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_B.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/2'
- }
- ]
-
- HP2_Models = [
- {
- 'model_name':'HP2_4BAND_44100_1',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_1.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 1/3'
- },
- {
- 'model_name':'HP2_4BAND_44100_2',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 2/3'
- },
- {
- 'model_name':'HP2_3BAND_44100_MSB2',
- 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
- 'model_location':'models/Main Models/HP2_3BAND_44100_MSB2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 3/3'
- }
- ]
-
- All_HP_Models = [
- {
- 'model_name':'HP_4BAND_44100_A',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_A.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/5'
- },
- {
- 'model_name':'HP_4BAND_44100_B',
- 'model_params':'lib_v5/modelparams/4band_v2.json',
- 'model_location':'models/Main Models/HP_4BAND_44100_B.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/5'
- },
- {
- 'model_name':'HP2_4BAND_44100_1',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_1.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 3/5'
-
- },
- {
- 'model_name':'HP2_4BAND_44100_2',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP2_4BAND_44100_2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 4/5'
-
- },
- {
- 'model_name':'HP2_3BAND_44100_MSB2',
- 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
- 'model_location':'models/Main Models/HP2_3BAND_44100_MSB2.pth',
- 'using_archtecture': '537238KB',
- 'loop_name': 'Ensemble Mode - Model 5/5'
- }
- ]
-
- Vocal_Models = [
- {
- 'model_name':'HP_Vocal_4BAND_44100',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_Vocal_4BAND_44100.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 1/2'
- },
- {
- 'model_name':'HP_Vocal_AGG_4BAND_44100',
- 'model_params':'lib_v5/modelparams/4band_44100.json',
- 'model_location':'models/Main Models/HP_Vocal_AGG_4BAND_44100.pth',
- 'using_archtecture': '123821KB',
- 'loop_name': 'Ensemble Mode - Model 2/2'
- }
- ]
- if data['ensChoose'] == 'HP1 Models':
- loops = HP1_Models
- ensefolder = 'HP_Models_Saved_Outputs'
- ensemode = 'HP_Models'
- if data['ensChoose'] == 'HP2 Models':
- loops = HP2_Models
- ensefolder = 'HP2_Models_Saved_Outputs'
- ensemode = 'HP2_Models'
- if data['ensChoose'] == 'All HP Models':
- loops = All_HP_Models
- ensefolder = 'All_HP_Models_Saved_Outputs'
- ensemode = 'All_HP_Models'
- if data['ensChoose'] == 'Vocal Models':
- loops = Vocal_Models
- ensefolder = 'Vocal_Models_Saved_Outputs'
- ensemode = 'Vocal_Models'
-
- #Prepare Audiofile(s)
- for file_num, music_file in enumerate(data['input_paths'], start=1):
- # -Get text and update progress-
- base_text = get_baseText(total_files=len(data['input_paths']),
- file_num=file_num)
- progress_kwargs = {'progress_var': progress_var,
- 'total_files': len(data['input_paths']),
- 'file_num': file_num}
- update_progress(**progress_kwargs,
- step=0)
-
- #Prepare to loop models
- for i, c in tqdm(enumerate(loops), disable=True, desc='Iterations..'):
-
- text_widget.write(c['loop_name'] + '\n\n')
-
- text_widget.write(base_text + 'Loading ' + c['model_name'] + '... ')
-
- arch_now = c['using_archtecture']
-
- if arch_now == '123821KB':
- from lib_v5 import nets_123821KB as nets
- elif arch_now == '537238KB':
- from lib_v5 import nets_537238KB as nets
- elif arch_now == '537227KB':
- from lib_v5 import nets_537227KB as nets
-
- def determineenseFolderName():
- """
- Determine the name that is used for the folder and appended
- to the back of the music files
- """
- enseFolderName = ''
-
- if str(ensefolder):
- enseFolderName += os.path.splitext(os.path.basename(ensefolder))[0]
-
- if enseFolderName:
- enseFolderName = '/' + enseFolderName
-
- return enseFolderName
-
- enseFolderName = determineenseFolderName()
- if enseFolderName:
- folder_path = f'{data["export_path"]}{enseFolderName}'
- if not os.path.isdir(folder_path):
- os.mkdir(folder_path)
-
- # Determine File Name
- base_name = f'{data["export_path"]}{enseFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
- enseExport = f'{data["export_path"]}{enseFolderName}/'
- trackname = f'{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
-
- ModelName_1=(c['model_name'])
-
- print('Model Parameters:', c['model_params'])
-
- mp = ModelParameters(c['model_params'])
-
- #Load model
- if os.path.isfile(c['model_location']):
- device = torch.device('cpu')
- model = nets.CascadedASPPNet(mp.param['bins'] * 2)
- model.load_state_dict(torch.load(c['model_location'],
- map_location=device))
- if torch.cuda.is_available() and data['gpu'] >= 0:
- device = torch.device('cuda:{}'.format(data['gpu']))
- model.to(device)
-
- text_widget.write('Done!\n')
-
- model_name = os.path.basename(c["model_name"])
-
- # -Go through the different steps of seperation-
- # Wave source
- text_widget.write(base_text + 'Loading wave source... ')
-
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
-
- bands_n = len(mp.param['band'])
-
- for d in range(bands_n, 0, -1):
- bp = mp.param['band'][d]
-
- if d == bands_n: # high-end band
- X_wave[d], _ = librosa.load(
- music_file, bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
-
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.resample(X_wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
-
- # Stft of wave source
-
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
- mp.param['mid_side_b2'], mp.param['reverse'])
-
- if d == bands_n and args.high_end_process != 'none':
- input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
- input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
-
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.1)
-
- text_widget.write(base_text + 'Stft of wave source... ')
- text_widget.write('Done!\n')
- text_widget.write(base_text + "Please Wait...\n")
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, mp)
-
- del X_wave, X_spec_s
-
- def inference(X_spec, device, model, aggressiveness):
-
- def _execute(X_mag_pad, roi_size, n_window, device, model, aggressiveness):
- model.eval()
-
- with torch.no_grad():
- preds = []
-
- iterations = [n_window]
-
- total_iterations = sum(iterations)
-
- text_widget.write(base_text + "Processing "f"{total_iterations} Slices... ")
-
- for i in tqdm(range(n_window)):
- update_progress(**progress_kwargs,
- step=(0.1 + (0.8/n_window * i)))
- start = i * roi_size
- X_mag_window = X_mag_pad[None, :, :, start:start + data['window_size']]
- X_mag_window = torch.from_numpy(X_mag_window).to(device)
-
- pred = model.predict(X_mag_window, aggressiveness)
-
- pred = pred.detach().cpu().numpy()
- preds.append(pred[0])
-
- pred = np.concatenate(preds, axis=2)
-
- text_widget.write('Done!\n')
- return pred
-
- def preprocess(X_spec):
- X_mag = np.abs(X_spec)
- X_phase = np.angle(X_spec)
-
- return X_mag, X_phase
-
- X_mag, X_phase = preprocess(X_spec)
-
- coef = X_mag.max()
- X_mag_pre = X_mag / coef
-
- n_frame = X_mag_pre.shape[2]
- pad_l, pad_r, roi_size = dataset.make_padding(n_frame,
- data['window_size'], model.offset)
- n_window = int(np.ceil(n_frame / roi_size))
-
- X_mag_pad = np.pad(
- X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
-
- pred = _execute(X_mag_pad, roi_size, n_window,
- device, model, aggressiveness)
- pred = pred[:, :, :n_frame]
-
- if data['tta']:
- pad_l += roi_size // 2
- pad_r += roi_size // 2
- n_window += 1
-
- X_mag_pad = np.pad(
- X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
-
- pred_tta = _execute(X_mag_pad, roi_size, n_window,
- device, model, aggressiveness)
- pred_tta = pred_tta[:, :, roi_size // 2:]
- pred_tta = pred_tta[:, :, :n_frame]
-
- return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.j * X_phase)
- else:
- return pred * coef, X_mag, np.exp(1.j * X_phase)
-
- aggressiveness = {'value': args.aggressiveness, 'split_bin': mp.param['band'][1]['crop_stop']}
-
- if data['tta']:
- text_widget.write(base_text + "Running Inferences (TTA)... \n")
- else:
- text_widget.write(base_text + "Running Inference... \n")
-
- pred, X_mag, X_phase = inference(X_spec_m,
- device,
- model, aggressiveness)
-
- update_progress(**progress_kwargs,
- step=0.85)
-
- # Postprocess
- if data['postprocess']:
- text_widget.write(base_text + 'Post processing... ')
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.85)
-
- # Inverse stft
- text_widget.write(base_text + 'Inverse stft of instruments and vocals... ') # nopep8
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, y_spec_m, input_high_end, mp)
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
-
- if args.high_end_process.startswith('mirroring'):
- input_high_end_ = spec_utils.mirroring(args.high_end_process, v_spec_m, input_high_end, mp)
-
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
-
- text_widget.write('Done!\n')
-
- update_progress(**progress_kwargs,
- step=0.9)
-
- # Save output music files
- text_widget.write(base_text + 'Saving Files... ')
- save_files(wav_instrument, wav_vocals)
- text_widget.write('Done!\n')
-
- # Save output image
- if data['output_image']:
- with open('{}_Instruments.jpg'.format(base_name), mode='wb') as f:
- image = spec_utils.spectrogram_to_image(y_spec_m)
- _, bin_image = cv2.imencode('.jpg', image)
- bin_image.tofile(f)
- with open('{}_Vocals.jpg'.format(base_name), mode='wb') as f:
- image = spec_utils.spectrogram_to_image(v_spec_m)
- _, bin_image = cv2.imencode('.jpg', image)
- bin_image.tofile(f)
-
- text_widget.write(base_text + 'Clearing CUDA Cache... ')
-
- torch.cuda.empty_cache()
- time.sleep(3)
-
- text_widget.write('Done!\n')
-
- text_widget.write(base_text + 'Completed Seperation!\n\n')
-
- # Emsembling Outputs
- def get_files(folder="", prefix="", suffix=""):
- return [f"{folder}{i}" for i in os.listdir(folder) if i.startswith(prefix) if i.endswith(suffix)]
-
- ensambles = [
+ if not data['ensChoose'] == 'User Ensemble':
+ HP1_Models = [
{
- 'algorithm':'min_mag',
- 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
- 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
- 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
- 'type': 'Instrumentals'
+ 'model_name':'1_HP-UVR',
+ 'model_name_c':'1st HP Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/1_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
},
{
- 'algorithm':'max_mag',
- 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
- 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
- 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
- 'type': 'Vocals'
+ 'model_name':'2_HP-UVR',
+ 'model_name_c':'2nd HP Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 2/2'
+ }
+ ]
+
+ HP2_Models = [
+ {
+ 'model_name':'7_HP2-UVR',
+ 'model_name_c':'1st HP2 Model',
+ 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
+ 'model_param_name':'3band_44100_msb2',
+ 'model_location':'models/Main_Models/7_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 1/3'
+ },
+ {
+ 'model_name':'8_HP2-UVR',
+ 'model_name_c':'2nd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/8_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 2/3'
+ },
+ {
+ 'model_name':'9_HP2-UVR',
+ 'model_name_c':'3rd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/9_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 3/3'
+ }
+ ]
+
+ All_HP_Models = [
+ {
+ 'model_name':'7_HP2-UVR',
+ 'model_name_c':'1st HP2 Model',
+ 'model_params':'lib_v5/modelparams/3band_44100_msb2.json',
+ 'model_param_name':'3band_44100_msb2',
+ 'model_location':'models/Main_Models/7_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 1/5'
+
+ },
+ {
+ 'model_name':'8_HP2-UVR',
+ 'model_name_c':'2nd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/8_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 2/5'
+
+ },
+ {
+ 'model_name':'9_HP2-UVR',
+ 'model_name_c':'3rd HP2 Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/9_HP2-UVR.pth',
+ 'using_archtecture': '537238KB',
+ 'loop_name': 'Ensemble Mode - Model 3/5'
+ },
+ {
+ 'model_name':'1_HP-UVR',
+ 'model_name_c':'1st HP Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/1_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 4/5'
+ },
+ {
+ 'model_name':'2_HP-UVR',
+ 'model_name_c':'2nd HP Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 5/5'
+ }
+ ]
+
+ Vocal_Models = [
+ {
+ 'model_name':'3_HP-Vocal-UVR',
+ 'model_name_c':'1st Vocal Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/3_HP-Vocal-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
+ },
+ {
+ 'model_name':'4_HP-Vocal-UVR',
+ 'model_name_c':'2nd Vocal Model',
+ 'model_params':'lib_v5/modelparams/4band_44100.json',
+ 'model_param_name':'4band_44100',
+ 'model_location':'models/Main_Models/4_HP-Vocal-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 2/2'
}
]
- for i, e in tqdm(enumerate(ensambles), desc="Ensembling..."):
-
- text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
-
- wave, specs = {}, {}
-
- mp = ModelParameters(e['model_params'])
-
- for i in range(len(e['files'])):
- spec = {}
-
- for d in range(len(mp.param['band']), 0, -1):
- bp = mp.param['band'][d]
-
- if d == len(mp.param['band']): # high-end band
- wave[d], _ = librosa.load(
- e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
-
- if len(wave[d].shape) == 1: # mono to stereo
- wave[d] = np.array([wave[d], wave[d]])
- else: # lower bands
- wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
-
- spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
-
- specs[i] = spec_utils.combine_spectrograms(spec, mp)
-
- del wave
+ mdx_vr = [
+ {
+ 'model_name':'VR_Model',
+ 'mdx_model_name': 'UVR_MDXNET_9703',
+ 'model_name_c':'VR Model',
+ 'model_params':'lib_v5/modelparams/4band_v2.json',
+ 'model_param_name':'4band_v2',
+ 'model_location':'models/Main_Models/2_HP-UVR.pth',
+ 'using_archtecture': '123821KB',
+ 'loop_name': 'Ensemble Mode - Model 1/2'
+ }
+ ]
- sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
- spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
- specs), mp), mp.param['sr'])
+ if data['ensChoose'] == 'HP Models':
+ loops = HP1_Models
+ ensefolder = 'HP_Models_Ensemble_Outputs'
+ ensemode = 'HP_Models'
+ if data['ensChoose'] == 'HP2 Models':
+ loops = HP2_Models
+ ensefolder = 'HP2_Models_Ensemble_Outputs'
+ ensemode = 'HP2_Models'
+ if data['ensChoose'] == 'All HP/HP2 Models':
+ loops = All_HP_Models
+ ensefolder = 'All_HP_HP2_Models_Ensemble_Outputs'
+ ensemode = 'All_HP_HP2_Models'
+ if data['ensChoose'] == 'Vocal Models':
+ loops = Vocal_Models
+ ensefolder = 'Vocal_Models_Ensemble_Outputs'
+ ensemode = 'Vocal_Models'
+ if data['ensChoose'] == 'MDX-Net/VR Ensemble':
+ loops = mdx_vr
+ ensefolder = 'MDX_VR_Ensemble_Outputs'
+ ensemode = 'MDX-Net_VR'
+
+
+ #Prepare Audiofile(s)
+ for file_num, music_file in enumerate(data['input_paths'], start=1):
+ print(data['input_paths'])
+ # -Get text and update progress-
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=file_num)
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': file_num}
+ update_progress(**progress_kwargs,
+ step=0)
- if not data['save']: # Deletes all outputs if Save All Outputs: is checked
- files = e['files']
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+
+ #Prepare to loop models
+ for i, c in tqdm(enumerate(loops), disable=True, desc='Iterations..'):
+
+ if hp2_ens == 'off' and loops == HP2_Models:
+ text_widget.write(base_text + 'You must install the UVR expansion pack in order to use this ensemble.\n')
+ text_widget.write(base_text + 'Please install the expansion pack or choose another ensemble.\n')
+ text_widget.write(base_text + 'See the \"Updates\" tab in the Help Guide for installation instructions.\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL)
+ return
+ elif hp2_ens == 'off' and loops == All_HP_Models:
+ text_widget.write(base_text + 'You must install the UVR expansion pack in order to use this ensemble.\n')
+ text_widget.write(base_text + 'Please install the expansion pack or choose another ensemble.\n')
+ text_widget.write(base_text + 'See the \"Updates\" tab in the Help Guide for installation instructions.\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL)
+ return
+
+ presentmodel = Path(c['model_location'])
+
+ if presentmodel.is_file():
+ print(f'The file {presentmodel} exist')
+ else:
+ text_widget.write(base_text + 'Model "' + c['model_name'] + '.pth" is missing, moving to next... \n\n')
+ continue
+
+ text_widget.write(c['loop_name'] + '\n\n')
+
+ text_widget.write(base_text + 'Loading ' + c['model_name_c'] + '... ')
+
+ aggresive_set = float(data['agg']/100)
+
+ model_size = math.ceil(os.stat(c['model_location']).st_size / 1024)
+ nn_architecture = '{}KB'.format(min(nn_arch_sizes, key=lambda x:abs(x-model_size)))
+
+ nets = importlib.import_module('lib_v5.nets' + f'_{nn_architecture}'.replace('_{}KB'.format(nn_arch_sizes[0]), ''), package=None)
+
+ text_widget.write('Done!\n')
+
+ ModelName=(c['model_location'])
+
+ #Package Models
+
+ model_hash = hashlib.md5(open(ModelName,'rb').read()).hexdigest()
+ print(model_hash)
+
+ #v5 Models
+
+ if model_hash == '47939caf0cfe52a0e81442b85b971dfd':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '4e4ecb9764c50a8c414fee6e10395bbe':
+ model_params_d=str('lib_v5/modelparams/4band_v2.json')
+ param_name=str('4band_v2')
+ if model_hash == 'e60a1e84803ce4efc0a6551206cc4b71':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'a82f14e75892e55e994376edbf0c8435':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == '6dd9eaa6f0420af9f1d403aaafa4cc06':
+ model_params_d=str('lib_v5/modelparams/4band_v2_sn.json')
+ param_name=str('4band_v2_sn')
+ if model_hash == '5c7bbca45a187e81abbbd351606164e5':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'd6b2cb685a058a091e5e7098192d3233':
+ model_params_d=str('lib_v5/modelparams/3band_44100_msb2.json')
+ param_name=str('3band_44100_msb2')
+ if model_hash == 'c1b9f38170a7c90e96f027992eb7c62b':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+ if model_hash == 'c3448ec923fa0edf3d03a19e633faa53':
+ model_params_d=str('lib_v5/modelparams/4band_44100.json')
+ param_name=str('4band_44100')
+
+ #v4 Models
+
+ if model_hash == '6a00461c51c2920fd68937d4609ed6c8':
+ model_params_d=str('lib_v5/modelparams/1band_sr16000_hl512.json')
+ param_name=str('1band_sr16000_hl512')
+ if model_hash == '0ab504864d20f1bd378fe9c81ef37140':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '7dd21065bf91c10f7fccb57d7d83b07f':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == '80ab74d65e515caa3622728d2de07d23':
+ model_params_d=str('lib_v5/modelparams/1band_sr32000_hl512.json')
+ param_name=str('1band_sr32000_hl512')
+ if model_hash == 'edc115e7fc523245062200c00caa847f':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == '28063e9f6ab5b341c5f6d3c67f2045b7':
+ model_params_d=str('lib_v5/modelparams/1band_sr33075_hl384.json')
+ param_name=str('1band_sr33075_hl384')
+ if model_hash == 'b58090534c52cbc3e9b5104bad666ef2':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == '0cdab9947f1b0928705f518f3c78ea8f':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl512.json')
+ param_name=str('1band_sr44100_hl512')
+ if model_hash == 'ae702fed0238afb5346db8356fe25f13':
+ model_params_d=str('lib_v5/modelparams/1band_sr44100_hl1024.json')
+ param_name=str('1band_sr44100_hl1024')
+
+ def determineenseFolderName():
+ """
+ Determine the name that is used for the folder and appended
+ to the back of the music files
+ """
+ enseFolderName = ''
+
+ if str(ensefolder):
+ enseFolderName += os.path.splitext(os.path.basename(ensefolder))[0]
+
+ if enseFolderName:
+ enseFolderName = '/' + enseFolderName
+
+ return enseFolderName
+
+ enseFolderName = determineenseFolderName()
+ if enseFolderName:
+ folder_path = f'{data["export_path"]}{enseFolderName}'
+ if not os.path.isdir(folder_path):
+ os.mkdir(folder_path)
+
+ # Determine File Name
+ base_name = f'{data["export_path"]}{enseFolderName}/{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+ enseExport = f'{data["export_path"]}{enseFolderName}/'
+ trackname = f'{file_num}_{os.path.splitext(os.path.basename(music_file))[0]}'
+
+ ModelName_1=(c['model_name'])
+
+ try:
+ ModelName_2=(c['mdx_model_name'])
+ except:
+ pass
+
+ print('Model Parameters:', model_params_d)
+ text_widget.write(base_text + 'Loading assigned model parameters ' + '\"' + param_name + '\"... ')
+
+ mp = ModelParameters(model_params_d)
+
+ text_widget.write('Done!\n')
+
+ #Load model
+ if os.path.isfile(c['model_location']):
+ device = torch.device('cpu')
+ model = nets.CascadedASPPNet(mp.param['bins'] * 2)
+ model.load_state_dict(torch.load(c['model_location'],
+ map_location=device))
+ if torch.cuda.is_available() and data['gpu'] >= 0:
+ device = torch.device('cuda:{}'.format(data['gpu']))
+ model.to(device)
+
+ model_name = os.path.basename(c["model_name"])
+
+ # -Go through the different steps of seperation-
+ # Wave source
+ text_widget.write(base_text + 'Loading audio source... ')
+
+ X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
+
+ bands_n = len(mp.param['band'])
+
+ for d in range(bands_n, 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == bands_n: # high-end band
+ X_wave[d], _ = librosa.load(
+ music_file, bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if X_wave[d].ndim == 1:
+ X_wave[d] = np.asarray([X_wave[d], X_wave[d]])
+ else: # lower bands
+ X_wave[d] = librosa.resample(X_wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ # Stft of wave source
+
+ X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(X_wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'],
+ mp.param['mid_side_b2'], mp.param['reverse'])
+
+ if d == bands_n and data['high_end_process'] != 'none':
+ input_high_end_h = (bp['n_fft']//2 - bp['crop_stop']) + (mp.param['pre_filter_stop'] - mp.param['pre_filter_start'])
+ input_high_end = X_spec_s[d][:, bp['n_fft']//2-input_high_end_h:bp['n_fft']//2, :]
+
+ text_widget.write('Done!\n')
+
+ update_progress(**progress_kwargs,
+ step=0.1)
+
+ text_widget.write(base_text + 'Loading the stft of audio source... ')
+ text_widget.write('Done!\n')
+ text_widget.write(base_text + "Please Wait...\n")
+
+ X_spec_m = spec_utils.combine_spectrograms(X_spec_s, mp)
+
+ del X_wave, X_spec_s
+
+ def inference(X_spec, device, model, aggressiveness):
+
+ def _execute(X_mag_pad, roi_size, n_window, device, model, aggressiveness):
+ model.eval()
+
+ with torch.no_grad():
+ preds = []
+
+ iterations = [n_window]
+
+ total_iterations = sum(iterations)
+
+ text_widget.write(base_text + "Processing "f"{total_iterations} Slices... ")
+
+ for i in tqdm(range(n_window)):
+ update_progress(**progress_kwargs,
+ step=(0.1 + (0.8/n_window * i)))
+ start = i * roi_size
+ X_mag_window = X_mag_pad[None, :, :, start:start + data['window_size']]
+ X_mag_window = torch.from_numpy(X_mag_window).to(device)
+
+ pred = model.predict(X_mag_window, aggressiveness)
+
+ pred = pred.detach().cpu().numpy()
+ preds.append(pred[0])
+
+ pred = np.concatenate(preds, axis=2)
+
+ text_widget.write('Done!\n')
+ return pred
+
+ def preprocess(X_spec):
+ X_mag = np.abs(X_spec)
+ X_phase = np.angle(X_spec)
+
+ return X_mag, X_phase
+
+ X_mag, X_phase = preprocess(X_spec)
+
+ coef = X_mag.max()
+ X_mag_pre = X_mag / coef
+
+ n_frame = X_mag_pre.shape[2]
+ pad_l, pad_r, roi_size = dataset.make_padding(n_frame,
+ data['window_size'], model.offset)
+ n_window = int(np.ceil(n_frame / roi_size))
+
+ X_mag_pad = np.pad(
+ X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
+
+ pred = _execute(X_mag_pad, roi_size, n_window,
+ device, model, aggressiveness)
+ pred = pred[:, :, :n_frame]
+
+ if data['tta']:
+ pad_l += roi_size // 2
+ pad_r += roi_size // 2
+ n_window += 1
+
+ X_mag_pad = np.pad(
+ X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode='constant')
+
+ pred_tta = _execute(X_mag_pad, roi_size, n_window,
+ device, model, aggressiveness)
+ pred_tta = pred_tta[:, :, roi_size // 2:]
+ pred_tta = pred_tta[:, :, :n_frame]
+
+ return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.j * X_phase)
+ else:
+ return pred * coef, X_mag, np.exp(1.j * X_phase)
+
+ aggressiveness = {'value': aggresive_set, 'split_bin': mp.param['band'][1]['crop_stop']}
+
+ if data['tta']:
+ text_widget.write(base_text + "Running Inferences (TTA)... \n")
+ else:
+ text_widget.write(base_text + "Running Inference... \n")
+
+ pred, X_mag, X_phase = inference(X_spec_m,
+ device,
+ model, aggressiveness)
+
+ update_progress(**progress_kwargs,
+ step=0.85)
+
+ # Postprocess
+ if data['postprocess']:
+ try:
+ text_widget.write(base_text + 'Post processing...')
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ text_widget.write(' Done!\n')
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Post process failed, check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run Post Processing on "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ # Inverse stft
+ # nopep8
+ y_spec_m = pred * X_phase
+ v_spec_m = X_spec_m - y_spec_m
+
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Instrumental... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], y_spec_m, input_high_end, mp)
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+ else:
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, mp)
+ if data['voc_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write(base_text + 'Saving Vocals... ')
+
+ if data['high_end_process'].startswith('mirroring'):
+ input_high_end_ = spec_utils.mirroring(data['high_end_process'], v_spec_m, input_high_end, mp)
+
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp, input_high_end_h, input_high_end_)
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+ else:
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, mp)
+ if data['inst_only']:
+ pass
+ else:
+ text_widget.write('Done!\n')
+
+
+ update_progress(**progress_kwargs,
+ step=0.9)
+
+ # Save output music files
+ save_files(wav_instrument, wav_vocals)
+
+ # Save output image
+ if data['output_image']:
+ with open('{}_Instruments.jpg'.format(base_name), mode='wb') as f:
+ image = spec_utils.spectrogram_to_image(y_spec_m)
+ _, bin_image = cv2.imencode('.jpg', image)
+ bin_image.tofile(f)
+ with open('{}_Vocals.jpg'.format(base_name), mode='wb') as f:
+ image = spec_utils.spectrogram_to_image(v_spec_m)
+ _, bin_image = cv2.imencode('.jpg', image)
+ bin_image.tofile(f)
+
+ text_widget.write(base_text + 'Completed Seperation!\n\n')
+
+
+ if data['ensChoose'] == 'MDX-Net/VR Ensemble':
+ text_widget.write('Ensemble Mode - Model 2/2\n\n')
+
+ update_progress(**progress_kwargs,
+ step=0)
+
+ if data['noisereduc_s'] == 'None':
+ pass
+ else:
+ if not os.path.isfile("lib_v5\sox\sox.exe"):
+ data['noisereduc_s'] = 'None'
+ data['non_red'] = False
+ widget_text.write(base_text + 'SoX is missing and required for noise reduction.\n')
+ widget_text.write(base_text + 'See the \"More Info\" tab in the Help Guide.\n')
+ widget_text.write(base_text + 'Noise Reduction will be disabled until SoX is available.\n\n')
+
+ e = os.path.join(data["export_path"])
+
+ demucsmodel = 'models/Demucs_Model/demucs_extra-3646af93_org.th'
+
+ pred = Predictor()
+ pred.prediction_setup(demucs_name=demucsmodel,
+ channels=channel_set)
+
+ # split
+ pred.prediction(
+ m=music_file,
+ )
+ else:
+ pass
+
+
+ # Emsembling Outputs
+ def get_files(folder="", prefix="", suffix=""):
+ return [f"{folder}{i}" for i in os.listdir(folder) if i.startswith(prefix) if i.endswith(suffix)]
+
+ voc_inst = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
+ 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
+ 'type': 'Instrumentals'
+ },
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
+ 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
+ 'type': 'Vocals'
+ }
+ ]
+
+ inst = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav"),
+ 'output':'{}_Ensembled_{}_(Instrumental)'.format(trackname, ensemode),
+ 'type': 'Instrumentals'
+ }
+ ]
+
+ vocal = [
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'files':get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav"),
+ 'output': '{}_Ensembled_{}_(Vocals)'.format(trackname, ensemode),
+ 'type': 'Vocals'
+ }
+ ]
+
+ if data['voc_only']:
+ ensembles = vocal
+ elif data['inst_only']:
+ ensembles = inst
+ else:
+ ensembles = voc_inst
+
+ try:
+ for i, e in tqdm(enumerate(ensembles), desc="Ensembling..."):
+
+ text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(e['files'])):
+
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ e['files'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
+ specs), mp), mp.param['sr'])
+
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.mp3'.format(e['output']))), format="mp3", bitrate="320k")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as mp3 "{os.path.basename(music_file)}".\n\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.flac'.format(e['output']))), format="flac")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ else:
+ text_widget.write(base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on... ')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to save file as flac "{os.path.basename(music_file)}".\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ text_widget.write("Done!\n")
+ except:
+ text_widget.write('\n' + base_text + 'Not enough files to ensemble.')
+ pass
+
+ update_progress(**progress_kwargs,
+ step=0.95)
+ text_widget.write("\n")
+
+ try:
+ if not data['save']: # Deletes all outputs if Save All Outputs isn't checked
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
for file in files:
os.remove(file)
+ if not data['save']:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ if data['save'] and data['saveFormat'] == 'Mp3':
+ try:
+ text_widget.write(base_text + 'Saving all ensemble outputs in Mp3... ')
+ path = enseExport
+ #Change working directory
+ os.chdir(path)
+ audio_files = os.listdir()
+ for file in audio_files:
+ #spliting the file into the name and the extension
+ name, ext = os.path.splitext(file)
+ if ext == ".wav":
+ if trackname in file:
+ musfile = pydub.AudioSegment.from_wav(file)
+ #rename them using the old name + ".wav"
+ musfile.export("{0}.mp3".format(name), format="mp3", bitrate="320k")
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ text_widget.write('Done!\n\n')
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ except Exception as e:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'\nError Received while attempting to save ensembled outputs as mp3s.\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+ if data['save'] and data['saveFormat'] == 'Flac':
+ try:
+ text_widget.write(base_text + 'Saving all ensemble outputs in Flac... ')
+ path = enseExport
+ #Change working directory
+ os.chdir(path)
+ audio_files = os.listdir()
+ for file in audio_files:
+ #spliting the file into the name and the extension
+ name, ext = os.path.splitext(file)
+ if ext == ".wav":
+ if trackname in file:
+ musfile = pydub.AudioSegment.from_wav(file)
+ #rename them using the old name + ".wav"
+ musfile.export("{0}.flac".format(name), format="flac")
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Vocals).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+ try:
+ files = get_files(folder=enseExport, prefix=trackname, suffix="_(Instrumental).wav")
+ for file in files:
+ os.remove(file)
+ except:
+ pass
+
+ text_widget.write('Done!\n\n')
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+
+ except Exception as e:
+ base_path = os.path.dirname(os.path.abspath(__file__))
+ os.chdir(base_path)
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if "ffmpeg" in errmessage:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ else:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Flac(s).\n')
+ text_widget.write(base_text + 'Please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'\nError Received while attempting to ensembled outputs as Flacs.\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+
+
+ try:
+ os.remove('temp.wav')
+ except:
+ pass
+
+ if len(os.listdir(enseExport)) == 0: #Check if the folder is empty
+ shutil.rmtree(folder_path) #Delete folder if empty
+
+ else:
+ progress_kwargs = {'progress_var': progress_var,
+ 'total_files': len(data['input_paths']),
+ 'file_num': len(data['input_paths'])}
+ base_text = get_baseText(total_files=len(data['input_paths']),
+ file_num=len(data['input_paths']))
+
+ try:
+ total, used, free = shutil.disk_usage("/")
+
+ total_space = int(total/1.074e+9)
+ used_space = int(used/1.074e+9)
+ free_space = int(free/1.074e+9)
+
+ if int(free/1.074e+9) <= int(2):
+ text_widget.write('Error: Not enough storage on main drive to continue. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly. \n\nPlease ensure your main drive has at least 3 GB\'s of storage and try again.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n')
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if int(free/1.074e+9) in [3, 4, 5, 6, 7, 8]:
+ text_widget.write('Warning: Your main drive is running low on storage. Your main drive must have \nat least 3 GB\'s of storage in order for this application function properly.\n\n')
+ text_widget.write('Detected Total Space: ' + str(total_space) + ' GB' + '\n')
+ text_widget.write('Detected Used Space: ' + str(used_space) + ' GB' + '\n')
+ text_widget.write('Detected Free Space: ' + str(free_space) + ' GB' + '\n\n')
+ except:
+ pass
+
+ music_file = data['input_paths']
+ if len(data['input_paths']) <= 1:
+ text_widget.write(base_text + "Not enough files to process.\n")
+ pass
+ else:
+ update_progress(**progress_kwargs,
+ step=0.2)
+
+ savefilename = (data['input_paths'][0])
+ trackname1 = f'{os.path.splitext(os.path.basename(savefilename))[0]}'
+
+ insts = [
+ {
+ 'algorithm':'min_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output':'{}_User_Ensembled_(Min Spec)'.format(trackname1),
+ 'type': 'Instrumentals'
+ }
+ ]
+
+ vocals = [
+ {
+ 'algorithm':'max_mag',
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_User_Ensembled_(Max Spec)'.format(trackname1),
+ 'type': 'Vocals'
+ }
+ ]
+
+ invert_spec = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_diff_si'.format(trackname1),
+ 'type': 'Spectral Inversion'
+ }
+ ]
+
+ invert_nor = [
+ {
+ 'model_params':'lib_v5/modelparams/1band_sr44100_hl512.json',
+ 'output': '{}_diff_ni'.format(trackname1),
+ 'type': 'Normal Inversion'
+ }
+ ]
+
+ if data['algo'] == 'Instrumentals (Min Spec)':
+ ensem = insts
+ if data['algo'] == 'Vocals (Max Spec)':
+ ensem = vocals
+ if data['algo'] == 'Invert (Spectral)':
+ ensem = invert_spec
+ if data['algo'] == 'Invert (Normal)':
+ ensem = invert_nor
+
+ #Prepare to loop models
+ if data['algo'] == 'Instrumentals (Min Spec)' or data['algo'] == 'Vocals (Max Spec)':
+ for i, e in tqdm(enumerate(ensem), desc="Ensembling..."):
+ text_widget.write(base_text + "Ensembling " + e['type'] + "... ")
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(data['input_paths'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ data['input_paths'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(spec_utils.ensembling(e['algorithm'],
+ specs), mp), mp.param['sr'])
+
+ if data['saveFormat'] == 'Mp3':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.mp3'.format(e['output']))), format="mp3", bitrate="320k")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Failed to save output(s) as Mp3.')
+ text_widget.write('\n' + base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ text_widget.write(base_text + f'Complete!\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run user ensemble:\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL)
+
+ return
+
+ if data['saveFormat'] == 'Flac':
+ try:
+ musfile = pydub.AudioSegment.from_wav(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])))
+ musfile.export((os.path.join('{}'.format(data['export_path']),'{}.flac'.format(e['output']))), format="flac")
+ os.remove((os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output']))))
+ except Exception as e:
+ text_widget.write('\n' + base_text + 'Failed to save output as Flac.\n')
+ text_widget.write(base_text + 'FFmpeg might be missing or corrupted, please check error log.\n')
+ text_widget.write(base_text + 'Moving on...\n')
+ text_widget.write(base_text + f'Complete!\n')
+ traceback_text = ''.join(traceback.format_tb(e.__traceback__))
+ errmessage = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while attempting to run user ensemble:\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'FFmpeg might be missing or corrupted.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ errmessage + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL)
+ return
+
text_widget.write("Done!\n")
+ if data['algo'] == 'Invert (Spectral)' and data['algo'] == 'Invert (Normal)':
+ if len(data['input_paths']) != 2:
+ text_widget.write(base_text + "Invalid file count.\n")
+ pass
+ else:
+ for i, e in tqdm(enumerate(ensem), desc="Inverting..."):
+
+ wave, specs = {}, {}
+
+ mp = ModelParameters(e['model_params'])
+
+ for i in range(len(data['input_paths'])):
+ spec = {}
+
+ for d in range(len(mp.param['band']), 0, -1):
+ bp = mp.param['band'][d]
+
+ if d == len(mp.param['band']): # high-end band
+ wave[d], _ = librosa.load(
+ data['input_paths'][i], bp['sr'], False, dtype=np.float32, res_type=bp['res_type'])
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(wave[d+1], mp.param['band'][d+1]['sr'], bp['sr'], res_type=bp['res_type'])
+
+ spec[d] = spec_utils.wave_to_spectrogram(wave[d], bp['hl'], bp['n_fft'], mp.param['mid_side'], mp.param['mid_side_b2'], mp.param['reverse'])
+
+ specs[i] = spec_utils.combine_spectrograms(spec, mp)
+
+ del wave
+
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:,:,:ln]
+ specs[1] = specs[1][:,:,:ln]
+ if data['algo'] == 'Invert (Spectral)':
+ text_widget.write(base_text + "Performing " + e['type'] + "... ")
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.j * np.angle(specs[0]))
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(-v_spec, mp), mp.param['sr'])
+ if data['algo'] == 'Invert (Normal)':
+ v_spec = specs[0] - specs[1]
+ sf.write(os.path.join('{}'.format(data['export_path']),'{}.wav'.format(e['output'])),
+ spec_utils.cmb_spectrogram_to_wave(v_spec, mp), mp.param['sr'])
+ text_widget.write("Done!\n")
+
+
- update_progress(**progress_kwargs,
- step=0.95)
- text_widget.write("\n")
-
except Exception as e:
traceback_text = ''.join(traceback.format_tb(e.__traceback__))
- message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\nFile: {music_file}\nPlease contact the creator and attach a screenshot of this error with the file and settings that caused it!'
- tk.messagebox.showerror(master=window,
- title='Untracked Error',
- message=message)
+ message = f'Traceback Error: "{traceback_text}"\n{type(e).__name__}: "{e}"\n'
+ if runtimeerr in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Your PC cannot process this audio file with the chunk size selected.\nPlease lower the chunk size and try again.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp: [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if cuda_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please close any GPU intensive applications and try again.\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please close any GPU intensive applications and try again.\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ f'Raw error details:\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if mod_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Application files(s) are missing.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write(f'Please check for missing files/scripts in the app directory and try again.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Application files(s) are missing.\n' +
+ f'Please check for missing files/scripts in the app directory and try again.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if file_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Missing file error raised.\n')
+ text_widget.write("\n" + f'{type(e).__name__} - "{e}"' + "\n\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Missing file error raised.\n' +
+ "\n" + f'Please address the error and try again.' + "\n" +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if ffmp_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The input file type is not supported or FFmpeg is missing.\n')
+ text_widget.write(f'Please select a file type supported by FFmpeg and try again.\n\n')
+ text_widget.write(f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files \nuntil it is available on this system.\n\n')
+ text_widget.write(f'See the \"More Info\" tab in the Help Guide.\n\n')
+ text_widget.write(f'If this error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The input file type is not supported or FFmpeg is missing.\nPlease select a file type supported by FFmpeg and try again.\n\n' +
+ f'If FFmpeg is missing or not installed, you will only be able to process \".wav\" files until it is available on this system.\n\n' +
+ f'See the \"More Info\" tab in the Help Guide.\n\n' +
+ f'If this error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmissing in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application could not detect this MDX-Net model on your system.\n')
+ text_widget.write(f'Please make sure all the models are present in the correct directory.\n')
+ text_widget.write(f'If the error persists, please reinstall application or contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application could not detect this MDX-Net model on your system.\n' +
+ f'Please make sure all the models are present in the correct directory.\n' +
+ f'If the error persists, please reinstall application or contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if onnxmemerror in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'The application was unable to allocate enough GPU memory to use this model.\n')
+ text_widget.write(f'Please do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n')
+ text_widget.write(f'If the error persists, your GPU might not be supported.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'The application was unable to allocate enough GPU memory to use this model.\n' +
+ f'Please do the following:\n\n1. Close any GPU intensive applications.\n2. Lower the set chunk size.\n3. Then try again.\n\n' +
+ f'If the error persists, your GPU might not be supported.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
+ if sf_write_err in message:
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n\n')
+ text_widget.write(f'Could not write audio file.\n')
+ text_widget.write(f'This could be due to low storage on target device or a system permissions issue.\n')
+ text_widget.write(f"\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write(f'\nIf the error persists, please contact the developers.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'Could not write audio file.\n' +
+ f'This could be due to low storage on target device or a system permissions issue.\n' +
+ f'If the error persists, please contact the developers.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ pass
+ torch.cuda.empty_cache()
+ progress_var.set(0)
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
print(traceback_text)
print(type(e).__name__, e)
print(message)
- progress_var.set(0)
- button_widget.configure(state=tk.NORMAL) #Enable Button
- return
-
- if len(os.listdir(enseExport)) == 0: #Check if the folder is empty
- shutil.rmtree(folder_path) #Delete folder if empty
+ try:
+ with open('errorlog.txt', 'w') as f:
+ f.write(f'Last Error Received:\n\n' +
+ f'Error Received while processing "{os.path.basename(music_file)}":\n' +
+ f'Process Method: Ensemble Mode\n\n' +
+ f'If this error persists, please contact the developers with the error details.\n\n' +
+ message + f'\nError Time Stamp [{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]\n')
+ except:
+ tk.messagebox.showerror(master=window,
+ title='Error Details',
+ message=message)
+ progress_var.set(0)
+ text_widget.write("\n" + base_text + f'Separation failed for the following audio file:\n')
+ text_widget.write(base_text + f'"{os.path.basename(music_file)}"\n')
+ text_widget.write(f'\nError Received:\n')
+ text_widget.write("\nFor raw error details, go to the Error Log tab in the Help Guide.\n")
+ text_widget.write("\n" + f'Please address the error and try again.' + "\n")
+ text_widget.write(f'If this error persists, please contact the developers with the error details.\n\n')
+ text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}')
+ torch.cuda.empty_cache()
+ button_widget.configure(state=tk.NORMAL) # Enable Button
+ return
+
update_progress(**progress_kwargs,
step=1)
-
- print('Done!')
-
- os.remove('temp.wav')
+
+ print('Done!')
+
progress_var.set(0)
- text_widget.write(f'Conversions Completed!\n')
+ if not data['ensChoose'] == 'User Ensemble':
+ text_widget.write(base_text + f'Conversions Completed!\n')
+ elif data['algo'] == 'Instrumentals (Min Spec)' and len(data['input_paths']) <= 1 or data['algo'] == 'Vocals (Max Spec)' and len(data['input_paths']) <= 1:
+ text_widget.write(base_text + f'Please select 2 or more files to use this feature and try again.\n')
+ elif data['algo'] == 'Instrumentals (Min Spec)' or data['algo'] == 'Vocals (Max Spec)':
+ text_widget.write(base_text + f'Ensemble Complete!\n')
+ elif len(data['input_paths']) != 2 and data['algo'] == 'Invert (Spectral)' or len(data['input_paths']) != 2 and data['algo'] == 'Invert (Normal)':
+ text_widget.write(base_text + f'Please select exactly 2 files to extract difference.\n')
+ elif data['algo'] == 'Invert (Spectral)' or data['algo'] == 'Invert (Normal)':
+ text_widget.write(base_text + f'Complete!\n')
+
text_widget.write(f'Time Elapsed: {time.strftime("%H:%M:%S", time.gmtime(int(time.perf_counter() - stime)))}') # nopep8
torch.cuda.empty_cache()
button_widget.configure(state=tk.NORMAL) #Enable Button
diff --git a/lib_v5/fonts/centurygothic/GOTHIC.TTF b/lib_v5/fonts/centurygothic/GOTHIC.TTF
new file mode 100644
index 0000000..c60a324
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHIC.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICB.TTF b/lib_v5/fonts/centurygothic/GOTHICB.TTF
new file mode 100644
index 0000000..d3577b9
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICB.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICBI.TTF b/lib_v5/fonts/centurygothic/GOTHICBI.TTF
new file mode 100644
index 0000000..d01cefa
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICBI.TTF differ
diff --git a/lib_v5/fonts/centurygothic/GOTHICI.TTF b/lib_v5/fonts/centurygothic/GOTHICI.TTF
new file mode 100644
index 0000000..777a6d8
Binary files /dev/null and b/lib_v5/fonts/centurygothic/GOTHICI.TTF differ
diff --git a/lib_v5/fonts/unispace/unispace.ttf b/lib_v5/fonts/unispace/unispace.ttf
new file mode 100644
index 0000000..6151186
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_bd.ttf b/lib_v5/fonts/unispace/unispace_bd.ttf
new file mode 100644
index 0000000..5312426
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_bd.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_bd_it.ttf b/lib_v5/fonts/unispace/unispace_bd_it.ttf
new file mode 100644
index 0000000..8f14509
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_bd_it.ttf differ
diff --git a/lib_v5/fonts/unispace/unispace_it.ttf b/lib_v5/fonts/unispace/unispace_it.ttf
new file mode 100644
index 0000000..be4b6e8
Binary files /dev/null and b/lib_v5/fonts/unispace/unispace_it.ttf differ
diff --git a/lib_v5/layers.py b/lib_v5/layers.py
new file mode 100644
index 0000000..e48d70b
--- /dev/null
+++ b/lib_v5/layers.py
@@ -0,0 +1,116 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/layers_33966KB.py b/lib_v5/layers_33966KB.py
new file mode 100644
index 0000000..d410a21
--- /dev/null
+++ b/lib_v5/layers_33966KB.py
@@ -0,0 +1,122 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/layers_537227KB.py b/lib_v5/layers_537227KB.py
new file mode 100644
index 0000000..d410a21
--- /dev/null
+++ b/lib_v5/layers_537227KB.py
@@ -0,0 +1,122 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin, nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False),
+ nn.Conv2d(
+ nin, nout,
+ kernel_size=1,
+ bias=False),
+ nn.BatchNorm2d(nout),
+ activ()
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ)
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ)
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ)
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ),
+ nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(self.conv1(x), size=(h, w), mode='bilinear', align_corners=True)
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/lib_v5/nets.py b/lib_v5/nets.py
new file mode 100644
index 0000000..b5a8417
--- /dev/null
+++ b/lib_v5/nets.py
@@ -0,0 +1,113 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers
+from lib_v5 import spec_utils
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/nets_33966KB.py b/lib_v5/nets_33966KB.py
new file mode 100644
index 0000000..07e2b8c
--- /dev/null
+++ b/lib_v5/nets_33966KB.py
@@ -0,0 +1,112 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers_33966KB as layers
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16, 32)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/nets_537227KB.py b/lib_v5/nets_537227KB.py
new file mode 100644
index 0000000..566e3f9
--- /dev/null
+++ b/lib_v5/nets_537227KB.py
@@ -0,0 +1,113 @@
+import torch
+import numpy as np
+from torch import nn
+import torch.nn.functional as F
+
+from lib_v5 import layers_537238KB as layers
+
+
+class BaseASPPNet(nn.Module):
+
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 64)
+ self.stg1_high_band_net = BaseASPPNet(2, 64)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(32, 64)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(130, 64, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(64, 128)
+
+ self.out = nn.Conv2d(128, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(64, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, :self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat([
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:])
+ ], dim=2)
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode='replicate')
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode='replicate')
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode='replicate')
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, :aggressiveness['split_bin']] = torch.pow(mask[:, :, :aggressiveness['split_bin']], 1 + aggressiveness['value'] / 3)
+ mask[:, :, aggressiveness['split_bin']:] = torch.pow(mask[:, :, aggressiveness['split_bin']:], 1 + aggressiveness['value'])
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset:-self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/lib_v5/sox/Sox goes here.txt b/lib_v5/sox/Sox goes here.txt
new file mode 100644
index 0000000..2d03d25
--- /dev/null
+++ b/lib_v5/sox/Sox goes here.txt
@@ -0,0 +1 @@
+Sox goes here
\ No newline at end of file
diff --git a/lib_v5/sox/mdxnetnoisereduc.prof b/lib_v5/sox/mdxnetnoisereduc.prof
new file mode 100644
index 0000000..e84270d
--- /dev/null
+++ b/lib_v5/sox/mdxnetnoisereduc.prof
@@ -0,0 +1,2 @@
+Channel 0: -7.009383, -9.291822, -8.961462, -8.988426, -8.133916, -7.550877, -6.823206, -8.324312, -7.926179, -8.284890, -7.006778, -7.520769, -6.676938, -7.599460, -7.296249, -7.862341, -7.603068, -7.957884, -6.943116, -7.064777, -6.617763, -6.976608, -6.474446, -6.976694, -6.775996, -7.173531, -6.239498, -7.433953, -7.435424, -7.556505, -6.661156, -7.537329, -6.869858, -7.345681, -6.348115, -7.624833, -7.356656, -7.397345, -7.268706, -8.009533, -7.879307, -7.206394, -7.595149, -8.183835, -7.877466, -7.849053, -6.575886, -7.970041, -7.973623, -8.654870, -8.238590, -8.322275, -7.080089, -8.381072, -8.166994, -8.211880, -6.978457, -8.440431, -8.660172, -8.568000, -7.374925, -7.825880, -7.727026, -8.436455, -8.058270, -7.776336, -7.163500, -8.324635, -7.496432, -8.231029, -8.168671, -8.803044, -8.365684, -8.284722, -7.717031, -7.899992, -6.716974, -7.789536, -8.123308, -8.718283, -8.127323, -8.608119, -7.955237, -8.195423, -8.562821, -8.923180, -8.620318, -8.362193, -7.892359, -9.106509, -8.866467, -8.334931, -8.432192, -7.981750, -8.118553, -8.357300, -8.303634, -8.951071, -8.357619, -8.628114, -8.194091, -8.329184, -8.479573, -9.059311, -8.928500, -8.971485, -8.930757, -7.888778, -8.512952, -8.701514, -8.509488, -7.927048, -8.980245, -9.453869, -8.502084, -9.179351, -9.352121, -8.612514, -8.515877, -8.990332, -8.064332, -9.353903, -9.226296, -8.582130, -8.062571, -8.975781, -8.985588, -9.084478, -9.475922, -9.627264, -8.866921, -9.788176, -9.405965, -9.690348, -9.697125, -9.834449, -9.723495, -9.551198, -9.067146, -8.391362, -8.062964, -8.664368, -8.834053, -9.365320, -8.774260, -8.826809, -8.938656, -8.571966, -9.301930, -8.476783, -9.083561, -9.606360, -9.013194, -9.633930, -9.361920, -8.814354, -8.210675, -8.741395, -8.973019, -9.735017, -9.445080, -9.970575, -9.387616, -8.885903, -8.364945, -8.181610, -9.367054, -9.632653, -9.174005, -9.669417, -9.632316, -8.792030, -8.639747, -8.757731, -8.189369, -8.609264, -9.203773, -9.027173, -9.267983, -9.038571, -8.480053, -8.989291, -9.334651, -8.989846, -8.505489, -9.093593, -8.603022, -8.935084, -8.995838, -9.807545, -9.936930, -9.858782, -9.525642, -9.342257, -9.687481, -10.109383, -9.415607, -9.960437, -9.511531, -9.512959, -9.410252, -9.463380, -8.009910, -9.010445, -7.930557, -8.907247, -8.696819, -7.628914, -8.656908, -9.540818, -9.834308, -10.149171, -9.603844, -9.368526, -9.262289, -9.177496, -7.941667, -8.894559, -9.577237, -9.213502, -8.329892, -8.875650, -8.551803, -7.293085, -7.970225, -8.689839, -9.213015, -8.729056, -8.370025, -9.476679, -9.801536, -8.779216, -7.794588, -8.743565, -8.677839, -8.659505, -8.530433, -9.471109, -8.952149, -9.026676, -8.581315, -8.305970, -7.698102, -9.075556, -8.994505, -9.525378, -9.427664, -8.896355, -7.806924, -8.713507, -8.001523, -8.820920, -8.825943, -9.033789, -8.943538, -8.305934, -7.843387, -8.222633, -9.394885, -9.639977, -9.382100, -9.858908, -9.861235, -9.617870, -9.572075, -8.937280, -7.900751, -8.817468, -8.367288, -8.198920, -8.835616, -9.120554, -9.430250, -9.599668, -8.890237, -9.182921, -9.068647, -9.198983, -9.219759, -8.444858, -8.306649, -9.081246, -9.658321, -9.175613, -9.559673, -9.202353, -8.468946, -8.959963, -8.611696, -9.287626, -9.178090, -9.829329, -9.418147, -8.433018, -6.759007, -7.992561, -8.209750, -8.367482, -8.160244, -8.659845, -8.142351, -8.449805, -9.052549, -8.108782, -9.131697, -8.656035, -8.754751, -8.799905, -9.252805, -9.666502, -8.742819, -8.779405, -9.290927, -9.100673, -8.813067, -7.968793, -8.372980, -8.334048, -8.766193, -8.525885, -8.295012, -9.267423, -8.512022, -8.716763, -7.543527, -8.133463, -8.899957, -8.884852, -8.879415, -8.921800, -8.989868, -8.456031, -8.742332, -8.387804, -9.199132, -9.269713, -8.533924, -9.031591, -9.510307, -9.003630, -8.032389, -8.199724, -9.178456, -9.109508, -8.830519, -8.833589, -9.138852, -8.359014, -9.055459, -9.124282, -8.931469, -8.293803, -8.784939, -8.829195, -8.204985, -8.832497, -9.291157, -9.229586, -8.902256, -7.836384, -8.558482, -9.045199, -8.784686, -8.640361, -8.122143, -8.856282, -9.933563, -10.433572, -10.053477, -9.901992, -9.234422, -8.272216, -7.767568, -8.634153, -9.037672, -7.966586, -7.879588, -8.073919, -7.618028, -8.733914, -9.367538, -9.360283, -8.472114, -8.424832, -8.244030, -8.266778, -8.279402, -8.488133, -8.574222, -8.015083, -7.603164, -7.773276, -7.969313, -8.463429, -8.327254, -8.908369, -8.842388, -8.697819, -9.069319, -8.471298, -8.487786, -7.722121, -7.005715, -6.071240, -4.913710, -5.252938, -6.890169, -8.112794, -8.627293, -8.763681, -8.730070, -8.663003, -8.490945, -8.165999, -7.835065, -7.929111, -8.760281, -9.092809, -8.427891, -8.396054, -7.063385, -8.432428, -8.356983, -8.770448, -8.572601, -8.279242, -8.050529, -9.172235, -9.494339, -9.115856, -8.913443, -9.234514, -8.266346, -8.655711, -7.904694, -8.750291, -8.669807, -8.733426, -8.195509, -8.445010, -8.608845, -9.364661, -8.545942, -9.320732, -8.908144, -8.906418, -8.977945, -8.351475, -8.425015, -8.580469, -8.635973, -8.587179, -8.825187, -8.613693, -8.572787, -9.008575, -9.139839, -8.730886, -8.378273, -8.104312, -7.693113, -8.144767, -7.909862, -8.660356, -8.560781, -8.402486, -8.329734, -8.549006, -8.467747, -7.797524, -8.701290, -8.745170, -9.123959, -8.828640, -8.034152, -8.244606, -7.922297, -8.304344, -8.390489, -8.384267, -8.804485, -8.274789, -7.641120, -7.419797, -6.875395, -7.779922, -8.285890, -8.435658, -8.243375, -8.234133, -8.147679, -7.876873, -7.560720, -8.453065, -7.912884, -8.321675, -8.351012, -8.551875, -8.245539, -8.157014, -8.045531, -8.802874, -7.939998, -8.531658, -8.286127, -8.426950, -7.872053, -7.950769, -8.103668, -7.361780, -7.233630, -8.588113, -8.391391, -8.025829, -7.778002, -6.812353, -6.892645, -8.379886, -8.968739, -9.232736, -7.678606, -8.519589, -7.233673, -7.732607, -7.712150, -8.588383, -7.141524, -8.350538, -7.687734, -8.350335, -7.299619, -7.251563, -7.551582, -7.601188, -8.913805, -8.327199, -8.351825, -9.285121, -8.206786, -7.760271, -5.924285, -7.253280, -7.920683, -8.456389, -8.348553, -8.304132, -7.914664, -7.378574, -6.740644, -8.366895, -7.828516, -8.495502, -8.358516, -8.638541, -8.803589, -7.815868, -6.526936, -8.311996, -8.795187, -8.682474, -7.771255, -8.021541, -7.061438, -8.140287, -8.479327, -8.769970, -9.137885, -8.767818, -8.507115, -7.818171, -7.023338, -6.684543, -7.590823, -7.973853, -7.125487, -6.444645, -5.015516, -5.527578, -4.825749, -6.076069, -6.067105, -6.832324, -6.415292, -7.687704, -7.876131, -8.185242, -7.719656, -8.129504, -7.591390, -7.471135, -8.264959, -7.372910, -6.003157, -7.699708, -8.063796, -6.937130, -6.498588, -6.515582, -6.480911, -6.705885, -7.971720, -8.244526, -7.773425, -8.179802, -7.852663, -7.736978, -7.450927, -7.798478, -7.171562, -7.725062, -7.005856, -6.939411, -7.545801, -7.298831, -7.866823, -7.788211, -6.324419, -6.972910, -6.354499, -6.692432, -7.116762, -8.336053, -8.031844, -7.638197, -6.962282, -7.762571, -7.219688, -7.684484, -6.576585, -6.971768, -6.049053, -5.645847, -5.826155, -5.018756, -6.294459, -7.700381, -8.087517, -7.940284, -8.351140, -7.342774, -5.678021, -7.577646, -8.088142, -7.801032, -6.492934, -7.910668, -7.328195, -7.128594, -6.916883, -5.799251, -6.564095, -6.370745, -5.558840, -7.342127, -7.275418, -6.746891, -7.759083, -6.735355, -6.476465, -6.283120, -7.176216, -7.664367, -6.443789, -5.538641, -5.694131, -7.232028, -7.065130, -7.523064, -6.623515, -5.389147, -3.544363, -5.611296, -6.213579, -6.530970, -6.581829, -6.395981, -7.651325, -7.012158, -8.015069, -7.575516, -7.032994, -5.677541, -3.718229, -6.020396, -7.988893, -9.343635, -9.945617, -10.323884, -10.642690, -10.876016, -11.078479, -11.255501, -11.395584, -11.483764, -11.557805, -11.698310, -11.737680, -11.840640, -11.912717, -11.909139, -11.977159, -11.978605, -12.038353, -12.093234, -12.111259, -12.121384, -12.176933, -12.171291, -12.176199, -12.198986, -12.233503, -12.275017, -12.265485, -12.274396, -12.241486, -12.261465, -12.282915, -12.275353, -12.276109, -12.255538, -12.296432, -12.243854, -12.250940, -12.222560, -12.250113, -12.183066, -12.247768, -12.242023, -12.285899, -12.235859, -12.219860, -12.231251, -12.265896, -12.266792, -12.217250, -12.292002, -12.251619, -12.283025, -12.208677, -12.143500, -12.194249, -12.168472, -12.159037, -12.136466, -12.175126, -12.182810, -12.148365, -12.157288, -12.111798, -12.070856, -12.088792, -12.088619, -12.050185, -12.073867, -12.053141, -12.079345, -12.013352, -11.999766, -12.055408, -11.965831, -11.985056, -11.968968, -11.961904, -11.959881, -12.045696, -11.965464, -11.966563, -11.887108, -11.874594, -11.889680, -11.904971, -11.870472, -11.882454, -11.926828, -11.848092, -11.827531, -11.810616, -11.798046, -11.860422, -11.843547, -11.817146, -11.766209, -11.751227, -11.771116, -11.767917, -11.759330, -11.740242, -11.770084, -11.770973, -11.770555, -11.702766, -11.672210, -11.656888, -11.644030, -11.633999, -11.688310, -11.612173, -11.615041, -11.608862, -11.675717, -11.672152, -11.619037, -11.607554, -11.621890, -11.539628, -11.582389, -11.505353, -11.506137, -11.516038, -11.488252, -11.464626, -11.555939, -11.470755, -11.477320, -11.503404, -11.444288, -11.514609, -11.442399, -11.395453, -11.417263, -11.507715, -11.409320, -11.432245, -11.437587, -11.405253, -11.347139, -11.368037, -11.442106, -11.416598, -11.311483, -11.318091, -11.345511, -11.311282, -11.263789, -11.369459, -11.318594, -11.253346, -11.275534, -11.303650, -11.246404, -11.238109, -11.330812, -11.262724, -11.256104, -11.304247, -11.222750, -11.260267, -11.268924, -11.264678, -11.178239, -11.215854, -11.183023, -11.236221, -11.190973, -11.213630, -11.148606, -11.194403, -11.171699, -11.036693, -11.178444, -11.212547, -11.126407, -11.096385, -11.113798, -11.100501, -11.117359, -11.137890, -11.133387, -11.173369, -11.087261, -11.093644, -11.072756, -11.086142, -11.111346, -11.077774, -11.041398, -11.115988, -11.051571, -11.023808, -11.007654, -10.986833, -11.045266, -11.028788, -10.972257, -11.024872, -11.023347, -10.963393, -10.999147, -10.988231, -11.024704, -10.955430, -10.948047, -10.976632, -10.963916, -10.944159, -10.941738, -10.988978, -10.986086, -10.893852, -10.970823, -10.930062, -10.907232, -10.985453, -10.946364, -10.870025, -10.952854, -10.817455, -10.883003, -10.932498, -10.827333, -10.860927, -10.907078, -10.876232, -10.887182, -10.870004, -10.914099, -10.877161, -10.936840, -10.929503, -10.838376, -10.858479, -10.841352, -10.896008, -10.929105, -10.945358, -11.049899, -11.024334, -11.083250, -11.577282, -11.331383, -11.528310, -11.884033, -12.191691, -12.494642, -12.393940, -11.879013, -11.514395, -11.288580, -11.240140, -11.185865, -11.183484, -11.195589, -11.173580, -11.232604, -11.226796, -11.173893, -11.171396, -11.198562, -11.178386, -11.154948, -11.233259, -11.218584, -11.263170, -11.226203, -11.212432, -11.234622, -11.203861, -11.141663, -11.252211, -11.182387, -11.184281, -11.251010, -11.153616, -11.200994, -11.251609, -11.229125, -11.234426, -11.188760, -11.167431, -11.214060, -11.189217, -11.169435, -11.176277, -11.215827, -11.224740, -11.252942, -11.188585, -11.259495, -11.175788, -11.209007, -11.186180, -11.269020, -11.167184, -11.239420, -11.246427, -11.212875, -11.274052, -11.248956, -11.138576, -11.200762, -11.196568, -11.234824, -11.189839, -11.256922, -11.243899, -11.181837, -11.172835, -11.249906, -11.216124, -11.218074, -11.203452, -11.190719, -11.235559, -11.208005, -11.241541, -11.222897, -11.245105, -11.218976, -11.238669, -11.186864, -11.235706, -11.251585, -11.194207, -11.206015, -11.248406, -11.130074, -11.267996, -11.164400, -11.230077, -11.253899, -11.256946, -11.265360, -11.526430, -12.161562, -12.806432
+Channel 1: -4.259930, -6.665874, -8.134066, -8.840438, -8.619794, -7.955403, -8.262574, -8.998555, -9.045693, -8.528444, -7.130245, -7.262262, -6.663597, -7.233217, -6.972096, -6.821386, -6.677742, -7.806568, -7.335373, -7.410591, -6.870041, -7.541009, -7.960963, -8.444545, -8.221375, -7.770029, -7.763016, -8.179813, -7.863228, -8.234585, -8.139375, -8.447256, -7.722274, -7.880364, -6.586095, -7.770856, -7.927386, -8.511121, -8.588671, -8.453915, -8.236507, -8.271281, -8.939804, -7.892449, -8.888687, -8.282051, -8.188881, -8.348185, -7.744533, -8.006490, -7.487299, -8.713056, -9.093363, -8.952080, -8.845392, -9.472238, -8.873316, -8.721225, -8.098806, -8.701453, -8.930824, -8.396164, -8.278354, -9.088575, -8.290803, -8.495568, -8.264076, -8.434325, -8.595228, -8.251158, -7.845592, -8.516354, -7.873776, -8.346703, -8.880695, -8.575607, -8.760291, -8.786157, -8.844520, -8.617285, -8.004654, -8.407488, -8.017504, -8.364023, -8.809873, -8.760958, -7.909836, -8.728406, -8.382615, -9.363587, -9.165038, -9.414248, -9.130792, -9.224532, -8.767155, -8.954391, -9.178588, -9.399056, -8.776269, -9.172440, -8.084314, -8.842681, -9.525107, -10.051264, -9.343119, -9.600515, -8.690162, -8.984976, -9.492682, -9.637033, -9.019089, -9.689909, -9.886874, -9.555185, -8.698978, -9.482370, -9.512797, -9.796427, -9.084339, -9.067111, -8.096872, -9.394472, -9.210224, -9.591035, -8.734660, -9.219631, -9.474369, -9.584915, -9.621107, -8.822695, -8.890237, -9.707699, -8.917385, -9.366862, -9.725400, -9.663552, -9.681070, -9.314154, -9.079782, -8.314726, -7.821788, -9.292004, -9.918605, -9.974658, -8.805674, -9.051614, -8.993109, -8.707320, -9.610121, -9.380853, -9.539219, -9.583693, -8.444094, -9.370004, -9.774833, -9.178371, -8.069433, -8.741679, -9.057518, -9.273414, -9.224139, -9.633160, -8.476246, -9.280371, -7.927913, -9.082052, -9.332532, -9.351880, -8.692086, -9.607157, -8.883523, -8.950102, -7.722098, -8.834408, -8.517441, -9.079045, -9.703975, -9.093547, -9.000713, -8.605949, -8.179986, -9.252756, -9.447043, -8.756150, -8.281525, -8.750285, -8.695918, -9.297653, -8.472452, -9.554568, -9.649224, -9.381518, -9.197469, -7.805096, -7.631302, -8.775340, -8.234345, -9.489371, -9.777892, -9.381069, -8.678194, -8.850762, -7.287530, -8.545574, -7.447676, -8.876554, -9.582433, -9.590407, -9.882222, -9.883838, -9.288763, -9.118943, -7.675229, -8.229518, -7.170421, -7.817407, -7.205565, -8.695884, -9.216897, -9.148524, -7.428808, -8.720323, -8.317363, -8.370560, -7.106984, -8.726242, -9.387314, -8.698427, -8.072460, -8.357757, -7.377579, -8.342648, -7.289837, -8.238201, -8.384848, -8.944333, -8.949400, -9.203900, -9.035657, -9.163540, -8.073293, -7.974755, -7.929166, -8.947936, -9.142023, -9.270968, -9.305846, -8.361058, -8.018343, -8.932560, -8.223735, -8.836396, -7.915270, -8.753596, -8.604981, -8.492489, -8.559630, -9.541150, -9.361395, -9.288562, -8.349491, -9.096639, -9.020768, -9.538647, -9.318568, -8.856726, -8.520123, -9.246026, -8.430225, -8.377248, -8.167982, -8.518759, -9.347731, -9.710631, -9.302118, -8.489496, -7.592235, -7.705674, -7.287686, -8.487080, -8.087019, -8.961322, -9.055279, -9.079551, -8.932386, -8.889071, -7.805691, -8.656663, -7.920151, -8.411662, -8.936442, -9.642854, -8.826767, -8.716343, -7.467595, -8.323562, -8.461170, -8.868902, -8.692887, -8.625588, -8.171611, -9.140244, -9.517572, -9.013833, -8.891995, -8.924587, -7.552063, -8.659528, -9.011218, -9.835388, -9.553982, -8.811605, -8.372470, -9.111942, -8.329686, -8.317845, -8.564806, -7.922851, -7.458095, -7.964257, -7.765472, -8.852958, -8.004261, -8.580846, -7.945783, -8.703115, -8.308766, -8.203026, -7.815558, -8.566113, -8.240727, -8.818314, -8.148007, -8.323301, -8.430678, -8.997805, -7.646616, -8.818527, -8.304271, -8.703316, -7.301023, -8.111465, -9.022206, -9.175094, -8.195924, -9.038541, -8.702284, -7.924984, -7.833028, -8.954045, -8.984037, -8.906318, -8.771588, -8.077010, -7.400714, -8.603812, -9.210019, -9.064473, -8.652490, -8.205794, -7.619889, -8.567104, -8.550753, -8.550062, -7.631665, -8.534122, -9.733936, -9.977779, -9.118277, -9.742090, -9.107510, -8.430905, -8.022441, -8.587177, -9.021651, -7.880519, -7.746123, -7.836301, -6.868521, -8.423772, -8.782660, -9.423576, -8.260281, -8.590183, -7.321841, -8.259229, -7.961996, -8.479307, -7.360967, -7.342826, -7.451933, -7.621740, -6.663265, -8.063039, -7.318747, -8.346091, -7.880221, -8.537465, -7.400912, -7.799035, -7.097081, -7.607987, -6.399781, -5.818133, -4.206942, -4.873427, -5.870036, -7.291239, -7.132577, -8.057511, -7.916516, -8.310016, -7.182425, -8.365717, -8.209022, -8.168317, -7.596393, -8.103685, -6.841571, -7.362644, -7.668583, -8.431250, -7.828101, -7.703382, -6.534189, -7.691038, -6.858395, -8.142296, -8.667139, -8.501014, -7.613063, -8.795669, -7.589070, -8.072585, -7.145250, -8.226945, -7.153139, -8.173641, -7.536234, -8.041589, -7.015898, -7.913368, -7.038860, -8.217951, -7.877144, -8.356038, -8.270323, -7.800798, -8.486864, -7.774801, -8.109586, -9.023869, -8.373515, -8.463743, -8.083220, -8.798285, -8.303820, -8.513109, -8.073146, -8.009741, -7.220683, -7.716941, -6.996583, -7.472267, -7.212493, -7.494446, -7.912122, -8.258996, -7.328467, -7.363515, -7.818997, -7.495634, -6.799818, -7.531826, -6.498136, -7.636568, -6.885640, -7.639394, -6.917420, -7.549028, -6.717033, -7.402769, -6.375102, -6.889420, -6.735350, -7.222528, -6.668705, -7.202723, -6.608903, -7.570821, -7.501699, -7.425125, -7.080040, -8.427832, -7.533368, -7.938439, -7.413480, -8.108686, -6.766507, -7.338324, -7.053434, -8.005589, -7.035327, -7.516874, -7.424109, -8.089847, -7.000190, -7.458596, -7.081159, -6.558933, -5.088411, -7.060199, -6.769171, -7.562777, -6.649964, -6.674577, -6.462755, -6.777149, -6.819967, -8.117656, -7.640822, -7.916130, -6.262249, -7.592839, -6.132151, -7.613210, -6.293193, -7.393553, -6.353974, -7.469313, -6.163464, -6.751505, -6.172511, -7.133448, -6.491663, -7.821720, -6.676021, -7.639304, -6.155329, -7.014252, -5.443317, -6.704660, -5.916575, -6.898118, -6.195959, -7.433244, -6.455409, -7.007600, -6.128975, -7.460167, -6.123561, -7.651618, -7.164772, -7.629981, -6.835324, -6.716437, -5.183644, -6.868895, -6.805713, -7.968579, -7.487688, -7.114592, -5.821909, -7.316700, -6.855646, -7.720102, -6.446047, -7.697660, -6.339335, -7.687504, -6.834591, -6.683082, -6.942220, -6.909783, -5.074804, -6.165250, -6.153298, -5.678282, -4.613012, -5.964366, -5.786907, -6.916967, -6.850884, -7.534286, -8.144188, -7.996600, -6.341528, -7.122040, -5.758266, -7.088390, -5.968180, -6.704577, -6.537925, -7.251836, -6.228176, -6.687443, -6.398175, -6.690834, -5.928494, -6.550750, -6.842618, -7.406426, -5.854750, -7.262702, -6.566095, -7.092973, -6.727913, -7.309717, -6.720907, -6.788705, -5.831271, -6.358783, -6.244705, -6.687904, -7.170726, -7.503015, -6.122330, -6.378451, -5.728226, -6.376993, -6.353649, -7.462792, -7.881882, -7.554917, -7.625055, -7.638963, -6.011956, -6.946953, -6.791678, -6.385592, -5.502690, -4.915271, -3.416375, -4.899525, -4.581249, -6.402817, -5.971680, -7.012322, -6.136549, -6.824212, -5.319725, -6.310439, -4.835482, -6.512325, -5.837218, -7.188224, -6.723541, -6.708874, -6.554284, -5.596497, -5.616427, -6.737126, -6.436505, -7.376004, -6.440490, -6.446702, -6.007579, -6.601145, -6.317451, -6.036757, -6.105096, -7.011704, -5.711968, -5.987137, -6.980494, -7.624007, -6.877258, -7.194951, -6.188616, -5.987470, -4.655405, -6.499982, -6.489651, -6.532937, -6.708004, -6.527180, -6.724357, -6.717589, -6.022833, -6.931286, -6.336641, -5.685828, -4.039437, -6.219453, -8.130675, -9.464308, -10.022870, -10.420049, -10.703384, -10.945469, -11.123913, -11.233537, -11.379059, -11.494582, -11.570949, -11.675247, -11.761181, -11.768067, -11.876720, -11.893350, -11.947802, -11.989884, -12.004077, -12.054701, -12.056536, -12.044354, -12.132642, -12.120678, -12.167317, -12.158012, -12.181180, -12.234111, -12.213580, -12.198493, -12.204160, -12.181049, -12.212451, -12.228227, -12.194394, -12.214880, -12.222660, -12.221822, -12.209952, -12.211454, -12.231614, -12.189473, -12.269559, -12.235000, -12.216308, -12.242371, -12.219618, -12.193850, -12.249622, -12.135980, -12.168841, -12.146604, -12.162963, -12.133065, -12.176877, -12.193899, -12.186448, -12.118124, -12.070942, -12.128473, -12.127756, -12.127233, -12.084522, -12.087598, -12.059898, -12.036678, -12.050549, -12.025837, -12.031931, -12.072273, -12.063232, -11.981957, -12.024312, -12.010247, -12.003762, -11.971796, -11.992863, -11.976723, -12.006408, -11.907823, -11.917524, -11.936979, -11.914774, -11.909843, -11.857338, -11.827791, -11.818738, -11.888795, -11.909382, -11.865104, -11.827947, -11.788726, -11.810175, -11.717047, -11.772633, -11.790649, -11.793788, -11.773142, -11.705820, -11.728366, -11.702689, -11.730853, -11.739186, -11.704392, -11.706135, -11.697459, -11.680339, -11.669865, -11.703570, -11.697549, -11.661277, -11.529678, -11.662926, -11.676917, -11.647680, -11.607013, -11.658460, -11.595510, -11.508871, -11.550809, -11.548915, -11.564424, -11.606986, -11.650755, -11.522508, -11.488883, -11.567245, -11.519251, -11.487745, -11.415361, -11.505821, -11.463196, -11.427436, -11.428846, -11.495184, -11.484595, -11.447071, -11.356764, -11.387198, -11.433549, -11.385021, -11.381288, -11.412570, -11.381546, -11.437341, -11.441191, -11.381344, -11.277543, -11.320440, -11.275726, -11.365967, -11.311194, -11.317135, -11.320085, -11.225074, -11.287350, -11.278776, -11.293480, -11.309305, -11.255347, -11.285573, -11.194140, -11.244653, -11.189018, -11.185633, -11.218847, -11.213889, -11.249570, -11.167549, -11.208049, -11.164425, -11.189422, -11.162452, -11.137228, -11.119850, -11.170403, -11.115357, -11.167995, -11.095230, -11.144916, -11.131977, -11.218188, -11.122955, -11.087488, -11.094148, -11.117593, -11.072780, -11.149068, -11.072266, -11.064289, -10.957873, -11.110456, -11.084738, -10.982981, -11.059867, -10.989739, -11.026423, -11.046131, -11.043926, -11.035169, -10.988957, -10.986110, -11.049037, -11.020273, -11.016151, -10.952446, -10.977067, -11.005713, -10.958026, -10.960253, -10.967862, -10.907291, -10.987797, -10.980047, -10.960212, -10.902742, -10.904990, -10.905846, -10.908110, -10.894984, -10.916619, -10.872750, -10.865998, -10.830662, -10.915156, -10.869629, -10.846634, -10.835961, -10.850613, -10.783281, -10.834146, -10.895739, -10.908914, -10.848139, -10.796355, -10.818753, -10.812157, -10.800378, -10.834988, -10.916374, -10.953966, -11.065389, -11.065859, -11.090129, -11.459610, -11.276367, -11.578049, -11.910393, -12.216752, -12.428281, -12.393793, -11.969883, -11.537288, -11.248703, -11.168830, -11.168840, -11.218028, -11.186548, -11.135037, -11.196804, -11.194995, -11.116007, -11.144456, -11.200728, -11.253898, -11.172103, -11.147541, -11.185085, -11.161169, -11.215450, -11.158085, -11.167490, -11.224521, -11.135065, -11.193638, -11.183433, -11.186640, -11.244736, -11.189924, -11.253969, -11.204787, -11.206291, -11.244095, -11.138053, -11.176304, -11.150232, -11.206832, -11.192003, -11.193088, -11.192120, -11.187546, -11.204346, -11.198397, -11.147942, -11.162097, -11.121401, -11.136583, -11.160843, -11.152843, -11.169833, -11.183629, -11.196892, -11.168925, -11.188020, -11.209744, -11.185288, -11.200361, -11.213862, -11.218718, -11.186627, -11.170916, -11.157483, -11.213737, -11.200897, -11.240792, -11.182018, -11.195962, -11.130478, -11.133306, -11.196097, -11.207166, -11.203553, -11.204930, -11.240325, -11.132530, -11.123456, -11.159070, -11.205329, -11.170352, -11.195209, -11.192614, -11.211015, -11.148291, -11.120795, -11.191674, -11.138820, -11.281963, -11.270242, -11.489305, -12.294074, -12.989191
diff --git a/lib_v5/spec_utils.py b/lib_v5/spec_utils.py
index a889ef6..79bab8f 100644
--- a/lib_v5/spec_utils.py
+++ b/lib_v5/spec_utils.py
@@ -369,6 +369,23 @@ def ensembling(a, specs):
return spec
+def stft(wave, nfft, hl):
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+ spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
+ spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+def istft(spec, hl):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hl)
+ wave_right = librosa.istft(spec_right, hop_length=hl)
+ wave = np.asfortranarray([wave_left, wave_right])
+
if __name__ == "__main__":
import cv2
diff --git a/lib_v5/sv_ttk/__init__.py b/lib_v5/sv_ttk/__init__.py
new file mode 100644
index 0000000..b265472
--- /dev/null
+++ b/lib_v5/sv_ttk/__init__.py
@@ -0,0 +1,61 @@
+from pathlib import Path
+
+inited = False
+root = None
+
+
+def init(func):
+ def wrapper(*args, **kwargs):
+ global inited
+ global root
+
+ if not inited:
+ from tkinter import _default_root
+
+ path = (Path(__file__).parent / "sun-valley.tcl").resolve()
+
+ try:
+ _default_root.tk.call("source", str(path))
+ except AttributeError:
+ raise RuntimeError(
+ "can't set theme. "
+ "Tk is not initialized. "
+ "Please first create a tkinter.Tk instance, then set the theme."
+ ) from None
+ else:
+ inited = True
+ root = _default_root
+
+ return func(*args, **kwargs)
+
+ return wrapper
+
+
+@init
+def set_theme(theme):
+ if theme not in {"dark", "light"}:
+ raise RuntimeError(f"not a valid theme name: {theme}")
+
+ root.tk.call("set_theme", theme)
+
+
+@init
+def get_theme():
+ theme = root.tk.call("ttk::style", "theme", "use")
+
+ try:
+ return {"sun-valley-dark": "dark", "sun-valley-light": "light"}[theme]
+ except KeyError:
+ return theme
+
+
+@init
+def toggle_theme():
+ if get_theme() == "dark":
+ use_light_theme()
+ else:
+ use_dark_theme()
+
+
+use_dark_theme = lambda: set_theme("dark")
+use_light_theme = lambda: set_theme("light")
diff --git a/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc b/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..471fa89
Binary files /dev/null and b/lib_v5/sv_ttk/__pycache__/__init__.cpython-38.pyc differ
diff --git a/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc b/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000..477c027
Binary files /dev/null and b/lib_v5/sv_ttk/__pycache__/__init__.cpython-39.pyc differ
diff --git a/lib_v5/sv_ttk/sun-valley.tcl b/lib_v5/sv_ttk/sun-valley.tcl
new file mode 100644
index 0000000..7baac78
--- /dev/null
+++ b/lib_v5/sv_ttk/sun-valley.tcl
@@ -0,0 +1,46 @@
+source [file join [file dirname [info script]] theme dark.tcl]
+
+option add *tearOff 0
+
+proc set_theme {mode} {
+ if {$mode == "dark"} {
+ ttk::style theme use "sun-valley-dark"
+
+ array set colors {
+ -fg "#F6F6F7"
+ -bg "#0e0e0f"
+ -disabledfg "#F6F6F7"
+ -selectfg "#F6F6F7"
+ -selectbg "#003b50"
+ }
+
+ ttk::style configure . \
+ -background $colors(-bg) \
+ -foreground $colors(-fg) \
+ -troughcolor $colors(-bg) \
+ -focuscolor $colors(-selectbg) \
+ -selectbackground $colors(-selectbg) \
+ -selectforeground $colors(-selectfg) \
+ -insertwidth 0 \
+ -insertcolor $colors(-fg) \
+ -fieldbackground $colors(-selectbg) \
+ -font {"Century Gothic" 10} \
+ -borderwidth 0 \
+ -relief flat
+
+ tk_setPalette \
+ background [ttk::style lookup . -background] \
+ foreground [ttk::style lookup . -foreground] \
+ highlightColor [ttk::style lookup . -focuscolor] \
+ selectBackground [ttk::style lookup . -selectbackground] \
+ selectForeground [ttk::style lookup . -selectforeground] \
+ activeBackground [ttk::style lookup . -selectbackground] \
+ activeForeground [ttk::style lookup . -selectforeground]
+
+ ttk::style map . -foreground [list disabled $colors(-disabledfg)]
+
+ option add *font [ttk::style lookup . -font]
+ option add *Menu.selectcolor $colors(-fg)
+ option add *Menu.background #0e0e0f
+ }
+}
diff --git a/lib_v5/sv_ttk/theme/dark.tcl b/lib_v5/sv_ttk/theme/dark.tcl
new file mode 100644
index 0000000..33a815d
--- /dev/null
+++ b/lib_v5/sv_ttk/theme/dark.tcl
@@ -0,0 +1,534 @@
+# Copyright © 2021 rdbende
+
+# A stunning dark theme for ttk based on Microsoft's Sun Valley visual style
+
+package require Tk 8.6
+
+namespace eval ttk::theme::sun-valley-dark {
+ variable version 1.0
+ package provide ttk::theme::sun-valley-dark $version
+
+ ttk::style theme create sun-valley-dark -parent clam -settings {
+ proc load_images {imgdir} {
+ variable images
+ foreach file [glob -directory $imgdir *.png] {
+ set images([file tail [file rootname $file]]) \
+ [image create photo -file $file -format png]
+ }
+ }
+
+ load_images [file join [file dirname [info script]] dark]
+
+ array set colors {
+ -fg "#F6F6F7"
+ -bg "#0e0e0f"
+ -disabledfg "#F6F6F7"
+ -selectfg "#ffffff"
+ -selectbg "#2f60d8"
+ }
+
+ ttk::style layout TButton {
+ Button.button -children {
+ Button.padding -children {
+ Button.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Toolbutton {
+ Toolbutton.button -children {
+ Toolbutton.padding -children {
+ Toolbutton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TMenubutton {
+ Menubutton.button -children {
+ Menubutton.padding -children {
+ Menubutton.label -side left -expand 1
+ Menubutton.indicator -side right -sticky nsew
+ }
+ }
+ }
+
+ ttk::style layout TOptionMenu {
+ OptionMenu.button -children {
+ OptionMenu.padding -children {
+ OptionMenu.label -side left -expand 0
+ OptionMenu.indicator -side right -sticky nsew
+ }
+ }
+ }
+
+ ttk::style layout Accent.TButton {
+ AccentButton.button -children {
+ AccentButton.padding -children {
+ AccentButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Titlebar.TButton {
+ TitlebarButton.button -children {
+ TitlebarButton.padding -children {
+ TitlebarButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Close.Titlebar.TButton {
+ CloseButton.button -children {
+ CloseButton.padding -children {
+ CloseButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TCheckbutton {
+ Checkbutton.button -children {
+ Checkbutton.padding -children {
+ Checkbutton.indicator -side left
+ Checkbutton.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Switch.TCheckbutton {
+ Switch.button -children {
+ Switch.padding -children {
+ Switch.indicator -side left
+ Switch.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Toggle.TButton {
+ ToggleButton.button -children {
+ ToggleButton.padding -children {
+ ToggleButton.label -side left -expand 1
+ }
+ }
+ }
+
+ ttk::style layout TRadiobutton {
+ Radiobutton.button -children {
+ Radiobutton.padding -children {
+ Radiobutton.indicator -side left
+ Radiobutton.label -side right -expand 1
+ }
+ }
+ }
+
+ ttk::style layout Vertical.TScrollbar {
+ Vertical.Scrollbar.trough -sticky ns -children {
+ Vertical.Scrollbar.uparrow -side top
+ Vertical.Scrollbar.downarrow -side bottom
+ Vertical.Scrollbar.thumb -expand 1
+ }
+ }
+
+ ttk::style layout Horizontal.TScrollbar {
+ Horizontal.Scrollbar.trough -sticky ew -children {
+ Horizontal.Scrollbar.leftarrow -side left
+ Horizontal.Scrollbar.rightarrow -side right
+ Horizontal.Scrollbar.thumb -expand 1
+ }
+ }
+
+ ttk::style layout TSeparator {
+ TSeparator.separator -sticky nsew
+ }
+
+ ttk::style layout TCombobox {
+ Combobox.field -sticky nsew -children {
+ Combobox.padding -expand 1 -sticky nsew -children {
+ Combobox.textarea -sticky nsew
+ }
+ }
+ null -side right -sticky ns -children {
+ Combobox.arrow -sticky nsew
+ }
+ }
+
+ ttk::style layout TSpinbox {
+ Spinbox.field -sticky nsew -children {
+ Spinbox.padding -expand 1 -sticky nsew -children {
+ Spinbox.textarea -sticky nsew
+ }
+
+ }
+ null -side right -sticky nsew -children {
+ Spinbox.uparrow -side left -sticky nsew
+ Spinbox.downarrow -side right -sticky nsew
+ }
+ }
+
+ ttk::style layout Card.TFrame {
+ Card.field {
+ Card.padding -expand 1
+ }
+ }
+
+ ttk::style layout TLabelframe {
+ Labelframe.border {
+ Labelframe.padding -expand 1 -children {
+ Labelframe.label -side left
+ }
+ }
+ }
+
+ ttk::style layout TNotebook {
+ Notebook.border -children {
+ TNotebook.Tab -expand 1
+ Notebook.client -sticky nsew
+ }
+ }
+
+ ttk::style layout Treeview.Item {
+ Treeitem.padding -sticky nsew -children {
+ Treeitem.image -side left -sticky {}
+ Treeitem.indicator -side left -sticky {}
+ Treeitem.text -side left -sticky {}
+ }
+ }
+
+ # Button
+ ttk::style configure TButton -padding {8 4} -anchor center -foreground $colors(-fg)
+
+ ttk::style map TButton -foreground \
+ [list disabled #7a7a7a \
+ pressed #d0d0d0]
+
+ ttk::style element create Button.button image \
+ [list $images(button-rest) \
+ {selected disabled} $images(button-disabled) \
+ disabled $images(button-disabled) \
+ selected $images(button-rest) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Toolbutton
+ ttk::style configure Toolbutton -padding {8 4} -anchor center
+
+ ttk::style element create Toolbutton.button image \
+ [list $images(empty) \
+ {selected disabled} $images(button-disabled) \
+ selected $images(button-rest) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Menubutton
+ ttk::style configure TMenubutton -padding {8 4 0 4}
+
+ ttk::style element create Menubutton.button \
+ image [list $images(button-rest) \
+ disabled $images(button-disabled) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ ttk::style element create Menubutton.indicator image $images(arrow-down) -width 28 -sticky {}
+
+ # OptionMenu
+ ttk::style configure TOptionMenu -padding {8 4 0 4}
+
+ ttk::style element create OptionMenu.button \
+ image [list $images(button-rest) \
+ disabled $images(button-disabled) \
+ pressed $images(button-pressed) \
+ active $images(button-hover) \
+ ] -border 0 -sticky nsew
+
+ ttk::style element create OptionMenu.indicator image $images(arrow-down) -width 28 -sticky {}
+
+ # Accent.TButton
+ ttk::style configure Accent.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Accent.TButton -foreground \
+ [list pressed #25536a \
+ disabled #a5a5a5]
+
+ ttk::style element create AccentButton.button image \
+ [list $images(button-accent-rest) \
+ {selected disabled} $images(button-accent-disabled) \
+ disabled $images(button-accent-disabled) \
+ selected $images(button-accent-rest) \
+ pressed $images(button-accent-pressed) \
+ active $images(button-accent-hover) \
+ ] -border 4 -sticky nsew
+
+ # Titlebar.TButton
+ ttk::style configure Titlebar.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Titlebar.TButton -foreground \
+ [list disabled #6f6f6f \
+ pressed #d1d1d1 \
+ active #ffffff]
+
+ ttk::style element create TitlebarButton.button image \
+ [list $images(empty) \
+ disabled $images(empty) \
+ pressed $images(button-titlebar-pressed) \
+ active $images(button-titlebar-hover) \
+ ] -border 4 -sticky nsew
+
+ # Close.Titlebar.TButton
+ ttk::style configure Close.Titlebar.TButton -padding {8 4} -anchor center -foreground #ffffff
+
+ ttk::style map Close.Titlebar.TButton -foreground \
+ [list disabled #6f6f6f \
+ pressed #e8bfbb \
+ active #ffffff]
+
+ ttk::style element create CloseButton.button image \
+ [list $images(empty) \
+ disabled $images(empty) \
+ pressed $images(button-close-pressed) \
+ active $images(button-close-hover) \
+ ] -border 4 -sticky nsew
+
+ # Checkbutton
+ ttk::style configure TCheckbutton -padding 4
+
+ ttk::style element create Checkbutton.indicator image \
+ [list $images(check-unsel-rest) \
+ {alternate disabled} $images(check-tri-disabled) \
+ {selected disabled} $images(check-disabled) \
+ disabled $images(check-unsel-disabled) \
+ {pressed alternate} $images(check-tri-hover) \
+ {active alternate} $images(check-tri-hover) \
+ alternate $images(check-tri-rest) \
+ {pressed selected} $images(check-hover) \
+ {active selected} $images(check-hover) \
+ selected $images(check-rest) \
+ {pressed !selected} $images(check-unsel-pressed) \
+ active $images(check-unsel-hover) \
+ ] -width 26 -sticky w
+
+ # Switch.TCheckbutton
+ ttk::style element create Switch.indicator image \
+ [list $images(switch-off-rest) \
+ {selected disabled} $images(switch-on-disabled) \
+ disabled $images(switch-off-disabled) \
+ {pressed selected} $images(switch-on-pressed) \
+ {active selected} $images(switch-on-hover) \
+ selected $images(switch-on-rest) \
+ {pressed !selected} $images(switch-off-pressed) \
+ active $images(switch-off-hover) \
+ ] -width 46 -sticky w
+
+ # Toggle.TButton
+ ttk::style configure Toggle.TButton -padding {8 4 8 4} -anchor center -foreground $colors(-fg)
+
+ ttk::style map Toggle.TButton -foreground \
+ [list {selected disabled} #a5a5a5 \
+ {selected pressed} #d0d0d0 \
+ selected #ffffff \
+ pressed #25536a \
+ disabled #7a7a7a
+ ]
+
+ ttk::style element create ToggleButton.button image \
+ [list $images(button-rest) \
+ {selected disabled} $images(button-accent-disabled) \
+ disabled $images(button-disabled) \
+ {pressed selected} $images(button-rest) \
+ {active selected} $images(button-accent-hover) \
+ selected $images(button-accent-rest) \
+ {pressed !selected} $images(button-accent-rest) \
+ active $images(button-hover) \
+ ] -border 4 -sticky nsew
+
+ # Radiobutton
+ ttk::style configure TRadiobutton -padding 0
+
+ ttk::style element create Radiobutton.indicator image \
+ [list $images(radio-unsel-rest) \
+ {selected disabled} $images(radio-disabled) \
+ disabled $images(radio-unsel-disabled) \
+ {pressed selected} $images(radio-pressed) \
+ {active selected} $images(radio-hover) \
+ selected $images(radio-rest) \
+ {pressed !selected} $images(radio-unsel-pressed) \
+ active $images(radio-unsel-hover) \
+ ] -width 20 -sticky w
+
+ ttk::style configure Menu.TRadiobutton -padding 0
+
+ ttk::style element create Menu.Radiobutton.indicator image \
+ [list $images(radio-unsel-rest) \
+ {selected disabled} $images(radio-disabled) \
+ disabled $images(radio-unsel-disabled) \
+ {pressed selected} $images(radio-pressed) \
+ {active selected} $images(radio-hover) \
+ selected $images(radio-rest) \
+ {pressed !selected} $images(radio-unsel-pressed) \
+ active $images(radio-unsel-hover) \
+ ] -width 20 -sticky w
+
+ # Scrollbar
+ ttk::style element create Horizontal.Scrollbar.trough image $images(scroll-hor-trough) -sticky ew -border 6
+ ttk::style element create Horizontal.Scrollbar.thumb image $images(scroll-hor-thumb) -sticky ew -border 3
+
+ ttk::style element create Horizontal.Scrollbar.rightarrow image $images(scroll-right) -sticky {} -width 12
+ ttk::style element create Horizontal.Scrollbar.leftarrow image $images(scroll-left) -sticky {} -width 12
+
+ ttk::style element create Vertical.Scrollbar.trough image $images(scroll-vert-trough) -sticky ns -border 6
+ ttk::style element create Vertical.Scrollbar.thumb image $images(scroll-vert-thumb) -sticky ns -border 3
+
+ ttk::style element create Vertical.Scrollbar.uparrow image $images(scroll-up) -sticky {} -height 12
+ ttk::style element create Vertical.Scrollbar.downarrow image $images(scroll-down) -sticky {} -height 12
+
+ # Scale
+ ttk::style element create Horizontal.Scale.trough image $images(scale-trough-hor) \
+ -border 5 -padding 0
+
+ ttk::style element create Vertical.Scale.trough image $images(scale-trough-vert) \
+ -border 5 -padding 0
+
+ ttk::style element create Scale.slider \
+ image [list $images(scale-thumb-rest) \
+ disabled $images(scale-thumb-disabled) \
+ pressed $images(scale-thumb-pressed) \
+ active $images(scale-thumb-hover) \
+ ] -sticky {}
+
+ # Progressbar
+ ttk::style element create Horizontal.Progressbar.trough image $images(progress-trough-hor) \
+ -border 1 -sticky ew
+
+ ttk::style element create Horizontal.Progressbar.pbar image $images(progress-pbar-hor) \
+ -border 2 -sticky ew
+
+ ttk::style element create Vertical.Progressbar.trough image $images(progress-trough-vert) \
+ -border 1 -sticky ns
+
+ ttk::style element create Vertical.Progressbar.pbar image $images(progress-pbar-vert) \
+ -border 2 -sticky ns
+
+ # Entry
+ ttk::style configure TEntry -foreground $colors(-fg)
+
+ ttk::style map TEntry -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style element create Entry.field \
+ image [list $images(entry-rest) \
+ {focus hover !invalid} $images(entry-focus) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ {focus !invalid} $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 5 -padding 8 -sticky nsew
+
+ # Combobox
+ ttk::style configure TCombobox -foreground $colors(-fg)
+
+ ttk::style map TCombobox -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style configure ComboboxPopdownFrame -borderwidth 0 -flat solid
+
+ ttk::style map TCombobox -selectbackground [list \
+ {readonly hover} $colors(-selectbg) \
+ {readonly focus} $colors(-selectbg) \
+ ] -selectforeground [list \
+ {readonly hover} $colors(-selectfg) \
+ {readonly focus} $colors(-selectfg) \
+ ]
+
+ ttk::style element create Combobox.field \
+ image [list $images(entry-rest) \
+ {readonly disabled} $images(button-disabled) \
+ {readonly pressed} $images(button-pressed) \
+ {readonly hover} $images(button-hover) \
+ readonly $images(button-rest) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ focus $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 0 -padding {8 8 28 8}
+
+ ttk::style element create Combobox.arrow image $images(arrow-down) -width 35 -sticky {}
+
+ # Spinbox
+ ttk::style configure TSpinbox -foreground $colors(-fg)
+
+ ttk::style map TSpinbox -foreground \
+ [list disabled #757575 \
+ pressed #cfcfcf
+ ]
+
+ ttk::style element create Spinbox.field \
+ image [list $images(entry-rest) \
+ invalid $images(entry-invalid) \
+ disabled $images(entry-disabled) \
+ focus $images(entry-focus) \
+ hover $images(entry-hover) \
+ ] -border 5 -padding {8 8 54 8} -sticky nsew
+
+ ttk::style element create Spinbox.uparrow image $images(arrow-up) -width 35 -sticky {}
+ ttk::style element create Spinbox.downarrow image $images(arrow-down) -width 35 -sticky {}
+
+ # Sizegrip
+ ttk::style element create Sizegrip.sizegrip image $images(sizegrip) \
+ -sticky nsew
+
+ # Separator
+ ttk::style element create TSeparator.separator image $images(separator)
+
+ # Card
+ ttk::style element create Card.field image $images(card) \
+ -border 10 -padding 4 -sticky nsew
+
+ # Labelframe
+ ttk::style element create Labelframe.border image $images(card) \
+ -border 5 -padding 4 -sticky nsew
+
+ # Notebook
+ ttk::style configure TNotebook -padding 1
+
+ ttk::style element create Notebook.border \
+ image $images(notebook-border) -border 5 -padding 5
+
+ ttk::style element create Notebook.client image $images(notebook)
+
+ ttk::style element create Notebook.tab \
+ image [list $images(tab-rest) \
+ selected $images(tab-selected) \
+ active $images(tab-hover) \
+ ] -border 13 -padding {16 14 16 6} -height 32
+
+ # Treeview
+ ttk::style element create Treeview.field image $images(card) \
+ -border 5
+
+ ttk::style element create Treeheading.cell \
+ image [list $images(treeheading-rest) \
+ pressed $images(treeheading-pressed) \
+ active $images(treeheading-hover)
+ ] -border 5 -padding 15 -sticky nsew
+
+ ttk::style element create Treeitem.indicator \
+ image [list $images(arrow-right) \
+ user2 $images(empty) \
+ user1 $images(arrow-down) \
+ ] -width 26 -sticky {}
+
+ ttk::style configure Treeview -background $colors(-bg) -rowheight [expr {[font metrics font -linespace] + 2}]
+ ttk::style map Treeview \
+ -background [list selected #292929] \
+ -foreground [list selected $colors(-selectfg)]
+
+ # Panedwindow
+ # Insane hack to remove clam's ugly sash
+ ttk::style configure Sash -gripcount 0
+ }
+}
\ No newline at end of file
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-down.png b/lib_v5/sv_ttk/theme/dark/arrow-down.png
new file mode 100644
index 0000000..2b0a9d8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-down.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-right.png b/lib_v5/sv_ttk/theme/dark/arrow-right.png
new file mode 100644
index 0000000..2638d88
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-right.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/arrow-up.png b/lib_v5/sv_ttk/theme/dark/arrow-up.png
new file mode 100644
index 0000000..f935a0d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/arrow-up.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png b/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png
new file mode 100644
index 0000000..bf7bd9b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-hover.png b/lib_v5/sv_ttk/theme/dark/button-accent-hover.png
new file mode 100644
index 0000000..8aea9dd
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png b/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png
new file mode 100644
index 0000000..edc1114
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-accent-rest.png b/lib_v5/sv_ttk/theme/dark/button-accent-rest.png
new file mode 100644
index 0000000..75e64f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-accent-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-close-hover.png b/lib_v5/sv_ttk/theme/dark/button-close-hover.png
new file mode 100644
index 0000000..6fc0c00
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-close-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-close-pressed.png b/lib_v5/sv_ttk/theme/dark/button-close-pressed.png
new file mode 100644
index 0000000..6023dc1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-close-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-disabled.png b/lib_v5/sv_ttk/theme/dark/button-disabled.png
new file mode 100644
index 0000000..43add5f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-hover.png b/lib_v5/sv_ttk/theme/dark/button-hover.png
new file mode 100644
index 0000000..2041375
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-pressed.png b/lib_v5/sv_ttk/theme/dark/button-pressed.png
new file mode 100644
index 0000000..4270149
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-rest.png b/lib_v5/sv_ttk/theme/dark/button-rest.png
new file mode 100644
index 0000000..128f5f6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png b/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png
new file mode 100644
index 0000000..a2ac951
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-rest_alternative!!.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png b/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png
new file mode 100644
index 0000000..fcb3751
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-titlebar-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png b/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png
new file mode 100644
index 0000000..2ed0623
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/button-titlebar-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/card.png b/lib_v5/sv_ttk/theme/dark/card.png
new file mode 100644
index 0000000..eaac11c
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/card.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-disabled.png b/lib_v5/sv_ttk/theme/dark/check-disabled.png
new file mode 100644
index 0000000..f766eba
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-hover.png b/lib_v5/sv_ttk/theme/dark/check-hover.png
new file mode 100644
index 0000000..59358d4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-pressed.png b/lib_v5/sv_ttk/theme/dark/check-pressed.png
new file mode 100644
index 0000000..02ee6af
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-rest.png b/lib_v5/sv_ttk/theme/dark/check-rest.png
new file mode 100644
index 0000000..aa8dc67
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png b/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png
new file mode 100644
index 0000000..a9d31c7
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-hover.png b/lib_v5/sv_ttk/theme/dark/check-tri-hover.png
new file mode 100644
index 0000000..ed218a0
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png b/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png
new file mode 100644
index 0000000..68d7a99
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-tri-rest.png b/lib_v5/sv_ttk/theme/dark/check-tri-rest.png
new file mode 100644
index 0000000..26edcdb
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-tri-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png b/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png
new file mode 100644
index 0000000..9f4be22
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png b/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png
new file mode 100644
index 0000000..0081141
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png b/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png
new file mode 100644
index 0000000..26767b8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png b/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png
new file mode 100644
index 0000000..55eabc6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/check-unsel-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/empty.png b/lib_v5/sv_ttk/theme/dark/empty.png
new file mode 100644
index 0000000..2218363
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/empty.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-disabled.png b/lib_v5/sv_ttk/theme/dark/entry-disabled.png
new file mode 100644
index 0000000..43add5f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-focus.png b/lib_v5/sv_ttk/theme/dark/entry-focus.png
new file mode 100644
index 0000000..58999e4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-focus.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-hover.png b/lib_v5/sv_ttk/theme/dark/entry-hover.png
new file mode 100644
index 0000000..6b93830
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-invalid.png b/lib_v5/sv_ttk/theme/dark/entry-invalid.png
new file mode 100644
index 0000000..7304b24
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-invalid.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/entry-rest.png b/lib_v5/sv_ttk/theme/dark/entry-rest.png
new file mode 100644
index 0000000..e876752
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/entry-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/notebook-border.png b/lib_v5/sv_ttk/theme/dark/notebook-border.png
new file mode 100644
index 0000000..0827a07
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/notebook-border.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/notebook.png b/lib_v5/sv_ttk/theme/dark/notebook.png
new file mode 100644
index 0000000..15c05f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/notebook.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png b/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png
new file mode 100644
index 0000000..f8035f8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-pbar-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png b/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png
new file mode 100644
index 0000000..3d0cb29
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-pbar-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png b/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png
new file mode 100644
index 0000000..9fe4807
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-trough-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png b/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png
new file mode 100644
index 0000000..22a8c1c
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/progress-trough-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-disabled.png b/lib_v5/sv_ttk/theme/dark/radio-disabled.png
new file mode 100644
index 0000000..965136d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-hover.png b/lib_v5/sv_ttk/theme/dark/radio-hover.png
new file mode 100644
index 0000000..9823345
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-pressed.png b/lib_v5/sv_ttk/theme/dark/radio-pressed.png
new file mode 100644
index 0000000..ed89533
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-rest.png b/lib_v5/sv_ttk/theme/dark/radio-rest.png
new file mode 100644
index 0000000..ef891d1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png
new file mode 100644
index 0000000..ec7dd91
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png
new file mode 100644
index 0000000..7feda0b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png
new file mode 100644
index 0000000..7a76749
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png b/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png
new file mode 100644
index 0000000..f311983
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/radio-unsel-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png
new file mode 100644
index 0000000..ba77f1d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png
new file mode 100644
index 0000000..8398922
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png
new file mode 100644
index 0000000..70029b3
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png b/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png
new file mode 100644
index 0000000..f6571b9
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-thumb-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png b/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png
new file mode 100644
index 0000000..7fa2bf4
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-trough-hor.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png b/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png
new file mode 100644
index 0000000..205fed8
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scale-trough-vert.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-down.png b/lib_v5/sv_ttk/theme/dark/scroll-down.png
new file mode 100644
index 0000000..4c0e24f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-down.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png b/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png
new file mode 100644
index 0000000..795a88a
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-hor-thumb.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png b/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png
new file mode 100644
index 0000000..89d0403
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-hor-trough.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-left.png b/lib_v5/sv_ttk/theme/dark/scroll-left.png
new file mode 100644
index 0000000..f43538b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-left.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-right.png b/lib_v5/sv_ttk/theme/dark/scroll-right.png
new file mode 100644
index 0000000..a56511f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-right.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-up.png b/lib_v5/sv_ttk/theme/dark/scroll-up.png
new file mode 100644
index 0000000..7ddba7f
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-up.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png b/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png
new file mode 100644
index 0000000..572f33d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-vert-thumb.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png b/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png
new file mode 100644
index 0000000..c947ed1
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/scroll-vert-trough.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/separator.png b/lib_v5/sv_ttk/theme/dark/separator.png
new file mode 100644
index 0000000..6e01f55
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/separator.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/sizegrip.png b/lib_v5/sv_ttk/theme/dark/sizegrip.png
new file mode 100644
index 0000000..7080c04
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/sizegrip.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png b/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png
new file mode 100644
index 0000000..4032c61
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-hover.png b/lib_v5/sv_ttk/theme/dark/switch-off-hover.png
new file mode 100644
index 0000000..5a136bd
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png b/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png
new file mode 100644
index 0000000..040e2ea
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-off-rest.png b/lib_v5/sv_ttk/theme/dark/switch-off-rest.png
new file mode 100644
index 0000000..6c31bb2
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-off-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png b/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png
new file mode 100644
index 0000000..c0d67c5
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-disabled.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-hover.png b/lib_v5/sv_ttk/theme/dark/switch-on-hover.png
new file mode 100644
index 0000000..fd4de94
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png b/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png
new file mode 100644
index 0000000..00e87c6
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/switch-on-rest.png b/lib_v5/sv_ttk/theme/dark/switch-on-rest.png
new file mode 100644
index 0000000..52a19ea
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/switch-on-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-hover.png b/lib_v5/sv_ttk/theme/dark/tab-hover.png
new file mode 100644
index 0000000..43a113b
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-rest.png b/lib_v5/sv_ttk/theme/dark/tab-rest.png
new file mode 100644
index 0000000..d873b66
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-rest.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/tab-selected.png b/lib_v5/sv_ttk/theme/dark/tab-selected.png
new file mode 100644
index 0000000..eb7b211
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/tab-selected.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-hover.png b/lib_v5/sv_ttk/theme/dark/treeheading-hover.png
new file mode 100644
index 0000000..beaaf13
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-hover.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png b/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png
new file mode 100644
index 0000000..9cd311d
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-pressed.png differ
diff --git a/lib_v5/sv_ttk/theme/dark/treeheading-rest.png b/lib_v5/sv_ttk/theme/dark/treeheading-rest.png
new file mode 100644
index 0000000..374ed49
Binary files /dev/null and b/lib_v5/sv_ttk/theme/dark/treeheading-rest.png differ
diff --git a/models.py b/models.py
new file mode 100644
index 0000000..15e5fb3
--- /dev/null
+++ b/models.py
@@ -0,0 +1,244 @@
+import torch
+from torch._C import has_mkl
+import torch.nn as nn
+import numpy as np
+import librosa
+
+dim_c = 4
+k = 3
+model_path = 'model'
+n_fft_scale = {'bass': 8, 'drums':2, 'other':4, 'vocals':3, '*':2}
+
+
+class Conv_TDF(nn.Module):
+ def __init__(self, c, l, f, k, bn, bias=True):
+
+ super(Conv_TDF, self).__init__()
+
+ self.use_tdf = bn is not None
+
+ self.H = nn.ModuleList()
+ for i in range(l):
+ self.H.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=c, kernel_size=k, stride=1, padding=k//2),
+ nn.BatchNorm2d(c),
+ nn.ReLU(),
+ )
+ )
+
+ if self.use_tdf:
+ if bn==0:
+ self.tdf = nn.Sequential(
+ nn.Linear(f,f, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU()
+ )
+ else:
+ self.tdf = nn.Sequential(
+ nn.Linear(f,f//bn, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU(),
+ nn.Linear(f//bn,f, bias=bias),
+ nn.BatchNorm2d(c),
+ nn.ReLU()
+ )
+
+ def forward(self, x):
+ for h in self.H:
+ x = h(x)
+
+ return x + self.tdf(x) if self.use_tdf else x
+
+
+class Conv_TDF_net_trim(nn.Module):
+ def __init__(self, device, load, model_name, target_name, lr, epoch,
+ L, l, g, dim_f, dim_t, k=3, hop=1024, bn=None, bias=True):
+
+ super(Conv_TDF_net_trim, self).__init__()
+
+ self.dim_f, self.dim_t = 2**dim_f, 2**dim_t
+ self.n_fft = self.dim_f * n_fft_scale[target_name]
+ self.hop = hop
+ self.n_bins = self.n_fft//2+1
+ self.chunk_size = hop * (self.dim_t-1)
+ self.window = torch.hann_window(window_length=self.n_fft, periodic=True).to(device)
+ self.target_name = target_name
+ self.blender = 'blender' in model_name
+
+ out_c = dim_c*4 if target_name=='*' else dim_c
+ in_c = dim_c*2 if self.blender else dim_c
+ #out_c = dim_c*2 if self.blender else dim_c
+ self.freq_pad = torch.zeros([1, out_c, self.n_bins-self.dim_f, self.dim_t]).to(device)
+
+ self.n = L//2
+ if load:
+
+ self.first_conv = nn.Sequential(
+ nn.Conv2d(in_channels=in_c, out_channels=g, kernel_size=1, stride=1),
+ nn.BatchNorm2d(g),
+ nn.ReLU(),
+ )
+
+ f = self.dim_f
+ c = g
+ self.ds_dense = nn.ModuleList()
+ self.ds = nn.ModuleList()
+ for i in range(self.n):
+ self.ds_dense.append(Conv_TDF(c, l, f, k, bn, bias=bias))
+
+ scale = (2,2)
+ self.ds.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=c+g, kernel_size=scale, stride=scale),
+ nn.BatchNorm2d(c+g),
+ nn.ReLU()
+ )
+ )
+ f = f//2
+ c += g
+
+ self.mid_dense = Conv_TDF(c, l, f, k, bn, bias=bias)
+ #if bn is None and mid_tdf:
+ # self.mid_dense = Conv_TDF(c, l, f, k, bn=0, bias=False)
+
+ self.us_dense = nn.ModuleList()
+ self.us = nn.ModuleList()
+ for i in range(self.n):
+ scale = (2,2)
+ self.us.append(
+ nn.Sequential(
+ nn.ConvTranspose2d(in_channels=c, out_channels=c-g, kernel_size=scale, stride=scale),
+ nn.BatchNorm2d(c-g),
+ nn.ReLU()
+ )
+ )
+ f = f*2
+ c -= g
+
+ self.us_dense.append(Conv_TDF(c, l, f, k, bn, bias=bias))
+
+
+ self.final_conv = nn.Sequential(
+ nn.Conv2d(in_channels=c, out_channels=out_c, kernel_size=1, stride=1),
+ )
+
+
+ model_cfg = f'L{L}l{l}g{g}'
+ model_cfg += ', ' if (bn is None or bn==0) else f'bn{bn}, '
+
+ stft_cfg = f'f{dim_f}t{dim_t}, '
+
+ model_name = model_name[:model_name.index('(')+1] + model_cfg + stft_cfg + model_name[model_name.index('(')+1:]
+ try:
+ self.load_state_dict(
+ torch.load('{0}/{1}/{2}_lr{3}_e{4:05}.ckpt'.format(model_path, model_name, target_name, lr, epoch), map_location=device)
+ )
+ print(f'Loading model ({target_name})')
+ except FileNotFoundError:
+ print(f'Random init ({target_name})')
+
+
+ def stft(self, x):
+ x = x.reshape([-1, self.chunk_size])
+ x = torch.stft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
+ x = x.permute([0,3,1,2])
+ x = x.reshape([-1,2,2,self.n_bins,self.dim_t]).reshape([-1,dim_c,self.n_bins,self.dim_t])
+ return x[:,:,:self.dim_f]
+
+ def istft(self, x, freq_pad=None):
+ freq_pad = self.freq_pad.repeat([x.shape[0],1,1,1]) if freq_pad is None else freq_pad
+ x = torch.cat([x, freq_pad], -2)
+ c = 4*2 if self.target_name=='*' else 2
+ x = x.reshape([-1,c,2,self.n_bins,self.dim_t]).reshape([-1,2,self.n_bins,self.dim_t])
+ x = x.permute([0,2,3,1])
+ x = torch.istft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
+ return x.reshape([-1,c,self.chunk_size])
+
+
+ def forward(self, x):
+
+ x = self.first_conv(x)
+
+ x = x.transpose(-1,-2)
+
+ ds_outputs = []
+ for i in range(self.n):
+ x = self.ds_dense[i](x)
+ ds_outputs.append(x)
+ x = self.ds[i](x)
+
+ x = self.mid_dense(x)
+
+ for i in range(self.n):
+ x = self.us[i](x)
+ x *= ds_outputs[-i-1]
+ x = self.us_dense[i](x)
+
+ x = x.transpose(-1,-2)
+
+ x = self.final_conv(x)
+
+ return x
+
+def stft(wave, nfft, hl):
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+ spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
+ spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+def istft(spec, hl):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hl)
+ wave_right = librosa.istft(spec_right, hop_length=hl)
+ wave = np.asfortranarray([wave_left, wave_right])
+
+ return wave
+
+def spec_effects(wave, algorithm='default', value=None):
+ spec = [stft(wave[0],2048,1024),stft(wave[1],2048,1024)]
+ if algorithm == 'min_mag':
+ v_spec_m = np.where(np.abs(spec[1]) <= np.abs(spec[0]), spec[1], spec[0])
+ wave = istft(v_spec_m,1024)
+ elif algorithm == 'max_mag':
+ v_spec_m = np.where(np.abs(spec[1]) >= np.abs(spec[0]), spec[1], spec[0])
+ wave = istft(v_spec_m,1024)
+ elif algorithm == 'default':
+ #wave = [istft(spec[0],1024),istft(spec[1],1024)]
+ wave = (wave[1] * value) + (wave[0] * (1-value))
+ elif algorithm == 'invert_p':
+ X_mag = np.abs(spec[0])
+ y_mag = np.abs(spec[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = spec[1] - max_mag * np.exp(1.j * np.angle(spec[0]))
+ wave = istft(v_spec,1024)
+ return wave
+
+
+def get_models(name, device, load=True, stems='vocals'):
+
+ if name=='tdf_extra':
+ models = []
+ if 'vocals' in stems:
+ models.append(
+ Conv_TDF_net_trim(
+ device=device, load=load,
+ model_name='Conv-TDF', target_name='vocals',
+ lr=0.0001, epoch=0,
+ L=11, l=3, g=32, bn=8, bias=False,
+ dim_f=11, dim_t=8
+ )
+ )
+ return models
+
+ else:
+ print('Model undefined')
+ return None
+
+
+
diff --git a/requirements.txt b/requirements.txt
index a0052ba..de17853 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,4 +1,5 @@
Pillow
+audioread
tqdm==4.45.0
librosa==0.8.0
resampy==0.2.2
@@ -8,3 +9,18 @@ numpy==1.21.0
samplerate
SoundFile
soundstretch
+loguru
+boto3
+openunmix
+musdb
+SoundFile
+scipy
+norbert
+asteroid>=0.5.0
+demucs
+pydub
+audiosegment
+pyglet
+pyperclip
+julius
+yaml
\ No newline at end of file